
Java面试题——集合(主要包含Collection部分,Map部分单写)
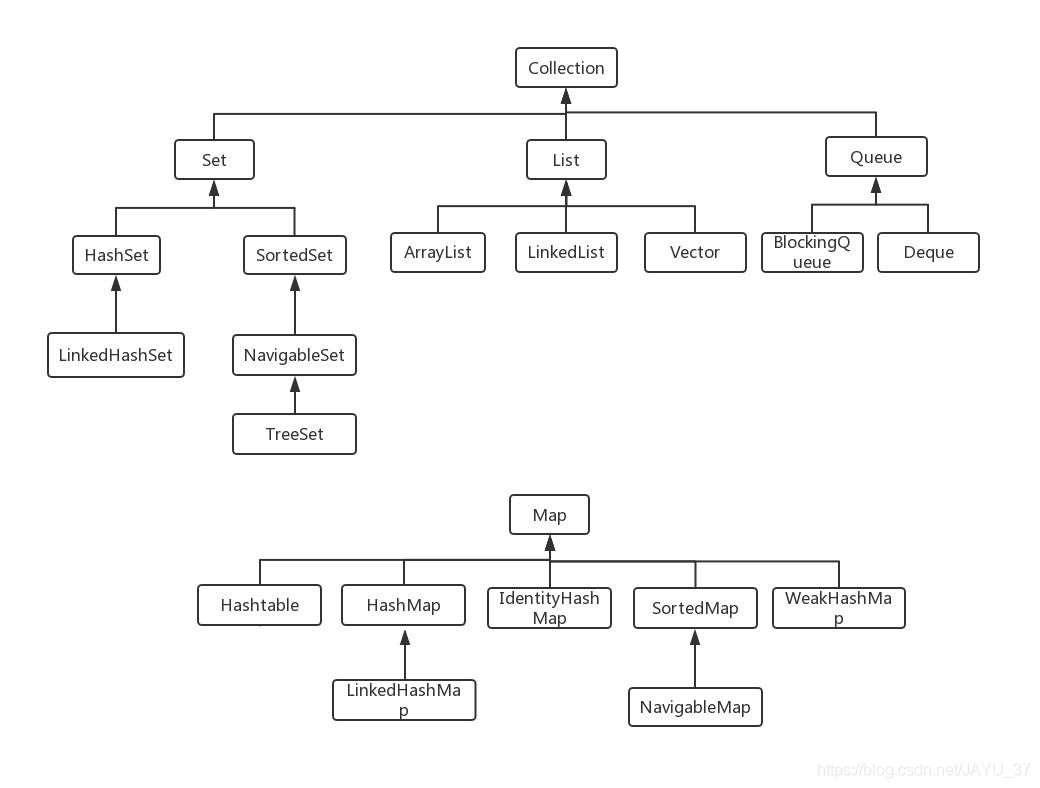
一、集合
1、什么是集合?
集合是存储数据的容器,这里的数据指的是对象,可以存储不同的对象,并且长度可变。
2、集合与数组的区别?
- 数组的长度是固定的,集合的长度是可变的
- 数组可以存储基本数据类型,也可以存储引用数据类型,集合只能存储引用数据类型
- 数组存储的元素必须是同一个数据类型,集合存储的对象可以是不同类型。
3、哪些集合是线程安全的?
SHE+v
- Stack:堆栈类,先进后出
- HashTable:就比HashMap多了个线程安全
- enumeration:枚举,相当于迭代器
- Vetor就比ArrayList多了个同步机制(线程安全),但因为效率低,已经很少使用了
二、Colletion接口
1、 Iterator和ListIterator有什么区别?
