
Spring简介
spring是分层的avaSE以及javaEE应用于全栈的轻量级开源框架,以IOC(Inverse Of Control)控制反转,AOP(Aspect Oriented Programing)面向切面编程为核心,提供表现层SpringMVC以及持久层Spring,并且可整合多种其他开源框架。
spring的本质是管理对象,包括创建对象及维护对象之间的关系。
Spring优点
1)方便解耦,简化开发
设计有一个基本原则,即高内聚低耦合,即类的职责越单一越好,并且对类进行维护时,避免"牵一发动全身"的情况。并且开发时也只需关注上层的应用,不用再多关注底层的应用。
2)AOP编程的支持
spring支持AOP面向切面编程,许多OOP面向对象编程不能或很难实现的功能,都可通过AOP轻松实现。
3)声明式事务的支持
可以将我们从单调烦闷的事务管理中解放出来,通过声明式事务的方式,可以灵活的进行事务管理,进而提高开发的质量和效率。
4)方便程序的测试
可以用非容器依赖的编程方式进行几乎所有的测试工作,测试不再是昂贵的操作,而是随手可做的事情。
5)方便集成各种优秀的框架
Spring可以降低各种框架的使用难度,提供了对各种优秀框架(Struts、Hibernate、Hessian、Quartz等)的直接支持。
6)降低javaEE的API的使用难度
Spring对 JavaEE API(如 JDBC、JavaMail、远程调用等)进行了薄薄的封装层,使这些API 的使用难度大为降低。
7)spring框架的源码是经典学习的案例
Spring的源代码设计精妙、结构清晰、匠心独用,处处体现着大师对Java设计模式灵活运用以及对 Java技术的高深造诣。它的源代码无疑是Java技术的最佳实践的范例。
8)非侵入式设计
Spring是一种非侵入式(non-invasive)框架,它可以使应用程序代码对框架的依赖最小化。
Spring的缺点:
发展得太久之后,违背原理的理念,配置十分繁琐,被称为“配置地狱”。
1,中断了应用程序的逻辑,使代码变得不完整,不直观。此时单从Source无法完全把握应用的所有行为。
2、将原本应该代码化的逻辑配置化,增加了出错的机会以及额外的负担。
3、时光倒退,失去了IDE的支持。在目前IDE功能日益强大的时代,以往代码重构等让人头痛的举动越来越容易。
而且IDE还提供了诸多强大的辅助功能,使得编程的门槛降低很多。通常来说,维护代码要比维护配置文件,或者配置文件+代码的混合体要容易的多。
4、调试阶段不直观,后期的bug对应阶段,不容易判断问题所在。
5、spring像一个胶水,将框架黏在一起,后面拆分的话就不容易拆分了。
如何理解 IOC控制反转,DI依赖注入?
理解好Ioc的关键是要明确:谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了?
所谓控制反转:
在传统的开发中,我们需要一个实例,都是需要自己new出一个对象,这样的程序不仅耦合度极高,而且也不利于开发。简单来说,如果有需求,则是需要我们自己修改代码,这样的操作是开发中的大忌!
而 IOC,则是帮我们创建对象,不需要我们去new出来了,并且把整个对象的生命周期交给 Spring容器中管理。而创建对象等一系列过程就不需要我们去操心了!!而我们只关心配置文件的修改和业务的实现。
简单来说,对象的控制权由程序员反转给交给Spring程序来管理!而 IOC控制反转的手段就是 依赖注入(当然,Java中还有其他的手段注入:构造器注入,setter方法注入,接口注入!)
依赖注入:
Spring中的IOC是创建对象,但是这个对象是没有初值的。那么要怎么为对象赋初值呢?Spring中的依赖注入DI就解决了这个问题。 DI是Dependency Injection的缩写,依赖注入的意思,依赖了Spring容器,进行set注入!
