Spark03 SQL
1. 概述
Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块
1.1 历史
Hive是早期唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:Drill、Impala、Shark
SparkSQL的前身就是Shark,Shark是伯克利实验室Spark生态环境的组件之一,是基于Hive所开发的工具,内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,Shark的出现,使得SQL-on-Hadoop的性能比Hive有了10-100倍的提高
但是随着Spark的发展,Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark各个组件的相互集成,所以提出了SparkSQL项目
SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便,真可谓“退一步,海阔天空”
-
数据兼容方面:SparkSQL不但兼容Hive,还可以从RDD、parquet文件、JSON文件中获取数据,未来版本甚至支持获取RDBMS数据以及cassandra等NoSQL数据
-
性能优化方面:除了采取In-Memory Columnar Storage、byte-code generation等优化技术外、将会引进Cost Model对查询进行动态评估、获取最佳物理计划等等
-
组件扩展方面:无论是SQL的语法解析器、分析器还是优化器都可以重新定义,进行扩展
2014年6月1日Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句号,但也因此发展出两个支线:SparkSQL和Hive on Spark
其中SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎
对于开发人员来讲,SparkSQL可以简化RDD的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是SparkSQL。Spark SQL为了简化RDD的开发,提高开发效率,提供了2个编程抽象,类似Spark Core中的RDD
-
DataFrame
-
DataSet
1.2 Spark SQL特点
- 易整合:无缝的整合了 SQL 查询和 Spark 编程
- 统一的数据访问:使用相同的方式连接不同的数据源
- 兼容Hive:在已有的仓库上直接运行 SQL 或者 HiveQL
- 标准数据连接:通过 JDBC 或者 ODBC 来连接
1.3 DataFrame是什么?
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格
DataFrame与RDD的主要区别在于,DataFrame带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型
这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标;反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在 stage层面 进行简单、通用的流水线优化
1.4 DataSet是什么
DataSet是分布式数据集合。DataSet是Spark 1.6中添加的一个新抽象,是DataFrame的一个扩展。它提供了RDD的优势(强类型,使用强大的lambda函数的能力)以及Spark SQL优化执行引擎的优点。DataSet也可以使用功能性的转换(操作map,flatMap,filter等等)
-
DataSet是DataFrame API的一个扩展,是SparkSQL最新的数据抽象
-
用户友好的API风格,既具有类型安全检查也具有DataFrame的查询优化特性
-
用样例类来对DataSet中定义数据的结构信息,样例类中每个属性的名称直接映射到DataSet中的字段名称
-
DataSet是强类型的。比如可以有DataSet[Car],DataSet[Person]
-
DataFrame是DataSet的特例,DataFrame=DataSet[Row] ,所以可以通过as方法将DataFrame转换为DataSet。Row是一个类型,跟Car、Person这些的类型一样,所有的表结构信息都用Row来表示。获取数据时需要指定顺序
1.5 RDD、DataFrame、DataSet
在SparkSQL中Spark为我们提供了两个新的抽象,分别是DataFrame和DataSet。他们和RDD有什么区别呢?首先从版本的产生上来看:
-
Spark1.0 => RDD
-
Spark1.3 => DataFrame
-
Spark1.6 => Dataset
如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同是的他们的执行效率和执行方式。在后期的Spark版本中,DataSet有可能会逐步取代RDD和DataFrame成为唯一的API接口
1.5.1 三者的共性
-
RDD、DataFrame、DataSet全都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
-
三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算
-
三者有许多共同的函数,如filter,排序等
-
在对DataFrame和Dataset进行操作许多操作都需要:
import spark.implicits._(注意这里的spark不是包名,而是指SparkSession对象,所以在创建好SparkSession对象后尽量直接导入) -
三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出
-
三者都有partition的概念
-
DataFrame和DataSet均可使用模式匹配获取各个字段的值和类型
1.5.2 三者的区别
1)RDD
-
RDD一般和spark mllib同时使用
-
RDD不支持spark sql操作
2)DataFarme
-
与RDD和Dataset不同,DataFrame每一行的类型固定为Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值
-
DataFrame与DataSet一般不与 spark mllib 同时使用
-
