
案例分享
- 度小满轩辕金融大模型
- 基础模型 LLAMA2-70B。
- 使用Post-Pretrain注入金融知识。
- 步骤
- 预训练阶段 获得知识
- 万级金融类书籍
- 十万级金融百科词条
- 百万级市公司公告
- 指令微调: 激活问答能力
- 根据金融百科启发式产生对应问答指令数据
- 改写金融试题数据,指令风格统一
- 强化学习:对齐偏好
- 人工标注排序数据
- 角色扮演客服类数据
- 金融计算数据
- CODE-LLAMA 代码大模型
- 结论
- 在HumanEval & MBPP 代码测评集上CODE-LLAMA-7B效果优于LLAMA2-70B
- 训练步骤
- 选择LLAMA2 7B 13B 34B
- 进行code traning 的持续训练
- 再第二步骤基础上将python code单独提取 进行专项增强
- 进行指令微调
- 千帆中文LLaMA大模型
- 数据
- 语料采集 高质量语料清洗
- 领域数据分析 配比
- 数据去重 回塑
- 基础与预训练
- 中文词表扩增
- 大模型收敛优化
- 3D分布式训练
- 指令能力优化
- 广泛收集 标注多种类型指令数据
- 注重理解 生成 对话等多种能力
- 自动评估和人工评估相组合
如何训练领域模型
- 两阶段Post-Pretrain (增加中文理解能力,注入领域知识)
- 中文增强
- 垂直领域
- 两阶段SFT(保证通用指令跟随能力同时,提升领域问答能力)
- 通用SFT
- 垂直领域SFT
- RLHF/DPO(人类偏好对齐)
- RLHF
- DPO
Post-Pretrain VS SFT
- 数据格式
- 语料格式 (任意数据格式)
- SFT格式(prompt response 问答对)
- Loss计算
- psot-Pretrain Loss计算
- 预测生成 前一个字预测下一个字
- SFT Loss 计算
- 只计算答案的损失 不计算问题的损失
- 语料的收集和清洗
- 文本抽取
- 多来源数据收集
- 正文提取
- 数据清洗
- 规则过滤
- 模型过滤
- 去重与校验
- MinHashLSH
- 单类别局部去重
- 全局去重
- 质量校验
- 人工抽样校验
- 小规模模型验证
- 语料配比(英文能力保持 中文能力增强 金融能力提升)
- 英文语料 VS 中文预料 = 1:3
- 金融语料 VS 通用语料 = 5:1(或者动态配比 前期9:1 后期 4:1)
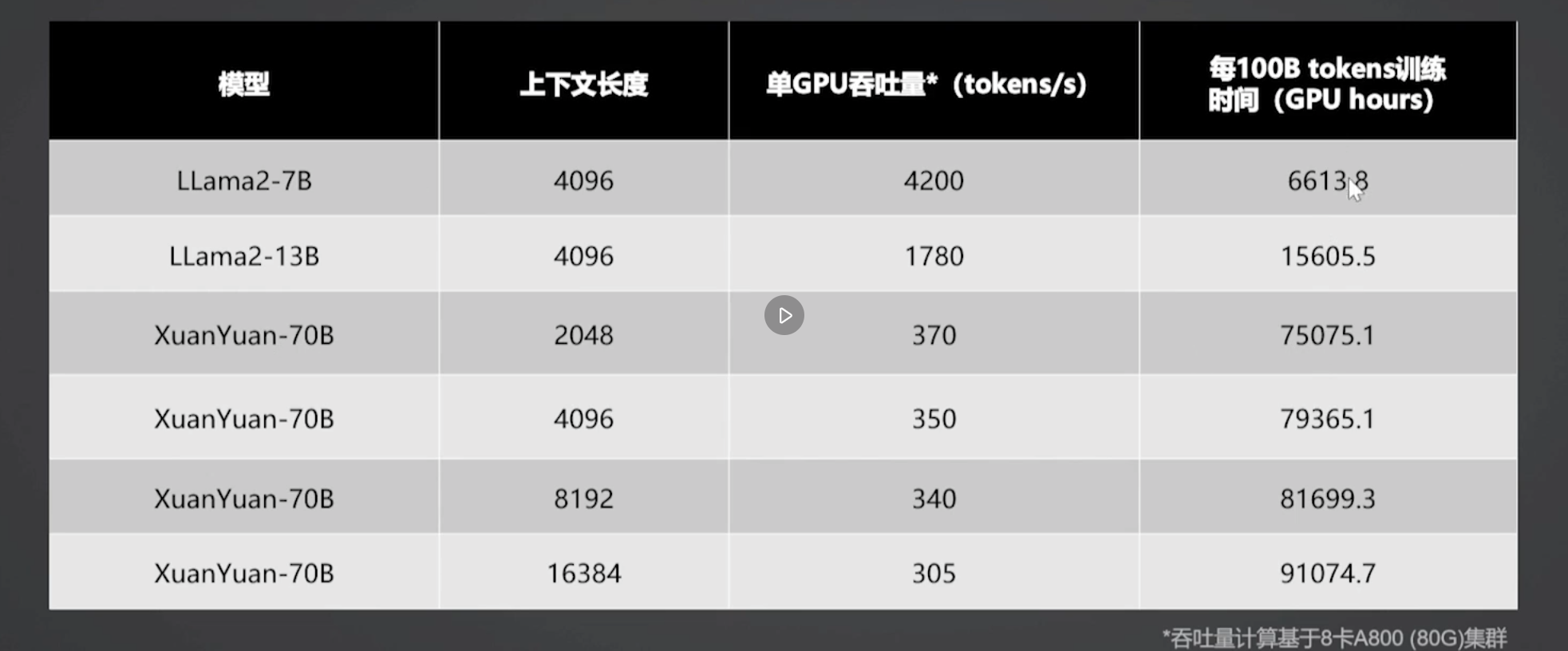
- Post-Pretrain 算力需求
![img]()
- Post-Pretrain 评测
- LOSS/PPL
- 多维度自动评测集
- 语言理解能力
- 知识推理能力
- 常识推理能力
- 学科能力
- 计算能力
- 代码能力
- 模型自动评估
- 评测方式 客观题自动评测
- 评测集
- 利用现有的Benchmark用新的纬度来集成
- 自动构建通用 + 金融客观评测集
- 特色
- 评测pipeline集成到训练pipline 自动化快速验证
- 评测方式
- 英文MMLU
- 中文CEVAL
- 金融FinanceIQ
posted @
2025-06-30 01:04
贺艳峰
阅读(
101)
评论()
收藏
举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号