Spark02 RDD核心编程
参考:【尚硅谷 Spark】
【《大数据处理框架Apache Spark设计与实现》】
【Spark官方文档】
2. 核心编程
逻辑处理流程
1)数据源
数据源表示的是原始数据,数据可以存放在本地文件系统和分布式系统中,对于流式处理,数据源还可以是网络流等
2)数据模型
我们怎么对数据源进行抽象?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合
-
弹性
-
存储的弹性:内存与磁盘的自动切换
-
容错的弹性:数据丢失可以自动恢复
-
计算的弹性:计算出错重试机制
-
分片的弹性:可根据需要重新分片
-
-
分布式:数据存储在大数据集群不同节点上
-
数据集:RDD封装了计算逻辑,并不保存数据
-
数据抽象:RDD是一个抽象类,需要子类具体实现
-
不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑
-
可分区、并行计算
根据不同的数据类型、不同的计算逻辑,以及不同的数据依赖,Spark分为了ParallelCollectionRDD、MapPartitionsRDD、ShuffledRDD等不同类型的RDD
3)数据操作
Spark将数据操作分为transformation和action算子,区别在于,action算子一般是对数据结果进行后处理,产生输出结果,而且会触发任务执行
4)计算结果处理
有两种处理方式,一种是 直接将计算结果存放到分布式文件系统中,另一种是在 Driver端收集后 再处理
2.1 创建RDD
-
从集合中创建
val rdd1 = sparkContext.parallelize( List(1,2,3,4) ) // makeRDD底层就是采用的parallelize方法,只是语义更清晰 val rdd2 = sparkContext.makeRDD( List(1,2,3,4) ) -
从外部文件创建
val fileRDD: RDD[String] = sparkContext.textFile("input") -
由其他RDD转换
-
直接new,一般由Spark框架自身使用
2.2 转换算子
RDD根据数据处理方式的不同将算子整体上分为Value类型、双Value类型和Key-Value类型
2.2.1 Value类型
1)map
将数据进行逐条映射转换,一条数据对应一条数据
2)mapPartitions
将待处理的数据 以分区为单位 发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据
3)mapPartitionsWithIndex
在mapPartitions基础上,处理的同时可以获取 当前分区索引
4)flatMap
扁平映射,将处理的数据进行扁平化后再进行映射处理
一条数据可以得到多条数据的List,但是最后会被拉直;处理后可以看作一条数据对应了多条数据
5)glom
def glom(): RDD[Array[T]]
转换为数组,分区不变
val intListRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val glomRDD: RDD[Array[Int]] = intListRDD.glom()
6)groupBy
对数据按 指定规则 进行分组,不同组的数据可以在一个分区中,会产生shuffle操作,极致情况下 数据可能分在一个分区中
7)filter
过滤 保留 符合规则的数据,可能会导致数据倾斜问题
8)sample
def sample(
withReplacement: Boolean, // true采取有放回的泊松算法,false则采取不放回的伯努利算法
fraction: Double, // 相应算法的参数
seed: Long = Utils.random.nextLong): RDD[T]
根据制定规则对数据进行采样,可以缓解数据倾斜的问题
9)distinct
对数据进行去重
10)coalesce
缩减分区,用于大数据集过滤后,存在过多的小任务时,通过缩减分区可以提高小数据集的执行效率
但是可能会产生数据倾斜问题,可以传入第二个参数shuffle,让数据不倾斜
11)repartition
该操作内部其实执行的是coalesce操作,参数shuffle的默认值为true
无论是将分区数多的RDD转换为分区数少的RDD,还是将分区数少的RDD转换为分区数多的RDD,repartition操作都可以完成,因为无论如何都会经shuffle过程
11)sortBy
def sortBy[K](
f: (T) => K, // 根据什么排序
ascending: Boolean = true, // 是否升序,默认升序
numPartitions: Int = this.partitions.length // 排序后的分区数,默认与原来一致
)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
2.2.2 双Value类型
1)intersection:求交集
2)union:求并集
3)subtract:求差集
4)zip
将两个RDD中的元素,以键值对的形式进行合并
其中,键值对中的Key为第1个RDD中的元素,Value为第2个RDD中相同位置的元素
2.2.3 Key-Value类型
1)partitionBy
将数据按照指定Partitioner重新进行分区,Spark默认的分区器是HashPartitioner
2)reduceByKey
可以将数据按照相同的Key对Value进行聚合
3)groupByKey
根据key对value进行分组
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
groupByKey()在不同情况下会生成不同类型的RDD和数据依赖关系
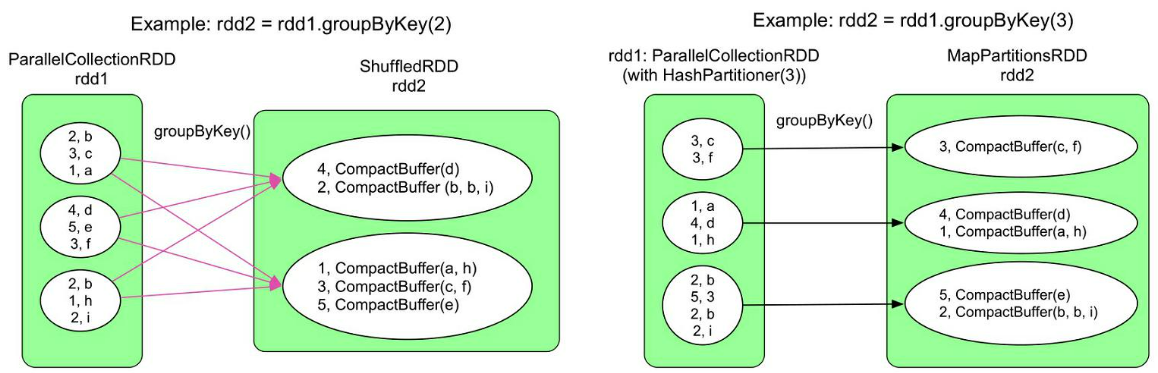
rdd1已经提前使用Hash划分进行了分区,具有相同Hash值的数据已经在同一个分区,而且我们设定的groupByKey()生成的RDD的分区个数与rdd1一致,那么我们只需要在每个分区中进行groupByKey()操作,不需要再使用ShuffleDependency,具体见示例代码
val inputRDD = sc.parallelize(Array[(Int, Char)]((2, 'b'), (3, 'c'), (1, 'a'), (4, 'd'), (5, 'e'), (3, 'f'), (2, 'b'), (1, 'h'), (2, 'i')), 3)
// 使用Hash划分对inputRDD进行划分,得到的inputRDD2就是右图中的rdd1
val inputRDD2 = inputRDD.partitionBy(new HashPartitioner(3))
// inputRDD2.partitioner与resultRDD的partitioner相同,不需要ShuffleDependency
val resultRDD = inputRDD2.groupByKey(3)
需要注意的是,在通常情况下,rdd1.partitioner与rdd2.partitioner不同,因此会产生ShuffleDependency,详见
reduceByKey和groupByKey的区别?