依赖注入的类型有:基本数据类型, 字符串类型,引用类型,集合类型。
依赖注入的方式:
首先需要有一个类供spring容器创建对象,同时这个实体类要求有set()方法,也可以通过lombok插件,使用注解完成get、set方法和构造方法的自动生成
在spring配置文件中的<bean></bean>标签内编写属性值(基本类型属性的赋值)。在这个标签之内一般都是以 map 集合的形式来存储对象的(其中 ref 是引用别的对象的内容):
<beans>
<bean id = "user" class="com.xxx.userDao.User">
<property name="id" value="2">
<property name="nama" value="张三">
<property name="age" value="18">
<property name="className" ref="计算机2班">
</bean>
</beans>
对 IOC 深层次的理解
Spring中的 org.springframework.beans包和 org.springframework.context 包构成了Spring框架,BeanFactory 接口提供了一个先进的机制,使得任何类型的对象的配合成为了可能!BeanFactory applicationContext
BeanFacotry是spring中比较原始的Factory。如XMLBeanFactory就是一种典型的BeanFactory。原始的BeanFactory无法支持spring的许多插件,如AOP功能、Web应用等。
ApplicationContext接口,它由BeanFactory接口派生而来,因而提供BeanFactory所有的功能。ApplicationContext以一种更向面向框架的方式工作以及对上下文进行分层和实现继承,ApplicationContext包还提供了以下的功能:
• MessageSource, 提供国际化的消息访问
• 资源访问,如URL和文件 (统一的资源文件读取方式)
• 事件传播 ,有强大的事件机制(Event)
• 载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层
BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化,这样,我们就不能发现一些存在的Spring的配置问题。
而ApplicationContext则相反,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误。 相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。
当应用程序配置Bean较多时,程序启动较慢。
注意:IoC把Bean对象的创建,初始化,销毁等生命周期交给Spring来管理,而不是开发者,这就是真正的实现了控制反转
个人认为:获得依赖对象的方式反转了!
BeanFactory和ApplicationContext之间的区别
BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用!
两者之间的区别是:
- 两者都支持beanpostProcessor
- BeanFactory需要手动注册,而ApplicationContext则是自动注册。
- BeanFactroy采用的是懒加载的形式来注入Bean的,而applicationContext是即时加载的
BeanFactory 可以理解是 Bean 集合的工厂类,BeanFactory 包含了Bean的定义,以便咋接收到客户端请求时将对应的Bean实例化。BeanFactory 还能在实例化对象的时候生成协作类之间的关系。此举将 Bean 自身与 Bean 客户端的配置中解放出来,BeanFactory 还包含了 Bean生命周期的控制,调佣客户端的初始方法(initialization methods)和销毁方法(destruction methods)。
从表面上看,applicationContext 如同 BeanFactory 一样具有 Bean 的定义,Bean 关联关系的设置,根据请求分发 Bean 的功能,但 applicationContext 在此基础之上还提供了其他功能!
支持国际化的文本消息
统一资源文件的读取方式
已在监听器中注册 Bean 的实例
Spring中有几种配置方式
将Spring配置到开发应用中有一下三张方式:
- 基于 xml文件的配置
- 基于注解的配置
- 基于Java的配置
请讲一下SpringBean的生命周期以及循环依赖问题
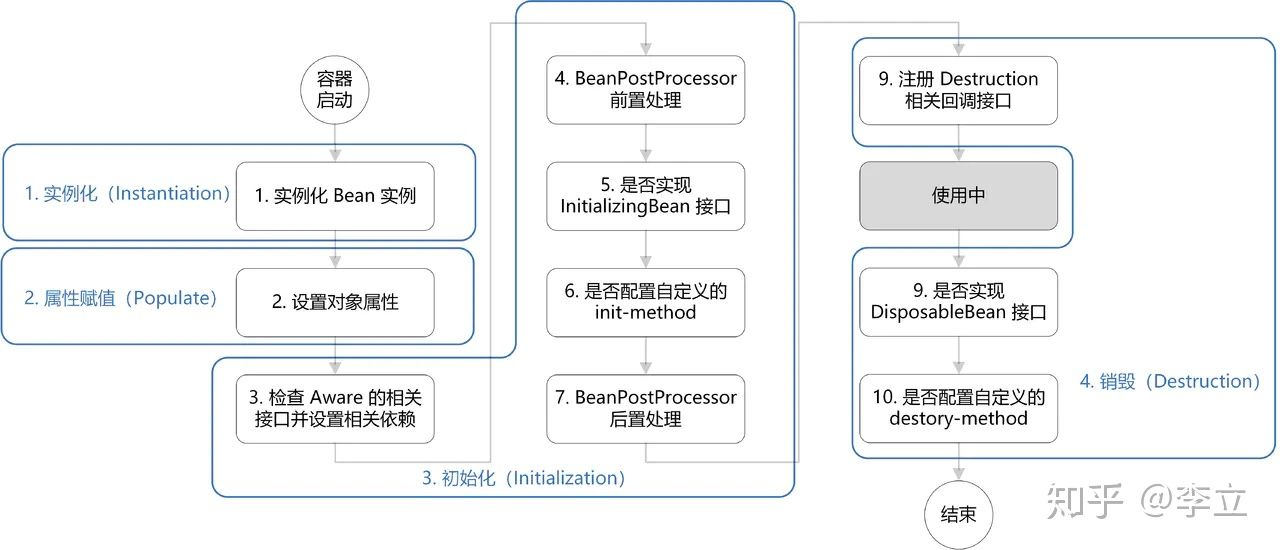
对象创建
