Spark源码阅读04:Shuffle
Shuffle
Shuffle过程中,会等待上游不同分区数据执行完成再进行下一步操作,但是肯定不能在内存中等待,因为数据会大量堆积,所以一定会进行落盘操作!所以提高效率的办法:1)减少落盘的数据量(预聚合)。2)减少落盘的次数
而写磁盘和读磁盘又对应shuffle write和shuffle read两个阶段,这里有点像MapReduce
如果只有一个落盘文件,下游多个task都来读取这个文件,读取压力会很大;但是如果将一个文件拆分为多个文件,当task过多的时候又会产生小文件问题
于是还是对于一个节点保留一个落盘文件,只是将这个文件分成了多个块,然后会有一个索引文件保存索引,下游task会根据这个索引文件来找到需要读取的数据
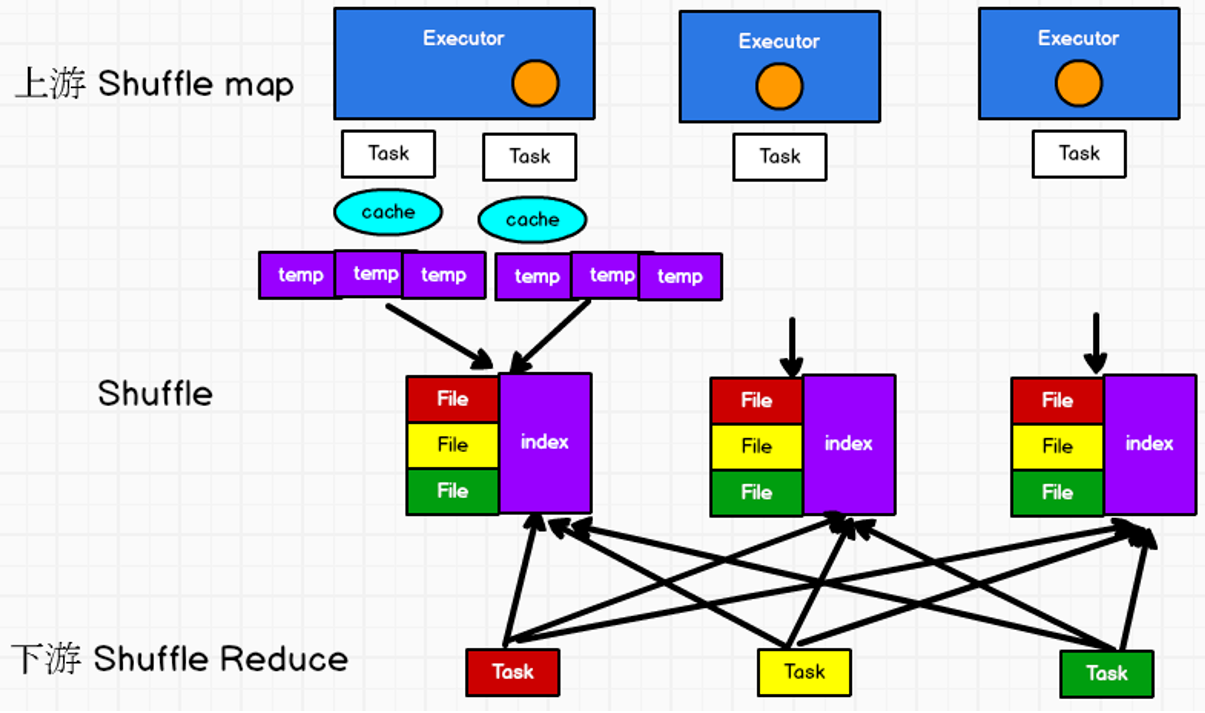
shuffle write
现在我们来阅读源码,首先找到org.apache.spark.scheduler.DAGScheduler类,然后搜索ShuffleMapTask找到代码块
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
}
点进去找到runTask方法,往下滑会找到与写磁盘相关的代码
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
}
找到getWriter方法,发现它根据第一个参数handle得到不同的处理器
| 处理器 | 写对象 | 判断条件 |
|---|---|---|
| SerializedShuffleHandle | UnsafeShuffleWriter | 1.序列化规则支持重定位操作(Java序列化不支持,Kryo支持);2.不能有预聚合;3.分区数目<=16777216 |
| BypassMergeSortShuffleHandle | BypassMergeSortShuffleWriter | 1.不能有预聚合;2.分区数目小于等于200 |
| BaseShuffleHandle | SortShuffleWriter | 其他情况 |
/** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
我们回退发现第一个参数传的是dep.shuffleHandle,点进去registerShuffle,发现注册处理器有不同的条件
/**
* Obtains a [[ShuffleHandle]] to pass to tasks.
