Kernel Linux学习(二)——驱动编写(部分转载)
Kernel Linux学习——驱动编写
2020-08-08 14:46:20 hawkJW
前面已经完成了Kernel Linux的环境配置部分,下面我们就熟悉一下Kernel Linux重要的部分,即驱动的编写
总体分析
实际上,Linux系统分为内核态和用户态。其中,只有内核态才能访问到硬件设备,而驱动可以当作从内核态中提供出来的API,供用户态的代码访问到硬件设备上。
因为,我们这篇文档主要简单介绍一下驱动的例子,并且说明一下驱动的工作原理。
简单驱动模块介绍
根据一些惯例,我们实现一个最简单的内核模块——HelloWorld模块,其功能也非常简单:加载模块和卸载模块的时候输出相关的提示信息即可。
其中和普通的计算机方面知识的学习一样,我们首先给出例子,并且模仿例子中的规定,然后熟悉后可以自己探索为什么,其中该模块的源代码如下所示
#include <linux/init.h> #include <linux/module.h> MODULE_LICENSE("GPL"); MODULE_AUTHOR("hawk"); int helloInit(void) { printk(KERN_INFO "Hello, world\n"); return 0; } void helloExit(void) { printk(KERN_INFO "Goodbye, world\n"); } module_init(helloInit); module_exit(helloExit);
可以看到,Linux下驱动仍然使用C语言进行开发,但是由于驱动主要运行在内核中,而内核中不存在libc库,因此使用内核中的库函数——比如printk,可以看到,其和glibc中的printf函数名称十分相似,实际上,这两个函数的功能也很相近。
对于这个驱动源代码来说,可以看到其包含有一些MODULE_*的函数,这个基本上是一些描述性质的字符串,对于驱动运行来说,仅仅是一个可选项——有了这些可以让其他人对于这个模块有更好地了解,但是没有并不影响运行。而其中module_*函数就和模块的运行息息相关了。
我们思考一个问题——由于编写模块管理机制的人并不知道之后会添加什么模块,但是其还需要通过一些机制调用添加的模块,因此一个合理的机制就是通过预先定义一个入口函数和一个出口函数——类似于正常C语言的main,当我要使用模块时,直接调用预先定义的入口函数,当要卸载模块时,调用出口函数就可以。而这里,明显的,module_init就是入口函数:当内核加载这个模块时,就调用这个helloInit入口函数即可;而module_exit就是出口函数:当内核卸载这个模块时,就调用这个helloExit模块即可。
我们如果有一些计算机的基础的话,应该知道,要想要程序可以执行,单纯的源代码计算机的CPU是不认识的,我们需要进行编译,最后生成可执行代码。这里对于驱动的编译通常使用make命令进行编译,其指导文件Makefile内容如下所示
ifneq ($(KERNELRELEASE),) obj-m := hello.o else KDIR ?= /home/hawk/Desktop/linux PWD := $(shell pwd) default: $(MAKE) -C $(KDIR) M=$(PWD) modules endif clean: rm -rf *.o *.ko *.order *.symvers *.mod.c
其中,KDIR表示Kernel Linux源代码的目录,在我的环境中,我将下载的源代码放入了/home/hawk/Desktop/linux。M表示其是make编译时的变量,具体作用可以自己在进行查询。因此具体到我的环境中,其Makefile内容如下所示
ifneq ($(KERNELRELEASE),) obj-m := driver.o else KDIR ?= /home/hawk/Desktop/linux PWD := $(shell pwd) default: $(MAKE) -C $(KDIR) M=$(PWD) modules endif clean: rm -rf *.o *.ko *.order *.symvers *.mod.c
需要特殊说明一下,Makefile的格式要求比较严格,如果执行命令错误的话,可以看一下tab格式是否正确。然后我们执行如下命令进行编译
make
最后在当前目录下,会生成对应的驱动文件*.ko文件,这就是最后编译出来的驱动文件。然后我们将其放入我们前面所说的根文件系统中,准备进入启动Linux系统后分别进行载入和卸载,命令如下所示
mv hello.ko /path/to/rootfs make clean cd /path/to/rootfs find . | cpio -o --format=newc > ../rootfs.img
然后通过qemu启动Kernel Linux,然后在其根目录下可以看到对应的文件,如图所示