1,从xml配置的Bean,@Bean注解,或者Java代码BeanDefinitionBuilder中读取Bean的定义,实例化Bean对象;
2,设置Bean的属性;
3,注入Aware的依赖(BeanNameAware,BeanFactoryAware,ApplicationContextAware);
4, 执行通用的方法前置处理,方法: BeanPostProcessor.postProcessorBeforeInitialization()
5, 执行 InitalizingBean.afterPropertiesSet() 方法
6,执行Bean自定义的初始化方法init,或者 @PostConstruct 标注的方法;
7,执行方法BeanPostProcessor.postProcessorAfterInitialization()
8, 创建对象完毕;
对象销毁
9, 执行 DisposableBean.destory() 方法;
10,执行自定义的destory方法或者 @PreDestory 标注的方法;
11,销毁对象完毕
Bean的作用域:
启动spring容器,也就是创建beanFactory(bean工厂),
一般用的是beanFactory的子类applicationcontext,
applicationcontext比一般的beanFactory要多很多功能,比如aop、事件等。
通过applicationcontext加载配置文件,或者利用注解的方式扫描将bean
的配置信息加载到spring容器里面。
2、 加载之后,spring容器会将这些配置信息(java bean的信息),封装成BeanDefinition对象
BeanDefinition对象其实就是普通java对象之上再封装一层,
赋予一些spring框架需要用到的属性,比如是否单例,是否懒加载等等。
3、 然后将这些BeanDefinition对象以key为beanName,
值为BeanDefinition对象的形式存入到一个map里面,
将这个map传入到spring beanfactory去进行springBean的实例化。
4、 传入到pring beanfactory之后,利用BeanFactoryPostProcessor接口这个扩展点
去对BeanDefinition对象进行一些属性修改。
5、 开始循环BeanDefinition对象进行springBean的实例化,springBean的实例化也就
是执行bean的构造方法(单例的Bean放入单例池中,但是此刻还未初始化),
在执行实例化的前后,可以通过InstantiationAwareBeanPostProcessor扩展点
(作用于所有bean)进行一些修改。
6、 spring bean实例化之后,就开始注入属性,
首先注入自定义的属性,比如标注@autowrite的这些属性,
再调用各种Aware接口扩展方法,注入属性(spring特有的属性),
比如BeanNameAware.setBeanName,设置Bean的ID或者Name;
7、 初始化bean,对各项属性赋初始化值,,初始化前后执行BeanPostProcessor
(作用于所有bean)扩展点方法,对bean进行修改。
初始化前后除了BeanPostProcessor扩展点还有其他的扩展点,执行顺序如下:
(1). 初始化前 postProcessBeforeInitialization()
(2). 执行构造方法之后 执行 @PostConstruct作用的方法(@PostConstruct注解)
(3). 所有属性赋初始化值之后 afterPropertiesSet()
(4). 初始化时 配置文件中指定的 init-method 方法
(5). 初始化后 postProcessAfterInitialization()
先执行BeanPostProcessor扩展点的前置方法postProcessBeforeInitialization(),
再执行@PostConstruct标注的方法
所有属性赋值完成之后执行afterPropertiesSet()
然后执行 配置文件或注解中指定的 init-method 方法
最后执行BeanPostProcessor扩展点的后置方法postProcessAfterInitialization()
8、 此时已完成bean的初始化,在程序中就可以通过spring容器拿到这些初始化好的bean。
9、 随着容器销毁,springbean也会销毁,销毁前后也有一系列的扩展点。
销毁bean之前,执行@PreDestroy 的方法,再执行重写DisposableBean接口的destroy方法
最后销毁时,执行配置文件或注解中指定的 destroy-method 方法。
Spring Bean 的作用域之间有什么区别?
