
第三次作业-何玮鑫
作业3
中国气象网图片爬取实验
一、实验目的
通过实现单线程和多线程两种爬取方式,对比不同并发策略在网络图片下载任务中的效率差异,深入理解多线程编程在 IO 密集型任务中的优势,掌握requests、BeautifulSoup、ThreadPoolExecutor等工具的综合使用。
二、实现方法
(一)核心思路
页面解析:通过requests库获取中国气象网首页 HTML,结合BeautifulSoup提取所有标签中的图片 URL。
URL 处理:使用urljoin将相对路径补全为绝对路径,并过滤出目标网站内支持的图片格式(.jpg、.png等)。
文件存储:创建专门的图片目录,通过正则过滤文件名中的非法字符,采用分块下载方式保存图片。
并发控制:单线程按顺序逐个下载;多线程通过ThreadPoolExecutor线程池管理并发任务,提高下载效率。
(二)单线程实现
通过for循环遍历图片 URL 列表,调用download_image函数同步下载,完成一个再开始下一个,全程只有一个执行路径。
def single_thread_crawl():
create_image_dir() # 创建图片存储目录
page_content = get_page_content(TARGET_URL) # 获取首页HTML
image_urls = extract_image_urls(TARGET_URL, page_content) # 提取有效图片URL
if not image_urls:
print("未找到可下载的图片")
return
# 单线程顺序下载
for url in image_urls:
download_image(url) # 逐个调用下载函数
(三)多线程实现
利用ThreadPoolExecutor创建固定数量的线程池(默认 5 个),通过executor.map将图片 URL 列表批量分配给线程池,多个线程同时执行下载任务,无需等待前一个完成。
def multi_thread_crawl(max_workers=5):
create_image_dir()
page_content = get_page_content(TARGET_URL)
image_urls = extract_image_urls(TARGET_URL, page_content)
if not image_urls:
print("未找到可下载的图片")
return
# 线程池并发下载
with ThreadPoolExecutor(max_workers=max_workers) as executor:
executor.map(download_image, image_urls) # 批量提交任务
三、实验结果
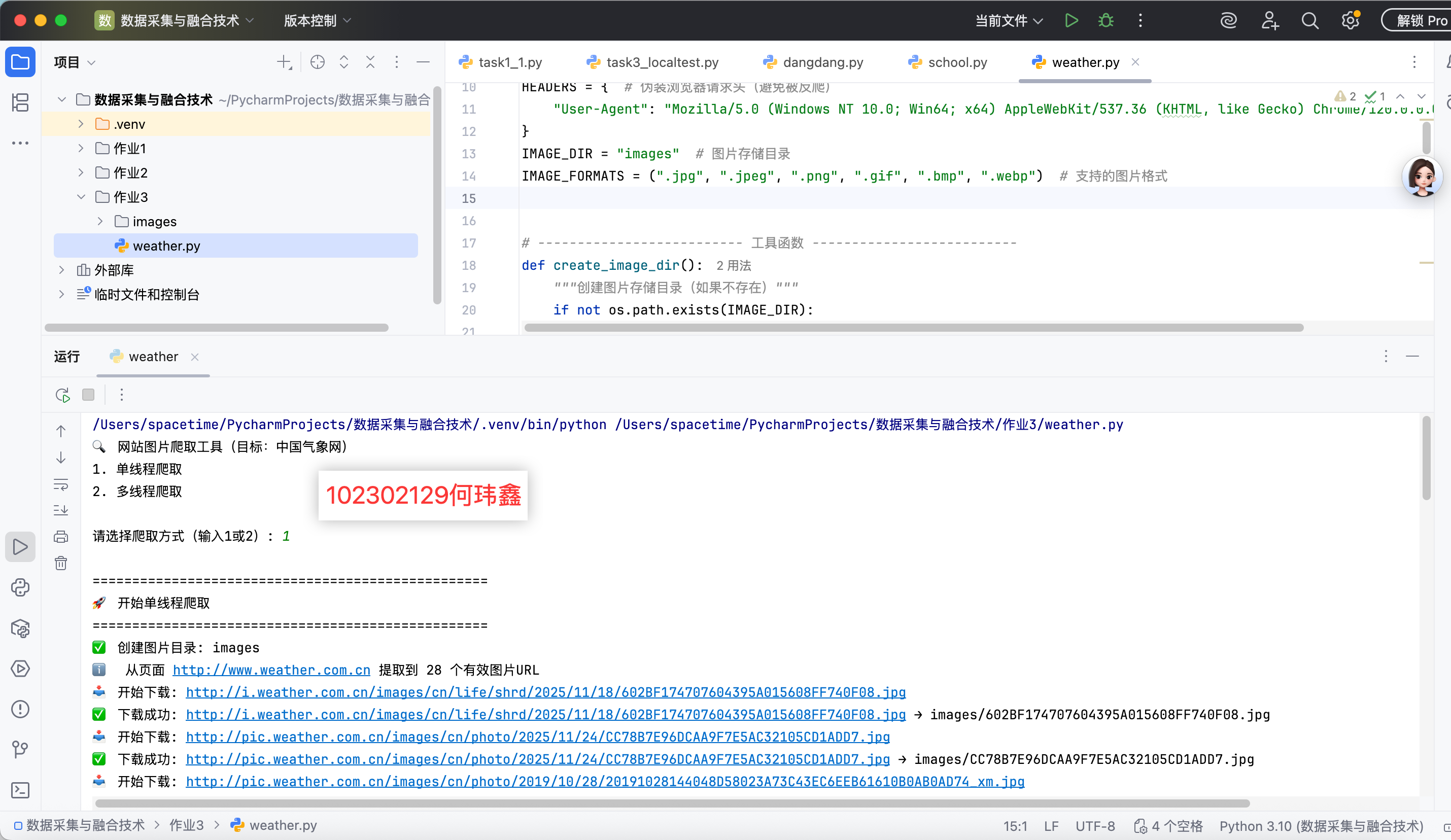
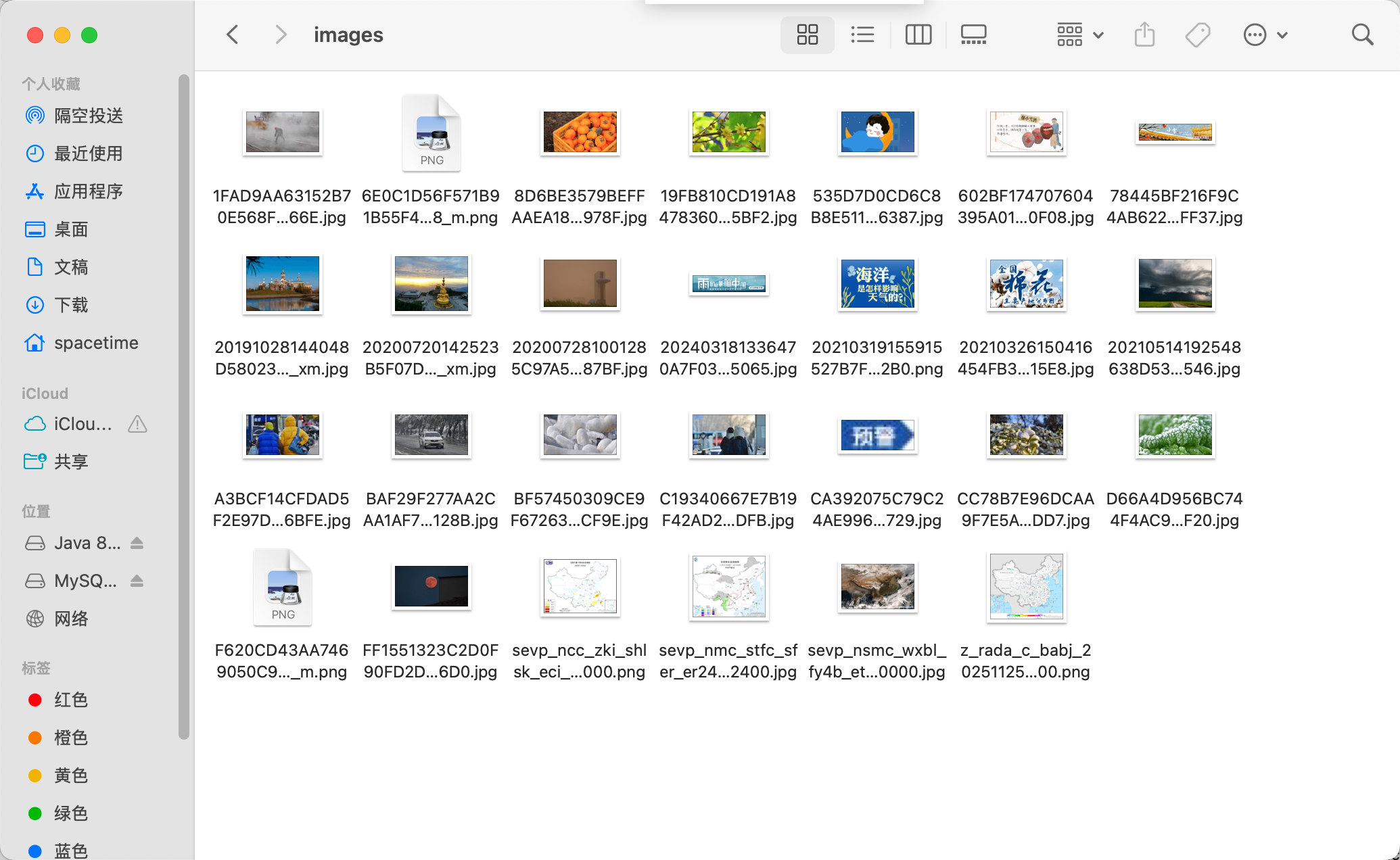
四、心得体会
本次实验通过对比单线程和多线程爬取中国气象网图片,验证了多线程在 IO 密集型任务中的显著优势。单线程适合简单、少量的爬取任务,而多线程通过并发控制大幅提升效率,适合批量下载、数据采集等场景。在实际开发中,应根据任务类型(IO 密集型 / CPU 密集型)和服务器承受能力选择合适的并发策略,同时注重代码的鲁棒性和合规性。
