Spark01 概览
参考:【尚硅谷 Spark】
【《大数据处理框架Apache Spark设计与实现》】
【Spark官方文档】
1. 简介
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎
Spark or MapReduce ?
Hadoop的 MR框架 和 Spark框架 都是数据处理框架,那么我们在使用时如何选择呢?
1)Hadoop MapReduce由于其设计初衷并不是为了满足循环迭代式数据处理,因此在多并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存在诸多计算效率等问题
所以Spark应运而生,Spark就是在传统的MapReduce 计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型
2)机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。而Spark所基于的scala语言恰恰擅长函数的处理
3)Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比MapReduce丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法
4)Spark和Hadoop的根本差异是多个作业之间的数据通信问题:Spark多个作业之间数据通信是基于内存,而Hadoop是基于磁盘
5)Spark Task的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程的方式
6)Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交互都要依赖于磁盘交互
7)Spark的缓存机制比HDFS的缓存机制高效
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark确实会比MapReduce更有优势。但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致Job执行失败,此时,MapReduce其实是一个更好的选择,所以Spark并不能完全替代MR
对比MapReduce,Spark有哪些优势?
从编程模型角度来说,Spark的编程模型更具有通用性和易用性
(1)通用性
基于函数式编程思想,MapReduce将数据类型抽象为<K,V>格式,并将数据处理操作抽象为map()和reduce()两个算子,这两个算子可以表达一大部分数据处理任务。因此,MapReduce为这两个算子设计了固定的处理流程map—Shuffle—reduce
但是map—Shuffle—reduce模式只适用于表达类似foldByKey()、reduceByKey()、aggregateByKey()的处理流程,而像cogroup()、join()、cartesian()、coalesce()的流程需要更灵活的表达方式。那么如何达到灵活呢?Spark转变了思路,在两方面进行了优化改进:
一方面借鉴了DryadLINQ/FlumeJava的思想,将输入/输出、中间数据抽象表达为一个数据结构RDD,相当于在Java中定义了class,然后可以根据不同类型的中间数据,生成不同的RDD(相当于Java中生成不同类型的object)。这样,数据结构就变得灵活了,不再拘泥于MapReduce中的<K,V>格式,而且中间数据变得可定义、可表示、可操作、可连接。
另一方面通过可定义的数据依赖关系来灵活连接中间数据。在MapReduce中,数据依赖关系只有ShuffleDependency,而Spark数据处理操作包含多种多样的数据依赖关系,Spark对这些数据依赖关系进行了分类,并总结出ShuffleDependency、NarrowDependency(包含多种子依赖关系)。这样,Spark可以根据数据操作的计算逻辑灵活选择数据依赖关系来实现。另外,Spark使用DAG图来组合数据处理操作,比固定的map—Shuffle—reduce处理流程表达能力更强