Spring容器中的Bean可以分为 5 个实例,所有范围的名称都是自说明的,但是为了避免混淆还是让我们来解释一些吧!
- singleton:这种 Bean 容器是默认的,这种范围不管接受多少个请求,每个容器中只有一个Bean的实例,单例模式是由 BeanFactory 自身来维护。
- prototype:原型范围与单例范围相反,为每个Bean的请求提供一个实例。
- request:在请求Bean范围内会每一个来自客户端的网络请求创建一个实例,在请求完成以后,Bean 会失失效并被垃圾回收期回收。
- Session:与请求范围类似,确保每一个Session中有一个Bean的实例,在Session过期后,Bean会随之消失。
- global-Session:global-Session和Portlet应用相关,当你的应用部署在Portlet容器中工作时,它包含很多portlet。如果你想要声明让所有的portlet公用全局的存储变量的话,那么这个全局变量需要存储在global-Session中。全局作用域与servlet中的Session作用域效果相同。
Sring容器中的单例 Bean 是线程安全吗?
Spring框架并没有对单例Bean进行任何多线程的封装处理,关于单例Bean的线程安全和并发问题需要开发者自行去搞定。但实际上,大部分的SpringBean并没有任何可变的状态(例如Serview,DAO)。
所以在某种程度上说Spring 的单例 Bean 是线程安全的。如果你的 Bean 有多种状态的话(比如,View Model 对象),就需要自行保证线程安全。最显现的解决办法就是将多态 Bean 的作用域由 “singleton”变为“prototype”
