Spark---组件的维护
Scala
#掌握Spark的架构#掌握Spark的工作原理#掌握Spark的安装部署#掌握Scala的架构#掌握Spark的参数修改方法#掌握Spark Shell的编程#掌握Spark的基础管理方法
注意:spark的版本号与Scala版本号是不一致的,spark依赖Scala
先安装Scala再安装Spark
1.进入apps目录下解压文件至指定目录并修改文件所有者
解压: tar -zxvf scala-2.11.8.tgz -C /opt/
权限:sudo chown -R cwl02:cwl02 /opt/
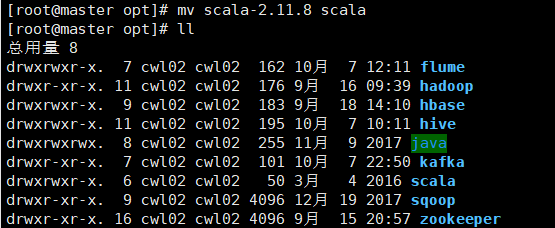
改名:
2.配置环境变量
sudo vim /etc/profile

3.生成环境变量并查看scala shell界面
source /etc/profile

Spark
1.解压文件
tar -zxvf /apps/spark-2.4.7-bin-hadoop2.7.tgz -C /opt
2.修改文件名和所有者权限
mv spark-2.4.7-bin-hadoop2.7 spark
sudo chown -R cwl02:cwl02 /opt
3.编辑环境变量
sudo vim /etc/profile

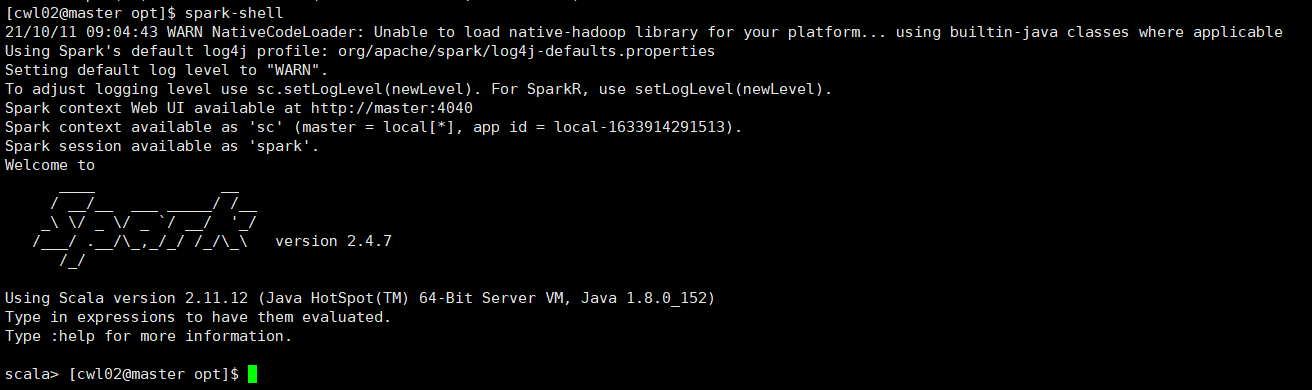
4.生成环境变量并查看spark-shell是否能进入scala shell界面
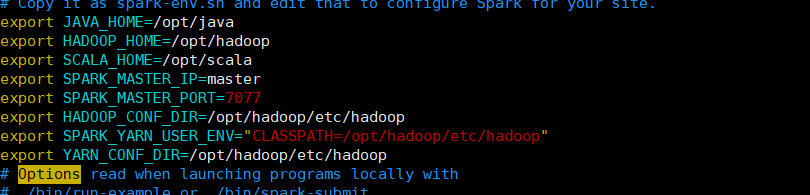
5.配置spark-env.sh文件
cd /opt/spark/conf目录下
cp spark-env.sh.template spark-env.sh
sudo vim spark-env.sh
添加:
export JAVA_HOME=/opt/java
export HADOOP_HOME=/opt/hadoop
export SCALA_HOME=/opt/scala
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
export SPARK_YARN_USER_ENV="CLASSPATH=/opt/hadoop/etc/hadoop"
export YARN_CONF_DIR=/opt/hadoop/etc/hadoop
6.编辑slaves文件
cp slaves.template slaves
sudo vim slaves
添加主/副节点名称