(2)易用性
基于灵活的数据结构和依赖关系,Spark原生实现了很多常见的数据操作,如MapReduce中的map()、reduceByKey(),SQL中的filter()、groupByKey()、join()、sortByKey(),Pig Latin中的cogroup(),集合操作union()、intersection(),以及特殊的zip()等。通过使用和组合这些操作,开发人员容易实现复杂的数据处理流程
另外,由于数据结构RDD上的操作可以由Spark自动并行化,程序开发时更像在写普通程序,不用考虑这些操作到底是本地的还是由Spark分布执行的
另外,使用RDD上的数据操作,开发人员更容易将数据操作与普通程序的控制流进行结合。例如,在实现迭代程序时,可以使用普通程序的while语句,而while循环内部可以使用RDD操作。在MapReduce中,实现迭代程序比较困难,需要不断手动提交job,而Spark提供了action()操作,job分割和提交都完全由Spark框架来进行,易用性得到了进一步提高
虽然Spark比MapReduce更加通用、易用,但还不能达到普通语言(如Java)的灵活性,具体存在两个缺点
第一个,Spark中的操作都是单向操作,单向的意思是中间数据不可修改。在普通Java程序中,在数据结构中存放的数据是可以直接被修改的,而Spark只能生成新的数据作为修改后的结果
第二个,Spark中的操作是粗粒度的。粗粒度操作是指RDD上的操作是面向分区的,也就是每个分区上的数据操作是相同的。假设我们处理partition1上的数据时需要partition2中的数据,并不能通过RDD的操作访问到partition2的数据,只能通过添加聚合操作来将数据汇总在一起处理,而普通Java程序的操作是细粒度的,我们随时可以访问数据结构中的数据
当然,这两个缺点也是并行化设计权衡后的结果,即这两个缺点是并行化的优点,粗粒度可以方便并行执行,如一台机器处理一个分区,而单向操作有利于错误容忍
Spark 核心模块

-
Spark Core
Spark Core中提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX,MLlib都是在Spark Core的基础上进行扩展的
-
Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据
-
Spark Streaming
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API
-
Spark MLlib
MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语
-
Spark GraphX
GraphX是Spark面向图计算提供的框架与算法库
提交应用
与Hadoop类似,Spark采用的也是Master-Worker结构,首先需要理解一些概念,简单来说,Master节点负责管理应用和任务,Worker节点负责执行任务
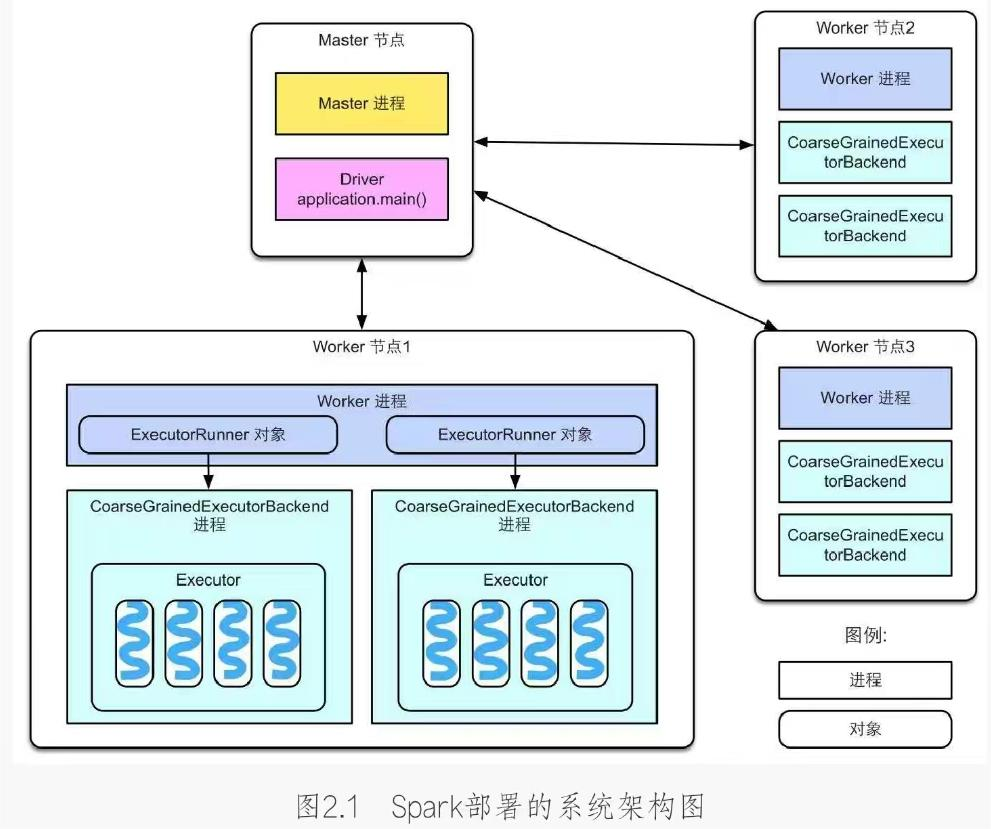
那么Driver又是什么呢?
Spark Driver,也就是Spark驱动程序,指实际在 运行Spark应用中main()函数的进程
The process running the main() function of the application and creating the SparkContext
Driver独立于Master进程。如果是YARN集群,那么Driver也可能被调度到Worker节点上运行
为什么不推荐 在自己的PC上运行Driver,然后通过网络与远程的Master进程连接?
一个原因是需要本地安装一个与集群一样的Spark版本;另一个原因是自己的PC一般和集群不在同一个网段,Driver和Worker节点之间的通信会很慢
什么是task?
