SpringCloud (九) Hystrix请求合并的使用

前言:
承接上一篇文章,两文本来可以一起写的,但是发现RestTemplate使用普通的调用返回包装类型会出现一些问题,也正是这个问题,两文没有合成一文,本文篇幅不会太长,会说一下使用和适应的场景。
本文简单记述了Hystrix的请求合并的使用
>注意:本文项目地址:https://github.com/HellxZ/SpringCloudLearn.git
目录:
本文内容:
一、请求合并是做什么的?
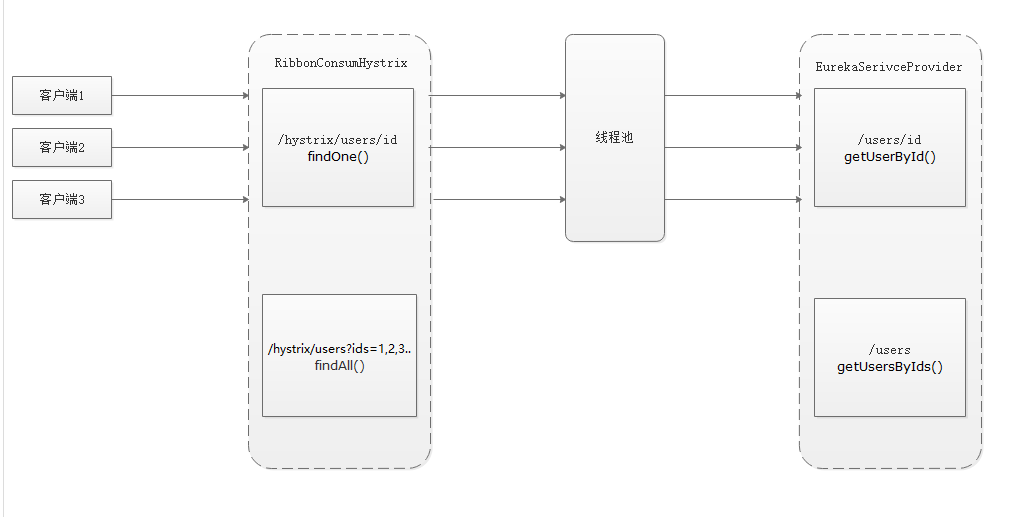
如图,多个客户端发送请求调用RibbonConsumHystrix(消费者)项目中的findOne方法,这时候在这个项目中的线程池中会发申请与请求数量相同的线程数,对EurekaServiceProvider(服务提供者)的getUserById方法发起调用,每个线程都要调用一次,在高并发的场景下,这样势必会对服务提供者项目产生巨大的压力。
请求合并就是将单个请求合并成一个请求,去调用服务提供者,从而降低服务提供者负载的,一种应对高并发的解决办法
二、请求合并的原理
NetFlix在Hystrix为我们提供了应对高并发的解决方案----请求合并,如下图

通过请求合并器设置延迟时间,将时间内的,多个请求单个的对象的方法中的参数(id)取出来,拼成符合服务提供者的多个对象返回接口(getUsersByIds方法)的参数,指定调用这个接口(getUsersByIds方法),返回的对象List再通过一个方法(mapResponseToRequests方法),按照请求的次序将结果对象对应的装到Request对应的Response中返回结果。
三、请求合并适用的场景
在服务提供者提供了返回单个对象和多个对象的查询接口,并且单个对象的查询并发数很高,服务提供者负载较高的时候,我们就可以使用请求合并来降低服务提供者的负载
四、请求合并带来的问题
问题:即然请求合并这么好,我们是否就可以将所有返回单个结果的方法都用上请求合并呢?答案自然是否定的!