从shuffle的角度:reduceByKey和groupByKey都存在shuffle的操作,但是reduceByKey可以在shuffle前对分区内相同key的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而groupByKey只是进行分组,不存在数据量减少的问题,reduceByKey性能比较高
从功能的角度:reduceByKey其实包含分组和聚合的功能。groupByKey只能分组,不能聚合,所以在分组聚合的场合下,推荐使用reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用groupByKey
Shuffle操作必须要落盘,因此会增加IO的时间
4)cogroup
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
cogroup()与groupByKey()的不同在于cogroup()可以将多个RDD聚合为一个RDD
因此,其生成的RDD与多个parent RDD存在依赖关系。一般来说,聚合关系需要ShuffleDependency,但也存在特殊情况。例如,在groupByKey()操作中,如果child RDD和parent RDD使用的partitioner相同且分区个数也相同,那么没有必要使用ShuffleDependency,使用OneToOneDewpendency即可
更为特殊的是,由于cogroup()可以聚合多个RDD,因此可能对一部分RDD采用ShuffleDependency,而对另一部分RDD采用OneToOneDependency。图中的上图展示的CoGroupedRDD与rdd1、rdd2之间都是ShuffleDependency,而图中的下图展示的CoGroupedRDD与rdd1之间是OneToOneDependency,原因是rdd1和CoGroupedRDD具有相同的partitioner(都是HashPartitioner)且分区个数相同,rdd1中每个record可以直接流入CoGroupedRDD进行聚合,不需要ShuffleDependency。对于rdd2,其分区个数和partitioner都与CoGroupedRDD不一致,因此还需要将rdd2中的数据通过ShuffleDependency分发到CoGroupedRDD中
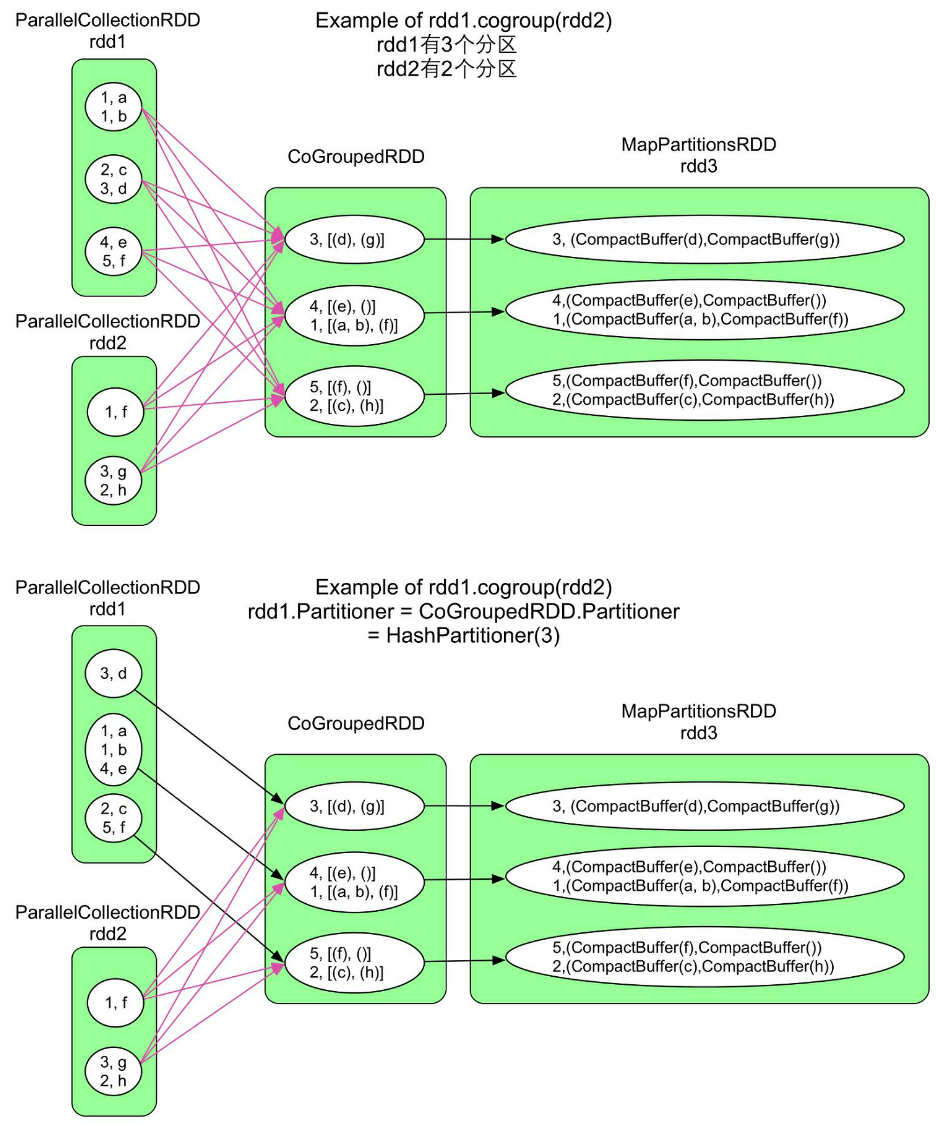
结论:Spark在决定RDD之间的数据依赖时除了考虑
transformation()的计算逻辑,还考虑child RDD和parent RDD的分区信息,当分区个数和partitioner都一致时,说明parent RDD中的数据可以直接流入child RDD,不需要ShuffleDependency,这样可以避免数据传输,提高执行效率
cogroup()最多支持4个RDD同时进行cogroup(),如rdd5 = rdd1.cogroup (rdd2, rdd3,rdd4)。cogroup()实际生成了两个RDD:CoGroupedRDD将数据聚合在一起,MapPartitionsRDD将数据类型转变为CompactBuffer(类似于Java的ArrayList)。当cogroup()聚合的RDD包含很多数据时,Shuffle这些中间数据会增加网络传输,而且需要很大内存来存储聚合后的数据,效率较低。
5)aggregateByKey
将数据根据不同的规则进行分区内计算和分区间计算
def aggregateByKey[U: ClassTag](zeroValue: U) // 指定初值,用于计算第一个数据
(seqOp: (U, V) => U, // 分区内的计算规则
combOp: (U, U) => U // 分区间的计算规则
): RDD[(K, U)]
6)foldByKey
当分区内计算规则和分区间计算规则相同时,aggregateByKey就可以简化为foldByKey
7)combineByKey
把相同key的值进行一些处理(比如类型转换)后 再在分区内分区间实现可以实现不同的聚合操作
def combineByKey[C](
createCombiner: V => C, // 这个函数把当前的值作为参数,此时我们可以对其做些附加操作(比如类型转换)并把它返回 (这一步类似于初始化操作)
mergeValue: (C, V) => C, // 该函数把元素V合并到之前的元素C(createCombiner)上 (这个操作在每个分区内进行)
mergeCombiners: (C, C) => C // 该函数把2个元素C合并 (这个操作在不同分区间进行)
): RDD[(K, C)]
比如:统计学生的成绩
val dataRDD: RDD[(String, Float)] = sc.makeRDD(
List(("xiaoli", 88.0f), ("xiaohong", 95.0f), ("xiaoli", 91.0f), ("xiaohong", 93.0f), ("xiaoli", 95.0f), ("xiaobai", 98.0f)),
2
)
val combineRDD: RDD[(String, (Float, Int))] = dataRDD.combineByKey(
(_, 1), // 是 score => (score, 1) 的简写,类似于初始化操作,这里进行了类型转换Float -> (Float, Int)来实现计数
(acc: (Float, Int), newScore: Float) => (acc._1 + newScore, acc._2 + 1), // 分区内进行统计(k,(score,count))
(acc1: (Float, Int), acc2: (Float, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) // 分区间进行统计
)
combineRDD.foreach(println)
>>> (xiaoli,(274.0,3))
>>> (xiaohong,(188.0,2))
>>> (xiaobai,(98.0,1))
reduceByKey、foldByKey、aggregateByKey、combineByKey的区别?
