PostgreSQL内核学习笔记(Btree索引)
什么是Btree?
B树是一种自平衡树数据结构,它维护有序数据并允许进行搜索,顺序访问,插入和删除。B树是二叉搜索树的一般化,因为节点可以有两个以上的子节点。与其他自平衡二进制搜索树不同,B树非常适合读取和写入相对较大的数据块的存储系统。它通常用于数据库和文件系统。
什么是Btree索引?
B-tree有几点重要的特性:
1.B-tree是平衡树,即每个叶子页到root页中间有相同个数的内部页。因此查询任何一个值的时间是相同的。
2.B-tree中一个节点有多个分支,即每页(通常8KB)具有许多TIDs。因此B-tree的高度比较低,通常4到5层就可以存储大量行记录。
3.索引中的数据以非递减的顺序存储(页之间以及页内都是这种顺序),同级的数据页由双向链表连接。因此不需要每次都返回root,通过遍历链表就可以获取一个有序的数据集。
下面是一个索引的简单例子,该索引存储的记录为整型并只有一个字段:
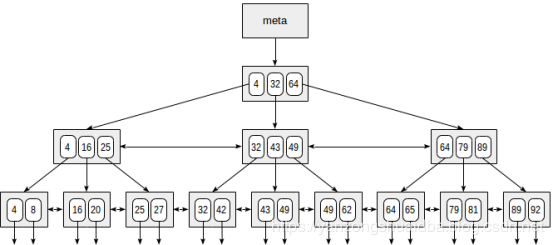
该索引最顶层的页是元数据页,该数据页存储索引root页的相关信息。内部节点位于root下面,叶子页位于最下面一层。向下的箭头表示由叶子节点指向表记录(TIDs)。
等值查询
例如通过"indexed-field = expression"形式的条件查询49这个值。
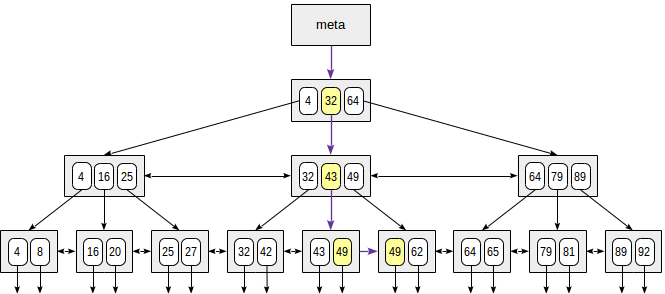
root节点有三个记录:(4,32,64)。从root节点开始进行搜索,由于32≤ 49 < 64,所以选择32这个值进入其子节点。通过同样的方法继续向下进行搜索一直到叶子节点,最后查询到49这个值。
实际上,查询算法远不止看上去的这么简单。比如,该索引是非唯一索引时,允许存在许多相同值的记录,并且这些相同的记录不止存放在一个页中。此时该如何查询?我们返回到上面的的例子,定位到第二层节点(32,43,49)。如果选择49这个值并向下进入其子节点搜索,就会跳过前一个叶子页中的49这个值。因此,在内部节点进行等值查询49时,定位到49这个值,然后选择49的前一个值43,向下进入其子节点进行搜索。最后,在底层节点中从左到右进行搜索。
(另外一个复杂的地方是,查询的同时树结构可能会改变,比如分裂)
非等值查询
通过"indexed-field ≤ expression" (or "indexed-field ≥ expression")查询时,首先通过"indexed-field = expression"形式进行等值(如果存在该值)查询,定位到叶子节点后,再向左或向右进行遍历检索。
下图是查询 n ≤ 35的示意图:
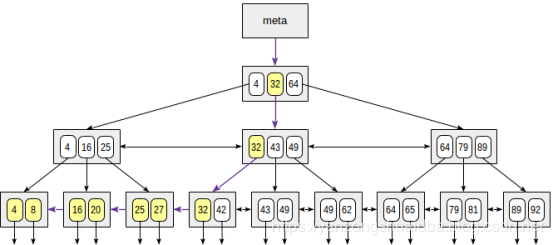
大于和小于可以通过同样的方法进行查询。查询时需要排除等值查询出的值。
范围查询
范围查询"expression1 ≤ indexed-field ≤ expression2"时,需要通过 "expression1 ≤ indexed-field =expression2"找到一匹配值,然后在叶子节点从左到右进行检索,一直到不满足"indexed-field ≤ expression2" 的条件为止;或者反过来,首先通过第二个表达式进行检索,在叶子节点定位到该值后,再从右向左进行检索,一直到不满足第一个表达式的条件为止。
下图是23 ≤ n ≤ 64的查询示意图:
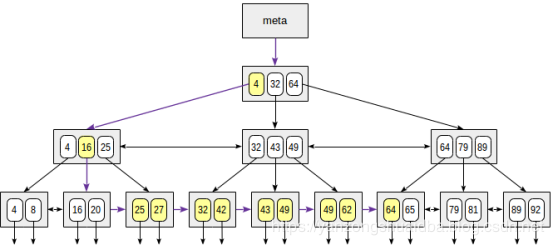
排序
再次强调,通过index、index-only或bitmap扫描,btree访问方法可以返回有序的数据。因此如果表的排序条件上有索引,优化器会考虑以下方式:表的索引扫描;表的顺序扫描然后对结果集进行排序。
排序顺序
当创建索引时可以明确指定排序顺序。如下所示,在range列上建立一个索引,并且排序顺序为降序:
demo=# create index on aircrafts(range desc);
本案例中,大值会出现在树的左边,小值出现在右边。为什么有这样的需求?这样做是为了多列索引。创建aircraft的一个视图,通过range分成3部分:
demo=# create view aircrafts_v as
select model,
case
when range < 4000 then 1
when range < 10000 then 2
else 3
end as class
from aircrafts;
demo=# select * from aircrafts_v;
model | class
---------------------+-------
Boeing 777-300 | 3
Boeing 767-300 | 2
Sukhoi SuperJet-100 | 1
Airbus A320-200 | 2
Airbus A321-200 | 2
Airbus A319-100 | 2