然后我们将该驱动装载入Linux内核中,命令如下所示
insmod hello.ko
其命令的结果如图所示

可以看到,其输出了Hello, world字符字样,和我们之间分析的一样;然后我们观察一下当前Linux内核中的相关驱动,命令如下所示
lsmod
其命令的结果如图所示

可以看到,确实正常加载了hello驱动,并且内核中目前只有这一个驱动(因为这仅仅是Linux内核,没有安装其他相关的配置)。最后,我们尝试从Linux内核中卸载该模块,命令如下所示
rmmod
其命令的结果如图所示

可以看到,其输出了Goodbye, world,和我们之前分析的一样,其成功从Linux内核中卸载了该驱动。这样,我们就完成了一个简单的驱动样例。
实际上,正如我们在前面分析到的一样,驱动实际上是用来操作设备的,因此我们前面给到的驱动的样例,实际上是一个驱动,但实际上却并没有牵扯到相关的设备,下面我们就在举一个虚拟字符设备驱动相关的例子——一个简单的char设备驱动,其内容如下所示
#include <linux/module.h> #include <linux/kernel.h> #include <linux/fs.h> #include <linux/cdev.h> static struct cdev chr_dev; static dev_t ndev; static int chr_open(struct inode* nd, struct file* filp) { int major, minor; major = MAJOR(nd->i_rdev); minor = MINOR(nd->i_rdev); printk("chr_open, major = %d, minor = %d\n", major, minor); return 0; } static ssize_t chr_read(struct file* filp, char __user* u, size_t sz, loff_t *off) { printk("chr_read process!\n"); return 0; } struct file_operations chr_ops = { .owner = THIS_MODULE, .open = chr_open, .read = chr_read }; static int helloInit(void) { int ret; cdev_init(&chr_dev, &chr_ops); ret = alloc_chrdev_region(&ndev, 0, 1, "hawkDev"); if(ret < 0) {return ret;} printk("helloInit(): major = %d, minor = %d\n", MAJOR(ndev), MINOR(ndev)); ret = cdev_add(&chr_dev, ndev, 1); if(ret < 0) {return ret;} return 0; } static void helloExit(void) { printk("helloExit process!\n"); cdev_del(&chr_dev); unregister_chrdev_region(ndev, 1); } module_init(helloInit); module_exit(helloExit); MODULE_LICENSE("GPL"); MODULE_AUTHOR("hawk");
可能代码看起来稍微有一些多,但是实际上大部分都是代码细节,主要的思路和前面介绍的一样。设备号分为主设备号和次设备号——其中主设备号和驱动一一对应,而次设备号用来区分使用相同主设备号的设备。这里alloc_chrdev_region方法用来申请一个动态主设备号以及一系列次设备号,其中最后一个参数表示该主设备号,也就是一一对应的驱动名称·;而申请到后还不能使用,我们需要将其注册入Linux内核中,也就是通过cdev_add方法最终完成设备的配置。如果还是不明白,不要紧,我认为就和一开始学C语言一样,为什么要#include<stdio.h>,我们首先知道要这么写,然后学会写其他的,当知识储备足够后,在探究为什么,以及其背后的原理。目前我们只需要知道,如果当我们需要操作一些设备的时候,我们需要申请设备号,并且向内核进行注册即可。
其余对于驱动编译和加载的方法和上面的例子是一样的,我们把命令列出来即可
insmod hello.ko
然后结果如图所示

可以看到,其应该确实注册了相关的设备。下面我们前往/dev目录下构建该虚拟设备,根据其major和minor进行构建即可,命令如下所示
mknod /dev/hawkDev c 248 0
其中,这里设备名称应该和上面驱动中申请注册的设备名称一样的。可能有人会问了,我已经在程序里面申请过了,为什么还要进行mknod注册呢?这里是我个人的理解,不一定正确,但是我认为对于理解会有帮助——实际上,从第一个例子中我们可以知道,这些程序仅仅是驱动,不包含设备。也就是如果学校要评选优秀毕业生,我们首先需要想校委会报备有优秀毕业生,并且需要说明选择的标准——对应的上面的程序,也就是alloc_chrdev_region函数相当于我们规定了优秀毕业生的标准,比如必须是毕业生,必须没有挂科等等,而cdev_add函数相当于我们最终想校委会报备这些信息。但是到这里,我们仅仅有了这个奖项,还没有对应的人,因此我们需要找符合条件的人。这里也就是找符合条件的设备,由于是虚拟设备,并非实际设备,我们需要“虚拟”的生成该设备,根据Linux知识,我们就在/dev中生成该设备即可,其中需要符合前面注册的条件,也就是设备类型、主设备号和次设备号都需要一致,也就是上面的命令,最后结果如图所示