reduceByKey:相同key的第一个数据不进行任何计算,分区内和分区间计算规则相同
foldByKey:相同key的第一个数据和初始值进行分区内计算,分区内和分区间计算规则相同
aggregateByKey:相同key的第一个数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同
combineByKey:当计算时,发现数据结构不满足要求时,可以转换值的类型,分区内和分区间计算规则可以不相同
8)sortByKey
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length) : RDD[(K, V)]
在一个 (K,V) 的RDD上调用,K必须实现Ordered接口(特质),返回一个按照key进行排序的RDD
9)join:连接
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
在类型为 (K,V)和(K,W) 的RDD上调用,返回一个相同key对应的所有元素连接在一起的 (K,(V,W)) 的RDD
join()操作实际上建立在cogroup()之上,首先利用CoGroupedRDD将具有相同Key的Value聚合在一起,形成<K,[list(V),list(W)]>,然后对[list(V),list(W)] 进行笛卡儿积计算并输出结果<K,(V,W)>,这里我们用list来表示CompactBuffer
10)leftOuterJoin:左外连接
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
2.3 行动算子
1)reduce
根据聚合规则 聚合所有元素,先是分区内进行聚合,然后分区间进行聚合
2)collect
在驱动程序(Driver)中,以数组Array的形式返回 所有元素
3)count
返回RDD中元素数目
4)first
返回第一个元素
5)take
以数组形式返回前n个元素
6)takeOrdered
以数组形式返回排序后的 前n个元素
7)aggregate
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
分区数据 通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合
需要注意的是,在aggregate()中,seqOp和combOp聚合时初始值zeroValue都会参与计算,而在aggregateByKey()中,初始值只参与seqOp的计算
8)fold
def fold(zeroValue: T)(op: (T, T) => T): T
当分区内和分区间聚合规则相同时,是aggregate的简化版操作
9)countByKey
def countByKey(): Map[K, Long]
统计每个key的元素数目
10)save相关算子
// 保存成Text文件
rdd.saveAsTextFile("output")
// 序列化成对象保存到文件
rdd.saveAsObjectFile("output1")
// 保存成Sequencefile文件
rdd.map((_,1)).saveAsSequenceFile("output2")
11)foreach
分布式遍历RDD中的每一个元素,调用指定函数
// driver端 收集后打印
rdd.collect().foreach(println)
// excutor端 分布式打印
rdd.foreach(println)
2.4 RDD序列化
2.4.1 闭包检查
从计算的角度,算子以外的代码都是在Driver端执行,算子里面的代码都是在Executor端执行
那么在scala的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测
Scala2.12版本后闭包编译方式发生了改变
可以通过java的extends Serializable来实现序列化
2.4.2 Kryo序列化框架
Java的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大
Spark出于性能的考虑,Spark2.0开始支持另外一种Kryo序列化机制。Kryo速度是Serializable的10倍。当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化
注意:即使使用Kryo序列化,也要继承Serializable接口
object serializable_Kryo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("SerDemo")
.setMaster("local[*]")
// 替换默认的序列化机制
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册需要使用 kryo 序列化的自定义类