什么是Spring中的循环依赖
循环依赖就是循环引用,也就是两个或者两个以上的Bean相互持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。
Spring处理循环依赖的机制
无法解决的循环依赖问题:
单例Bean构造函数的循环依赖
prototype原型的循环依赖 (对与原型Bean的初始化过程中不论是通过构造器参数循环依赖还是通过setXxx方法产生循环依赖,Spring都会直接报错处理BeanCurrentlyInCreationException)
构造器的循环依赖问题⽆法解决,只能拋出 BeanCurrentlyInCreationException 异常
解决单例Bean的属性注入的循环依赖问题
原理
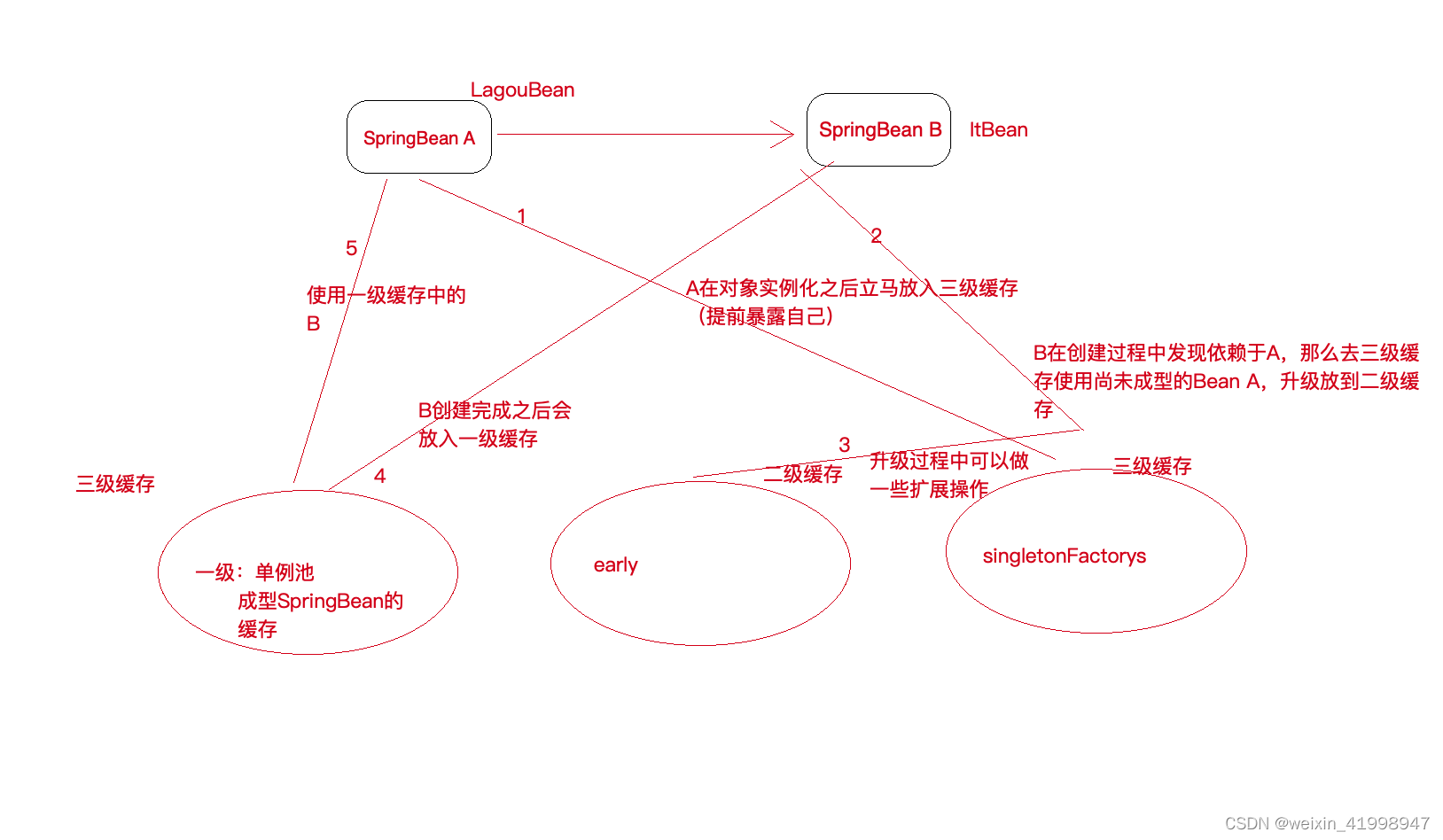
在解决属性循环依赖时,spring采⽤的是提前暴露对象的⽅法。Spring 的循环依赖的理论依据基于 Java 的引⽤传递,当获得对象的引⽤时,对象的属性是可以延后设置的,但是构造器必须是在获取引⽤之前。Spring通过setXxx或者@Autowired⽅法解决循环依赖其实是通过提前暴露⼀个ObjectFactory对象来完成的,简单来说ClassA在调⽤构造器完成对象初始化之后,在调⽤ClassA的setClassB⽅法之前就把ClassA实例化的对象通过ObjectFactory提前暴露到Spring容器中。
Spring容器初始化ClassA通过构造器初始化对象后提前暴露到Spring容器。
ClassA调⽤setClassB⽅法,Spring⾸先尝试从容器中获取ClassB,此时ClassB不存在Spring
容器中。
