CPU缓存行(Cache Line)和MESI协议
CPU缓存行(Cache Line)和MESI协议
(1 封私信) CPU缓存行(Cache Line)详解:从原理到优化实践 - 知乎
在现代的计算机体系结构中,CPU的计算速度是远远高于内存访问速度的,因此 CPU 增加了缓存,以均衡与内存的速度差异。
计算机存储的层次
要了解Cache Line,首先需要知道计算机存储的层次,这个层次结构对于性能和成本的平衡(很多项目和设计都是取舍的结果),可以从下图来看,越上层速度越快,价格也就越高,其中L1,L2,L3 Cache都是在CPU内部

Cache Line读取流程
关于缓存读取的顺序,当CPU读取一个变量时,确实会先检查自己的缓存(通常是L1/L2/L3缓存)。现代CPU的缓存结构是这样的:
- 每个CPU核有自己独享的L1和L2缓存
- 多个核共享L3缓存(在大多数现代架构中)
- 最后才是主内存(DRAM)
读取顺序是:L1 → L2 → L3 → 主内存。如果某一级缓存命中,就不会继续往下查找。
读取流程整体来说:
- 就是从上往下依次检查是否存在,存在的话就直接使用,不存在就去下一级存储读取。
- 其中从内存到Cache的最小传输单位就是 Cache Line,对于现代CPU而言,一般是64字节,也就是说,即使只取一个字节数据也要映射64字节取到cache中,这体现了局部性的原理,当访问一个地址时,这个地址附近的内容近期大概率也会被访问到。
Cache Line一致性
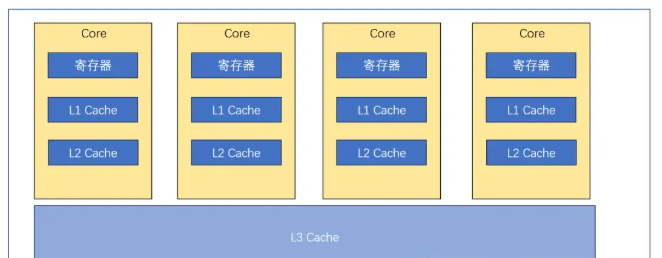
现代CPU一般都有多个Core,每个Core都可以支持一个并发(超线程可以支持两个),每个Core都有自己的L1,L2缓存,而共享L3缓存,其结构如图,这种场景下就可能面临Cache Line不一致的问题,常见的解决方法有MESI协议,其是经典的状态机模式,可以分为以下四个状态:
1)Modified(已修改):缓存行数据被修改且未同步到主内存,此状态下其他核心无法直接访问该数据。
2)Exclusive(独占):缓存行数据与主内存一致,且未被其他核心缓存,可直接修改为 Modified 状态。
3)Shared(共享):缓存行数据与主内存一致,且可被多个核心同时缓存,修改前需先获取独占权限。
4)Invalid(无效):缓存行数据已失效,需从主内存或其他核心缓存中重新加载。
该协议通过状态转换和总线监听机制,确保多核心环境下缓存数据的一致性。例如,当核心 A 修改 Shared 状态的缓存行时,会通过总线通知其他核心将对应数据标记为 Invalid,避免脏读问题。
注意:MESI协议的状态标记针对的是CPU各级缓存(L1/L2/L3)中的缓存行(Cache Line),而非直接标记主内存中的数据。
状态标记的位置
- L1/L2私有缓存:每个核心的私有缓存(L1数据/指令缓存、L2缓存)独立维护其缓存行状态
- L3共享缓存:所有核心共享的L3缓存同样通过MESI状态管理一致性
- 主内存无状态:内存中的数据不携带MESI状态,仅作为数据源或写入目标。
MESI协议状态切换
MESI名字就是高速缓存行的四种状态首字母缩略词。
在 MESI 缓存一致性协议中,缓存行(Cache Line)的四种状态(I(Invalid)、E(Exclusive)、S(Shared)、M(Modified))在读写操作时会触发状态转换和总线交互。以下是详细的状态变化逻辑及对应的总线操作,基于协议规范与硬件实现原理整理:
📊 一、读操作(Read)时的状态变化
当 CPU 发起读请求时,根据当前缓存行的状态,行为如下:
| 当前状态 | 读操作行为 | 新状态 | 总线操作 |
|---|---|---|---|