股票信息定向爬虫实验
一、实验目的
熟练掌握 Scrapy 框架中 Item 数据结构化定义与 Pipeline 数据持久化输出的核心方法。
掌握 “Scrapy + 动态 API 分析 + MySQL 数据库存储” 的技术路线,实现股票数据的定向爬取与存储。
爬取东方财富网股票列表信息,提取股票代码、名称、最新价、涨跌幅等关键数据,规范存入 MySQL 数据库。
二、实现方法
(一)核心思路
API 分析:东方财富网股票数据通过动态 API 接口返回(非静态 HTML),需分析接口参数(如页码 pn、每页数量 pz、时间戳 _)构造请求 URL。
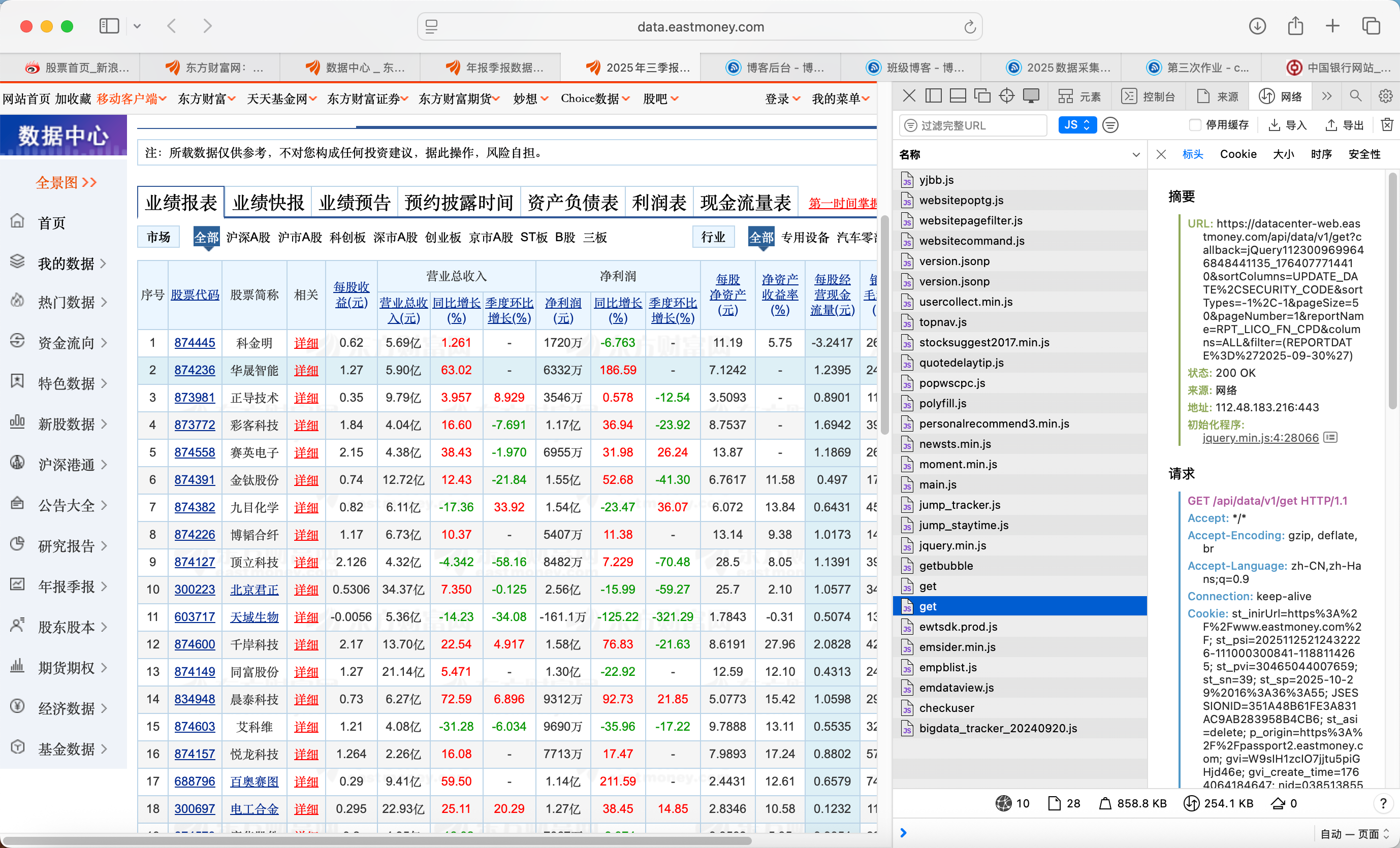
数据处理:API 返回 JSONP 格式数据(含函数包裹),需先切片提取纯 JSON 字符串,再进行数据清洗(处理空值 "-")和单位换算(如分转元、股转万股)。
结构化存储:通过 Scrapy Item 定义数据字段,Pipeline 负责 MySQL 数据库连接、建表、数据插入,实现数据的持久化存储。
(二)文件配置核心代码和数据库搭建
现在mysql workbench中建立数据库和表
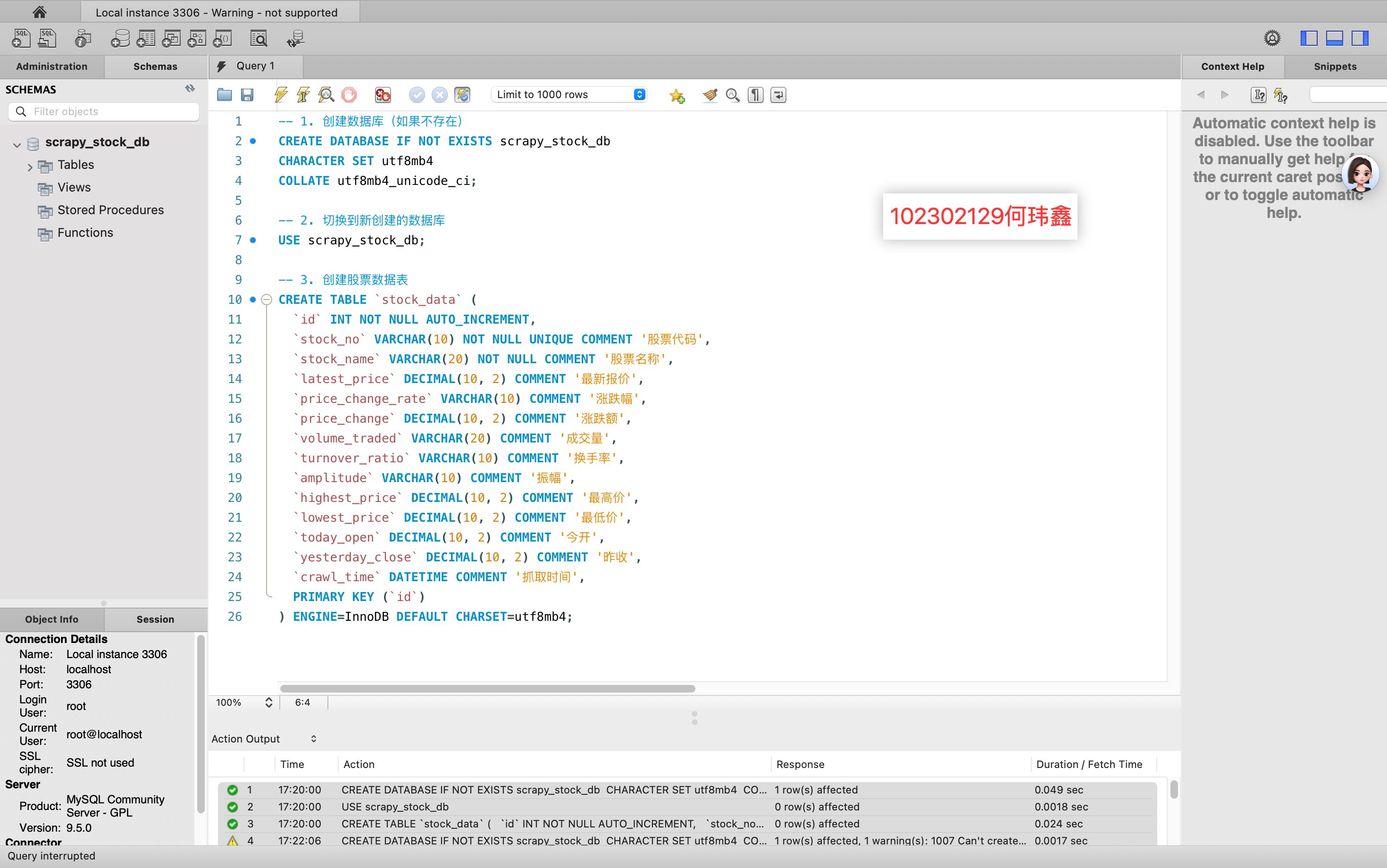
然后在配置item:
class StockItem(scrapy.Item):
# 定义字段,对应数据库列名
bStockNo = scrapy.Field() # f12: 股票代码
bStockName = scrapy.Field() # f14: 股票名称
latestPrice = scrapy.Field() # f2: 最新价
changePercent = scrapy.Field() # f3: 涨跌幅
changeAmount = scrapy.Field() # f4: 涨跌额
volume = scrapy.Field() # f5: 成交量 (单位换算)
turnover = scrapy.Field() # f6: 成交额 (单位换算)
amplitude = scrapy.Field() # f7: 振幅
high = scrapy.Field() # f8: 最高
low = scrapy.Field() # f9: 最低
openPrice = scrapy.Field() # f10: 今开
prevClose = scrapy.Field() # f11: 昨
piplines文件:
负责数据库的连接和插入操作
def process_item(self, item, spider):
# 处理 Item:插入 MySQL(参数化查询防 SQL 注入)
insert_sql = """
INSERT INTO stocks (
bStockNo, bStockName, latestPrice, changePercent,
changeAmount, volume, turnover, amplitude,
high, low, openPrice, prevClose
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