Boeing 737-300 | 2
Cessna 208 Caravan | 1
Bombardier CRJ-200 | 1
(9 rows)
然后创建一个索引(使用下面表达式):
demo=# create index on aircrafts( (case when range < 4000 then 1 when range < 10000 then 2 else 3 end), model);
现在,可以通过索引以升序的方式获取排序的数据:
demo=# select class, model from aircrafts_v order by class, model;
class | model
-------+---------------------
1 | Bombardier CRJ-200
1 | Cessna 208 Caravan
1 | Sukhoi SuperJet-100
2 | Airbus A319-100
2 | Airbus A320-200
2 | Airbus A321-200
2 | Boeing 737-300
2 | Boeing 767-300
3 | Boeing 777-300
(9 rows)
demo=# explain(costs off)
select class, model from aircrafts_v order by class, model;
QUERY PLAN
--------------------------------------------------------
Index Scan using aircrafts_case_model_idx on aircrafts
(1 row)
同样,可以以降序的方式获取排序的数据:
demo=# select class, model from aircrafts_v order by class desc, model desc;
class | model
-------+---------------------
3 | Boeing 777-300
2 | Boeing 767-300
2 | Boeing 737-300
2 | Airbus A321-200
2 | Airbus A320-200
2 | Airbus A319-100
1 | Sukhoi SuperJet-100
1 | Cessna 208 Caravan
1 | Bombardier CRJ-200
(9 rows)
demo=# explain(costs off)
select class, model from aircrafts_v order by class desc, model desc;
QUERY PLAN
-----------------------------------------------------------------
Index Scan BACKWARD using aircrafts_case_model_idx on aircrafts
(1 row)
然而,如果一列以升序一列以降序的方式获取排序的数据的话,就不能使用索引,只能单独排序:
demo=# explain(costs off)
select class, model from aircrafts_v order by class ASC, model DESC;
QUERY PLAN
-------------------------------------------------
Sort
Sort Key: (CASE ... END), aircrafts.model DESC
-> Seq Scan on aircrafts
(3 rows)
(注意,最终执行计划会选择顺序扫描,忽略之前设置的enable_seqscan = off。因为这个设置并不会放弃表扫描,只是设置他的成本----查看costs on的执行计划)
若有使用索引,创建索引时指定排序的方向:
demo=# create index aircrafts_case_asc_model_desc_idx on aircrafts(
(case
when range < 4000 then 1
when range < 10000 then 2
else 3
end) ASC,
model DESC);
demo=# explain(costs off)
select class, model from aircrafts_v order by class ASC, model DESC;
QUERY PLAN
-----------------------------------------------------------------
Index Scan using aircrafts_case_asc_model_desc_idx on aircrafts
(1 row)
列的顺序