.registerKryoClasses(Array(classOf[Searcher]))
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello atguigu", "atguigu", "hahah"), 2)
val searcher = new Searcher("hello")
val result: RDD[String] = searcher.getMatchedRDD1(rdd)
result.collect.foreach(println)
}
}
case class Searcher(val query: String) {
def isMatch(s: String) = {
s.contains(query)
}
def getMatchedRDD1(rdd: RDD[String]) = {
rdd.filter(isMatch)
}
def getMatchedRDD2(rdd: RDD[String]) = {
val q = query
rdd.filter(_.contains(q))
}
}
2.5 RDD依赖关系
所谓依赖关系,就是两个相邻RDD之间的关系
val sc: SparkContext = new SparkContext(conf)
val fileRDD: RDD[String] = sc.textFile("input/1.txt")
println(fileRDD.dependencies)
println("----------------------")
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
println(wordRDD.dependencies)
println("----------------------")
val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))
println(mapRDD.dependencies)
println("----------------------")
val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)
println(resultRDD.dependencies)
resultRDD.collect()
2.5.1 数据分区
在依赖之前,我们需要知道Spark中的数据分区,常用的数据分区方法(Partitioner)包括3种:水平划分、Hash划分(HashPartitioner)和Range划分(RangePartitioner)
(1)水平划分
按照record的索引进行划分。例如,我们经常使用的sparkContext.parallelize(list(1,2,3,4,5,6,7,8,9), 3),就是按照元素的下标划分,(1, 2, 3)为一组,(4, 5, 6)为一组,(7, 8, 9)为一组。这种划分方式经常用于输入数据的划分,如使用Spark处理大数据时,我们先将输入数据上传到HDFS上,HDFS自动对数据进行水平划分,也就是按照128MB为单位将输入数据划分为很多个小数据块(block),之后每个Spark task可以只处理一个数据块。
(2)Hash划分(HashPartitioner)
使用record的Hash值来对数据进行划分,该划分方法的好处是只需要知道分区个数,就能将数据确定性地划分到某个分区。在水平划分中,由于每个RDD中的元素数目和排列顺序不固定,同一个元素在不同RDD中可能被划分到不同分区。而使用HashPartitioner,可以根据元素的Hash值,确定性地得出该元素的分区。该划分方法经常被用于数据Shuffle阶段
(3)Range划分(RangePartitioner)
该划分方法一般适用于排序任务,核心思想是按照元素的大小关系将其划分到不同分区,每个分区表示一个数据区域。例如,我们想对一个数组进行排序,数组里每个数字是[0, 100]中的随机数,Range划分首先将上下界[0,100]划分为若干份(如10份),然后将数组中的每个数字分发到相应的分区,如将18分发到(10, 20]的分区,最后对每个分区进行排序,这个排序过程可以并行执行,排序完成后是全局有序的结果。Range划分需要提前划分好数据区域,因此需要统计RDD中数据的最大值和最小值。为了简化这个统计过程,Range划分经常采用抽样方法来估算数据区域边界
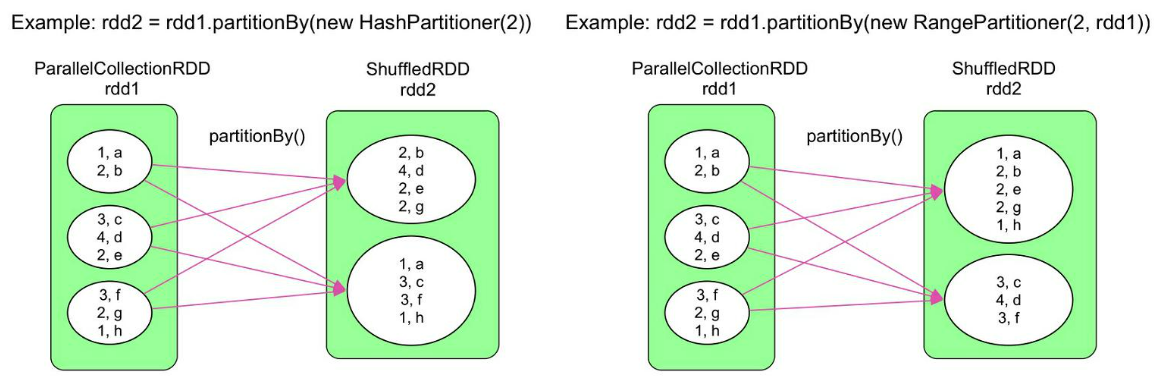
partitionBy
语义:使用新的partitioner对rdd1进行重新分区,partitioner可以是HashPartitioner、RangePartitioner等,要求rdd1是<K,V>类型
val inputRDD = sc.parallelize(Array[(Int, Char)]((1, 'a'), (2, 'b'), (3, 'c'), (4, 'd'), (2, 'e'), (3, 'f'), (2, 'g'), (1, 'h')), 3)