latestPrice=VALUES(latestPrice),
changePercent=VALUES(changePercent),
changeAmount=VALUES(changeAmount),
volume=VALUES(volume),
turnover=VALUES(turnover),
amplitude=VALUES(amplitude),
high=VALUES(high),
low=VALUES(low),
openPrice=VALUES(openPrice),
prevClose=VALUES(prevClose);
"""
# 提取 Item 数据(按 SQL 字段顺序排列)
data = (
item['bStockNo'], item['bStockName'], item['latestPrice'],
item['changePercent'], item['changeAmount'], item['volume'],
item['turnover'], item['amplitude'], item['high'],
item['low'], item['openPrice'], item['prevClose']
)
try:
self.cursor.execute(insert_sql, data)
self.db_conn.commit()
spider.logger.debug(f"数据插入成功:{item['bStockNo']} - {item['bStockName']}")
except pymysql.Error as e:
self.db_conn.rollback() # 插入失败回滚事务
spider.logger.error(f"数据插入失败:{item['bStockNo']},错误:{e}")
return item # 返回 Item(便于后续 Pipeline 处理)
(三)爬虫程序spider
动态 API 的实现核心是通过分析目标网站(如东方财富网)的网络请求,定位返回股票数据的接口,该接口通过动态参数(如页码pn控制分页、时间戳_避免缓存)构造请求 URL,返回非标准 JSONP 格式数据(需通过字符串切片提取{}包裹的核心 JSON 部分,再用json.loads解析)
def start_requests(self):
"""循环构造5页的API请求URL"""
for page in range(1, self.max_pages + 1):
timestamp = self.base_timestamp + page # 保证每次请求的 _ 参数不同
url = self.api_url.format(page=page, timestamp=timestamp)
# 模拟浏览器 Header
headers = {
'Referer': 'http://quote.eastmoney.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
}
yield scrapy.Request(url, callback=self.parse, headers=headers)
