OO第四单元总结 —— UML系列
OO第四单元总结 —— UML系列
一、本单元作业架构设计
-
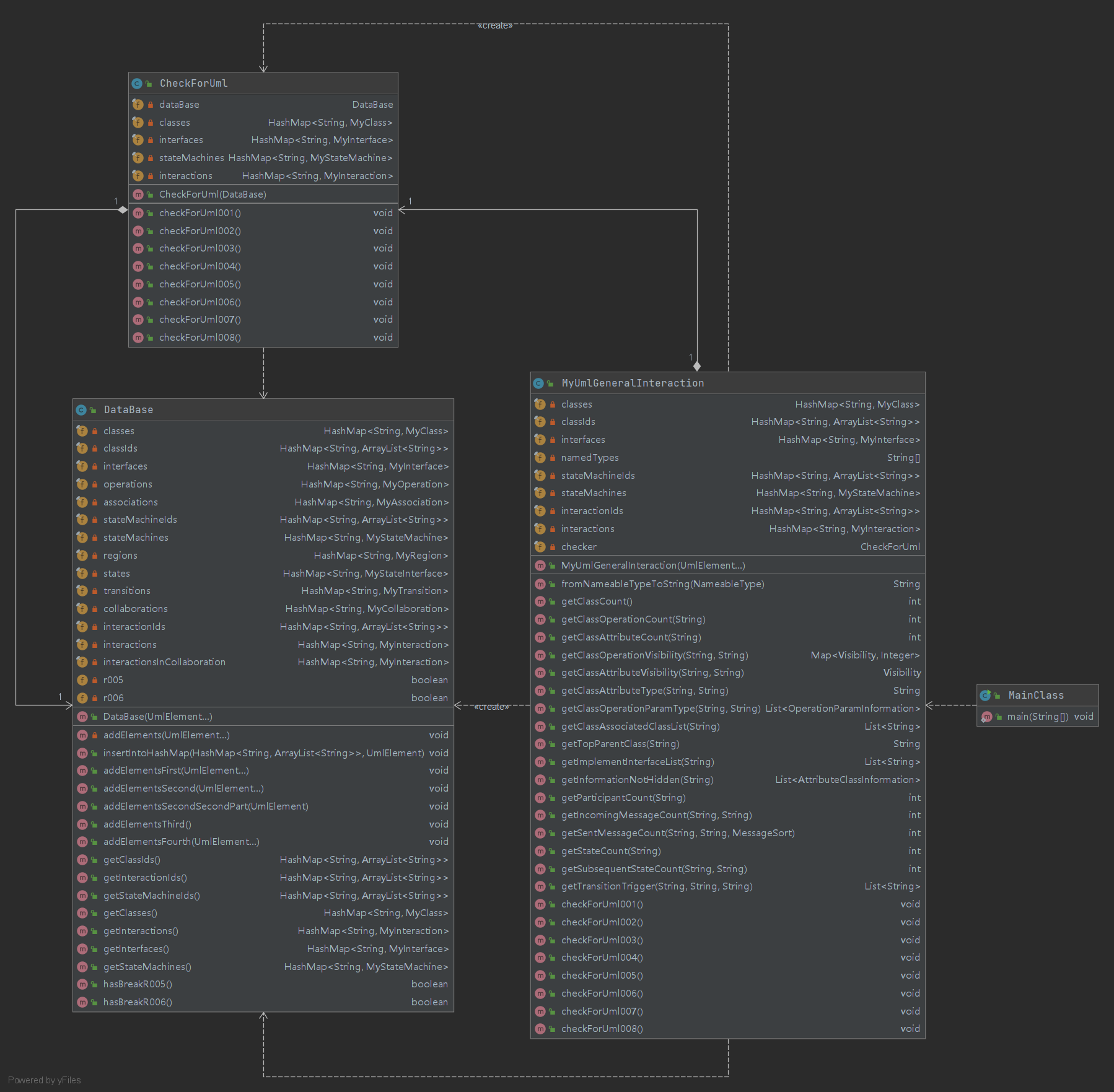
UML类图(主干部分)
![]()
类图中只展示了主干部分,除此之外还有针对每一种
UmlElement的包装类,如:package analyzer; import com.oocourse.uml3.models.common.NameableType; import com.oocourse.uml3.models.common.Visibility; import com.oocourse.uml3.models.elements.UmlAttribute; import com.oocourse.uml3.models.elements.UmlElement; public class MyAttribute { private final UmlAttribute umlAttribute; public MyAttribute(UmlElement element) { umlAttribute = (UmlAttribute) element; } public Visibility getVisibility() { return umlAttribute.getVisibility(); } public NameableType getType() { return umlAttribute.getType(); } public String getParentId() { return umlAttribute.getParentId(); } public String getName() { return umlAttribute.getName(); } public String getId() { return umlAttribute.getId(); } } -
类的设计
-
包装类
在
UmlElement的包装类中,存储了官方包提供的UmlElement对象中没有存储的重要信息(如类的继承关系,各种属性等),也实现了对官方包对象的部分重要信息的查询方法,以此来更加便捷地管理数据。 -
Database主要负责接受传入的
UmlElement... elements,并对有用信息进行提取与存储。处于对类的行数限制的要求,以及明确类的分工的考虑,在第二次作业时将其独立分出作为一个单独的类。
在第三次作业中的
R005和R006在这一初始化步骤即可被发现,因而该类也负责对这两个错误的识别。 -
CheckForUml在第三次作业时加入,主要负责接受初始化后的
Database,检查相应的8条规则。
-
-
Database的初始化基本思路是遍历传入的
UmlElement... elements,根据其类型进行包装,之后装入相应的容器并与相应的元素建立联系。考虑到不同类型元素在遍历时先后次序的不确定性,选择进行多轮遍历,并按照元素之间的依赖关系在每一轮遍历时只处理部分类型的元素,以此来避免记录元素之间的关联时出现空指针异常。
具体分类如下:
-
第一轮:
UML_CLASS UML_INTERFACE UML_ASSOCIATION UML_STATE_MACHINE UML_REGION UML_TRANSITION UML_COLLABORATION UML_INTERACTION -
第二轮:
