IO分类
IO分类
阻塞IO:去读数据时,有数据就读完返回,没数据就一直傻等到有数据,再读完返回。期间什么事也做不了。
非阻塞IO:去读数据时,有数据就读完返回,没数据就不读直接返回。
例子:
- 阻塞IO:你打开邮箱,发现是空的。于是你就一直站在邮箱旁边等着,直到邮递员送来新邮件,你取出邮件后才离开。在这期间你什么别的事都做不了。
- 非阻塞IO:你打开邮箱,用手摸一下(执行一次read调用)。
- 如果有邮件(有数据),你就拿走,然后离开(返回读取的字节数)。
- 如果是空的(没数据),你立刻关上邮箱门,直接离开(返回0),然后你可以去浇花、看电视(执行其他业务逻辑),过一会儿再来检查一次。
非阻塞IO结合Selector使用:单纯的非阻塞IO效率并不高,因为你需要不断地“摸邮箱”(循环调用read),这会造成空循环,浪费CPU。因此,它总是和Selector(多路复用器) 搭配使用:
- Selector 负责告诉你:“哪个邮箱可能有邮件了”(哪个通道就绪了),从而避免了盲目地“轮询摸邮箱”。
- 非阻塞IO 负责执行:“我去摸一下那个邮箱”(对该通道执行read操作)。
| 模式 | 描述 | 线程行为 | 例子 |
|---|---|---|---|
| 同步阻塞IO (BIO) | 最传统的IO模型。发起read操作后,线程一直阻塞,直到数据准备好并且从内核拷贝到用户空间。 | 全程阻塞 | Java InputStream.read() |
| 同步非阻塞IO (NIO) | 发起read操作后,如果数据没准备好,内核立即返回一个错误(EWOULDBLOCK),线程不会阻塞。线程需要不断轮询(循环调用read)来检查数据是否就绪。 | 轮询(忙等待) | 将Socket设置为 non-blocking 后循环调用 read |
| IO多路复用 (IO Multiplexing) | 这是Java NIO使用的模型。 select/poll/epoll 帮我们阻塞地监听多个通道。当某个通道数据就绪后,应用程序仍然需要自己调用read操作,将数据从内核同步地拷贝到用户空间。 | 在select()上阻塞,在read()上非阻塞 | Java NIO (Selector.select(), Channel.read()) |
同步:线程自己去获取结果(一个线程) 。
- 线程1发起读请求,线程1等待内核线程准备好数据(最耗时的操作),线程1自己将数据从内核空间拷贝到用户空间(相对耗时的操作),然后返回。
异步:线程自己不去获取结果,而是由其它线程送结果(至少两个线程)。
- 线程1发起读请求(并提供一个存放数据的缓冲区和一个回调函数),线程1直接返回。内核线程不仅负责准备好数据,还负责将数据从内核空间拷贝到用户空间提供的缓冲区中。完成所有工作后,内核通知框架,由框架内部的某个线程(线程2)来调用预先注册的回调函数。此时,数据已经躺在缓冲区里了,回调函数是直接使用数据,而不是再去‘获取’数据。
总结:
- 阻塞 vs. 非阻塞:关注的是调用者线程的状态。发起IO调用后,线程是否被挂起(阻塞)还是立即返回(非阻塞)。
- 同步 vs. 异步:关注的是消息通知机制和数据拷贝工作由谁完成。同步需要调用者主动询问或等待结果,异步则由被调用方主动通知结果(通常通过回调),且数据拷贝工作由内核完成。
IO模型总结对比表
| 模型 | 核心思想 (比喻:取快递) | 等待数据阶段 (阶段一) | 数据拷贝阶段 (阶段二) | 优点 | 缺点 | 代表 |
|---|---|---|---|---|---|---|
| 同步阻塞 (BIO) | 你自己下单,然后一直站在门口等,拿到快递才回家。 | 线程阻塞 | 线程同步拷贝 | 编程简单、直观 | 性能极差,资源浪费严重,1线程对应1连接 | Java InputStream.read() |