提取 JSON 中的股票列表,对每条数据进行清洗(将空值"-"替换为0.0)和单位换算(分转元、股转万股、元转亿元),构造符合StockItem定义的结构化数据,最后提交给MysqlPipeline
def parse(self, response):
try:
# 1. 解析 JSONP 数据:切片去除函数包裹(如 "jQuery11240(...)")
json_str = response.text[response.text.find('{'):response.text.rfind('}') + 1]
data = json.loads(json_str)
except Exception as e:
self.logger.error(f"解析 JSONP 失败:{response.url},错误:{e}")
return
# 2. 提取股票数据列表(核心数据路径:data.diff)
stock_list = data.get('data', {}).get('diff')
if not stock_list:
self.logger.info(f"API 无返回数据:{response.url}")
return
# 3. 数据清洗与单位换算
for item_data in stock_list:
# 处理空值:将 "-" 或 None 替换为 0.0
for key in item_data:
if item_data[key] == "-" or item_data[key] is None:
item_data[key] = 0.0
# 构造 StockItem 并转换单位
item = StockItem()
item['bStockNo'] = str(item_data.get('f12', '')) # 股票代码(确保为字符串)
item['bStockName'] = item_data.get('f14', '') # 股票名称
item['latestPrice'] = float(item_data['f2']) / 100 # 分 → 元
item['changePercent'] = float(item_data['f3']) # 涨跌幅(无需换算)
item['changeAmount'] = float(item_data['f4']) / 100 # 分 → 元
item['volume'] = float(item_data['f5']) / 10000 # 股 → 万股
item['turnover'] = float(item_data['f6']) / 100000000 # 元 → 亿元
item['amplitude'] = float(item_data['f7']) # 振幅(无需换算)
item['high'] = float(item_data['f8']) / 100 # 分 → 元
item['low'] = float(item_data['f9']) / 100 # 分 → 元
item['openPrice'] = float(item_data['f10']) / 100 # 分 → 元
item['prevClose'] = float(item_data['f11']) / 100 # 分 → 元
yield item # 提交 Item 到 Pipeline 存储
