
正则表达式优化总结
什么是正在表达式
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式快速入门可参考:https://www.w3cschool.cn/regex_rmjc/。正则表达式里包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。简单的基础不用多讲,讲几个正则中重要又稍微难懂的概念。
1、回溯
正则引擎主要可以分为基本不同的两大类:一种是DFA(确定性有穷自动机),另一种是NFA(非确定性有穷自动机)。在NFA中由于表达式主导的串行匹配方式,所以用到了回溯(backtracking),这个是NFA最重要的部分,每一次某个分支的匹配失败都会导-致一次回溯。
回溯法也称试探法,它的基本思想是:从问题的某一种状态(初始状态)出发,搜索从这种状态出发所能达到的所有“状态”,当一条路走到“尽头”的时候(不能再前进),再后退一步或若干步,从另一种可能“状态”出发,继续搜索,直到所有的“路径”(状态)都试探过。这种不断“前进”、不断“回溯”寻找解的方法,就称作“回溯法”。
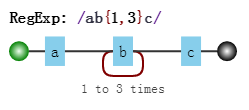
举个例子更能直观说明。正则是 /ab{1,3}c/ ,其可视化形式是:
而当目标字符串是"abbbc"时,就没有所谓的“回溯”。其匹配过程是:
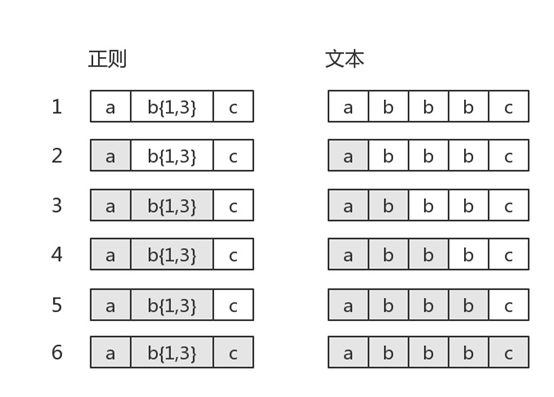
如果目标字符串是"abbc",中间就有回溯。

2、贪婪匹配和非贪婪匹配
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例: a.*b ,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索 aabab 的话,它会匹配整个字符串 aabab。这被称为贪婪匹配。
非贪婪匹配就是尽可能少的匹配。一下几个是非贪婪匹配常见的用法。

以 a.*?b 为例,用它来搜索 aabab 的话,他它会匹配 aab(第一到第三个字符)和 ab(第四到第五个字符)

3、捕获和断言

捕获:当我们使用小括号指定一个子表达式之后,就要对这个子表达式的文本进行匹配,即此分组捕获的内容,可以在表达式或其它程序中作进一步的处理。一般情况下,每个分组都会自动拥有一个组号,它的规则是:从左到右以分组的左括号作为标志,把第一次出现的分组的组号定为1,第二个即2,以此类推下去。
后向引用:用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。我们根据示例来深刻理解: \b(\w+)\b\s+\1\b 可以用来匹配重复的单词,像go go。
非捕获组:第三个 (?:exp) 不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像前两种那样被捕获到某个组里面,也不会拥有组号。
零宽断言:用于查找在某些内容的之前或之后的东西,但是有不包含这些内容本身的时候,零宽断言就起到作用了。
(?=exp) :也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。比如 \b\w+(?=ing\b),匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=exp) :也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp。比如 (?<=\bre)\w+\b 会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
正则优化
正则在安全领域中最常见的用途是用来编写安全策略,比如WAF的拦截策略以及HIDS对应的webshell检测策略等。以下归纳了几点正则优化的策略:
a) 合理使用括号
当要捕获组的时候,使用非捕获型括号(?:),这是写策略正则最常用的优化方法,因为使用(?:)可以匹配想要的内容,但不捕获到组里,可以节省资源,提高效率。
b) 使用非贪婪模式
尽量使用非贪婪模式,因为贪婪模式情况下,容易造成回溯。如果不确定使用哪种模式,优先考虑
c)使用字符组代替分支条件
使用[a-d]表示a~d之间的字母,而不是使用(a|b|c|d)
d) 谨慎用点号元字符,尽可能不用星号和加号这样的任意量词
例子: 要匹配 <12345>,其中<>中间是1-5位的数字
正常写法: <\d*>
优化写法: <\d{1,5}>
e)提取多选结构开头的相同字符
例如 the|this 改成th(?:e|is)
f)使用占有优先量词和固化分组
占有优先量词:
?+ *+ ++ {m,n}+
占有优先量词与匹配优先量词很相似,只是它们从来不会交还已经匹配的字符。
固化分组:
(?>...) ...是指具体内容
固化分组的内容与正常的匹配并无区别,只是当匹配完括号中的内容后,括号中的备用状态会全部舍去。
g)始、行描点优化
能确定起止位置,使用^能提高匹配的速度。同理,使用$标记结尾,正则引擎则会从符合条件的长度处开始匹配,略过目标字符串中许多可能的字符。在写正则表达式时,应该将描点独立出来,例如“^(?:abc|123)”比“^123|^abc”效率高,而“^(abc)”比“(^abc)”效率更高。
其他
正则库的选择:
PCRE(Perl Compatible Regular Expressions中文含义:perl语言兼容正则表达式)是一个用C语言编写的正则表达式函数库,由菲利普.海泽(Philip Hazel)编写。PCRE是一个轻量级的函数库,比Boost之类的正则表达式库小得多。PCRE十分易用,同时功能也很强大,性能超过了POSIX正则表达式库和一些经典的正则表达式库 。
正则测试工具
正则效率评估工具
http://blog.chacuo.net/238.html
url搜集:镜像流量、日志请求、爬虫
url去重:布隆过滤器,BerkeleyDB
https://www.anquanke.com/post/id/85298

 浙公网安备 33010602011771号
浙公网安备 33010602011771号