| 同步非阻塞 (NIO式轮询) | 你下单后,不停跑下楼看快递到没到,没到就回家干点别的。 | 线程轮询 (非阻塞) | 线程同步拷贝 | 线程不会在等待时完全卡死 | 轮询消耗大量CPU,效率依然很低 | socket.setNonBlocking(true) 后循环调用 read |
| IO多路复用 (NIO) | 你有很多快递。你把所有单号给驿站(Selector)。驿站监控到有快递到了就打电话叫你,你再下楼拿。 | 在Selector上阻塞 (高效) | 线程同步拷贝 | 1个线程可处理大量连接,性能高 | 编程复杂,数据拷贝仍由应用线程同步进行 | Java NIO (Selector), select, poll, epoll |
| 异步非阻塞 (AIO) | 你下单时就把家门密码给快递员。快递员送到后直接开门把快递放桌上,然后发短信通知你。 | 内核处理 (非阻塞) | 内核异步拷贝 | 性能最高,应用线程完全不被IO阻塞 | 编程复杂(回调地狱),需要操作系统强力支持 | Java AIO, Windows IOCP |
| 异步阻塞 | 理论上存在但无实用价值。例如:调用一个异步方法,却又傻傻地去等待它的回调完成。 | - | - | - | 结合了两者的缺点 | 无实际应用 |
核心区别详解
1. 同步阻塞 (BIO)
- 过程:线程调用
read()-> 内核数据未准备好人 -> 线程被挂起(阻塞) -> 内核数据准备好 -> 线程被唤醒,将数据从内核拷贝到用户空间 ->read()返回。 - 区别:全程同步且全程阻塞。是最简单也是最低效的模型。
2. 同步非阻塞 (轮询式NIO)
- 过程:线程调用
read()-> 内核数据未准备好 -> 立即返回错误(EWOULDBLOCK)-> 线程循环调用read()直到成功。 - 区别:等待阶段非阻塞,但拷贝阶段同步。通过轮询避免线程挂起,但CPU空转严重。
3. IO多路复用 (如Java NIO)
- 过程:线程将多个通道注册到Selector -> 调用
selector.select()阻塞 -> 当有通道就绪时,select()返回 -> 线程遍历就绪通道,同步地调用read()拷贝数据。 - 区别:等待阶段是高效的阻塞(代理),拷贝阶段同步。它的“非阻塞”指的是SocketChannel的行为(
read()立即返回),但管理它们的线程在select()上是阻塞的。这是同步IO的一种高效实现形式。
4. 异步非阻塞 (AIO)
- 过程:线程调用
aio_read(),传入一个缓冲区和回调函数 -> 方法立即返回 -> 线程去做别的事 -> 内核完成数据等待和拷贝到缓冲区的所有工作 -> 内核主动调用回调函数通知应用程序。 - 区别:从等待到拷贝,整个IO过程都是异步的,由内核完成。应用程序线程在整个过程中完全没有阻塞,也无需参与数据拷贝。这是真正的异步IO。
5. 异步阻塞 (理论模型)
- 这个概念本身是矛盾的,但可以理解为一个奇怪的行为:比如,你发起了异步调用,但却不使用回调机制,而是愚蠢地用一个循环去不停地检查一个
Future.isDone(),这相当于把异步调用又变成了同步阻塞。
终极结论
- 判断同步/异步的标准:看数据从内核空间拷贝到用户空间这一步是由应用程序线程完成(同步)还是由内核完成(异步)。
- 判断阻塞/非阻塞的标准:看发起IO调用后,应用程序线程是否被挂起。
因此,Java NIO(多路复用)属于同步IO,因为应用程序线程需要自己调用 read() 来拷贝数据。 它之所以高性能,是因为它用Selector高效地解决了“如何知道多个连接中谁有数据可读了”这个管理性问题,但最终的数据搬运工还是应用程序自己。
不管是什么类型的IO,阻塞说的是等待数据阶段,数据拷贝阶段是没有阻塞的说法的?
是的,无论是什么类型的IO(阻塞、非阻塞、多路复用、异步),我们所说的 “阻塞”,特指的是线程在 “等待数据可读/可写” 这个阶段的状态。
而 “数据拷贝” 阶段(将数据从内核缓冲区复制到用户缓冲区,或反之)是一个积极的、消耗CPU的动作,它本身不是一个等待过程,因此不适用“阻塞”这个词。
为什么数据拷贝不叫“阻塞”?