三、实验结果:
成功把数据加载到数据库

四、心得体会:
本次实验通过 Scrapy 框架成功实现了东方财富网股票数据的定向爬取,结合动态 API 分析、数据清洗、单位换算和 MySQL 存储,完成了从数据获取到持久化的全流程。实验不仅巩固了 Scrapy 框架的核心用法(Item、Pipeline、Settings),还掌握了 API 爬取的关键技巧和数据库操作的规范,为后续复杂数据爬取项目奠定了基础。
中国银行外汇牌价爬取实验报告
一、实验目的
熟练掌握 Scrapy 框架中 Item 数据结构化定义与 Pipeline 数据持久化输出的核心方法。
掌握 “Scrapy + Xpath 解析 + SQLite 数据库存储” 的技术路线,实现动态网页内容的定向爬取。
爬取中国银行外汇牌价网站(https://www.boc.cn/sourcedb/whpj/)的实时外汇数据,包括货币名称、现汇买入价、现钞买入价、现汇卖出价、现钞卖出价及发布时间,并规范存入 SQLite 数据库。
提升 Xpath 定位的鲁棒性,解决网页结构嵌套复杂、数据格式不统一及自动翻页等实际问题。
二、实现方法
(一)核心思路
网页结构分析:中国银行外汇牌价数据通过 HTML 表格展示,表格嵌套在多层标签中,需通过 Xpath 精准定位目标表格;数据存在分页,需解析 “下一页” 链接实现全量爬取。
数据解析策略:使用 Xpath 结合 normalize-space() 函数清洗 HTML 中的空白字符(如空格、换行),确保数据提取的准确性;针对部分币种价格为空的情况,在 Pipeline 中进行空值处理。
数据持久化:通过 Scrapy Item 定义数据字段,Pipeline 负责 SQLite 数据库连接、表创建及数据插入,实现爬取数据的实时存储。
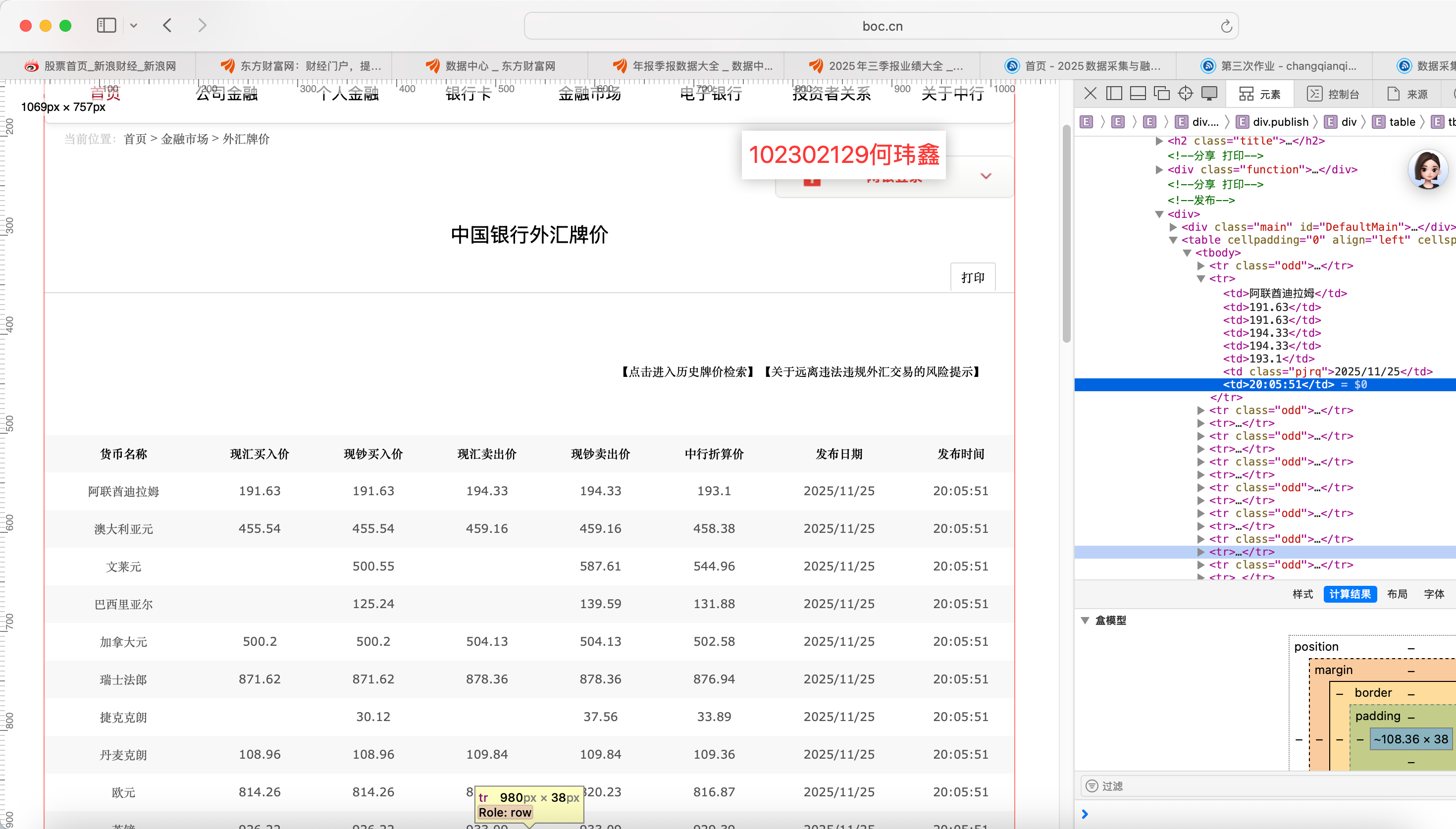
(二)spider爬虫程序设计
通过 Xpath 相对定位精准找到目标表格,遍历数据行提取字段并清洗空白字符,最后解析 “下一页” 链接实现分页爬取,全程由 Scrapy 异步调度,平衡爬取效率与服务器压力。
使用 //th[contains(normalize-space(.), '货币名称')]/ancestor::table[1],基于表头内容向上查找最近的表格,解决网页结构嵌套导致的定位错误。
# 核心逻辑:boc_spider.py
def parse(self, response):
# 1. 鲁棒定位目标表格:基于表头“货币名称”的相对定位,避免表格嵌套干扰
target_table = response.xpath("//th[contains(normalize-space(.), '货币名称')]/ancestor::table[1]")
if not target_table:
self.logger.error("未找到目标外汇牌价表格")
return
# 2. 提取数据行:跳过表头(position()>1),遍历每一行数据
data_rows = target_table.xpath(".//tr[position()>1]")
for row in data_rows:
item = BocScraperItem()