// 使用HashPartitioner重新分区
val resultRDD = inputRDD.partitionBy(new HashPartitioner(2))
// 使用RangePartitioner重新分区
val resultRDD = inputRDD.partitionBy(new RangePartitioner(2, inputRDD))
左图展示了使用HashPartitioner对rdd1进行重新分区的情景,Key=2和Key=4的record被分到rdd2中的partition1,Key=1和Key=3的record被分到rdd2中的partition2
右图展示了使用RangePartitioner对rdd1进行重新分区的情景,Key值较小的record被分到partition1,Key值较大的record被分到partition2。注意RangePartitioner并不能保证得到的rdd2分区中的数据是有序的
2.5.2 窄依赖和宽依赖
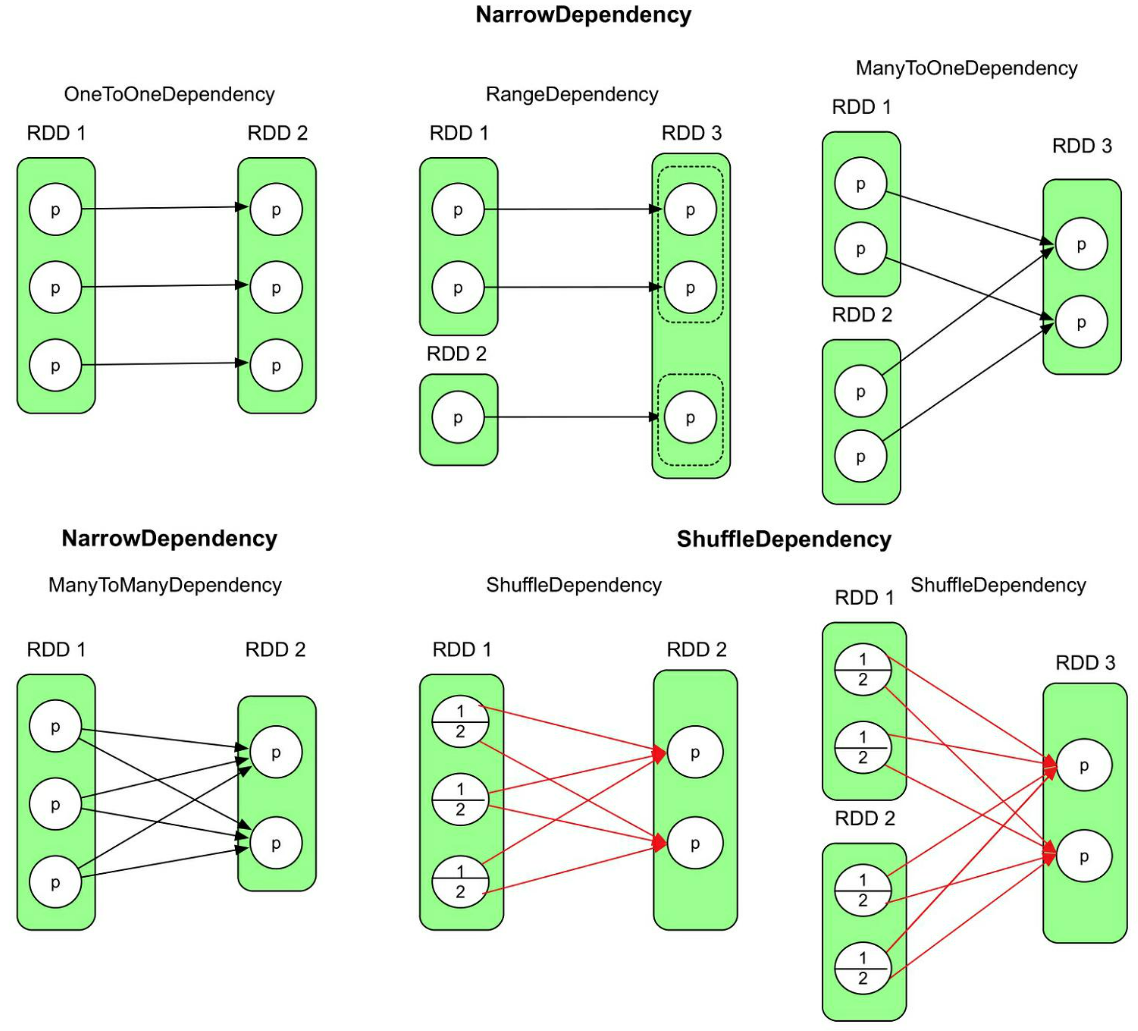
窄依赖 ,包括一对一依赖(OneToOneDependency)、区域依赖(RangeDependency,表示child RDD和parent RDD的分区经过区域化后存在一一映射关系)、多对一依赖(ManyToOneDependency)、多对多依赖(ManyToManyDependency)。比如一对一依赖,表示child RDD和parent RDD中的分区个数相同,并存在一一映射关系
“Base class for dependencies where each partition of the child RDDdepends on a small number of partitions of the parent RDD. Narrow dependencies allow forpipelined execution。”
中文意思:“如果新生成的child RDD中每个分区都依赖parent RDD中的一部分分区,那么这个分区依赖关系被称为NarrowDependency。”
其实,在Spark代码中没有对ManyToOneDependency和ManyToManyDependency这两种依赖关系进行命名,只是统称为NarrowDependency。这里只是为了方便说明
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd)
宽依赖 会引起Shuffle操作【洗牌】
To understand what happens during the shuffle, we can consider the example of the
reduceByKeyoperation.The
reduceByKeyoperation generates a new RDD where all values for a single key are combined into a tuple - the key and the result of executing a reduce function against all values associated with that key. The challenge is that not all values for a single key necessarily reside on the same partition, or even the same machine, but they must be co-located to compute the result.In Spark, data is generally not distributed across partitions to be in the necessary place for a specific operation. During computations, a single task will operate on a single partition - thus, to organize all the data for a single
reduceByKeyreduce task to execute, Spark needs to perform an all-to-all operation. It must read from all partitions to find all the values for all keys, and then bring together values across partitions to compute the final result for each key - this is called the shuffle.