| I(无效) | 缓存行无效,需从内存或其他核心获取数据。 | S 或 E | 发送 Read 请求: 若其他核心有 M 或 E 状态数据,则回写内存并转为 S; 若无其他副本,则转为 E。 |
| E(独占) | 数据有效且仅当前核心持有,直接读取本地缓存。 | E | 无总线交互(静默操作)。 |
| S(共享) | 数据有效且可能被多个核心共享,直接读取本地缓存。 | S | 无总线交互(状态不变)。 |
| M(修改) | 数据有效且已修改(脏数据),直接读取本地缓存(最新值)。 | M | 无总线交互(静默操作)。 |
关键点:
- I→S/E 是唯一触发总线请求的读操作,需协调其他核心确保数据一致性。
- E/M 状态 的读操作无延迟,因其独占数据无需协商。
✍️ 二、写操作(Write)时的状态变化
当 CPU 发起写请求时,状态转换涉及独占权获取和失效广播:
| 当前状态 | 写操作行为 | 新状态 | 总线操作 |
|---|---|---|---|
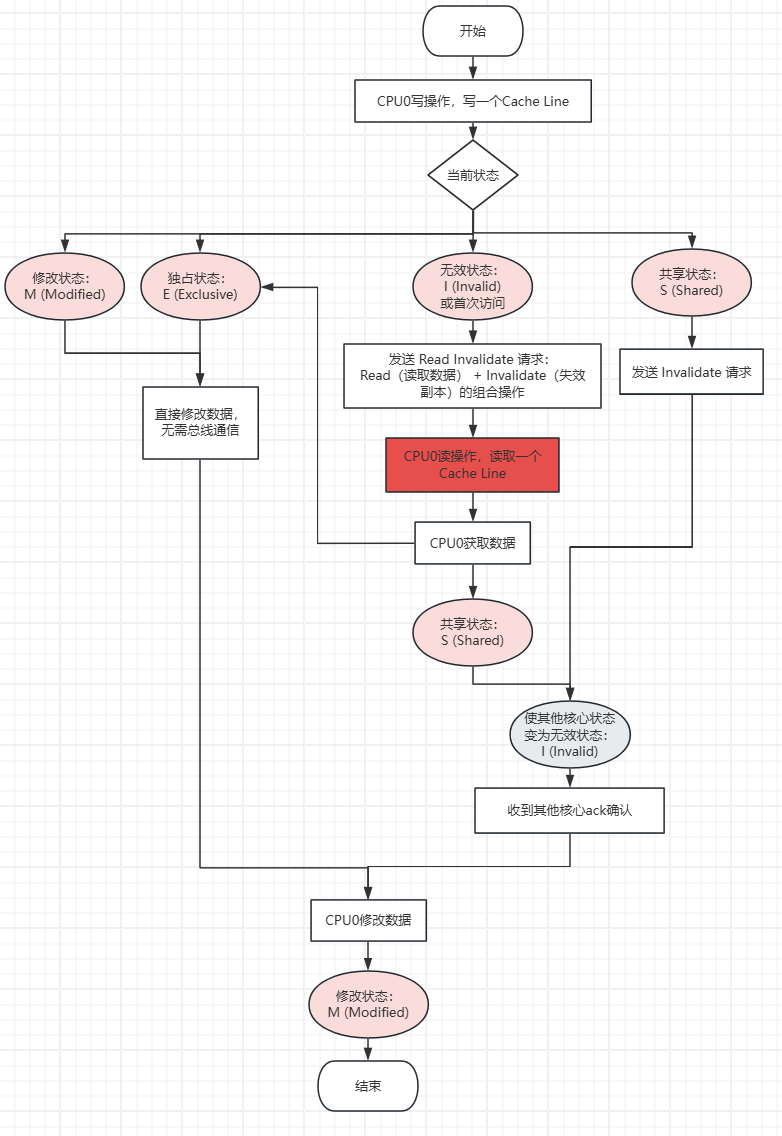
| I(无效) | 缓存行无效,需先获取数据独占权。 | M | 发送 Read Invalidate 请求: CPU0读操作,读取一个Cache Line,具体流程看上面读操作; 此时本核心是E或者S, 其他核心的副本失效(I 状态); 收到其他核心ack确认后,获取数据后修改数据,然后状态转为 M。 |
| E(独占) | 数据独占且未修改,直接写入本地缓存。 | M | 无总线交互(状态转为 M,无需广播)。 |
| S(共享) | 数据被多个核心共享,需先使其他副本失效。 | M | 发送 Invalidate 请求: • 其他核心将副本置为 I; • 本地转为 M。 |
| M(修改) | 数据已修改且独占,直接写入本地缓存(覆盖旧值)。 | M | 无总线交互(静默操作)。 |
关键点:
- S→M 必须广播 Invalidate,确保全局唯一写入权(串行化写入)。
- 硬件优化:写操作可能先暂存于 Store Buffer,异步刷入缓存(引入可见性延迟)。
Invalidate 请求 和 Read Invalidate 请求区别:
Invalidate 请求(失效请求)
用于强制其他 CPU 核心将指定缓存行状态置为 Invalid(失效),不涉及数据传递。例如,当某个核心需要独占修改共享数据时,会广播 Invalidate 消息,要求其他核心丢弃副本
其他核心仅需响应 Invalidate Acknowledge (ACK),不返回数据。
Read Invalidate 请求(读失效请求):是 Read(读取数据) + Invalidate(失效副本)的组合操作:
- 先请求读取目标缓存行的最新数据;
- 同时要求其他核心失效该缓存行的副本,确保后续操作的独占性。
- 其他核心需响应 ACK,同时返回最新数据(若持有 Modified 状态则先写回内存)。
⚠️ 三、特殊场景与性能影响
- E 状态的优化意义
- 静默升级:E 状态允许本地直接写操作(无需总线请求),大幅减少写延迟。
- 触发条件:读缺失时若其他核心无副本,则直接进入 E 而非 S。
- M 状态的数据回写
- 写回时机:仅当缓存行被替换或收到远程读请求时,强制将脏数据写回内存
- 性能代价:回写操作占用总线带宽,可能阻塞其他核心。
- 伪共享(False Sharing)问题
- 成因:不同核心修改同一缓存行的不同变量,反复触发 S↔M 转换,导致总线震荡。
- 规避方案:对齐数据结构至缓存行大小(通常 64 字节)。
💎 总结:状态转换核心逻辑
| 操作 | 关键状态转换 | 协议目标 |
|---|---|---|
| 读操作 | I → S/E(需总线协调) | 确保读取最新数据 |