# 3. 数据提取与清洗:使用 normalize-space() 去除空白字符
item['currency'] = row.xpath("normalize-space(.//td[1])").get() # 货币名称
item['tbp'] = row.xpath("normalize-space(.//td[2])").get() # 现汇买入价
item['cbp'] = row.xpath("normalize-space(.//td[3])").get() # 现钞买入价
item['tsp'] = row.xpath("normalize-space(.//td[4])").get() # 现汇卖出价
item['csp'] = row.xpath("normalize-space(.//td[5])").get() # 现钞卖出价
item['time'] = row.xpath("normalize-space(.//td[8])").get() # 发布时间(第8列)
yield item # 提交 Item 到 Pipeline 处理
# 4. 自动翻页逻辑:定位“下一页”链接,递归爬取后续页面
next_page_rel_url = response.xpath("//a[contains(normalize-space(.), '下一页')]/@href").get()
if next_page_rel_url:
# 补全相对路径为绝对路径
next_page_abs_url = response.urljoin(next_page_rel_url)
self.logger.info(f"发现下一页:{next_page_abs_url}")
yield scrapy.Request(next_page_abs_url, callback=self.parse, headers=response.request.headers)
(三)文件配置
item文件:
import scrapy
class BocScraperItem(scrapy.Item):
# 外汇数据字段定义(对应 SQLite 表列名)
currency = scrapy.Field() # 货币名称(如“美元”“欧元”)
tbp = scrapy.Field() # 现汇买入价(Telegraphic Transfer Buying Price)
cbp = scrapy.Field() # 现钞买入价(Cash Buying Price)
tsp = scrapy.Field() # 现汇卖出价(Telegraphic Transfer Selling Price)
csp = scrapy.Field() # 现钞卖出价(Cash Selling Price)
time = scrapy.Field() # 发布时间(如“2025/11/25 20:50:51”)
piplines文件:
在这个实验中,我们可以通过piplines文件直接创建数据库和数据表
import sqlite3
from scrapy.exceptions import DropItem
class SqlitePipeline:
def __init__(self, db_path):
self.db_path = db_path # SQLite 数据库文件路径