- Iterator可以遍历List和Set的集合,而ListIterator只能遍历List集合
- Iterator只支持单向遍历,而ListIterator支持双向遍历(前/后)
- ListIterator实现Iterator接口,又添加了一些额外功能,如添加一个元素,替换一个元素。
2、遍历List的方式
遍历方法:
- for循环遍历:基于计数器,集合外部维护着一个计数器,然后依次读取每个元素,直到读到最后一个元素即可
- Iterator遍历:Iterator是面向对象的一种设计模式,目的是屏蔽不同集合的特点,统一遍历集合接口,Collection中采用的迭代器模式。
- foreach:内部还是使用了迭代器的方式实现,使用时不需要显示的声明迭代器和计数器,优点是代码简洁,不易出错,缺点是,在遍历的时候不能操作集合,如增删改,否则会报并发异常
最佳方法:Java Collection接口中提供了RandomAccess 接口,用于标记集合是否支持RandomAccess接口
- 如果一个集合实现了该接口,则它支持快速随机访问,按位置读取元素的平均时间复杂度是O(1),如ArrayList
- 如果集合没有实现该接口,表示不支持RandomAccess接口,如LinkedList
综上:推荐的做法是,如果集合支持RandomAccess可以使用for遍历,否则使用Iterator/foreach遍历。
3、说下ArrayList的优缺点
增删慢,查找快
优点:
- ArrayList底层采用数组实现,是一种随机访问模式,并且实现了RandomAccess接口,因此查找的速度非常快
- ArrayList顺序添加元素非常方便
缺点:
- 删除元素的时候需要做元素的复制操作,如果元素很多的话,很消耗性能
- 插入元素的时候,同样遇到上面的问题,移动元素,让出插入位置
4、数组与List之间的转换
- 数组转List:使用Arrays.asList方法
- List转数组:使用toArray方法
List<Integer> list = new ArrayList<Integer>(); list.add(11); list.add(22); list.add(33); Object[] objects = list.toArray(); //list->[] String []strs = new String[]{ "aa","bb"}; List<String> strings = Arrays.asList(strs); //[]->list
5、ArrayList与LinkedList之间的区别
- 数据结构:ArrayList底层采用的是数组实现,LinkedList底层采用的是双向链表实现
- 数据访问:ArrayList要优于LinkedList,因为ArrayList底层采用数组实现,LinkedList采用线性的链式存储结构,需要移动指针来访问。
- 增删效率:LinkedList要优于ArrayList,ArrayList增删要复制元素,影响其它数组元素的下标,而LinkedList只需要移动指针。
- 线程安全:ArrayList和LinkedList都是线程不同步的,都不能保证线程安全。
- 内存空间:ArrayList 内存空间会耗费在列表后面的预留空间;LinkedList 内存空间会耗费在每个数据要多存储一个前驱和后继。
综上:如果对集合元素增删比较频繁的话推荐使用LinkedList,查找比较频繁的话推荐使用ArrayList。
6、多线程场景下使用ArrayList
由于ArrayList非线程安全,多线程的场景下使用ArrayList,可能会出现问题,可以使用Collections的synchronizedList方法将其转成一个线程安全的List再使用
List<Integer> list = new ArrayList<Integer>(); list.add(11); list.add(22); list.add(33); List<Integer> integers = Collections.synchronizedList(list); integers.add(44);
7、List与Set的区别
List和Set都继承与Collection接口
特点:
List:一个有序(存入和取出的顺序一致)的容器,可以插入Null值,可以有重复元素,元素都有索引,常用的实现类有ArrayList,LinkedList,Vector.
Set:一个无序(存入和取出的顺序可能不一致)的容器,不允许重复元素,只允许存入一个NULL值,必须保证元素的的唯一性,Set常见的实现类有HashSet,LinkedHashSet,TreeSet.
遍历:
List因为是有序的,所以支持使用for,也就是通过下标进行遍历,迭代器遍历,而Set只支持迭代器遍历,因为他是无序的,无法通过下标来获取值。
8、说一下HashSet的实现原理,
HashSet是基于HashMap实现的,HashSet的值存放在HashMap的 key 上,相关的HashSet的操作,基本上都是直接调用底层的HashMap的相关方法来实现的,并且HashSet不可重复,是无序的
9、说一下HashSet如何检查重复,如何保证数据不可重复?