DataFrame与DataSet均支持 SparkSQL 的操作,比如select,groupby之类,还能注册临时表/视窗,进行 sql 语句操作
-
DataFrame与DataSet支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
3)DataSet
-
Dataset和DataFrame拥有完全相同的成员函数,区别只是每一行的数据类型不同。 DataFrame其实就是DataSet的一个特例
type DataFrame = Dataset[Row] -
DataFrame也可以叫Dataset[Row],每一行的类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面getAS方法或者模式匹配拿出特定字段。而Dataset中,在自定义了case class之后可以很自由的获得每一行的信息
1.5.3 三者的转换
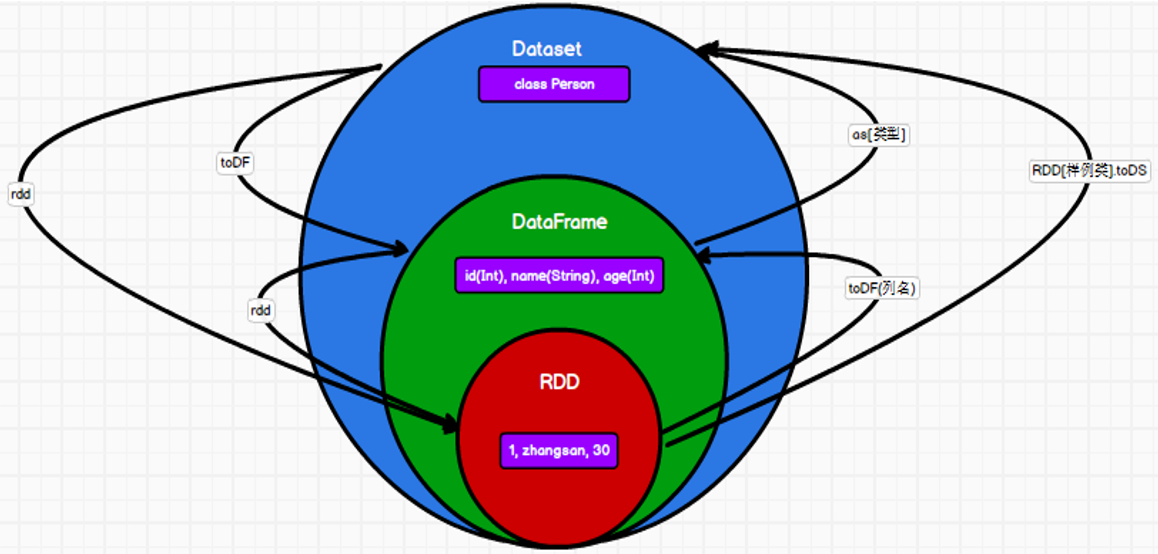
2. 代码开发
2.1 添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
2.2 代码实现
object SparkSQL01_Demo {
def main(args: Array[String]): Unit = {
// 创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL01_Demo")
// 创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// RDD=>DataFrame=>DataSet转换需要引入隐式转换规则,否则无法转换
// spark不是包名,是上下文环境中SparkSession对象名
import spark.implicits._
// 读取json文件 创建DataFrame {"username": "lisi","age": 18}
val df: DataFrame = spark.read.json("input/test.json")
// df.show()
// SQL风格语法
df.createOrReplaceTempView("user")
// spark.sql("select avg(age) from user").show
// DSL风格语法
//df.select("username","age").show()
// *****RDD=>DataFrame=>DataSet*****
// 1.RDD
val rdd1: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List((1,"zhangsan",30),(2,"lisi",28),(3,"wangwu",20)))
// 2.DataFrame
val df1: DataFrame = rdd1.toDF("id","name","age")
// df1.show()
// 3.DateSet
val ds1: Dataset[User] = df1.as[User]
// ds1.show()
// *****DataSet=>DataFrame=>RDD*****
// 1.DataFrame
val df2: DataFrame = ds1.toDF()
// 2.RDD 返回的RDD类型为Row,里面提供的getXXX方法可以获取字段值,类似jdbc处理结果集,但是索引从0开始
val rdd2: RDD[Row] = df2.rdd
//rdd2.foreach(a=>println(a.getString(1)))
// *****RDD=>DataSet*****
rdd1.map{
case (id,name,age)=>User(id,name,age)
}.toDS()
// *****DataSet=>=>RDD*****
ds1.rdd
// 释放资源
spark.stop()
}
}
case class User(id:Int,name:String,age:Int)
2.3 用户自定义函数
2.3.1 UDF
2.3.2 UDAF
2.4 数据的加载和保存
2.4.1 通用的加载和保存方式
1)加载数据
scala> spark.read.format("…")[.option("…")].load("…")
-
format("…"):指定加载的数据类型,包括"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"
-
load("…"):在"csv"、"jdbc"、"json"、"orc"、"parquet"和"textFile"格式下需要传入加载数据的路径
-
option("…"):在"jdbc"格式下需要传入JDBC相应参数,url、user、password和dbtable
2)保存数据
scala> df.write.format("…")[.option("…")].save("…")
保存操作可以使用 SaveMode指明如何处理数据,通过mode()方法来设置,但是注意它是没有加锁的,也不是原子操作
SaveMode常量值以及具体使用方式如下:
| Scala/Java | Any Language | Meaning |
|---|---|---|
| SaveMode.ErrorIfExists(default) | "error"(default) | 如果文件已经存在则抛出异常 |
| SaveMode.Append | "append" | 如果文件已经存在则追加 |
| SaveMode.Overwrite | "overwrite" | 如果文件已经存在则覆盖 |
| SaveMode.Ignore | "ignore" | 如果文件已经存在则忽略 |
df.write.mode("append").json("/opt/module/data/output")
2.4.2 Parquet
Spark SQL的默认数据源为Parquet格式。Parquet是一种能够有效存储嵌套数据的列式存储格式
数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作,不需要使用format。修改配置项spark.sql.sources.default,可修改默认数据源格式
1)加载数据
scala> val df = spark.read.load("examples/src/main/resources/users.parquet")
scala> df.show
2)保存数据