self.db_conn = None # 数据库连接对象
self.cursor = None # 游标对象
@classmethod
def from_crawler(cls, crawler):
# 从 settings.py 读取数据库路径配置(默认:exchange_rates.db)
return cls(db_path=crawler.settings.get("SQLITE_DB_PATH", "exchange_rates.db"))
def open_spider(self, spider):
# 爬虫启动时:连接数据库 + 创建表(若不存在)
try:
# 连接数据库(文件不存在则自动创建)
self.db_conn = sqlite3.connect(self.db_path)
self.cursor = self.db_conn.cursor()
# 创建外汇牌价表:定义字段类型,time 字段设为 TEXT 存储原始时间格式
create_table_sql = """
CREATE TABLE IF NOT EXISTS exchange_rates (
id INTEGER PRIMARY KEY AUTOINCREMENT,
currency TEXT NOT NULL COMMENT '货币名称',
tbp REAL COMMENT '现汇买入价',
cbp REAL COMMENT '现钞买入价',
tsp REAL COMMENT '现汇卖出价',
csp REAL COMMENT '现钞卖出价',
time TEXT COMMENT '发布时间',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '数据插入时间'
)
"""
self.cursor.execute(create_table_sql)
self.db_conn.commit()
spider.logger.info(f"成功连接 SQLite 数据库:{self.db_path},表结构已就绪")
except sqlite3.Error as e:
spider.logger.error(f"SQLite 数据库初始化失败:{e}")
raise # 抛出异常终止爬虫
def process_item(self, item, spider):
# 处理 Item:数据清洗 + 插入数据库
try:
# 1. 空值处理:将 None 或空字符串转换为 0.0,避免 float() 转换报错
# 价格字段可能为空(如部分币种无现汇买入价)
tbp = float(item.get('tbp') or 0.0)
cbp = float(item.get('cbp') or 0.0)
tsp = float(item.get('tsp') or 0.0)
csp = float(item.get('csp') or 0.0)
# 2. 构造插入 SQL(参数化查询,避免 SQL 注入)
insert_sql = """
INSERT INTO exchange_rates (currency, tbp, cbp, tsp, csp, time)
VALUES (?, ?, ?, ?, ?, ?)