我们可以从两个层面理解:
- 从线程状态看:
- 等待数据:线程因为等待一个外部事件(网络包到达、磁盘寻道完成)而无法继续执行,操作系统会将其置为睡眠状态(Sleeping),不分配CPU时间片。这是被动的。
- 数据拷贝:线程是活跃状态(Running),正在执行指令(内存复制指令),全力占用CPU进行计算。这是主动的。
- 从耗时特性看:
- 等待数据:耗时不确定且可能很长(几毫秒到几秒),取决于网络延迟、磁盘速度等外部因素。
- 数据拷贝:耗时相对确定且较短,取决于数据量和内存带宽,是纯硬件速度。
各IO模型在两个阶段的对比
让我们用这个结论来重新审视所有IO模型,您会发现一切变得异常清晰:
IO模型 等待数据阶段 数据拷贝阶段 总体评价 同步阻塞 (BIO) 线程阻塞(睡眠) 线程同步拷贝(工作) 线程在等待时浪费资源 同步非阻塞 (轮询) 线程轮询(忙等待,消耗CPU) 线程同步拷贝(工作) 等待阶段空转CPU,效率低 多路复用 (NIO) 在Selector上阻塞(高效等待) 线程同步拷贝(工作) 高效管理等待,但拷贝活还得自己干 异步IO (AIO) 内核处理(线程不关心) 内核异步拷贝(线程不关心) 最理想,两个阶段都不占用应用线程 注意:上表中的“同步拷贝”和“异步拷贝”是决定模型是同步IO还是异步IO的最终判断标准。
- 同步IO (BIO, NIO):拷贝工作必须由应用程序线程亲自发起并完成(拷贝工作是程序线程获得更高的权限变成内核线程后进行的)。
- 异步IO (AIO):拷贝工作由内核发起并完成,然后通知应用程序。
Linux IO 和 Java IO
理解这个关系至关重要:
Linux I/O (内核空间) <---(JVM 封装)---> Java I/O (用户空间)
Java 的各类 I/O 模型(BIO, NIO, AIO)其底层实现最终都依赖于操作系统(Linux)提供的相应机制。
Linux I/O (内核空间) :同步阻塞 I/O (BIO)、同步非阻塞 I/O (NIO)、I/O 多路复用 (select, poll, epoll)、信号驱动 I/O(半异步/信号通知)、异步非阻塞 I/O (AIO)
Java I/O (用户空间):BIO (传统 IO)、NIO (New IO)、NIO.2 (AIO)
-
模型 包路径 核心抽象 编程模式 特点 首次出现版本 BIO java.io.*流 (Stream) + Socket 同步阻塞 一个连接一个线程,简单但性能瓶颈明显 JDK 1.0 (1996年) NIO java.nio.channels.*通道 (Channel) + 缓冲区 (Buffer) + 选择器 (Selector) 同步非阻塞+多路复用 一个线程处理多个连接,高性能网络编程基础 JDK 1.4 (2002年) AIO (NIO.2) java.nio.channels.*异步通道 (AsynchronousChannel) + 回调 (CompletionHandler) 异步 由操作系统完成后通知,目前应用较少 JDK 7 (2011年) 简单记忆:
java.io是 BIO,是老祖宗。java.nio是 NIO 和 AIO 的家,其中channels子包是核心。- 以
Channel,Buffer,Selector为核心的是 NIO。 - 以
Asynchronous开头的类为核心的是 AIO。
- 以
详细模型对比
1. 阻塞 I/O (BIO)
- Linux: 最基本的
read,write调用,默认就是阻塞的。 - Java:
java.io包,如Socket.getInputStream().read()。一个连接需要一个线程,并发能力受线程数限制。 - 关系: Java BIO 就是对 Linux 阻塞 I/O 的系统调用的简单封装。
2. 非阻塞 I/O (NIO)
- Linux: 通过
fcntl(fd, F_SETFL, O_NONBLOCK)设置文件描述符为非阻塞模式。调用read时若无数据则立即返回EAGAIN错误。 - Java:
java.nio.channels包。通过SocketChannel.configureBlocking(false)设置为非阻塞模式。需要与 Selector 结合才能发挥最大威力,否则需要不断轮询,浪费 CPU。 - 关系: Java NIO 的非阻塞模式就是对 Linux
O_NONBLOCK标志的封装。
3. I/O 多路复用
- Linux:
select,poll,epoll。核心是用一个线程/进程监听大量文件描述符的就绪状态。select/poll: 线性扫描,性能随 fd 数量增加而下降。epoll: 基于事件回调,性能极高,与 fd 数量无关。
- Java:
Selector类。其open()和select()等方法,在 Linux 平台上的实现就是基于epoll。Selector.select()->epoll_wait()Channel.register(selector, ...)->epoll_ctl(EPOLL_CTL_ADD/ MOD, ...)