Spring容器初始化ClassB,同时也会将ClassB提前暴露到Spring容器中
ClassB调⽤setClassA⽅法,Spring从容器中获取ClassA ,因为第⼀步中已经提前暴露了
ClassA,因此可以获取到ClassA实例
ClassA通过spring容器获取到ClassB,完成了对象初始化操作。
这样ClassA和ClassB都完成了对象初始化操作,解决了循环依赖问题。
Spring源码分析循环依赖问题
准备:创建了两个Bean,#CircularReferenceBean和#ItBean,两个bean相互依赖,通过setXxx方法进行注入。
1、以new ClassPathXmlApplicationContext("classpath:applicationContext.xml")为入口进行源码跟踪。进入到AbstractBeanFactory#doGetBean方法,获取Bean。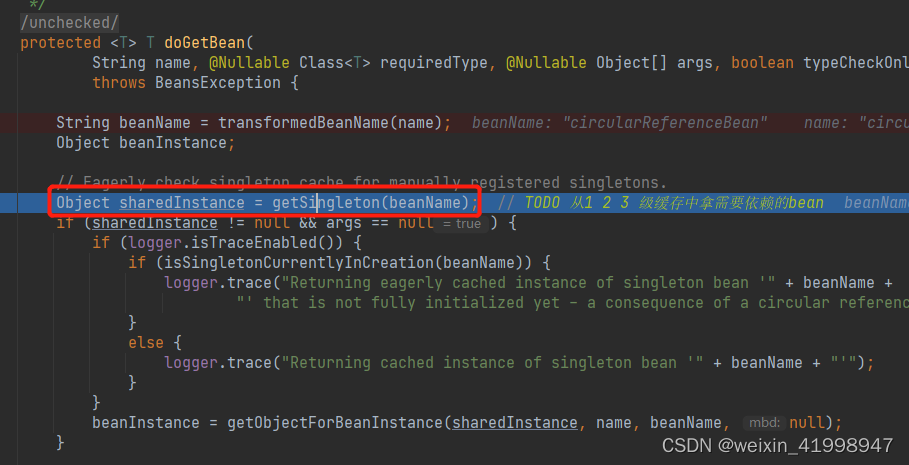
先1 2 3 级缓存中拿bean,如果没有拿到,则创建。具体的逻辑如下
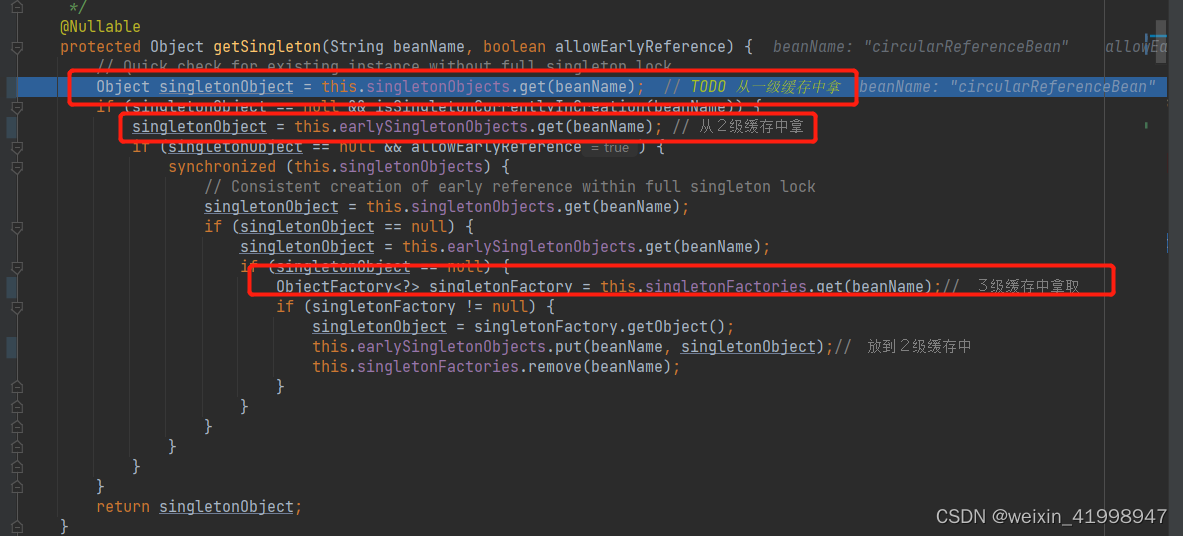
由于是第一次创建CircularReferenceBean,所以缓存中并没有,需要创建,走下面流程,解析bean标签里面的依赖信息,然后调用创建bean的方法。AbstractBeanFactory#doGetBean.getSingleton(),进入createBean方法,查看具体的创建逻辑。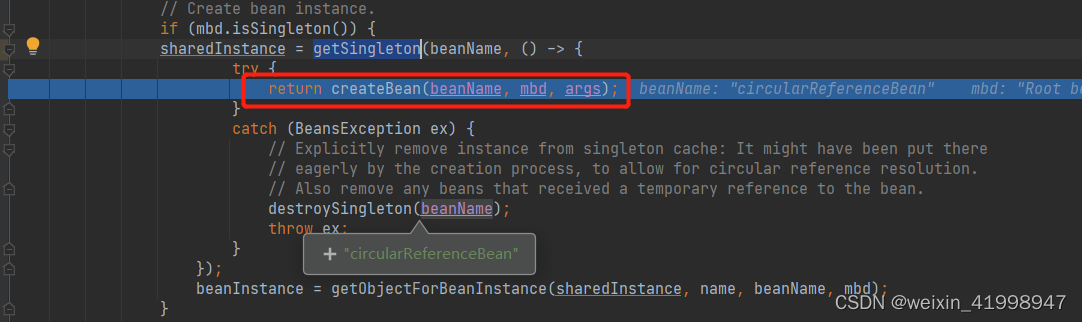
