hive
简介
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能
本质
将HQL转化成MapReduce程序
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
优缺点
优点
(1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
(2)避免了去写MapReduce,减少开发人员的学习成本
(3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合
(4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高
(5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点
1)Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长,由于MapReduce数据处理流程的限制,效率更高的算法却无法实现
2)Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
架构原理
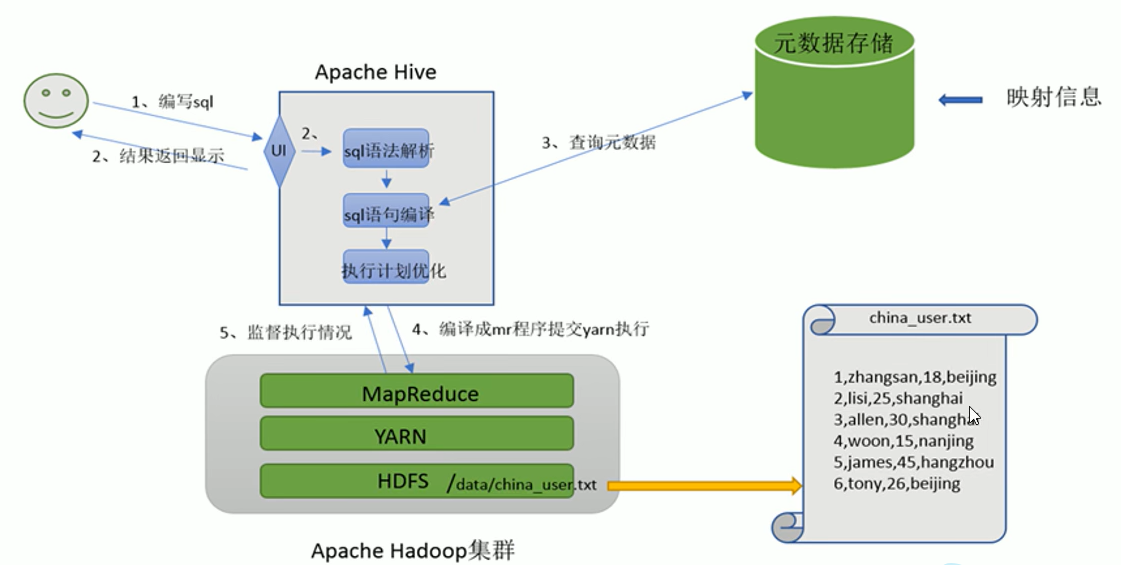
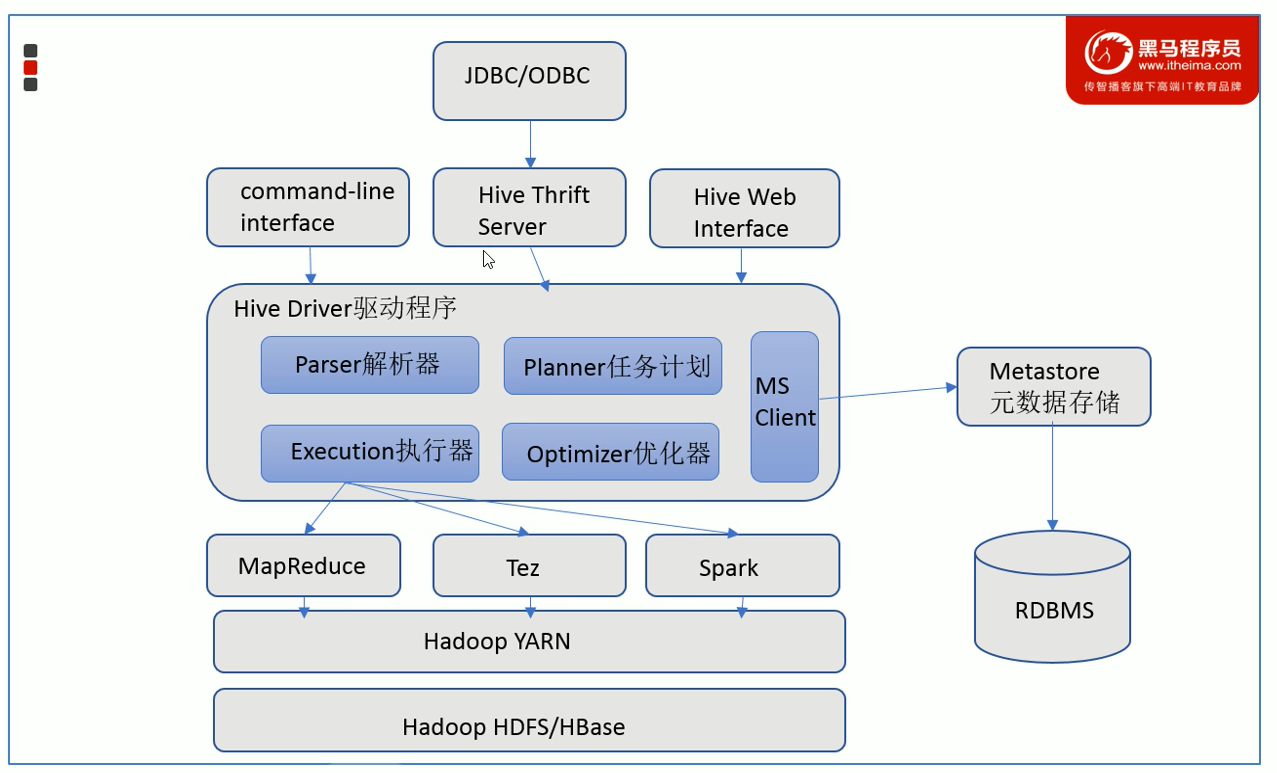
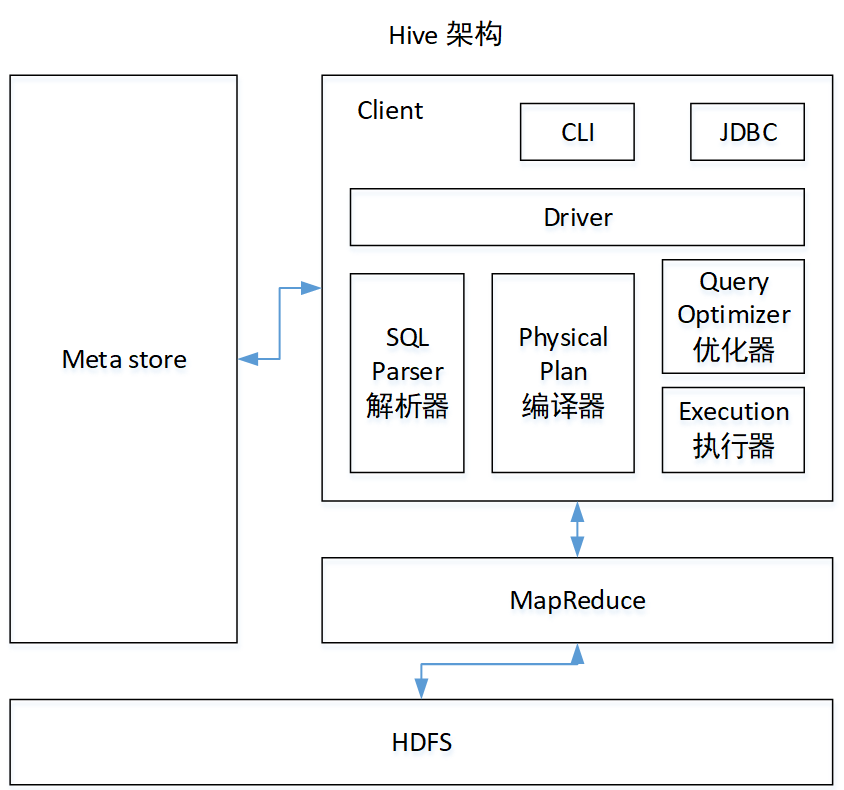
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问hive)
1.1 使用元数据服务的方式访问Hive
-
在hive-site.xml文件中添加如下配置信息
<!-- 指定存储元数据要连接的地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop101:9083</value> </property> -
启动metastore
hive --service metastore
1.2 使用 JDBC 方式访问Hive
-
在hive-site.xml文件中添加如下配置信息
<!-- 指定hiveserver2连接的host --> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop101</value> </property> <!-- 指定hiveserver2连接的端口号 --> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> -
启动hiveserver2
bin/hive --service hiveserver2
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore(可支持多窗口操作)
-
将MySQL的JDBC驱动拷贝到Hive的lib目录下
cp /opt/software/mysql-connector-java-5.1.48.jar $HIVE_HOME/lib -
配置Metastore到MySql
vim $HIVE_HOME/conf/hive-site.xml<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- jdbc连接的URL --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop101:3306/metastore?useSSL=false</value> </property> <!-- jdbc连接的Driver--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!-- jdbc连接的username--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- jdbc连接的password --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!-- Hive默认在HDFS的工作目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!-- Hive元数据存储的验证 --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!-- 元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration> -
初始化元数据库
-
登陆MySQL
-
新建Hive元数据库
-
初始化Hive元数据库
