flink中Time和window
一、Time
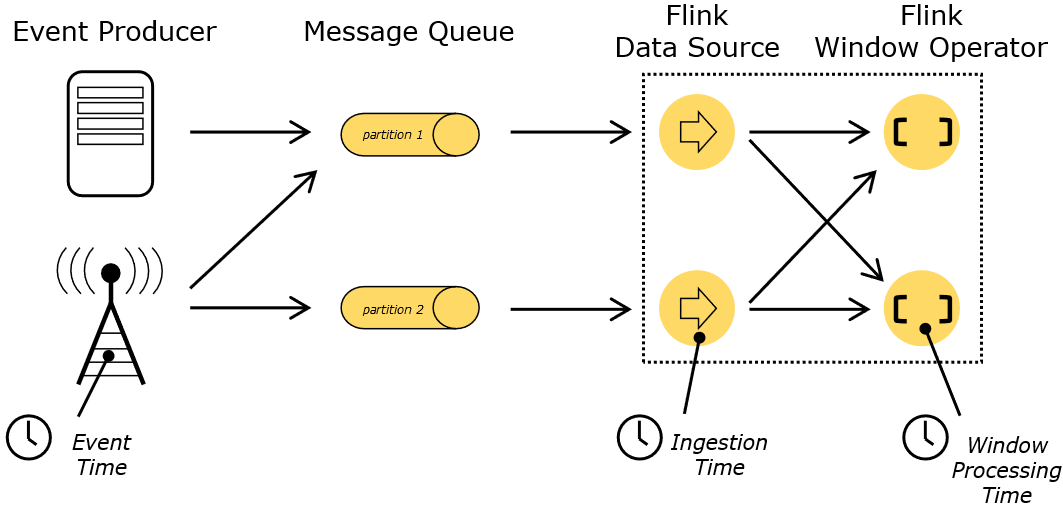
(1)Even time
1、Event Time 是事件发生的时间,一般就是数据本身携带的时间。这个时间通常是在事件到达 Flink 之前就确定的,并且可以从每个事件中获取到事件时间戳。
2、在 Event Time 中,时间取决于数据,而跟其他没什么关系。如果事件按照事件先后发生的顺序到达,那么处理 Event Time 将产生完全一致和确定的结果;否则处理 Event Time 时将会因为要等待一些无序事件而产生一些延迟。由于只能等待一段有限的时间,因此就难以保证处理 Event Time 将产生完全一致和确定的结果。
3、Event Time 程序必须指定如何生成 Event Time 水印,这是表示 Event Time 进度的机制
(2)Ingestion Time
1、Ingestion Time 是事件进入 Flink 的时间,在概念上位于 Event Time 和 Processing Time 之间。
2、与 Event Time 相比,Ingestion Time 程序无法处理任何无序事件或延迟数据,但程序不必指定如何生成watermark。
3、Ingestion Time 与 Event Time 非常相似,但 Ingestion Time 具有自动分配时间戳和自动生成watermark功能。
(3)procession time:Processing Time 是指事件被处理时机器的系统时间。
二、window
(1)window类型
1、TimeWindow:按照时间生成Window
2、CountWindow:按照指定的数据条数生成一个Window,与时间无关。
(2)time window的类型
1、Tumbling Time Window(滚动窗口):假设统计每一分钟中用户购买的商品的总数,需要将用户的行为事件按每一分钟进行切分,这种切分被成为翻滚时间窗口,翻滚窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口。特点:将数据依据固定的窗口长度对数据进行切片;时间对齐,窗口长度固定,没有重叠。
val tumblingCnts= buyCnts.keyBy(0).timeWindow(Time.minutes(1)).sum(1)