- 关系: Java NIO 的 Selector 是 Linux epoll 机制在 Java 语言中的跨平台抽象。这是 Java 能够编写高性能网络应用的关键。
4. 异步 I/O (AIO)
- Linux: 提供了原生 AIO 接口 (
libaio,如io_submit,io_getevents),但主要对磁盘文件 I/O 优化得好,在网络编程中远不如 epoll 流行和稳定。 - Java:
java.nio.channels.AsynchronousChannel(NIO.2, JDK7+)。重要提示:在 Linux 上,Java AIO 的实现并未使用 Linux 的原生 AIO,而是使用了一个基于 epoll 的线程池来模拟异步效果!所以它的性能并不一定比 NIO+Selector 更好。 - 关系: Java AIO 提供了一个统一的异步编程模型,但在 Linux 上的底层实现与 Linux 原生 AIO 不同。
总结与选择建议
- 历史与基础:
- Java BIO 是对 Linux 阻塞 I/O 的简单封装。
- Java NIO 是对 Linux 非阻塞 I/O 和 epoll 多路复用 的封装和抽象。
- 性能之王:
- 在 Linux 上,epoll 是解决高并发网络 I/O 的事实标准。
- 因此,在 Java 中,NIO + Selector 是构建高性能网络应用(如 Netty、Tomcat NIO Connector)的首选和基石。
- 关于异步 I/O:
- 在 Linux 上,Java AIO 的实现并未使用 Linux 的原生 AIO,而是使用了一个基于 epoll 的线程池来模拟异步效果!所以它的性能并不一定比 NIO+Selector 更好。
- 不要被名字迷惑。在 Linux 平台,Java AIO (NIO.2) 并非真正的操作系统级异步。它的应用场景更多在文件 I/O 而非网络 I/O。
- 对于网络编程,反应堆模式 (Reactor) 基于 NIO + Selector 已经足够优秀和高效,是经过大规模验证的模式。
- 如何选择:
- 传统 BIO:仅适用于客户端或连接数非常少、开发速度要求高的内部服务。
- NIO (Selector):必须用于所有高并发服务器端开发。直接使用较复杂,通常通过Netty、Mina等框架来使用。
- AIO (NIO.2):在 Linux 上不推荐用于网络编程,优势不明显且生态不成熟。在 Windows 上(其 IOCP 是真正的异步)可能更有优势。
最终结论:理解 Linux epoll 是理解 Java NIO 高性能之源的关键。在 Linux 环境下进行Java服务端开发,NIO + Selector(或基于其的框架,如Netty)是绝对的主流和正确选择。
同步阻塞 I/O:read
同步阻塞 I/O:read(Socket A) -> 【线程1(用户版)】被OS挂起(阻塞) -> 数据到网卡 -> DMA硬件自动处理:拷贝数据到内核缓冲区 -> 【线程1(内核版)】被唤醒,拷贝数据到用户缓冲区空间 -> 【线程1(用户版)】读取buf数据 -> 【线程1(用户版)】处理数据。