先判断是否需要先将bean放入到三级缓存中,如果是需要则将bean放入三级缓存,注意,此时的bean还没有初始化完成的。里面的属性信息都没有进行赋值。进入populateBean()方法对Bean进行属性的装配,这里面完成对bean中注入属性的分析和赋值。进入方法,主要关注这一段代码。
可以看到 CircularReferenceBean创建的时候需要注入一个id为ItBean的bean。进入applyPropertyValues方法,看看如何获取需要的属性的。AbstractAutowireCapableBeanFactory#applyPropertyValues方法中调用BeanDefinitionValueResolver#resolveValueIfNecessary方法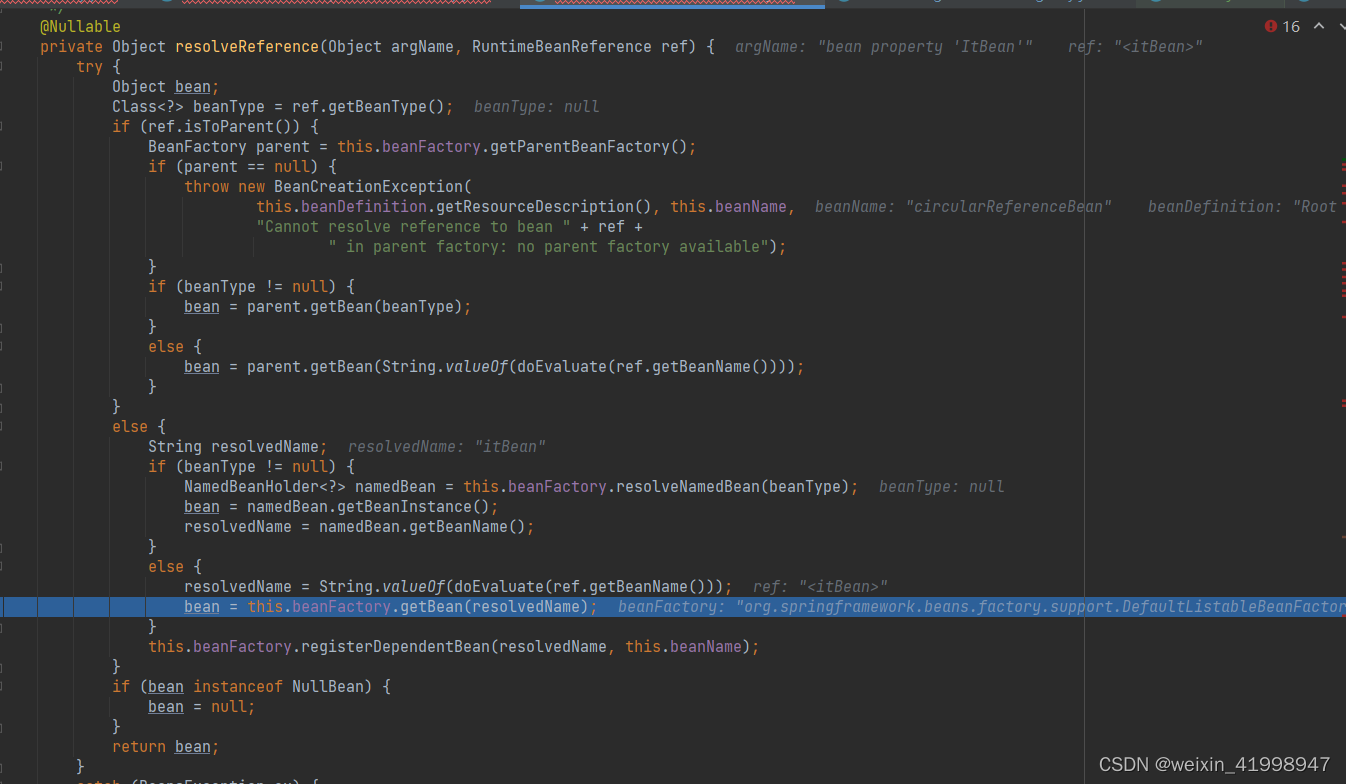
进入resolveReference方法,方法中最终通过getBean的方法获取所需要的ItBean。进入方法,可以看到创建ItBean和创建CircularReferenceBean的方法一样,都进入到了doCreateBean方法。创建ItBean的流程跟上面流程完全一致,创建的时候发现ItBean依赖CircularReferenceBean则跟上述流程一样getBean方法获取CircularReferenceBean,并进入到doCreateBean方法中,但是这个时候由于CircularReferenceBean是被放入到三级缓存中的,所以可以再三级缓存中直接获取到,并且将CircularReferenceBean放到2级缓存中。这样ItBean就创建成功了,CircularReferenceBean也可以正常依赖ItBean。
Spring中用到了哪些设计模式
1、工厂模式。
Spring的BeanFactory类,就是使用了简单工厂模式。它主要提供getBean()方法,用来创建对象的实例;我们见得比较多的ApplicationContext也是继承自BeanFactory。
2、单例模式。
Spring中的Bean默认为singleton单例。我们可以通过配置Bean的作用域scope参数来进行修改。Spring Bean一共有5种内置的作用域,分别是singleton、prototype、request、session、globalSession。
3、适配器模式。
在Spring,只要是以Adapter命名的类基本都是适配器模式的应用。比如MVC模块中的HandlerAdapter。
4、代理模式。
比如AOP模块中的AopProxy,用到了JDK的动态代理和CGLIB字节码生成技术;
5、模板方法模式。
主要用来解决代码重复的问题。Spring提供了非常多的模板类来减少重复代码,基本都是以Template结尾,比如RestTemplate,JmsTemplate,JdbcTemplate。
6、观察者模式。
主要用于当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知,在Spring中一般以Listener结尾,比如ApplicationListener等等。
当然,Spring是一个非常经典的框架,它用的的设计模式也非常多。而且很多设计模式经常是混合使用的,都是你中有我,我中有你。所以,我们在阅读代码的时候,还不能简单地断定某个类就一定是只用了某一种设计模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号