schematool -initSchema -dbType mysql -verbose
-
3)Hadoop
使用HDFS进行存储,使用MapReduce进行计算
4)驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划
(3)优化器(Query Optimizer):对逻辑执行计划进行优化
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark
整体流程:Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口
Hive和数据库比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库
其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处
以下将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性
1.查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发
2.数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的,因此,Hive中不建议对数据的改写,所有的数据都是在加载的时候确定好的
而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据
3.执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟
相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势
4.数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;
对应的,数据库可以支持的数据规模较小
常用交互命令
-
-e不进入hive的交互窗口执行sql语句 -
-f执行脚本中sql语句 -
退出hive窗口
在新版的hive中没区别了,在以前的版本是有的:exit: 先隐性提交数据,再退出;quit: 不提交数据,退出;
-
在 hive cli 命令窗口中如何查看 hdfs 文件系统
hive(default)>dfs -ls /; -
查看在 hive 中输入的所有历史命令
进入到当前用户的根目录/root 或 home目录下;查看
. hivehistory文件
常见属性配置
-
hive窗口打印默认库和表头
<property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> -
运行日志信息配置
- 修改 hive/conf/hive-log4j2.properties.template文件名称为 hive-log4j2.properties
- 在hive-log4j.properties文件中修改log存放位置
-
参数配置方式
-
查看当前所有的配置信息
hive>set; -
参数的配置三种方式
1)配置文件方式
默认配置文件:hive-default.xml;用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置;另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置
配置文件的设定对本机启动的所有Hive进程都有效
2)命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数
bin/hive -hiveconf mapred.reduce.tasks=10; 注意:仅对本次hive启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;3)参数声明方式
可以在HQL中使用SET关键字设定参数
hive (default)> set mapred.reduce.tasks=100; 注意:仅对本次hive启动有效
上述三种设定方式的优先级依次递增。即 配置文件<命令行参数<参数声明
注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了
-
相关错误
1)hiveserver2 报错 OutOfMemoryError
a. 修改 hive 目录下的 conf/hive-env.sh 文件
export HADOOP_HEAPSIZE=1024
调大 HADOOP_HEAPSIZE 堆内存的大小
b. 增加虚机内存
c. 使用物理机,加大内存
d. 优化 sql

 浙公网安备 33010602011771号
浙公网安备 33010602011771号