| 写操作 | S → M(广播失效) | 保证写入串行化与原子性 |
| 静默操作 | E/M 状态的本地读写 | 减少总线流量,提升性能 |
协议局限性:
尽管 MESI 保障最终一致性,但 Store Buffer 和 Invalidate Queue 的异步机制会导致短期可见性问题(需内存屏障干预)。实际编程中仍需通过 volatile 或锁机制强制同步。
可通过 MESI 协议动态演示工具 观察状态流转过程。
可通过 MESI 协议动态演示工具 观察状态流转过程。
可通过 MESI 协议动态演示工具 观察状态流转过程。
重要的事情说三遍!!!
读操作流程图

写操作流程图
MESI协议
核心独享缓存(L1/L2)的状态变化流程,L1与L2的状态转换由核心本地操作触发,流程高度相似(以L1为例):
| 触发事件 | 起始状态 | 目标状态 | 关键操作 |
|---|---|---|---|
| 本地读未命中 | I (Invalid) | E 或 S | 发起Read总线请求:若其他核心无数据→E;若其他核心有副本(S/M)→S |
| 本地写(独占态) | E (Exclusive) | M (Modified) | 直接修改数据,无需总线通信,脏标记置位 |
| 本地写(共享态) | S (Shared) | M (Modified) | 广播Invalidate使其他核心副本失效,待ACK后修改数据 |
| 收到其他核心写请求 | S 或 E | I (Invalid) | 响应Invalidate消息,立即置缓存行为无效 |
关键约束:
- L1写操作若命中E态,可无延迟完成;命中S态需等待其他核心ACK(引入延迟)。
- L2作为L1备份,状态通常为S或E,接收L1淘汰的数据行。
多级缓存状态流转的核心逻辑
- 读操作:
- 触发状态I→ L1未命中→查L2→未命中→查L3→未命中→读内存→E/S(独享/共享)。
- 数据加载时逐级填充,触发状态从I→E/S(独享/共享)。
- 写操作:
- 需确保独占权:S态时广播失效信号,M态时直接修改。
- 修改后的数据在缓存层级间按需回写(如L1淘汰时写回L2)。
- 跨核同步:
- L3通过总线嗅探和目录协议维护全局状态视图,确保任一核心访问的数据为最新版本。
️ 提示:实际硬件可能采用MESI变体(如Intel的MESIF、AMD的MOESI),在Shared态细分"Owner"角色,允许脏数据在缓存间直接共享,减少内存写入。可通过perf工具监测缓存命中率,针对性优化数据布局。
MESI协议的状态标记针对的是CPU各级缓存(L1/L2/L3)中的缓存行(Cache Line),而非直接标记主内存中的数据。协议通过协调多核处理器中各层级缓存的状态,确保数据的一致性。
| 缓存层级 | 状态常见性 | 触发场景 |
|---|---|---|
| L1缓存 | 高频出现E/M状态 | 核心独占修改数据时(如核心本地写操作)。 |
| L2缓存 | 常见S/E状态 | 作为L1的备份,数据可能被多核共享。 |
| L3缓存 | 主要S状态 | 共享数据池,减少访问内存的延迟。 |
| 主内存 | 无MESI状态 | 仅存储数据,状态由缓存协议间接维护。 |
总结
- 核心作用对象:MESI协议的状态标记仅作用于CPU缓存行(L1/L2/L3),通过状态机(Modified/Exclusive/Shared/Invalid)实现多核间数据一致性
- 内存的角色:主内存不参与状态维护,仅在缓存未命中或写回时作为数据来源/存储目标。
- 实际影响:程序员需关注缓存行对齐(如避免伪共享)和内存屏障(解决Store Buffer引起的重排序),以适配MESI的硬件机制。
导致可见性问题的原因
既然MESI协议可以解决多核处理器中缓存一致性问题,那导致可见性问题的原因是啥?
