

算法学习(13):前缀树
前缀树
前缀树是什么
前缀树是一种用于快速检索的多叉树结构,利用字符串的公共前缀来降低查询时间,核心思想是空间换时间,经常被搜索引擎用于文本词频统计。它的优点是最大限度地减少无谓的字符串比较,查询效率高;缺点是内存消耗较大。
前缀树的结构
经典前缀树的节点有两个属性一个是pass,代表从这个节点通过多少次,即有多少个字符串是由这个节点到根节点的路径上的字符串为前缀的;另一个属性是end,即有多少个字符串到这个节点结束。边有一个属性,即这条边代表的字符。在使用的过程中,每次从根节点出发,先把第一个字符串的树建好,然后依次建后面的字符串,从根节点开始如果路径相同就复用,到了不相同的字符就再往下建立一个节点。如下图所示。
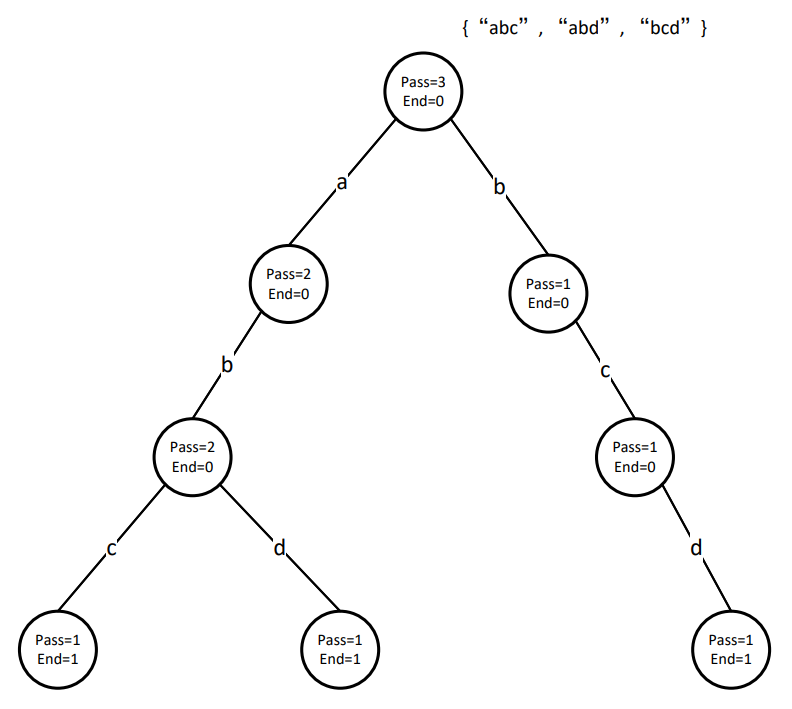
值得注意的是,最开始的节点的pass可以代表有多少个字符串是由""为前缀的,或者是加入了多少个字符串
前缀树结构的C++代码实现
前缀树需要实现的功能:插入字符串、查找字符串的数量、查找以pre为前缀的字符串数量、删除字符串
class TrieNode
{
public:
TrieNode()
{
this->m_Pass = 0;
this->m_End = 0;
}
public:
int m_Pass;
int m_End;
TrieNode* nexts[26] = {}; //该点后面有没有路,一个下标对应一个字母,0-25对应a-z,下标对应的值表示有没有路,null表示没有到这个字母的路,实际应用中如果还有除了字母的其他字符,可以用哈希表代替,key值存放字符char,value存放下一个节点
};
class TrieTree
{
public:
//插入字符串
void insert(string word)
{
if (word.size() == 0)
{
return;
}
TrieNode* node = &this->m_Root;
node->m_Pass++;
int index = 0;
for (int i = 0; i < word.size(); i++)
{
index = word[i] - 'a';
if (node->nexts[index] == NULL)
{
node->nexts[index] = new TrieNode();
}
node = node->nexts[index];
node->m_Pass++;
}
node->m_End++;
}
//查询word这个字符串加入过几次
int search(string word)
{
if (word.size() == 0)
{
return 0;
}
TrieNode* node = &this->m_Root;
int index = 0;
for (int i = 0; i < word.size(); i++)
{
index = word[i] - 'a';
if (node->nexts[index] == NULL)
{
return 0;
}
node = node->nexts[index];
}
return node->m_End;
}
//所有加入的字符串中,有多少个是以pre这个字符串作为前缀的
int prefixNumber(string pre)
{
if (pre.size() == 0)
{
return this->m_Root.m_Pass; //加入过多少字符串
}
TrieNode* node = &this->m_Root;
int index = 0;
for (int i = 0; i < pre.size(); i++)
{
index = pre[i] - 'a';
if (node->nexts[index] == NULL)
{
return 0;
}
node = node->nexts[index];
}
return node->m_Pass;
}
//所有加入的字符串中,有多少个是以pre这个字符串的前缀作为前缀的。例如"abc"的前缀是"a" "ab" "abc",此函数的功能就是查询有多少个字符串是以"a" "ab" "abc"为前缀的
//此函数的实现与prefixNumber函数基本一致,只不过在for循环中每次循环都累加一次,最后返回累加的结果
int prefixNumber1(string pre)
{
if (pre.size() == 0)
{
return this->m_Root.m_Pass; //加入过多少字符串
}
TrieNode* node = &this->m_Root;
int index = 0;
int res = 0;
for (int i = 0; i < pre.size(); i++)
{
index = pre[i] - 'a';
if (node->nexts[index] == NULL)
{
return 0;
}
res += node->nexts[index]->m_m_Pass;
node = node->nexts[index];
}
return res;
}
//删除word这个字符串
void deletE(string word)
{
if (search(word) != 0)
{
TrieNode* node = &this->m_Root;
TrieNode* nextNode = nullptr;
TrieNode* nextDelete = nullptr;
int index = 0;
node->m_Pass--;
for (int i = 0; i < word.size(); i++)
{
index = word[i] - 'a';
nextNode = node->nexts[index];
nextNode->m_Pass--;
if (node->m_Pass == 0 && node != &m_Root)
{
delete node; //如果pass=0,释放这个节点的内存空间,防止内存泄漏
node = nullptr;
}
node = nextNode;
}
node->m_End--;
if (node->m_Pass == 0) //循环跳出时,最后一个节点没有释放,判断是否需要释放
{
delete node;
node = nullptr;
}
}
}
private:
TrieNode m_Root;
};

 浙公网安备 33010602011771号
浙公网安备 33010602011771号