简单来说,就是比如reduceByKey算子,子RDD每个分区结果 需要通过父RDD的所有数据 跨分区计算得到
总的来说,窄依赖、宽依赖的区别是child RDD的各个分区 是否完全依赖 parent RDD的一个或者多个分区
根据数据操作语义和分区个数,Spark可以在生成逻辑处理流程时就明确child RDD是否需要parentRDD的一个或多个分区的全部数据。如果parent RDD的一个或者多个分区中的数据需要全部流入childRDD的某一个或者多个分区,则是窄依赖。如果parent RDD分区中的数据需要一部分流入child RDD的某一个分区,另外一部分流入child RDD的另外分区,则是宽依赖(即图中的ManyToManyDependency与ShuffleDependency的区别)
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]]
对数据依赖进行分类有什么用呢?
这样做首先可以明确RDD分区之间的数据依赖关系,在执行时Spark可以确定从哪里获取数据,输出数据到哪里
其次,对数据依赖进行分类有利于生成物理执行计划。NarrowDependency在执行时可以在同一个阶段进行流水线(pipeline)操作,不需要进行Shuffle,而ShuffleDependency需要进行Shufle
最后,对数据依赖进行分类有利于代码实现,如OneToOneDependency可以采用一种实现方式,而ShuffleDependency采用另一种实现方式。这样,Spark可以根据transformation()操作的计算逻辑选择合适的数据依赖进行实现
2.5.3 任务划分
在了解shuffle操作之后,再来看看Spark里的RDD任务划分(物理计划)
RDD任务切分包括:Application、Job、Stage 和 Task
-
Application:初始化一个SparkContext即生成一个Application
-
Job:一个Action算子就会生成一个 Job
-
Stage:Stage等于宽依赖(ShuffleDependency) 的个数加1
-
Task:一个Stage阶段中,最后一个RDD的分区个数 就是Task的个数
注意:Application(SparkContext)->Job(Action)->Stage(Shuffle)->Task(Last RDD)每一层都是1对n的关系,括号内是相应数量的划分依据
如下图所示,图中粉色箭头表示ShuffleDependency,对于每个 Job,从后往前进行回溯,如果遇见ShuffleDependency,就会建立一个阶段
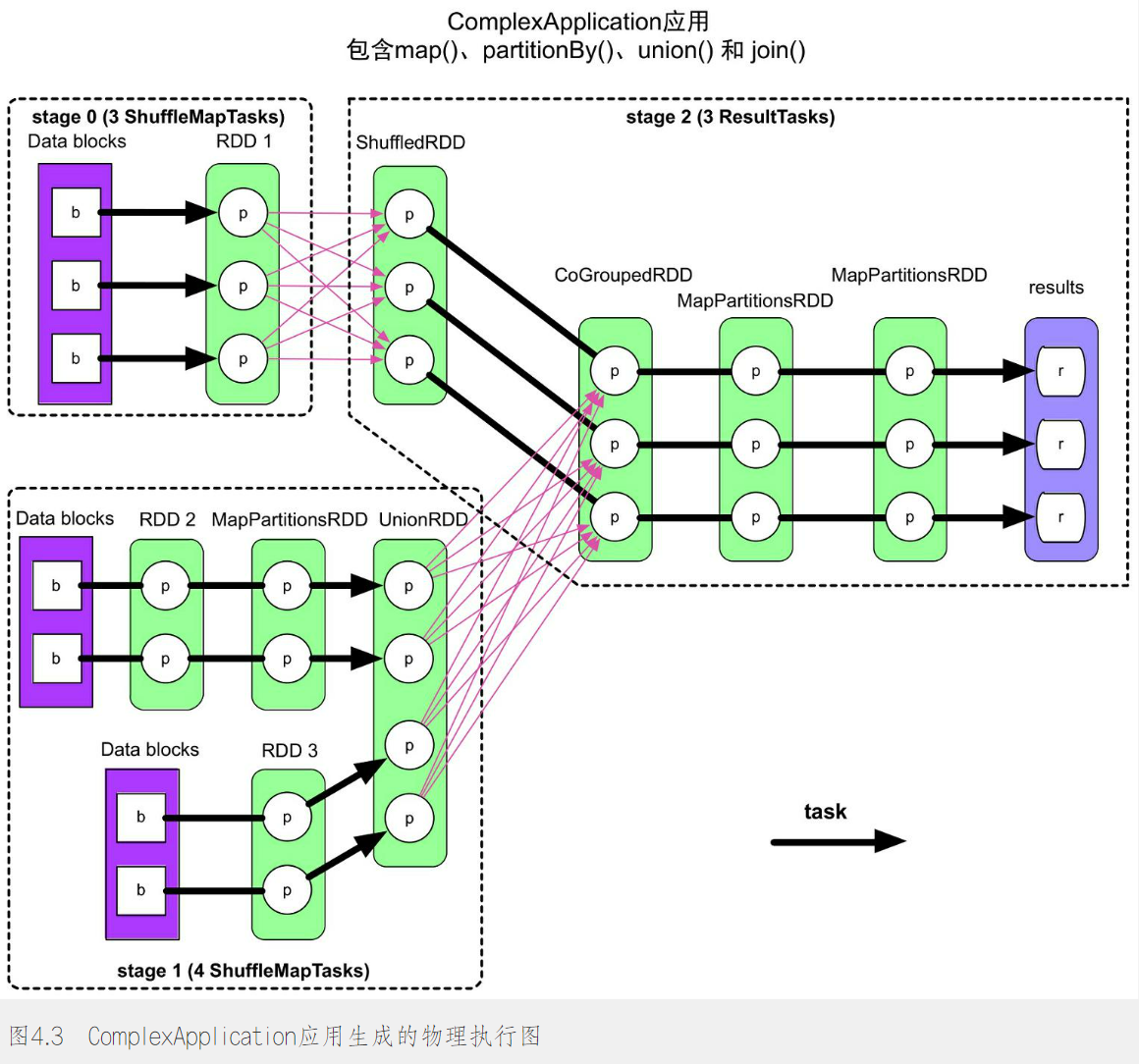
对于job、stage、和task的计算顺序,job的提交时间和action算子的执行时间有关;提交之后就是从包含输入数据的stage开始从前到后以此执行,仅当上游的stage执行完之后,才会执行下游的stage;而stage中的每个task因为是独立而且同构的,可以并行运行没有先后之分
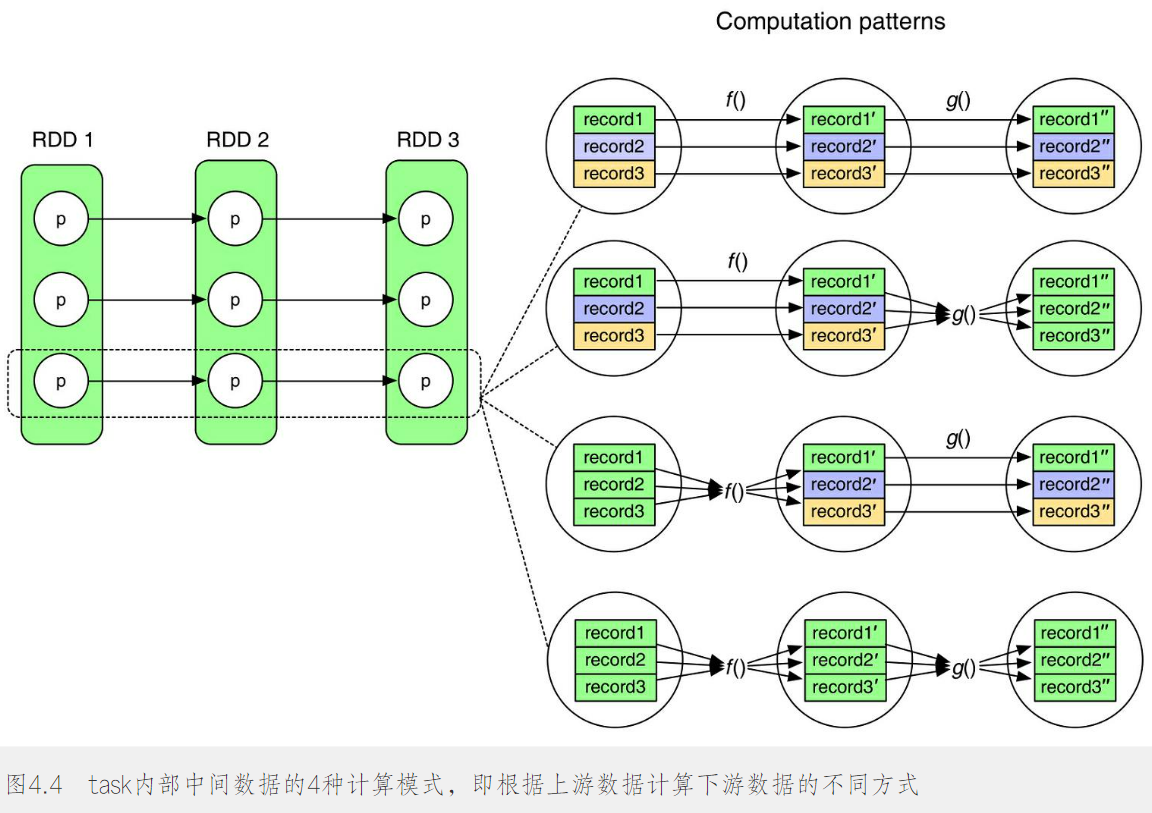
对于task内部数据的存储和计算问题(流水线计算),采用流水线计算的好处是可以有效地减少内存使用空间,在task计算时只需要在内存中保留当前被处理的单个record即可,不需要保存其他record或者已经处理完的record
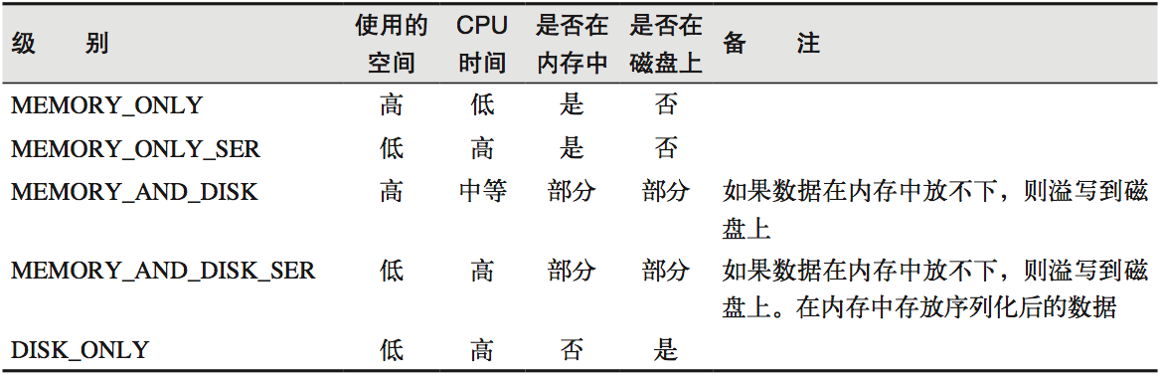