原因有二:
- 在第二节曾介绍过,我们为这个请求人为的设置了延迟时间,这样在并发不高的接口上使用请求缓存,会降低响应速度
- 有可能会提高服务提供者的负载:返回List的方法并发比返回单个对象方法负载更高的情况
- 实现请求合并比较复杂
五、实现请求合并
1、传统方式
首先在服务提供者的GetRequestController中添加两个接口,用于打印是哪个方法被调用
/**
* 为Hystrix请求合并提供的接口
*/
@GetMapping("/users/{id}")
public User getUserById(@PathVariable Long id){
logger.info("=========getUserById方法:入参ids:"+id);
return new User("one"+id, "女", "110-"+id);
}
@GetMapping("/users")
public List<User> getUsersByIds(@RequestParam("ids") List<Long> ids){
List<User> userList = new ArrayList<>();
User user;
logger.info("=========getUsersByIds方法:入参ids:"+ids);
for(Long id : ids){
user = new User("person"+id ,"男","123-"+id);
userList.add(user);
}
System.out.println(userList);
return userList;
}
在消费者(RibbonConsumHystrix)项目中的RibbonController中实现简单的调用上边的两个接口
/**
* 单个请求处理
* @param id
*/
@GetMapping("/users/{id}")
public User findOne(@PathVariable Long id){
LOGGER.debug("=============/hystrix/users/{} 执行了", id);
User user = service.findOne(id);
return user;
}
/**
* 多个请求处理
* @param ids id串,使用逗号分隔
*/
@GetMapping("/users")
public List<User> findAll(@RequestParam List<Long> ids){
LOGGER.debug("=============/hystrix/users?ids={} 执行了", ids);
return service.findAll(ids);
}
扩充RibbonService,添加两个方法,分别调用上述两个接口,主要是为了分层明确
/**请求合并使用到的测试方法**/
/**
* 查一个User对象
*/
public User findOne(Long id){
LOGGER.info("findOne方法执行了,id= "+id);
return restTemplate.getForObject("http://eureka-service/users/{1}", User.class, id);
}
/**
* 查多个对象
*
* 注意: 这里用的是数组,作为结果的接收,因为restTemplate.getForObject方法在这里受限
* 如果尽如《SpringCloud微服务实战》一书中指定类型为List.class,会返回一个List<LinkedHashMap>类型的集合
* 为了避坑这里我们使用数组的方式接收结果
*/
public List<User> findAll(List<Long> ids){
LOGGER.info("findAll方法执行了,ids= "+ids);
User[] users = restTemplate.getForObject("http://eureka-service/users?ids={1}", User[].class, StringUtils.join(ids, ","));
return Arrays.asList(users);
}
接着在hystrix包下创建一个请求批处理UserBatchCommand类,使他继承HystrixCommand,泛型用List
package com.cnblogs.hellxz.hystrix;
import com.cnblogs.hellxz.entity.User;
import com.cnblogs.hellxz.servcie.RibbonService;
import com.netflix.hystrix.HystrixCommand;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
import static com.netflix.hystrix.HystrixCommandGroupKey.Factory.asKey;
/**
* @Author : Hellxz
* @Description: 批量请求命令的实现
* @Date : 2018/5/5 11:18
*/
public class UserBatchCommand extends HystrixCommand<List<User>> {
private static final Logger LOGGER = LoggerFactory.getLogger(UserBatchCommand.class);
private RibbonService service;
/**
* 这个ids是UserCollapseCommand获取的参数集
*/
private List<Long> ids;
public UserBatchCommand(RibbonService ribbonService, List<Long> ids){
super(Setter.withGroupKey(asKey("userBatchCommand")));
this.service = ribbonService;
this.ids = ids;
}
/**
* <b>方法名</b>: run
* <p><b>描 述</b>: 调用服务层的简单调用返回集合</p>
*
* @param
* @return List<User>
*
* <p><b>创建日期</b> 2018/5/22 12:39 </p>
* @author HELLXZ 张
* @version 1.0
* @since jdk 1.8
*/
@Override
protected List<User> run() {
List<User> users = service.findAll(ids);
System.out.println(users);
return users;
}
/**
* Fallback回调方法,如果没有会报错
*/
@Override
protected List<User> getFallback(){
LOGGER.info("UserBatchCommand的run方法,调用失败");
return null;
}
}
上边的这个类是实际用来调用服务提供者的接口的,除了这个我们还需要一个将请求合并的类
在hystrix包下创建UserCollapseCommand
package com.cnblogs.hellxz.hystrix;
import com.cnblogs.hellxz.entity.User;
import com.cnblogs.hellxz.servcie.RibbonService;
import com.netflix.hystrix.HystrixCollapser;
import com.netflix.hystrix.HystrixCollapserProperties;