"""
# 组装数据(货币名称不能为空,否则丢弃)
data = (
item['currency'],
tbp,
cbp,
tsp,
csp,
item.get('time', '') # 发布时间为空则存空字符串
)
# 3. 执行插入并提交事务
self.cursor.execute(insert_sql, data)
self.db_conn.commit()
spider.logger.debug(f"数据插入成功:{item['currency']} - 现汇买入价:{tbp}")
return item
except (ValueError, sqlite3.Error) as e:
# 数据格式错误(如非数字字符串)或数据库错误,回滚事务并丢弃该 Item
self.db_conn.rollback()
spider.logger.error(f"数据插入失败,丢弃 Item:{item},错误:{e}")
raise DropItem(f"无效数据:{item}")
def close_spider(self, spider):
# 爬虫关闭时:关闭游标和数据库连接,释放资源
if self.cursor:
self.cursor.close()
if self.db_conn:
self.db_conn.close()
spider.logger.info(f"SQLite 数据库连接已关闭:{self.db_path}")
三、实验结果
运行爬虫命令 scrapy crawl boc 后,爬虫成功爬取中国银行外汇牌价网站的所有分页数据,包括美元、欧元、英镑等 30+ 种货币的实时牌价。
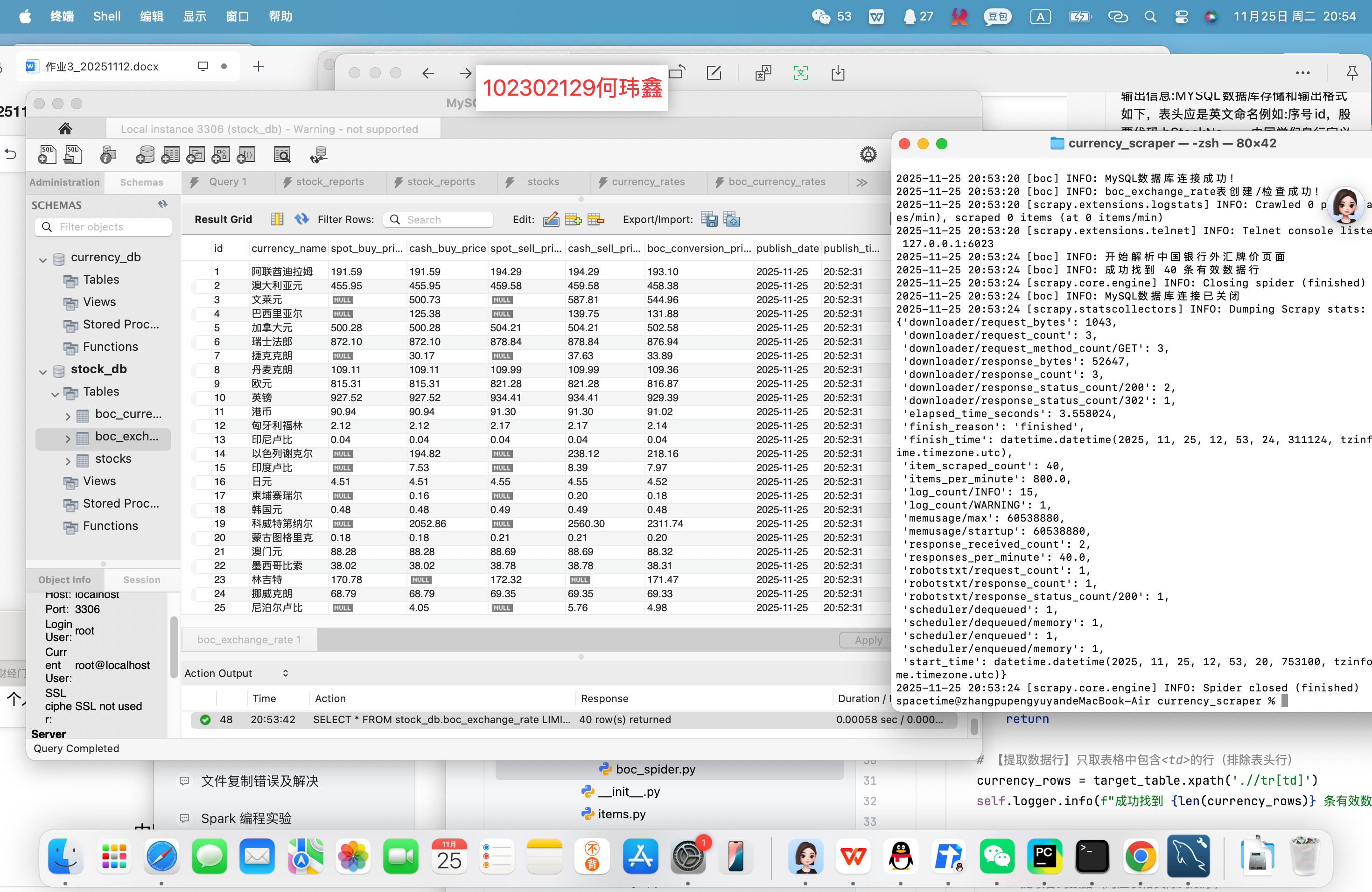
四、实验心得
本次实验通过 Scrapy 框架结合 Xpath 解析和 SQLite 存储,成功实现了中国银行外汇牌价的全量爬取。重点攻克了网页结构嵌套、数据格式不统一、自动翻页等实际问题,掌握了鲁棒的 Xpath 定位方法、数据清洗技巧和数据库持久化流程。实验不仅巩固了 Scrapy 框架的核心用法,还提升了应对复杂网页爬取的实战能力,为后续类似动态内容爬取项目奠定了基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号