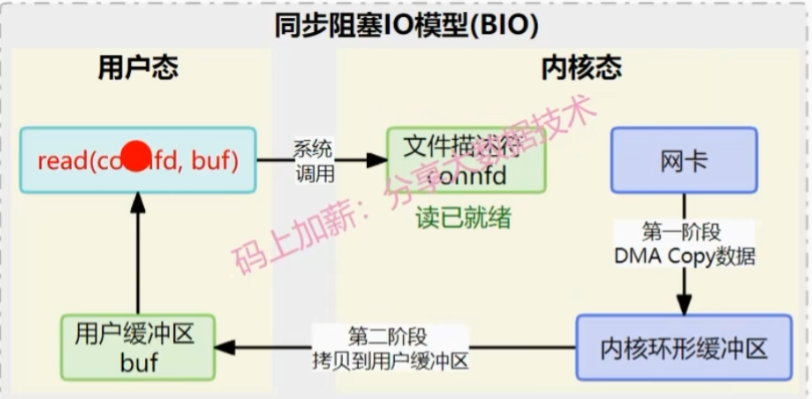
个人解读:
数据包 -> 内核缓冲区,是DMA硬件自动处理。
内核缓冲区 -> 用户缓冲区,是发起请求的用户线程获得更高的权限,执行内核代码完成。
- 也可以理解是用户线程获取更高权限后,变成用户线程黑化版,复制完成后,再变回原来的那个用户线程,对于原来这个用户线程来说,他不知道是自己黑化后复制了数据过来,只知道突然有了数据可读。
“用户线程黑化”全流程
- 普通用户线程 (天真善良版)
- 它在自己的世界里(用户态)快乐地运行着
printf、i++这些普通的指令。 - 它需要数据了,于是天真地调用了一句
read(fd, buf, size)。它以为这只是个普通函数调用。
- 它在自己的世界里(用户态)快乐地运行着
- 触发黑化 (召唤内核之力)
- 这句
read不是一个简单的函数,它是一个系统调用。这就像念了一句咒语,触发了CPU的特殊机制(如syscall指令)。 - CPU立刻响应:剥夺当前线程的用户态权限(Ring 3),赋予其最高的内核态权限(Ring 0)。
- 此刻,这个线程“黑化”了! 它不再执行应用程序的代码,它的灵魂被内核接管,开始执行内核中实现
read功能的那些强大而危险的代码。
- 这句
- 黑化线程的执行 (内核代行)
- 这个“黑化版”线程现在代表着内核的意志。它可以看到所有的内核数据结构和缓冲区。
- 它检查Socket的内核缓冲区,发现数据已经由D大哥(DMA)准备好了。
- 于是,它执行了最关键的一步:调用
memcpy等指令,将数据从内核缓冲区物理地拷贝到用户缓冲区buf中。 这个拷贝动作是黑化线程干的。 - 拷贝完成后,黑化线程还要更新一些状态,比如文件偏移量等。
- 净化恢复 (返回用户世界)
- 所有脏活累活干完了,系统调用走到了尽头。
- CPU再次执行特殊指令,收回内核态权限,将其权限降级回普通的用户态(Ring 3)。
- “黑化”状态解除! 线程的灵魂回来了,变回了那个“天真善良”的用户线程。
- 天真线程的视角 (毫不知情)
- 从它的视角看,刚才发生的一切就像一瞬间的事:它刚调用了
read(),这个函数就返回了,并且告诉自己成功读取了N个字节。 - 它低头一看,惊讶地发现数据已经整整齐齐地躺在
buf里了! - 它完全不知道中间发生过“黑化”,也不知道是自己(的黑化版)亲手拷贝了数据。它只会觉得:“哇,
read这个函数真厉害,一下就帮我把数据弄来了!” - 然后它开开心心地开始处理数据,对背后发生的一切毫不知情。
- 从它的视角看,刚才发生的一切就像一瞬间的事:它刚调用了
为什么这个比喻如此准确?
因为它完美地捕捉到了几个核心特征:
- 还是同一个线程:从头到尾,CPU核心都是在为这同一个线程服务。
- 权限和身份的彻底改变:“黑化”后,它执行的是内核的代码,拥有至高无上的权力,能做普通线程绝对做不到的事(比如直接访问硬件、操作所有内存)。
- 记忆的隔离:“净化”后,它对自己黑化时的行为一无所知(用户线程无法感知也无法干涉内核的执行过程)。
- 结果的继承:黑化的成果(用户缓冲区里的数据)留了下来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号