然后我们尝试对该设备进行读操作,结果如图所示

可以看到,对于该设备的打开、读操作都使用了我们在驱动中缩写的功能,也就是我们确实通过驱动操作了该虚拟设备。
块设备驱动
实际上,除了上述字符设备外,我们经常使用的还有诸如块设备,不同于字符设备只能获取连续的顺序字节,块设备可以随机读写设备上的数据,因此块设备的驱动远远不同于字符设备驱动。当然,除了字符设备以及块设备外,Linux还有其它类型的设备。这里主要再讲述一下块设备的驱动,其余如果感兴趣的话,可以自己下去再查看一下。
对于块设备来说,最为典型的就是硬盘设备,如果有计算机基础的可以知道,硬盘的话其单位为Sector(扇区),而Linux下对于这些又添加了一些抽象层,包括Page、Segment以及Block,这里也简单说一下这些概念——Page,即页,是内存映射的最小单位。而Block,即块,是逻辑上进行数据存取的最小单位(根据局部性原理,我们不可能每改变一个磁盘的一字节就直接写入,而应该首先通过缓冲区,然后积累一部分后再写入,从而提高效率),一个Block最多只可能容纳一个文件,并且一个Block由多个Sector构成。而在Page和Segment之间,即为Block,即Page由多个Segment构成,而Segment由多个Block构成。如果还是比较混乱也没有关系,我们只需要大概了解Page->Segment->Block->Sector这个层次结构即可,其中一个前者由若干个后者组成即可。而Block是数据存取的最小单元、Sector是硬件读写的最小单元、Page是内存映射的最小单元。
至于为什么要分成这么多个层级结构,我认为一方面,计算机大部分问题可以通过添加中间层解决,因此为了解决硬盘格式兼容、系统兼容等诸多问题从而导致了这些层次结构;另一方面是局部性原理,就和缓存层次一样,最理想的是全部使用昂贵的寄存器,但是为了兼顾效率和可实现性,我们进行了层次结构的划分。这些也只是我的理解,可能底层原因有很多,但目前我们只需要理解并掌握这些知识即可。
那么前面介绍了一下块设备的大体结构,我们基于这个结构也可以更好地分析一下块设备驱动的调用过程:当系统想要向存储在某一块设备(硬盘)上的文本文件写入一个字节时,其调用了块设备驱动,正如前面分析的——Block才是数据存取的最小单位,因此往往驱动会先将其写入缓冲区,而由于块设备时随机存取,可能在很短的时间内有大量跨度很大或跨度很小的写或读,这时需要驱动对这些请求进行一些合并、优化,从而提高整个硬盘的访问效率。
因此,很明显,我们块设备驱动的任务就是接受系统的数据读写请求,通过实现一些算法进行优化,从而最后向硬盘进行访问。虽然说起来很简单,但是实际上实现起来仍然很复杂,需要一些额外的复杂数据结构。如果有兴趣的话,可以自己填一下驱动这块的大坑。
下面是对于我们要实现的部分的一个整体概括。和上面讲到的字符设备相同的,我们首先需要向内核申请块设备,并且对设备进行描述(根据上面的分析,我们需要获取该设备的缓冲区、存储所有请求的数据结构——这里Linux使用队列、相对应的硬件设备的相关描述)。之后,我们还需要实现相关的算法处理系统的请求,也就是对于上述请求队列的处理,从而提高效率。大体上我们要实现的也就是这些。
和字符设备一样,这里仍然给出一个极其简单的块设备样例,对于里面的一些写法和数据结构,仍然不需要了解,只需要知道需要这样写即可,当学习掌握到一定程度后,可以在做更为深入的了解。在我们实现的样例中,仅仅是简单的在终端进行输出请求,并不执行实际的操作。其代码如下所示
#include <linux/module.h>
#include <linux/init.h>
#include <linux/blkdev.h>
#include <linux/bio.h>
#include <linux/sched.h>
#include <linux/kernel.h>
#include <linux/slab.h>
#include <linux/fs.h>
#include <linux/errno.h>
#include <linux/timer.h>
#include <linux/types.h>
#include <linux/kdev_t.h>
#include <linux/fcntl.h>
#include <linux/hdreg.h>
#include <linux/vmalloc.h>
#include <linux/bio.h>
#include <linux/buffer_head.h>
#define HELLO_SECTOR_SIZE (512)
#define HELLO_SIZE (1024 * 1024)
static int hello_major;
static DEFINE_SPINLOCK(helloLock);
static struct gendisk *helloDisk;