当使用多列索引时与列的顺序有关的问题会显示出来。对于B-tree,这个顺序非常重要:页中的数据先以第一个字段进行排序,然后再第二个字段,以此类推。
下图是在range和model列上构建的索引:
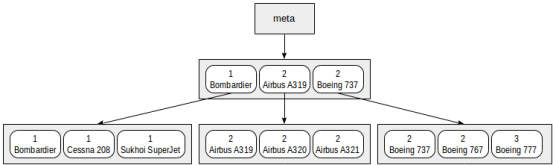
当然,上图这么小的索引在一个root页足以存放。但是为了清晰起见,特意将其分成几页。
从图中可见,通过类似的谓词class = 3(仅按第一个字段进行搜索)或者class = 3 and model = 'Boeing 777-300'(按两个字段进行搜索)将非常高效。
然而,通过谓词model = 'Boeing 777-300'进行搜索的效率将大大降低:从root开始,判断不出选择哪个子节点进行向下搜索,因此会遍历所有子节点向下进行搜索。这并不意味着永远无法使用这样的索引----它的效率有问题。例如,如果aircraft有3个classes值,每个class类中有许多model值,此时不得不扫描索引1/3的数据,这可能比全表扫描更有效。
但是,当创建如下索引时:
demo=# create index on aircrafts( model, (case when range < 4000 then 1 when range < 10000 then 2 else 3 end));
索引字段的顺序会改变:
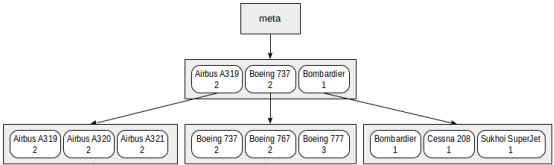
通过这个索引,model = 'Boeing 777-300'将会很有效,但class = 3则没这么高效。
NULLs
PostgreSQL的B-tree支持在NULLs上创建索引,可以通过IS NULL或者IS NOT NULL的条件进行查询。
考虑flights表,允许NULLs:
demo=# create index on flights(actual_arrival);
demo=# explain(costs off) select * from flights where actual_arrival is null;
QUERY PLAN
-------------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (actual_arrival IS NULL)
-> Bitmap Index Scan on flights_actual_arrival_idx
Index Cond: (actual_arrival IS NULL)
(4 rows)
NULLs位于叶子节点的一端或另一端,这依赖于索引的创建方式(NULLS FIRST或NULLS LAST)。如果查询中包含排序,这就显得很重要了:如果SELECT语句在ORDER BY子句中指定NULLs的顺序索引构建的顺序一样(NULLS FIRST或NULLS LAST),就可以使用整个索引。
下面的例子中,他们的顺序相同,因此可以使用索引:
demo=# explain(costs off)
select * from flights order by actual_arrival NULLS LAST;
QUERY PLAN
--------------------------------------------------------
Index Scan using flights_actual_arrival_idx on flights
(1 row)
下面的例子,顺序不同,优化器选择顺序扫描然后进行排序:
demo=# explain(costs off)
select * from flights order by actual_arrival NULLS FIRST;
QUERY PLAN
----------------------------------------
Sort
Sort Key: actual_arrival NULLS FIRST
-> Seq Scan on flights
(3 rows)
NULLs必须位于开头才能使用索引:
demo=# create index flights_nulls_first_idx on flights(actual_arrival NULLS FIRST);
demo=# explain(costs off)
select * from flights order by actual_arrival NULLS FIRST;
QUERY PLAN
-----------------------------------------------------
Index Scan using flights_nulls_first_idx on flights
(1 row)
原文 https://blog.51cto.com/yanzongshuai/2406164

 浙公网安备 33010602011771号
浙公网安备 33010602011771号