*/
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
if (SortShuffleWriter.shouldBypassMergeSort(conf, dependency)) {
// If there are fewer than spark.shuffle.sort.bypassMergeThreshold partitions and we don't
// need map-side aggregation, then write numPartitions files directly and just concatenate
// them at the end. This avoids doing serialization and deserialization twice to merge
// together the spilled files, which would happen with the normal code path. The downside is
// having multiple files open at a time and thus more memory allocated to buffers.
// =>
def shouldBypassMergeSort(conf: SparkConf, dep: ShuffleDependency[_, _, _]): Boolean = {
// We cannot bypass sorting if we need to do map-side aggregation.
if (dep.mapSideCombine) { // 是否有map端的combine,即预聚合
false
} else {
// 阈值默认为200
val bypassMergeThreshold: Int = conf.getInt("spark.shuffle.sort.bypassMergeThreshold", 200)
dep.partitioner.numPartitions <= bypassMergeThreshold // 分区数目是否小于200
}
}
// <=
new BypassMergeSortShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
// Otherwise, try to buffer map outputs in a serialized form, since this is more efficient:
// =>
def canUseSerializedShuffle(dependency: ShuffleDependency[_, _, _]): Boolean = {
val shufId = dependency.shuffleId
val numPartitions = dependency.partitioner.numPartitions
if (!dependency.serializer.supportsRelocationOfSerializedObjects) { // 是否支持重定位操作,默认的Java序列化是不支持的,序列化框架Kryo支持
log.debug(s"Can't use serialized shuffle for shuffle $shufId because the serializer, " +
s"${dependency.serializer.getClass.getName}, does not support object relocation")
false
} else if (dependency.mapSideCombine) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because we need to do " +
s"map-side aggregation")
false
} else if (numPartitions > MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE) {
log.debug(s"Can't use serialized shuffle for shuffle $shufId because it has more than " +
s"$MAX_SHUFFLE_OUTPUT_PARTITIONS_FOR_SERIALIZED_MODE partitions")
false
} else {
log.debug(s"Can use serialized shuffle for shuffle $shufId")
true
}
}
}
// <=
new SerializedShuffleHandle[K, V](
shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
} else {
// Otherwise, buffer map outputs in a deserialized form:
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}
}
点进writer.write方法,会发现它是抽象方法,这里以实现类SortShuffleWriter为例!!!,在这里可以看见调用了更新索引并提交的writeIndexFileAndCommit方法
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records) // 插入数据
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp) // 写分区文件
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp) // 更新索引并提交
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
调用sorter.insertAll方法插入数据
// Data structures to store in-memory objects before we spill. Depending on whether we have an
// Aggregator set, we either put objects into an AppendOnlyMap where we combine them, or we
// store them in an array buffer.
@volatile private var map = new PartitionedAppendOnlyMap[K, C]
@volatile private var buffer = new PartitionedPairBuffer[K, C]
...
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
if (shouldCombine) { // 有预聚合,使用PartitionedAppendOnlyMap
// Combine values in-memory first using our AppendOnlyMap
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true) // 是否溢写磁盘
}
} else { // 没有预聚合,使用PartitionedPairBuffer
// Stick values into our buffer
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false) // 是否溢写磁盘
}
}
}
maybeSpill=> spill=> spillMemoryIteratorToDisk,在spill方法中,会判断是否应该溢写磁盘,溢写磁盘后会释放相应的内存;在spillMemoryIteratorToDisk中会先创建一块缓冲区再写磁盘,所以这时候会有很多的临时文件
在插入数据之后,会调用sorter.writePartitionedFile方法写分区文件,会根据是否溢写来合并所有数据
/**
* Write all the data added into this ExternalSorter into a file in the disk store. This is
* called by the SortShuffleWriter.
*
* @param blockId block ID to write to. The index file will be blockId.name + ".index".
* @return array of lengths, in bytes, of each partition of the file (used by map output tracker)
*/
def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = {
// Track location of each range in the output file
val lengths = new Array[Long](numPartitions)
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics().shuffleWriteMetrics)
if (spills.isEmpty) {
// Case where we only have in-memory data,只需要操作内存中的数据
val collection = if (aggregator.isDefined) map else buffer
val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
while (it.hasNext) {
val partitionId = it.nextPartition()
while (it.hasNext && it.nextPartition() == partitionId) {
it.writeNext(writer)
}
val segment = writer.commitAndGet()
lengths(partitionId) = segment.length
}
} else {
// We must perform merge-sort; get an iterator by partition and write everything directly.
for ((id, elements) <- this.partitionedIterator) {
if (elements.hasNext) {
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
val segment = writer.commitAndGet()
lengths(id) = segment.length
}
}
}
writer.close()
context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(peakMemoryUsedBytes)
lengths
}
点击进入this.partitionedIterator
/**
* Return an iterator over all the data written to this object, grouped by partition and
* aggregated by the requested aggregator. For each partition we then have an iterator over its
* contents, and these are expected to be accessed in order (you can't "skip ahead" to one
* partition without reading the previous one). Guaranteed to return a key-value pair for each
* partition, in order of partition ID.
