
第二次作业
一、安装Spark
hadoop,jdk基础坏境的检查
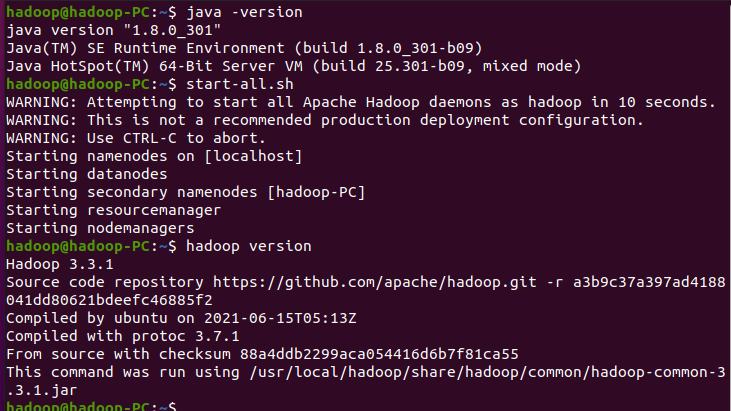
spark的使用
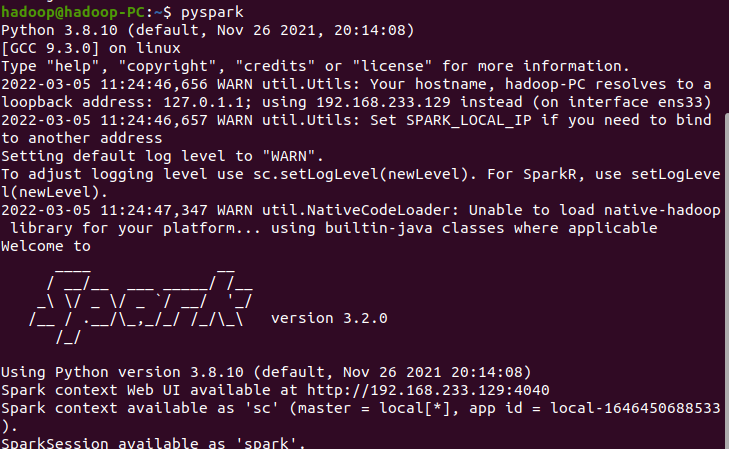
二、Python编程练习:英文文本的词频统计
import string list=[] dict={} txt=open('text.txt','r').read().lower() #读取文件 for ch in string.punctuation: #替换标点符号 txt=txt.replace(ch,"") list=txt.split() #分割文章 for i in list: #统计词频 if i in dict: dict[i]+=1 else: dict[i]=1 dict= sorted(dict.items(),key=lambda d:d[1],reverse= True) #词频排序 f = open('result.txt','w') #格式化将结果写入文件 for items in dict: f.writelines('{}--{}'.format(items[0],items[1]) + '\n')
运行结果:
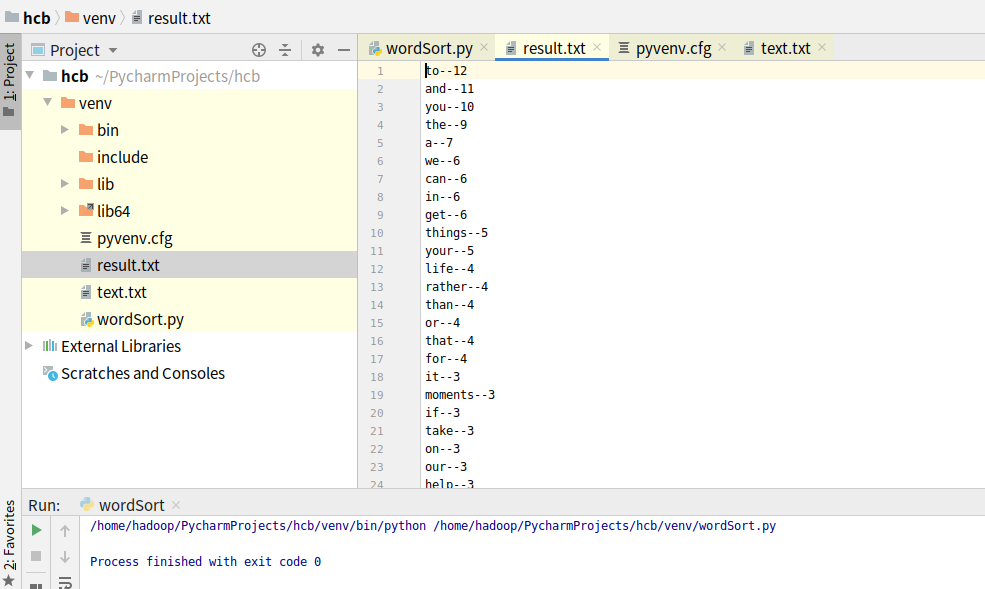

 浙公网安备 33010602011771号
浙公网安备 33010602011771号