Spark----shell操作
Spark-shell进行词频统计
1.将README.md文件上传至hdfs上:
hadoop fs -put README.md /
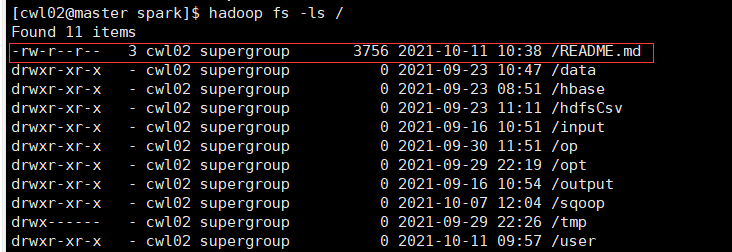
2.进入shell编辑界面
spark-shell

①:val textFile = sc.textFile("/README.md")

②: textFile.first()
查看文件中的第一条数据

③:textFile.count()
统计文件中 的单词总数

④: val wordcount = textFile.flatMap(line=>line.split("")).map(word=>(word,1)).reduceByKey(_+_)
扁平化操作将分割开的单词和1构成元组

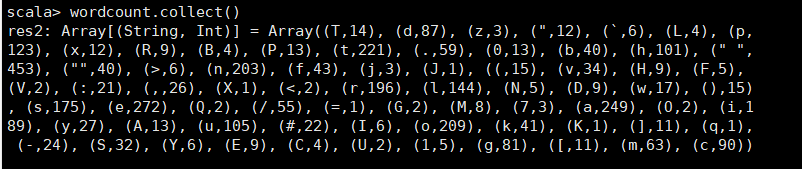
⑤:wordcount.collect()
遍历list中的每一个元组
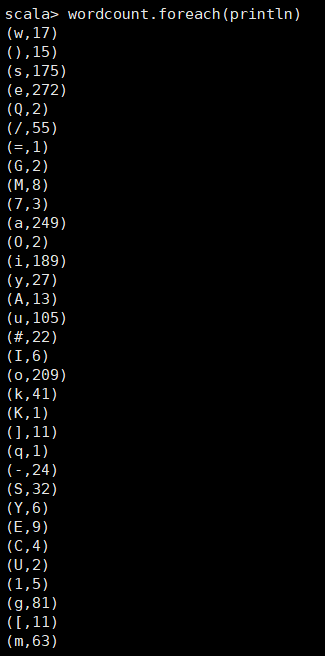
⑥: wordcount.foreach(println)
输出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号