*
* For now, we just merge all the spilled files in once pass, but this can be modified to
* support hierarchical merging.
* Exposed for testing.
*/
def partitionedIterator: Iterator[(Int, Iterator[Product2[K, C]])] = {
val usingMap = aggregator.isDefined
val collection: WritablePartitionedPairCollection[K, C] = if (usingMap) map else buffer
if (spills.isEmpty) {
// Special case: if we have only in-memory data, we don't need to merge streams, and perhaps
// we don't even need to sort by anything other than partition ID
if (!ordering.isDefined) {
// The user hasn't requested sorted keys, so only sort by partition ID, not key
groupByPartition(destructiveIterator(collection.partitionedDestructiveSortedIterator(None)))
} else {
// We do need to sort by both partition ID and key
groupByPartition(destructiveIterator(
collection.partitionedDestructiveSortedIterator(Some(keyComparator))))
}
} else {
// Merge spilled and in-memory data,同时合并溢写的数据和内存中的数据
merge(spills, destructiveIterator(
collection.partitionedDestructiveSortedIterator(comparator)))
}
}
点击merge方法,这里会进行归并排序
/**
* Merge a sequence of sorted files, giving an iterator over partitions and then over elements
* inside each partition. This can be used to either write out a new file or return data to
* the user.
*
* Returns an iterator over all the data written to this object, grouped by partition. For each
* partition we then have an iterator over its contents, and these are expected to be accessed
* in order (you can't "skip ahead" to one partition without reading the previous one).
* Guaranteed to return a key-value pair for each partition, in order of partition ID.
*/
private def merge(spills: Seq[SpilledFile], inMemory: Iterator[((Int, K), C)])
: Iterator[(Int, Iterator[Product2[K, C]])] = {
val readers = spills.map(new SpillReader(_))
val inMemBuffered = inMemory.buffered
(0 until numPartitions).iterator.map { p =>
val inMemIterator = new IteratorForPartition(p, inMemBuffered)
val iterators = readers.map(_.readNextPartition()) ++ Seq(inMemIterator)
if (aggregator.isDefined) {
// Perform partial aggregation across partitions
(p, mergeWithAggregation(
iterators, aggregator.get.mergeCombiners, keyComparator, ordering.isDefined))
} else if (ordering.isDefined) {
// No aggregator given, but we have an ordering (e.g. used by reduce tasks in sortByKey);
// sort the elements without trying to merge them
(p, mergeSort(iterators, ordering.get)) // 归并排序
} else {
(p, iterators.iterator.flatten)
}
}
}
回退到提交分区文件,点击进入shuffleBlockResolver.writeIndexFileAndCommit方法,发现在里面对临时文件进行了重命名
if (indexFile.exists()) {
indexFile.delete()
}
if (dataFile.exists()) {
dataFile.delete()
}
if (!indexTmp.renameTo(indexFile)) {
throw new IOException("fail to rename file " + indexTmp + " to " + indexFile)
}
if (dataTmp != null && dataTmp.exists() && !dataTmp.renameTo(dataFile)) {
throw new IOException("fail to rename file " + dataTmp + " to " + dataFile)
}
shuffle read
相应地回退到ResultStage部分代码块
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
点进ResultTask找到runTask方法
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
func(context, rdd.iterator(partition, context))
}
然后进入rdd.iterator
/**
* Internal method to this RDD; will read from cache if applicable, or otherwise compute it.
* This should ''not'' be called by users directly, but is available for implementors of custom
* subclasses of RDD.
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
点击getOrCompute,计算或者得到RDD
/**
* Gets or computes an RDD partition. Used by RDD.iterator() when an RDD is cached.
*/
private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = {
val blockId = RDDBlockId(id, partition.index)
var readCachedBlock = true
// This method is called on executors, so we need call SparkEnv.get instead of sc.env.
SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {
readCachedBlock = false
computeOrReadCheckpoint(partition, context)
}) match {
case Left(blockResult) =>
if (readCachedBlock) {
val existingMetrics = context.taskMetrics().inputMetrics
existingMetrics.incBytesRead(blockResult.bytes)
new InterruptibleIterator[T](context, blockResult.data.asInstanceOf[Iterator[T]]) {
override def next(): T = {
existingMetrics.incRecordsRead(1)
delegate.next()
}
}
} else {
new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]])
}
case Right(iter) =>
new InterruptibleIterator(context, iter.asInstanceOf[Iterator[T]])
}
}
再点computeOrReadCheckpoint=>compute,发现它是一个抽象方法,于是全局搜索找到org.apache.spark.rdd.ShuffledRDD,找到compute方法,最终发现读磁盘相关的代码
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号