说在前面:HashSet是Set的实现,不是Map接口下的实现。。。。
HashSet的add方法底层使用HashMap的put方法来插入数据,判断数据是否存在的依据,不仅要比较hashcode值还要equals方法。
HashSet部分源码:
private static final Object PRESENT = new Object(); private transient HashMap<E,Object> map; public HashSet() { map = new HashMap<>(); } public boolean add(E e) { // 调用HashMap的put方法,PRESENT是一个至始至终都相同的虚值 return map.put(e, PRESENT)==null; }
HashMap的key是唯一的,由源码可知HashSet的key就是使用HashMap的key,如果HashSet中遇到相同的key时,对于新的value就会覆盖旧的value,返回旧的value,所以是不会重复的。
HashMap比较key是否相等是先比较hashcode,再equals。
<mark>回顾hashcode和equals。</mark>
Java对hashcode()和equals()有以下规定:
- 如果两个对象相等,则它们的hashcode()一定相等
- 如果两个对象相等,则它们的equals也返回true
- 如果两个对象的hashcode相等,但是它们不一定相等。
综上:我们再重写equals时,规定也必须重写hashcode
hashcode()的默认行为是对堆上的对象产生独特值,如果没有重写hashcode(),无论如何两个对象都不会相等(即使两个对象指向相同的数据)
== 与 equals的区别
- == 是判断两个变量或实例是否指向相同的内存地址,equals是判断两个变量或实例指向的内存地址对应的值是否相等
- ==是对内存地址进行比较,equals是对字符串进行比较
- ==是比较引用是否相同,equals是值是否相同
10、 HashSet和HashMap的区别?
| HashMap | HashSet |
|---|---|
| 实现Map接口 | 实现Set接口 |
| 存储键值对 | 存储对象 |
| 调用put方法向map中添加元素 | 调用add方法向Set中添加元素 |
| HashMap使用key来计算hashcode值 | HashSet使用成员对象来计算hashcode值,如果相等则在调用equals判断,如果对象不同的话,返回false |
| HashMap相比HashSet快,因为它是使用唯一的key来获取值 | HashSet比HashMap稍慢点 |
11、comparable和comparator的区别
- comparable在
java.lang.Comparable它有一个comparaTo方法用于排序;comparator在java.util包中,它有一个compare(Object obj1,Object obj2)用于排序 - 如果实现类没有实现comparable接口或者实现了comparable接口但是不满足于comparable接口提供的compareTo方法,我们可以自定义比较方法,只需要实现Comparator接口重写compare(Object obj1,Object obj2)方法。
- comparable需要比较对象来实现接口,使用对象调用方法来比较对象,需要改变对象内部结构(重写compareTo),耦合度高。comparator相当于一个通用的比较工具接口,需要定制一个比较类去实现它,重写里面的compare方法,方法参数即比较的对象,对象不用做任何的改变,解耦。
12、Collection和Collections的区别
Collection是java.utils.Collectioni的集合接口,也是集合的顶级接口,它提供了对集合对象的基本操作和通用方法,Collection类在Java类库中有很多体现,直接实现类有List,Set。
Collections:是集合类的一个工具类,提供了一系列的静态方法,用于对集合中的元素进行排序,搜索等操作。
三、Map
1、Hashtable和ConcurrentHashMap有什么区别?
锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap提供了与Hashtable和SynchronizedMap不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而在同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。
ConcurrentHashMap默认将hash表分为16个桶,诸如get、put、remove等常用操作只锁住当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。
2、Vector、Collections.synchronizedList 和CopyOnWriteArrayList有什么区别?
ArrayList是线程不安全的,但是有几个与它结构相似的容器是线程安全的: Vector、Collections.synchronizedList 和CopyOnWriteArrayList
下面分别说一下这几个线程安全的容器的区别:
Vector:它几乎在每个方法声明处都加了synchronized关键字来使容器安全
Collections.synchronizedList:也是几乎都是每个方法都加上synchronized关键字的,只不过它不是加在方法的声明处,而是方法的内部
CopyOnWriteArrayList:
原文入口:https://blog.nowcoder.net/n/62973d62e5214fc4aebc1df8cdd571dd#11__5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号