2、sliding time window(滑动窗口):对于某些应用,它们需要的窗口是不间断的,需要平滑地进行窗口聚合。比如,我们可以每30秒计算一次最近一分钟用户购买的商品总数。这种窗口我们称为滑动时间窗口(Sliding Time Window)。在滑窗中,一个元素可以对应多个窗口。特点:滑动窗口由固定的窗口长度和滑动间隔组成;时间对齐,窗口长度固定,有重叠。
1)滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。
val slidingCnts = buyCnts.keyBy(0).timeWindow(Time.minutes(1), Time.seconds(30)).sum(1)
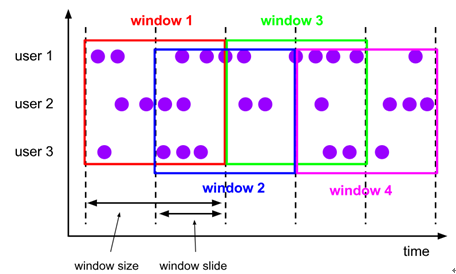
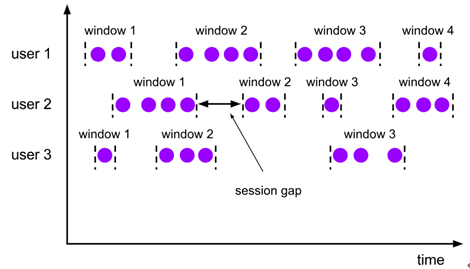
3、Session Windows(会话窗口):session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。特点:时间无对齐。由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
val sessionCnts: DataStream[(Int, Int)] = vehicleCnts.keyBy(0).window(ProcessingTimeSessionWindows.withGap(Time.seconds(30))).sum(1)
(3)CountWindow类型
CountWindow根据窗口中相同key元素的数量来触发执行,执行时只计算元素数量达到窗口大小的key对应的结果。注意: CountWindow的window_size指的是相同Key的元素的个数,不是输入的所有元素的总数。如:windowSize=4,输入(1,2,3,1,1,1)结果:(1,3),此时key为2和3的条数才1,达到4时才计算。
1、滚动窗口:默认的CountWindow是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
2、滑动窗口:滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size:5,一个是sliding_size:2。若sliding_size设置为了2,也就是说,每收到两个相同key的数据就计算一次,每一次计算的window范围是5个元素。达到滑动步长的时候计算一次,达到滑动窗口大小的时候计算一次
三、EventTime与Window
(1)EventTime的引入:在Flink的流式处理中,大部分的业务都会使用eventTime,一般在eventTime无法使用时,才会使用ProcessingTime或者IngestionTime。若要使用EventTime,则需要引入EventTime的时间属性。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
(2)waterMark
1、问题:理论上流到operator的数据都是按照事件产生的时间顺序来的,但实际应用中会出现数据记录乱序、延迟到达等问题导致乱序的产生。即乱序指的是Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
2、解决方案:基于EventTime处理数据的进度依赖于数据本身,而不是当前Flink处理系统中Operator所在主机节点的系统时钟。故需要一种机制能够控制数据处理的进度,比如一个基于事件时间的Time Window创建后,具体怎么确定属于该Window的数据元素都已经到达?如果确定都到达了,就可以对属于这个Window的所有数据元素进行处理处理(如汇总、分组等)。这就要用到WaterMark机制,它能够衡量数据处理进度(表达数据到达的完整性)。
3、Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。
4、数据流中的Watermark用于表示timestamp小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的。Watermark可以理解为一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定EventTime 小于 maxEventTime -t 的所有数据都已经到达,如果有窗口的结束时间等于 maxEventTime -t,那么这个这个窗口被触发执行
5、有序流的watermarker如下图所示:其中watermaker设置为0

6、乱序流的watermaker如下图所示:其中watermaker设置为2

当Flink接收到数据时,会按照一定的规则去生成Watermark,这条Watermark就等于当前所有到达数据中的maxEventTime - 延迟时长,也就是说,Watermark是由数据携带的,一旦数据携带的Watermark比当前未触发的窗口的结束时间要晚,那么就会触发相应窗口的执行。
由于Watermark是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的Watermark是5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口1是1s~5s,窗口2是6s~10s,那么时间戳为7s的事件到达时的Watermarker恰好触发窗口1,时间戳为12s的事件到达时的Watermark恰好触发窗口2。
Watermark 就是触发前一个窗口的“关窗时间”,一旦触发关窗那么以当前时刻为准在窗口范围内的所有数据都会收入窗口中。只要没有达到Watermark那么不管现实中的时间推进了多久都不会触发关窗
(3)如何自定义从事件数据中抽取时间戳:Flink暴露了TimestampAssigner接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳。
1、AssignerWithPeriodicWatermarks周期性的生成watermark:系统会周期性的将watermark插入到流中(水位线也是一种特殊的事件数据)。默认周期是200毫秒。可以使用 ExecutionConfig.setAutoWatermarkInterval()方法进行设置。
每隔5秒产生一个watermark:env.getConfig.setAutoWatermarkInterval(5000)
2、AssignerWithPunctuatedWatermarks间断式地生成watermark。和周期性生成的方式不同,这种方式不是固定时间的,而是可以根据需要对每条数据进行筛选和处理
四、解析windowAPI
Flink 中定义一个窗口主要需要以下三个组件:Window Assigner,Trigger,Evictor。
1、Window Assigner:用来决定某个元素被分配到哪个/哪些窗口中去。
数据流源源不断地进入算子,每一个到达的元素都会被交给 WindowAssigner。WindowAssigner 会决定元素被放到哪个或哪些窗口(window),可能会创建新窗口。因为一个元素可以被放入多个窗口中,所以同时存在多个窗口是可能的。注意,Window本身只是一个ID标识符,其内部可能存储了一些元数据,如TimeWindow中有开始和结束时间,但是并不会存储窗口中的元素。窗口中的元素实际存储在 Key/Value State 中,key为Window,value为元素集合(或聚合值)。
2、Trigger:触发器。决定了一个窗口何时能够被计算或清除,每个窗口都会拥有一个自己的Trigger。
每一个窗口都拥有一个属于自己的 Trigger,Trigger上会有定时器,用来决定一个窗口何时能够被计算或清除。每当有元素加入到该窗口,或者之前注册的定时器超时了,那么Trigger都会被调用。Trigger的返回结果可以是 continue(不做任何操作),fire(处理窗口数据),purge(移除窗口和窗口中的数据),或者 fire + purge。一个Trigger的调用结果只是fire的话,那么会计算窗口并保留窗口原样,也就是说窗口中的数据仍然保留不变,等待下次Trigger fire的时候再次执行计算。一个窗口可以被重复计算多次知道它被 purge 了。在purge之前,窗口会一直占用着内存。
3、Evictor:在Trigger触发之后,在窗口被处理之前,Evictor(如果有Evictor的话)会用来剔除窗口中不需要的元素,相当于一个filter。
当Trigger fire了,窗口中的元素集合就会交给Evictor(如果指定了的话)。Evictor 主要用来遍历窗口中的元素列表,并决定最先进入窗口的多少个元素需要被移除。剩余的元素会交给用户指定的函数进行窗口的计算。如果没有 Evictor 的话,窗口中的所有元素会一起交给函数进行计算。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号