UML_ATTRIBUTE UML_OPERATION UML_ASSOCIATION_END UML_GENERALIZATION UML_STATE UML_PSEUDOSTATE UML_FINAL_STATE UML_EVENT UML_OPAQUE_BEHAVIOR UML_LIFELINE -
第三轮:
本轮不进行遍历,而是在已经处理的元素之间建立联系,包括:
在
class和interface之间添加association在
stateMachine中添加region在
state(包括pseudoState和finalState)之间添加transition -
第四轮:
UML_PARAMETER UML_INTERFACE_REALIZATION UML_GENERALIZATION UML_MESSAGE
-
-
容器选择
在本单元作业中,主要选用了一下三种容器;
HashMap HashSet ArrayList-
HashMap主要用于需要检索的元素集合。
-
HashMap主要用于不需要检索、不允许有重复对象、且在本单元作业涉及到的操作中只需要查询元素个数或遍历,不需要检索或取出特定元素的集合,如类实现的接口、关联的类或接口等。
-
ArrayList主要用于不需要检索,但在正常情况下(指可以通过第三次作业的检测且进行查询时返回数据而非异常)元素个数已知,甚至需要取出操作的集合。
-
针对依据
Name进行查询的查询指令所使用的复合容器对于一些元素,在初始化时往往需要依据
Id来进行识别与查找,但在处理查询指令时又需要依照Name进行查找,且可能因为存在相同Name元素(或不存在该Name的元素)而触发异常。针对这样的使用了HashMap和ArrayList的复合数据结构,以class的存储为例:// DataBase.java private final HashMap<String, MyClass> classes; private final HashMap<String, ArrayList<String>> classIds;在
classes中,键值为Id,建立了Id到class的包装类对象的映射;而在classId中,键值为Name,建立了Name到一个装有全部具有该Name的class的Id的容器的映射。由此,在处理查询指令时,往往可以通过第一级
Name到Id的映射快速判断是否抛出异常,如不需要抛出异常又可以通过第二级Id到包装类对象的映射快速定位所需要的的数据。
-
-
图模型存储
本单元作业中涉及到了若干个图,如类和接口的继承,且需要对路径、环等进行查询。
选择在包装类中一方面存储该节点的边,即和该节点直接相连的边,另一方面也存储所有可达的结点。
以
class为例,在其包装类中即记录了其由UML_GENERALIZATION所规定的父类和子类,也使用另外的域记录了其所有父类和子类,这样的好处是:在初始化
DataBase步骤便可以计算出全部的所需信息,在之后处理查询指令时极少需要循环或递归操作。避免了由于循环继承等错误导致陷入死循环
简化了第三次作业中的检查步骤
二、四个单元以来各方面理解的演进
-
程序设计方面
从面向过程编程到面向对象编程的转变。
在第二、三和四单元,分别对多线程编程、JML规格和UML模型进行了一定的了解,但同时也在不断加深对于第一单元内容的理解。
在进行第一单元时,往往是为了面向对象而面向对象,胡乱分类
初见面向对象编程,不甚理解,只是简单地将面向过程的程序拆成三个文件,装到三个类中
类的架构设计完全依据直觉
和代码长度,没有从层次和功能考虑错误地认为对象只能是一种事物,无法理解将某种操作定义为一个对象的行为