scala> var df = spark.read.json("/opt/module/data/input/people.json")
//保存为parquet格式
scala> df.write.mode("append").save("/opt/module/data/output")
2.4.3 JSON
Spark SQL 能够自动推测 JSON数据集的结构,并将它加载为一个Dataset[Row]
可以通过SparkSession.read.json()去加载 JSON 文件
注意:Spark读取的JSON文件不是传统的 JSON文件,每一行都应该是一个 JSON串。格式如下:
{"name":"Michael"}
{"name":"Andy","age":30}
[{"name":"Justin","age":19},{"name":"Justin","age":19}]
1)导入隐式转换
import spark.implicits._
2)加载JSON文件
val path = "/opt/module/spark-local/people.json"
val peopleDF = spark.read.json(path)
3)创建临时表
peopleDF.createOrReplaceTempView("people")
4)数据查询
val teenagerNamesDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19")
teenagerNamesDF.show()
+------+
| name|
+------+
|Justin|
+------+
2.4.4 CSV
spark.read.format("csv").option("sep", ";").option("inferSchema", "true").option("header", "true").load("data/user.csv")
2.4.5 MySQL
1)导入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
2)读取数据
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
//创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
//方式1:通用的load方法读取
spark.read.format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user")
.load().show
//方式2:通用的load方法读取 参数另一种形式
spark.read.format("jdbc")
.options(Map("url"->"jdbc:mysql://linux1:3306/spark-sql?user=root&password=123123",
"dbtable"->"user","driver"->"com.mysql.jdbc.Driver")).load().show
//方式3:使用jdbc方法读取
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123123")
val df: DataFrame = spark.read.jdbc("jdbc:mysql://linux1:3306/spark-sql", "user", props)
df.show
//释放资源
spark.stop()
3)写入数据
case class User2(name: String, age: Long)
。。。
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
//创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val rdd: RDD[User2] = spark.sparkContext.makeRDD(List(User2("lisi", 20), User2("zs", 30)))
val ds: Dataset[User2] = rdd.toDS
//方式1:通用的方式 format指定写出类型
//方式2:通过jdbc方法
val props: Properties = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "123123")
ds.write.mode(SaveMode.Append).jdbc("jdbc:mysql://linux1:3306/spark-sql", "user", props)
//释放资源
spark.stop()
2.4.6 Hive
Spark内置了Hive,但是使用较少。在这里只说明外部Hive的使用方式
Spark想链接外部已经部署好的Hive,首先需要进行如下操作:
-
Spark要接管Hive需要把hive-site.xml拷贝到conf/目录下
-
把Mysql的驱动copy到jars/目录下
-
如果访问不到hdfs,则需要把core-site.xml和hdfs-site.xml拷贝到conf/目录下
然后启动Thrift Server:
sbin/start-thriftserver.sh
使用beeline连接Thrift Server:
bin/beeline -u jdbc:hive2://linux1:10000 -n root
代码操作Hive
1)导入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
2)创建 Spark Session
// 创建SparkSession
val spark: SparkSession = SparkSession
.builder()
.enableHiveSupport()
.master("local[*]")
.appName("sql")
.getOrCreate()
注意:在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址:config("spark.sql.warehouse.dir", "hdfs://linux1:8020/user/hive/warehouse")
如果在执行操作时出现Permission denied错误,可以代码最前面增加如下代码解决:
// 此处的root改为你们自己的hadoop用户名称
System.setProperty("HADOOP_USER_NAME", "root")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号