import com.netflix.hystrix.HystrixCommand;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.stream.Collectors;
//注意这个asKey方法不是HystrixCommandKey.Factory.asKey
import static com.netflix.hystrix.HystrixCollapserKey.Factory.asKey;
/**
* @Author : Hellxz
* @Description: 继承HystrixCollapser的请求合并器
* @Date : 2018/5/5 11:42
*/
public class UserCollapseCommand extends HystrixCollapser<List<User>,User,Long> {
private RibbonService service;
private Long userId;
/**
* 构造方法,主要用来设置这个合并器的时间,意为每多少毫秒就会合并一次
* @param ribbonService 调用的服务
* @param userId 单个请求传入的参数
*/
public UserCollapseCommand(RibbonService ribbonService, Long userId){
super(Setter.withCollapserKey(asKey("userCollapseCommand")).andCollapserPropertiesDefaults(HystrixCollapserProperties.Setter().withTimerDelayInMilliseconds(100)));
this.service = ribbonService;
this.userId = userId;
}
/**
* 获取请求中的参数
*/
@Override
public Long getRequestArgument() {
return userId;
}
/**
* 创建命令,执行批量操作
*/
@Override
public HystrixCommand<List<User>> createCommand(Collection<CollapsedRequest<User, Long>> collapsedRequests) {
//按请求数声名UserId的集合
List<Long> userIds = new ArrayList<>(collapsedRequests.size());
//通过请求将100毫秒中的请求参数取出来装进集合中
userIds.addAll(collapsedRequests.stream().map(CollapsedRequest::getArgument).collect(Collectors.toList()));
//返回UserBatchCommand对象,自动执行UserBatchCommand的run方法
return new UserBatchCommand(service, userIds);
}
/**
* 将返回的结果匹配回请求中
* @param batchResponse 批量操作的结果
* @param collapsedRequests 合在一起的请求
*/
@Override
protected void mapResponseToRequests(List<User> batchResponse, Collection<CollapsedRequest<User, Long>> collapsedRequests) {
int count = 0 ;
for(CollapsedRequest<User,Long> collapsedRequest : collapsedRequests){
//从批响应集合中按顺序取出结果
User user = batchResponse.get(count++);
//将结果放回原Request的响应体内
collapsedRequest.setResponse(user);
}
}
}
其中将多个参数封装成一个List,将参数交给UserBatchCommand类执行
创建测试接口:
在这里用了类比方法,分别是同步方法和异步方法
/**
* 合并请求测试
* 说明:这个测试本应在findOne方法中new一个UserCollapseCommand对象进行测试
* 苦于没有好的办法做并发实验,这里就放在一个Controller中了
* 我们看到,在这个方法中用了三个UserCollapseCommand对象进行模拟高并发
*/
@GetMapping("/collapse")
public List<User> collapseTest(){
LOGGER.info("==========>collapseTest方法执行了");
List<User> userList = new ArrayList<>();
Future<User> queue1 = new UserCollapseCommand(service, 1L).queue();
Future<User> queue2 = new UserCollapseCommand(service, 2L).queue();
Future<User> queue3 = new UserCollapseCommand(service, 3L).queue();
try {
User user1 = queue1.get();
User user2 = queue2.get();
User user3 = queue3.get();
userList.add(user1);
userList.add(user2);
userList.add(user3);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
return userList;
}
/**
* 同步方法测试合并请求
*
* 说明:这个方法是用来与上面的方法做类比的,通过这个实验我们发现如果使用同步方法,
* 那么这个请求合并的作用就没有了,这会给findAll方法造成性能浪费
*/
@GetMapping("synccollapse")
public List<User> syncCollapseTest(){
LOGGER.info("==========>syncCollapseTest方法执行了");
List<User> userList = new ArrayList<>();
User user1 = new UserCollapseCommand(service, 1L).execute();
User user2 = new UserCollapseCommand(service, 2L).execute();
User user3 = new UserCollapseCommand(service, 3L).execute();
userList.add(user1);
userList.add(user2);
userList.add(user3);
return userList;
}
测试:
1)异步测试
postman访问 http://localhost:8088/hystrix/collapse
服务提供者的输出:
2018-05-22 13:11:46.718 INFO 9372 --- [io-8080-exec-10] c.c.h.controller.GetRequestController : =========getUsersByIds方法:入参ids:[1, 2, 3]
[user:{name: person1, sex: 男, phone: 123-1 }, user:{name: person2, sex: 男, phone: 123-2 }, user:{name: person3, sex: 男, phone: 123-3 }]
异步请求合并成功!
