


Mysql同步机制 - PXC 大数据量下分页问题

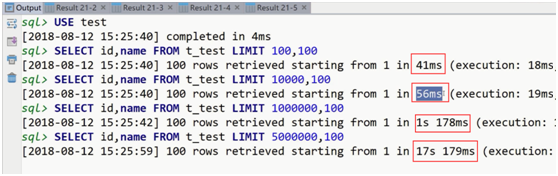


未优化前的limit的执行分析:
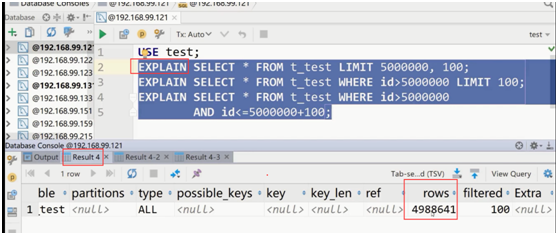
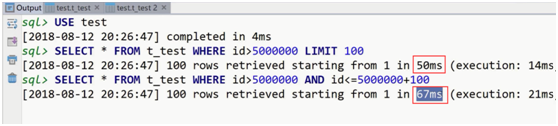
第一种优化方案的执行分析
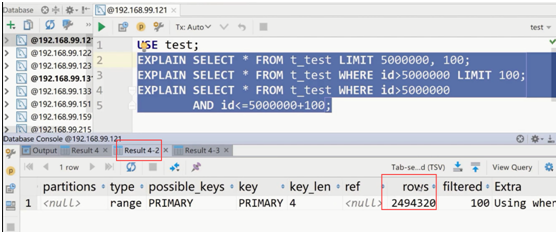
第二种优化方案的执行分析:
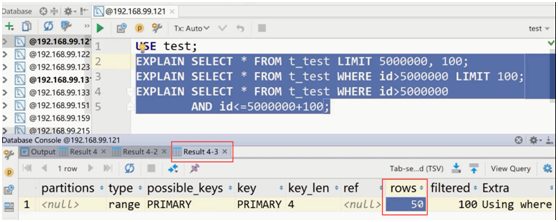
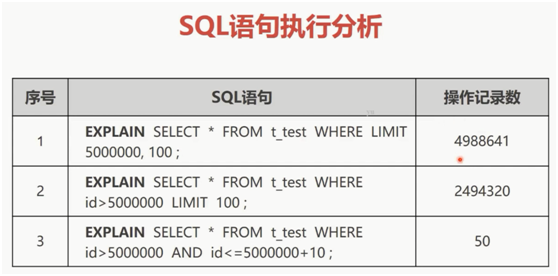
第一种全表扫描。
第二种通过主键索引把id大于5000000的所有记录找到后,再找前面100条。
第三种直接通过主键索引定位数据。

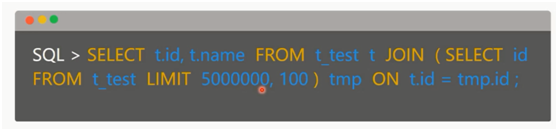
下面就是上面的第二种方案:
利用limit 找出不连续的100条数据的id(只找出id),然后再用表关联取出相应的数据。
当然子句中的limit依然会引发全表扫描。(这个语句的执行时间是239ms)
业务上可以限制一个最后页数,用来防止出现这种limit 。
比如百度,限制一个最后页数 76页。这样查询的数据比较靠前,即使用limit,速度也很快。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号