一、硬件层:CPU缓存与优化机制破坏强一致性
- Store Buffer(存储缓冲区)
- 写操作时,CPU将数据暂存于本地Store Buffer而非直接更新缓存,避免阻塞等待其他核心的Invalidate Acknowledge响应。
- 问题:其他核心可能仍从自身缓存读取旧值,直到Store Buffer数据同步到缓存(存在延迟)。
- 示例:线程A修改变量flag=true,但数据滞留于Store Buffer,这时候没有去修改缓存,即不会去通知其他核的缓存失效;线程B读取flag时仍为false
- Invalidate Queue(失效队列)
- 收到Invalidate消息的核心将失效操作排队,先响应ACK再异步处理失效,减少等待时间。
- 问题:失效操作未及时执行时,核心可能读取到本应失效的脏数据。
- 优化后果
- MESI协议从强一致性退化为弱一致性,写入与失效通知的异步性导致“时间窗口内的数据不一致”
二、执行层:指令重排序与乱序执行
- 编译器/CPU指令重排序
- 为提升性能,编译器或CPU可能调整无依赖关系的指令顺序(如先写非volatile变量再写volatile变量)。
- 问题:重排序后,其他线程可能先观察到依赖变量的修改,后观察到原因变量的修改,导致逻辑错误。
- 内存操作非原子性
- 如i++对应“读-改-写”三个操作,多线程交叉执行时可能丢失更新(即使缓存一致,操作时序仍可能重叠)
三、抽象层:编程模型与硬件的语义隔阂
- Java内存模型(JMM)vs 硬件内存模型
- JMM的“工作内存”是抽象概念,涵盖CPU寄存器、Store Buffer、L1缓存等,并非直接对应物理缓存
- 问题:MESI仅保证缓存行一致,而Store Buffer/寄存器中的数据对其他核心不可见。
- 跨平台差异
- MESI是硬件协议,但不同架构(如x86/ARM)实现差异大。JMM需通过volatile、synchronized等统一语义,屏蔽底层差异
四、解决方案:内存屏障与同步原语
- 内存屏障(Memory Barrier)
- 写屏障:强制刷新Store Buffer到缓存,保证写操作全局可见(如x86的sfence)。
- 读屏障:清空Invalidate Queue(先去执行Invalidate Queue所有剩余的任务,等其执行完所有任务,再进行读操作),确保读取前缓存已失效(如x86的lfence)。
- 示例:volatile变量写操作后插入写屏障,读操作前插入读屏障。
- 锁与原子指令
- synchronized或Lock通过锁总线/缓存行(如x86的lock前缀)阻塞其他核心访问,确保原子性与可见性。
- volatile关键字
- 禁用重排序 + 插入内存屏障 → 解决可见性与有序性问题(但无法保证原子性)。
总结:可见性问题的本质
层级 核心原因 解决方案 硬件优化 Store Buffer/Invalidate Queue异步性 内存屏障强制刷新 指令执行 重排序与操作非原子性 禁止重排序(volatile) 编程模型 JMM抽象与物理缓存的映射差异 同步原语(锁、原子类) MESI协议仅保证缓存行状态一致,但硬件优化(Store Buffer/Invalidate Queue)和指令重排序导致“写入可见性延迟”,需开发者通过内存屏障或高级语言同步机制主动规避。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号