2)同步测试
postman访问 http://localhost:8088/hystrix/synccollapse
服务提供者的输出:
2018-05-22 13:13:22.195 INFO 9372 --- [nio-8080-exec-8] c.c.h.controller.GetRequestController : =========getUsersByIds方法:入参ids:[1]
[user:{name: person1, sex: 男, phone: 123-1 }]
2018-05-22 13:13:22.295 INFO 9372 --- [nio-8080-exec-1] c.c.h.controller.GetRequestController : =========getUsersByIds方法:入参ids:[2]
[user:{name: person2, sex: 男, phone: 123-2 }]
2018-05-22 13:13:22.393 INFO 9372 --- [nio-8080-exec-5] c.c.h.controller.GetRequestController : =========getUsersByIds方法:入参ids:[3]
[user:{name: person3, sex: 男, phone: 123-3 }]
异步请求合并失败!
2、注解方式
扩充RibbonService
/**注解方式实现请求合并**/
/**
* 被合并请求的方法
* 注意是timerDelayInMilliseconds,注意拼写
*/
@HystrixCollapser(batchMethod = "findAllByAnnotation",collapserProperties = {@HystrixProperty(name = "timerDelayInMilliseconds",value = "100")})
public Future<User> findOneByAnnotation(Long id){
//你会发现根本不会进入这个方法体
LOGGER.info("findOne方法执行了,ids= "+id);
return null;
}
/**
* 真正执行的方法
*/
@HystrixCommand
public List<User> findAllByAnnotation(List<Long> ids){
LOGGER.info("findAll方法执行了,ids= "+ids);
User[] users = restTemplate.getForObject("http://eureka-service/users?ids={1}", User[].class, StringUtils.join(ids, ","));
return Arrays.asList(users);
}
扩充RibbonController调用findOneByAnnotation()
/**
* 注解方式的请求合并
*
* 这里真想不出怎么去测试 这个方法了,有什么好的并发测试框架请自测吧,如果找到这种神器
* 请给我发邮件告诉我: hellxz001@foxmail.com
*/
@GetMapping("/collapsebyannotation/{id}")
public User collapseByAnnotation(@PathVariable Long id) throws ExecutionException, InterruptedException {
Future<User> one = service.findOneByAnnotation(id);
User user = one.get();
return user;
}
找到好用的测试工具记得联系我:hellxz001@foxmail.com ,在下在此感激不尽!
结束:
好了,这就是Hystrix请求合并的部分我所分享的,如果文章中有错误的地方及建议,还望评论指出。
引用:
理论部分来自:《SpringCloud微服务实战》作者:翟永超
实践部分参考官方文档:https://github.com/Netflix/Hystrix/wiki/How-To-Use#Collapsing
以及:Hystrix请求合并

 浙公网安备 33010602011771号
浙公网安备 33010602011771号