flink的特点
(1)事件驱动型
1、什么是事件驱动型应用程序:事件驱动的应用程序是有状态的应用程序,它从一个或多个事件中提取事件,并通过触发计算,状态更新或外部操作来对传入的事件做出反应。
2、事件驱动型应用程序与传统应用程序的区别:
1)程序与数据的位置:传统应用程序不要求程序和程序使用的数据位于相同的机器上,数据的位置对程序来说无关紧要;事件驱动程序则要求数据本地性,这有利于数据的快速计算
2)容错:传统应用程序一般不依赖容错机制,因处理逻辑链条较短且同一个程序内部并发较少,因此一般使用事务来限制数据异常。而事件驱动程序,需要7*24不间断执行,且增量计算比较常见,通过定期将检查点写入远程持久化存储来实现容错。
3、flink如何支持事件驱动型的应用程序
1)事件驱动的应用程序的限制由流处理器处理时间和状态的能力来定义,flink通过exactly once管理非常大的数据量。
2)Flink对事件时间的支持,高度可定制的窗口逻辑以及对时间的细粒度控制【通过ProcessFunction启用高级业务逻辑的实现】提供了支持。
3)Flink对于事件驱动的应用程序的突出功能是保存点savepoint。保存点是一致的状态映像,可用作兼容应用程序的起点。
4、典型的事件驱动型程序:欺诈识别,异常检测
(2)flink是典型的流式处理
1、在spark中一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
2、在flink中一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
1)无界数据流有一个开始但是没有结束,处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
2)有界数据流有明确定义的开始和结束,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
(3)提供精确一次(exactly once)的状态一致性保障。
1、状态一致性分类:at-most-once最多一次,at-least-once至少一次,exactly-once精准一次
2、端到端的状态一致性:实际应用时,不只是要求流处理器阶段的状态一致性,还要求source到sink阶段(从数据源到输出到持久化系统)的状态一致性
1)内部保证 – 依赖checkpoint
2)source端 – 需要外部源可以重设数据的读取位置
3)sink端 – 需要保证从故障恢复时,数据不会重复写入外部系统
a、sink端有两种实现方式,幂等(Idempotent)写入和事务性(Transactional)写入
事务性写入:预写日志(WAL)和两阶段提交(2PC)
3、flink到kafka的状态一致性的保证
1)内部 – 利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
2)source – kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
3)sink – kafka producer作为sink,通过过两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction
4、Exactly-once两段提交步骤
1)第一条数据来了之后,开启一个kafka的事务(transaction),正常写入kafka分区日志但标记为未提交,这就是预提交
2)jobmanager触发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知jobmanager
3)sink连接器收到barrier,保存当前状态,存入checkpoint,通知jobmanager,并开启下一阶段的事务,用于提价下个检查点的数据
4)jobmanager收到所有任务的通知,发生确认信息,表示checkpoint完成
5)sink任务收到jobmanager的确认信息,正式提交这段时间的数据
6)外部kafka关闭事务,提交的数据可以正常消费了
(4)flink的分层API
1、处理函数(ProcessFunctions):Flink 提供的ProcessFuntion是用来处理来自于一个或者两个输入流或者一段时间窗内的聚合的独立event。ProcessFunction提供了对时间和状态的细粒度控制。一个ProcessFunction可以任意的修改它的状态,并且也可以注册定时器在将来触发一个回调函数。
2、DataStream API:为很多常用的流式计算操作提供了基本操作,同时DataStream API基于函数的,比如map()、reduce()。
3、SQL和Table API
(5)支持有状态的计算
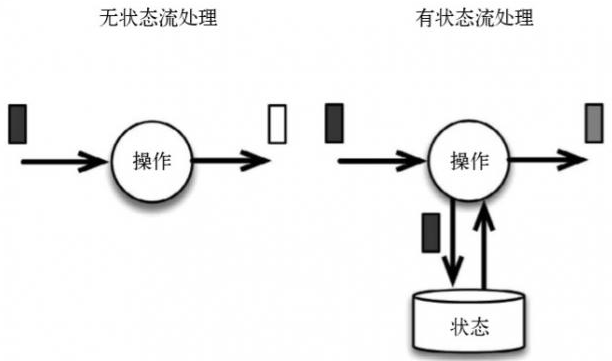
有状态计算是指在程序计算过程中,在Flink程序内部存储计算产生的中间结果,并提供给后续Function或算子计算结果使用。状态数据可以维系在本地存储中,这里的存储可以是Flink的堆内存或者堆外内存,也可以借助第三方的存储介质。和状态计算不同的是,无状态计算不会存储计算过程中产生的结果,也不会将结果用于下一步计算过程中,程序只会在当前的计算流程中实行计算,计算完成就输出结果,然后下一条数据接入,然后再处理。
(6)支持事件时间
1、处理时间:处理时间是指执行操作的机器系统时间。
2、事件时间:事件时间是每个发生在生产装置中的独立事件的时间。这个时间是在它们进入Flink和从记录中抽取的事件时间戳之前就包含在记录中的。
3、摄入时间:摄入时间是进入Flink的事件的时间。 摄入时间是位于事件时间和处理时间之间的概念。
(7)checkpoint与savepoint
1、checkpoint:Checkpoint指定触发生成时间间隔后,每当需要触发Checkpoint时,会向Flink程序运行时的多个分布式的Stream Source中插入一个Barrier标记,这些Barrier会根据Stream中的数据记录一起流向下游的各个Operator。当一个Operator接收到一个Barrier时,它会暂停处理Steam中新接收到的数据记录。因为一个Operator可能存在多个输入的Stream,而每个Stream中都会存在对应的Barrier,该Operator要等到所有的输入Stream中的Barrier都到达。当所有Stream中的Barrier都已经到达该Operator,这时所有的Barrier在时间上看来是同一个时刻点(表示已经对齐),在等待所有Barrier到达的过程中,Operator的Buffer中可能已经缓存了一些比Barrier早到达Operator的数据记录(Outgoing Records),这时该Operator会将数据记录(Outgoing Records)发射(Emit)出去,作为下游Operator的输入,最后将Barrier对应Snapshot发射(Emit)出去作为此次Checkpoint的结果数据。

2、savepoint:Flink Savepoint 作为实时任务的全局镜像,其在底层使用的代码和Checkpoint的代码是一样的,因为Savepoint可以看做 Checkpoint在特定时期的一个状态快照。
1)savepoint触发方式:使用 flink savepoint 命令触发 Savepoint,其是在程序运行期间触发 savepoint。
3、savepoint与checkpoint的对比:
1)概念:Checkpoint 是 自动容错机制 ,Savepoint 程序全局状态镜像 。
2)目的:Checkpoint 是程序自动容错,快速恢复 。Savepoint是 程序修改后继续从状态恢复,程序升级等。
3)行为类型:Checkpoint 是 Flink 系统行为 。Savepoint是用户触发。
4)状态文件保留策略:Checkpoint默认程序删除,可以设置CheckpointConfig中的参数进行保留 。Savepoint会一直保存,除非用户删除 。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号