static struct request_queue *helloQueue;
static unsigned char *helloBuf; //存储
static struct block_device_operations helloFops = {
.owner = THIS_MODULE,
};
static void helloRequest(struct request_queue *q) {
struct request *req;
//从系统的读写请求中处理一个
while((req = blk_fetch_request(q)) != NULL) {
printk("offset:%lu length:%u ", blk_rq_pos(req) * HELLO_SECTOR_SIZE, blk_rq_cur_sectors(req) * HELLO_SECTOR_SIZE);
if(rq_data_dir(req) == READ) {printk("Read\n");}
else {printk("Write\n");}
//结束获取的申请
__blk_end_request_all(req, 0);
}
}
static int helloInit(void) {
printk("helloInit\n");
//注册结构体
hello_major = register_blkdev(0, "hello");
printk("helloInit major:%d\n", hello_major);
//分配一个请求队列
helloQueue = blk_init_queue(helloRequest, &helloLock);
//注册gendisk结构
helloDisk = alloc_disk(1);
helloDisk->major = hello_major;
helloDisk->first_minor = 0;
sprintf(helloDisk->disk_name, "hawk Disk");
helloDisk->fops = &helloFops;
helloDisk->queue = helloQueue;
set_capacity(helloDisk, HELLO_SIZE / HELLO_SECTOR_SIZE);
//申请缓冲区
helloBuf = vmalloc(HELLO_SIZE);
add_disk(helloDisk);
return 0;
}
static void helloExit(void) {
printk("helloExit\n");
//卸载相关数据结构
put_disk(helloDisk);
del_gendisk(helloDisk);
vfree(helloBuf);
blk_cleanup_queue(helloQueue);
unregister_blkdev(hello_major, "hello");
}
module_init(helloInit);
module_exit(helloExit);
MODULE_LICENSE("GPL");
和字符设备驱动是类似的,虽然看起来代码量很大,但是逻辑和字符设备差不多,主要包括入口函数module_init和出口函数module_exit,这里面主要实现了申请块设备号register_blkdev函数、申请块设备数据结构alloc_disk函数、申请系统读写的请求队列blk_init_queue函数、向内核注册设备add_disk函数。其余基本差距不大,只不过是初始化相关数据结构的差异罢了。但有区别的一点是,正如前面分析的,块设备可能同时会有多个请求等,这里我们需要自己实现一个处理请求队列的算法,从而实现更高的效率。这里我只是简单列出了请求,函数为helloRequest,其余的块设备驱动并没有什么更特殊的。
下面我们尝试运行这个块设备驱动。首先类似于上面分析的字符设备驱动,我们编译并且打包入根文件目录中,然后使用insmod装载该驱动,结果如图所示

可以看到,根据输出,我们可以判断这里成功装载了该块设备驱动。下面我们需要插入相关的块设备。这里我们需要通过mknod创建该块设备,方便进行实验。
mknod /dev/hawk b 252 0
其中上面的名称随便写,因为最后识别的是主设备号,结果如图所示

可以看到,我们成功构建了该设备,下面我们尝试写入数据,结果如图所示
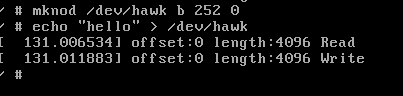
可以看到,根据输出,我们已经使用写好的驱动进行读写块设备。
总结
实际上,Linux相关的驱动还有很多,这里只是简单的介绍了一些,方便之后的Kernel Pwn,如果大家还感兴趣的话,可以自己查看一些相关的资料。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号