由此导致写出来的程序有着拓展性极差等缺点,最终在第三次作业时体验了通宵重构的快乐
在进行第二单元时,过于极端地执着于拆分
由于重构的惨剧就在昨日,过分地关注对象的拆分,三四个类即可完成的第一次作业被拆到了13个类ORZ
类的设计过于零散,甚至存在部分不必要单独列出的纯方法类,本质上还是残留的面向过程编程思维所致
数据结构的设计没有被重视,一方面导致想象中极佳的拓展性(w)并没有很好地体现,反而受到了重重制约;另一方面也突出了类的设计的缺陷:数据与方法的割裂,导致部分数据在不同的对象之间被反复拷贝,效率低下
在进行后两个单元时,逐步注意到了上面的问题,努力地改正,但仍有需要提高的地方:
相似结构的代码反复出现,没能很好地进行代码的复用
类的架构设计仍不甚合理,尤其表现在主干类中行数过多、功能驳杂,给程序编写带来了诸多不便。
-
测试方面
graph LR Z[程序的测试] A(样例) --> B(大量随机数据) B --> C(单元测试) B --> G(大量特殊重复数据/指令) B --> D(临界数据) D --> E(数据限制) D --> F(程序语言限制) E --> H(正确性测试) F --> H C --> H G --> I(性能测试)最初并不是很能理解测试的重要性,错误地认为“自己造数据时注意到的可能会出错的地方,自己在当初编写程序时一定也会注意到”,觉得编写测试数据和重新阅读源代码检查的作用相仿,并没有重视
后来逐渐认识到了使用大量的随机数据可以快速发现编写程序时忽略的逻辑错误,尤其是在进行互测,面对并非由自己编写的程序时。
由此自然想到针对程序语言的限制和数据自身的限制进行针对性地测试。在编写程序时往往是从解决问题的角度出发,容易忽略掉特殊的情况,而测试时却可以转换角度,从数据本身出发,从而更有针对性地检验特定的问题。
在后两个单元中,学习了单元测试的测试模式,简化了测试的难度,提高了测试的针对性。同时在此也首次将注意力放到了性能问题上。
三、课程收获
-
面向对象编程的相关知识。
这自不必多言,课程核心所在。
-
熟练使用 java 语言。
在课程之前我对这门编程语言的了解仅限于上学期《java程序设计》课程期末考试之前的三天速成,经过这一学期的磨炼,已经熟练掌握了这门语言的基本应用。
-
懂得了关注架构设计
这是编程方法上的提高,具体上面已经有了详细地说明,但其实这并不只是面向对象编程独有的思维模式,在目光重新回到用C语言编写面向过程的程序时也有了更加清晰的思路,甚至也在影响着其他的领域。
-
更加注重代码风格
四、课程改进建议
-
上机实验反馈
个人认为上机实验的题目也是需要反馈的,尤其是部分上机实验的题目与课下作业的形式有较大不同,这也是同学对自己是否理解了课上内容的一次检验
-
互测指导
课程组多次强调参与互测的重要性,但个人认为与之配套的更加详细的指导也是需要的,包括但不限于相关工具的使用、评测机的搭建等,甚至可以考虑将搭建一台评测机作为一次课下作业的内容2333
-
时间略显紧张
影响我本人互测积极性的另一大因素便是没有充分的时间进行互测,只有一两天的时间,周二还是满课emmmm,虽然互测不结束就没有办法进行后续的debug等环节,但将每次作业的周期再延长一周左右或许也无伤大雅?
最后,感谢课程组的老师和助教们,
以及身边一直给予了我诸多帮助朋友们,
希望OO课程可以越办越好,
希望大家都能取得满意的成果~
2021年6月26日

 浙公网安备 33010602011771号
浙公网安备 33010602011771号