2.6 RDD持久化
2.6.1 RDD Cache缓存
RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以缓存在JVM的堆内存中
但是并不是这两个方法被调用时立即缓存,而是触发后面的action算子时,该RDD将会被缓存在计算节点的内存中,并供后面重用
// cache操作会增加血缘关系,不改变原有的血缘关系
println(wordToOneRdd.toDebugString)
// 数据缓存。
wordToOneRdd.cache()
// 可以更改存储级别
// mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition
Spark会自动对一些Shuffle操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点Shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache
2.6.2 RDD CheckPoint检查点
所谓的检查点其实就是通过将RDD中间结果写入磁盘
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发
// 设置检查点路径
sc.setCheckpointDir("./checkpoint1")
// 创建一个RDD,读取指定位置文件
val lineRdd: RDD[String] = sc.textFile("input/1.txt")
// 业务逻辑
val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))
val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {
word => {
(word, System.currentTimeMillis())
}
}
// 增加缓存,避免再重新跑一个job做checkpoint
wordToOneRdd.cache()
// 数据检查点:针对wordToOneRdd做检查点计算
wordToOneRdd.checkpoint()
// 触发执行逻辑
wordToOneRdd.collect().foreach(println)
缓存和检查点区别
1)Cache缓存只是将数据保存起来,不切断血缘依赖。Checkpoint检查点切断血缘依赖
2)Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高
3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD
2.7 累加器
累加器用来把 Executor端变量信息 聚合到Driver端
在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge
2.7.1 系统累加器
系统累加器包括longAccumulator、doubleAccumulator、collectionAccumulator
val rdd = sc.makeRDD(List(1,2,3,4,5))
// 声明累加器
var sum = sc.longAccumulator("sum");
rdd.foreach(
num => {
// 使用累加器
sum.add(num)
}
)
// 获取累加器的值