task,即Spark应用的计算任务。Driver在运行Spark应用的main()函数时,会将应用拆分为多个计算任务,然后分配给多个Executor执行
task是Spark中最小的计算单位,不能再拆分。task以线程方式运行在Executor进程中,执行具体的计算任务,如map算子、reduce算子等。由于Executor可以配置多个CPU,而1个task一般使用1个CPU,因此当Executor具有多个CPU时,可以运行多个task。例如,在上图中Worker节点1有8个CPU,启动了2个Executor,每个Executor可以并行运行4个task。Executor的总内存大小由用户配置,而且Executor的内存空间由多个task共享
如果上述解释不够清楚,那么我们可以用一个直观例子来理解Master、Worker、Driver、Executor、task的关系
例如,一个农场主(Master)有多片草场(Worker),农场主要把草场租给3个牧民来放马、牛、羊。假设现在有3个项目(application)需要农场主来运作:第1个牧民需要一片牧场来放100匹马,第2个牧民需要一片牧场来放50头牛,第3个牧民需要一片牧场来放80只羊。每个牧民可以看作是一个Driver,而马、牛、羊可以看作是task。为了保持资源合理利用、避免冲突,在放牧前,农场主需要根据项目需求为每个牧民划定可利用的草场范围,而且尽量让每个牧民在每个草场都有一小片可放牧的区域(Executor)。在放牧时,每个牧民(Driver)只负责管理自己的动物(task),而农场主(Master)负责监控草场(Worker)、牧民(Driver)等状况。来自《大数据处理框架Apache Spark设计与实现》
基于Yarn环境的提交流程
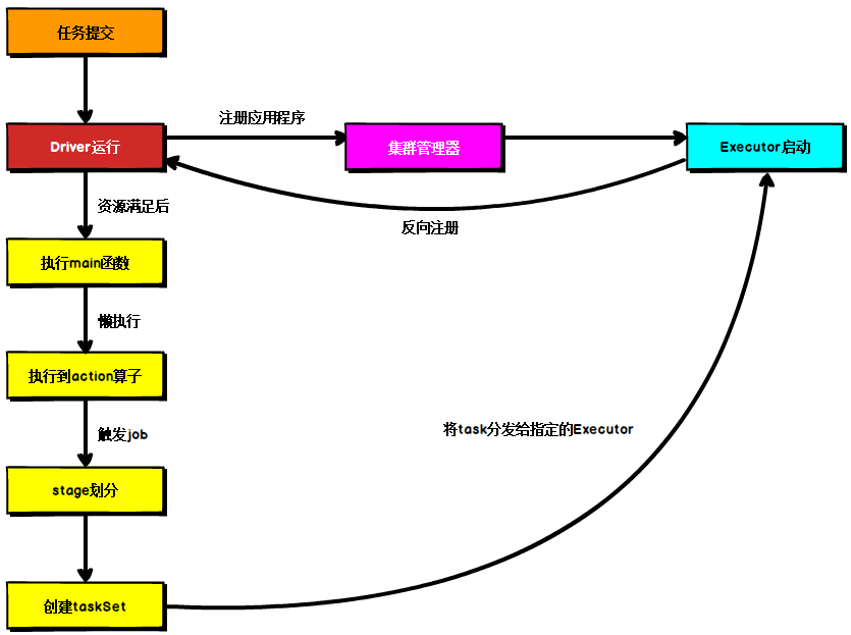
例子:
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
bin/spark-submit \
--class <main-class>
--master <master-url> \
... # other options
<application-jar> \
[application-arguments]
| 参数 | 解释 |
|---|---|
| --class | Spark程序 中包含主函数的类 |
| --master | Spark程序 运行的模式(环境),例如 spark://host:port, yarn, local |
| --deploy-mode | 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client。区别在于Driver程序运行的节点位置 |
| --num-executors | 配置Executor的数量 |
| --executor-memory 1G | 指定每个executor可用内存为1G |
| --total-executor-cores 2 | 指定所有executor使用的cpu核数为2个 |
| --executor-cores | 指定每个executor使用的cpu核数 |
| application-jar | 打包好的应用jar,包含依赖。这个URL在集群中全局可见。 比如,hdfs://共享存储系统;如果是file://path,那么所有的节点的path都包含同样的jar |
| application-arguments | 传给 main() 方法的参数 |
部署模式对比
| 模式 | Spark安装机器数 | 需启动的进程 | 所属者 | 应用场景 |
|---|---|---|---|---|
| Local | 1 | 无 | Spark | 测试 |
| Standalone | 3 | Master 及 Worker | Spark | 单独部署 |
| Yarn | 1 | Yarn 及 HDFS | Hadoop | 混合部署 |
端口号
-
Spark查看当前Spark-shell运行任务情况端口号:4040(计算)
-
Spark Master内部通信服务端口号:7077
-
Standalone模式下,Spark Master Web端口号:8080(资源)
-
Spark历史服务器端口号:18080
-
Hadoop YARN任务运行情况查看端口号:8088

 浙公网安备 33010602011771号
浙公网安备 33010602011771号