7.将环境变量和spark拷贝至其他两个节点
环境变量:
sudo scp -r /etc/profile @slave1:/etc/
sudo scp -r /etc/profile @slave2:/etc/

spark:
sudo scp -r /opt/spark @slave1:/opt/
sudo scp -r /opt/spark @slave2:/opt/
注意:拷贝至其它节点后查看其他节点的权限是否为当前用户
9.启动集群
三个节点执行:zkServer-sh start
master上执行:hadoop-daemons.sh start journalnode 和 start_all.sh
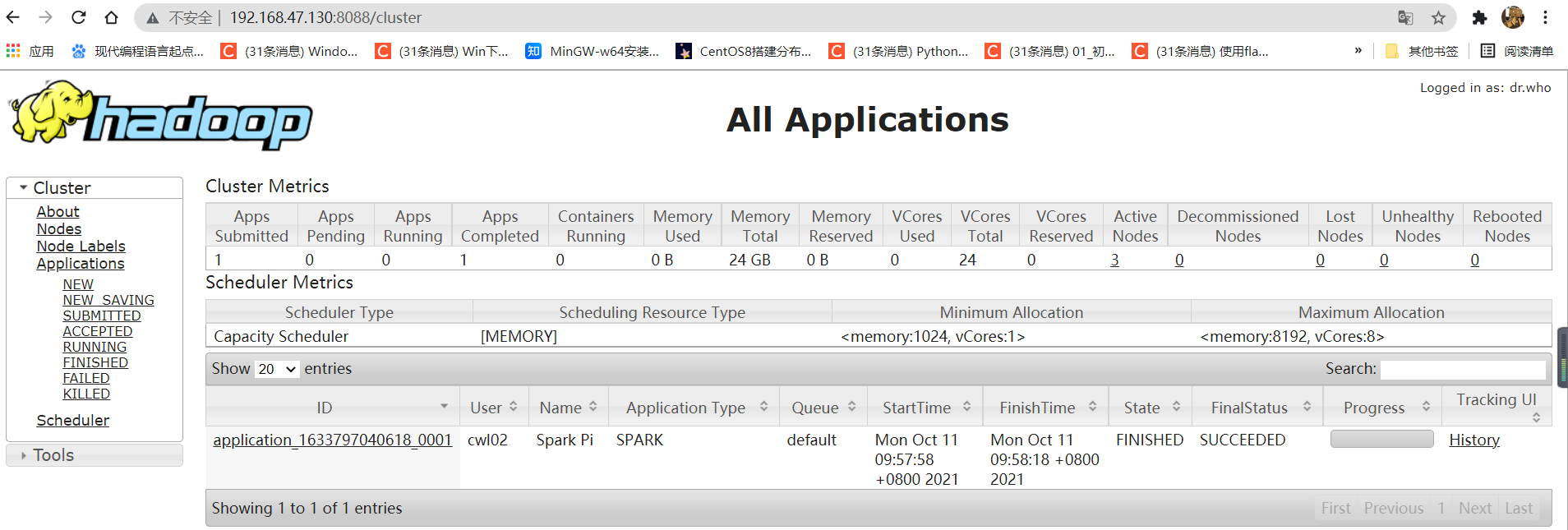
10.以集群运行SparkPi程序
进入bin目录下执行:spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client /opt/spark/examples/jars/spark-examples_2.11-2.4.7.jar 40

打开浏览器输入8088端口查看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号