println("sum = " + sum.value)
2.7.2 自定义累加器
import org.apache.spark.util.AccumulatorV2
import scala.collection.mutable.ArrayBuffer
// 1. 继承AccumulatorV2;2. 实现方法
class ODArrayAccumulator extends AccumulatorV2[OD, ArrayBuffer[OD]] {
// 存放累加的结果
private var odArray = ArrayBuffer[OD]()
// 重置
override def reset(): Unit = odArray.clear()
// 复制
override def copy(): AccumulatorV2[OD, ArrayBuffer[OD]] = new ODArrayAccumulator()
// 判断是否为初始状态
override def isZero: Boolean = odArray.isEmpty
// driver端 合并累加器
override def merge(other: AccumulatorV2[OD, ArrayBuffer[OD]]): Unit = {
odArray ++ other.value
}
// executor端 累加 OD 数据
override def add(od: OD): Unit = {
odArray.append(od)
}
override def value: ArrayBuffer[OD] = odArray
}
使用自定义的累加器
// 自定义一个累加器
val odArrayAccumulator: ODArrayAccumulator = new ODArrayAccumulator()
sc.register(odArrayAccumulator, "odArray")
...
odArrayAccumulator.add(od)
val outputRDD: RDD[OD] = sc.makeRDD(odArrayAccumulator.value)
2.8 广播变量
广播变量用来高效分发 较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用
比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送
val rdd1 = sc.makeRDD(List( ("a",1), ("b", 2), ("c", 3), ("d", 4) ),4)
val list = List( ("a",4), ("b", 5), ("c", 6), ("d", 7) )
// 声明广播变量
val broadcast: Broadcast[List[(String, Int)]] = sc.broadcast(list)
val resultRDD: RDD[(String, (Int, Int))] = rdd1.map {
case (key, num) => {
var num2 = 0
// 使用广播变量
for ((k, v) <- broadcast.value) {
if (k == key) {
num2 = v
}
}
(key, (num, num2))
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号