第一个应用:鸢尾花分类
第一个应用:鸢尾花分类
本例中我们用到了鸢尾花(Iris)数据集,这是机器学习和统计学中一个经典的数据集。
本文章所有知识都来自《python机器学习基础教程》这本书,有需要的道友请留言。
初识数据:都有哪些数据呢?
from sklearn.datasets import load_iris data = load_iris() print('key of load_iris:\n{}'.format(data.keys()))
结果: key of load_iris: dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
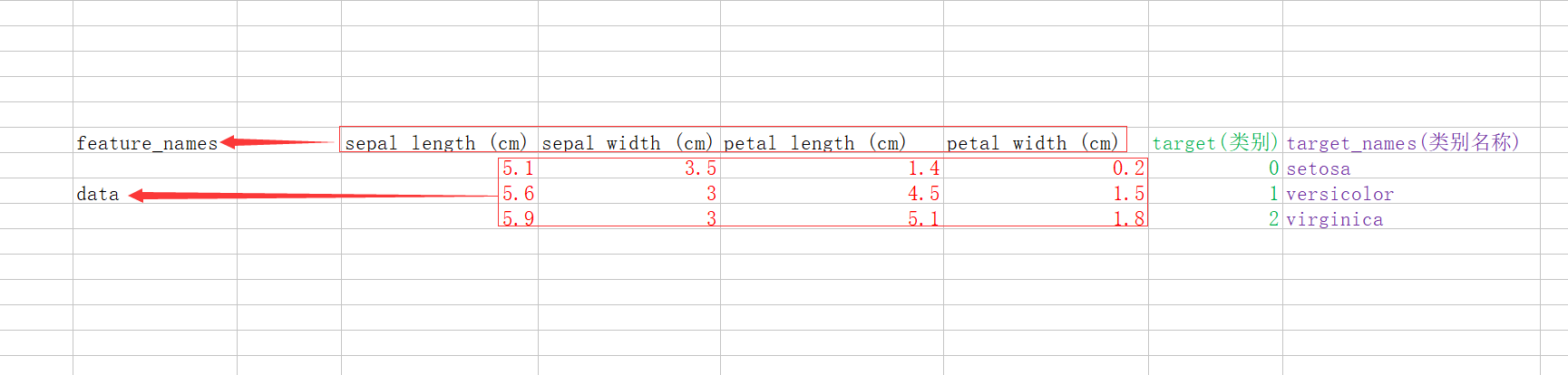
data:数据列表 ,data 里面是花萼长度、花萼宽度、花瓣长度、花瓣宽 度的测量数据
from sklearn.datasets import load_iris data = load_iris() # print('key of load_iris:\n{}'.format(data.keys())) print('data of load_iris:\n{}'.format(data.data[:5])) 结果: D:\software\Anaconda3\python.exe D:/MyCode/learn/11.py data of load_iris: [[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2]]
target:结果(分类的结果,这里一共三个分类,分别是0、1、2)
from sklearn.datasets import load_iris data = load_iris() # print('key of load_iris:\n{}'.format(data.keys())) # print('data of load_iris:\n{}'.format(data.data[:5])) print('target of load_iris:\n{}'.format(data.target))
结果:
D:\software\Anaconda3\python.exe D:/MyCode/learn/11.py
data of load_iris:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
target_name:分类的名称(3种类别)
from sklearn.datasets import load_iris data = load_iris() # print('key of load_iris:\n{}'.format(data.keys())) # print('data of load_iris:\n{}'.format(data.data[:5])) # print('target of load_iris:\n{}'.format(data.target)) print('target of load_iris:\n{}'.format(data.target_names)) 结果: D:\software\Anaconda3\python.exe D:/MyCode/learn/11.py target_name of load_iris: ['setosa' 'versicolor' 'virginica']
DESCR:数据的介绍
filename:文件所在路径
feature_names:数据描述
他们的关系如下图:
训练数据与测试数据
在有监督学习中,数据分为两种,训练数据和测试数据。
训练数据用来给程序学习,并且包含数据和结果两部分。
测试数据用来判断我们的程序算法的准确性。用来评估模型性能,叫作测试数据(test data)、测试集(test set)或留出集(hold-out set)。
scikit-learn 中的 train_test_split 函数可以打乱数据集并进行拆分。这个函数将 75% 的 行数据及对应标签作为训练集,剩下 25% 的数据及其标签作为测试集。训练集与测试集的 分配比例可以是随意的,但使用 25% 的数据作为测试集是很好的经验法则。
train_test_split的用法说明,请看这里https://blog.csdn.net/mrxjh/article/details/78481578
train_test_split的作用是使用伪随机器将数据集打乱,x_train包含75%行数据,x_test包含25行数据,代码如下:
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split data = load_iris() x_train, x_test, y_train, y_test = train_test_split(data['data'],data['target'],random_state=0) print('x_train length is:', len(x_train)) print('x_test length is:', len(x_test)) print('y_train length is:', len(y_train)) print('y_test length is:', len(y_test)) 结果: D:\software\Anaconda3\python.exe D:/MyCode/learn/11.py x_train length is: 112 x_test length is: 38 y_train length is: 112 y_test length is: 38
观察数据
代码:
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import pandas as pd from IPython.display import display import matplotlib.pyplot as plt from introduction_to_ml_with_python import mglearn iris_dataset = load_iris() x_train, x_test, y_train, y_test = train_test_split(iris_dataset['data'],iris_dataset['target'],random_state=0) iris_dataframe = pd.DataFrame(x_train, columns=iris_dataset.feature_names) grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o', hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3) plt.show()
其中,
mglearn可以到https://github.com/amueller/introduction_to_ml_with_python.git下载,也可以到我的代码库下载,名字叫16.py,项目地址如下:https://gitee.com/hardykay/machineLearning.git
在这里先声明一下,这都是为了学习,如有侵权,请联系我,立马删除。还有不会安装的道友请自行学习pip命令和git的代码拉取。

构建第一个模型:k近邻算法
# 构建算法
knn = KNeighborsClassifier(n_neighbors=1, algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, p=2, weights='uniform')
knn.fit(x_train, y_train)
KNeighborsClassifier的使用KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n-jobs=1)
n_neighbors 就是 kNN 里的 k,就是在做分类时,我们选取问题点最近的多少个最近邻。
weights 是在进行分类判断时给最近邻附上的加权,默认的 'uniform' 是等权加权,还有 'distance' 选项是按照距离的倒数进行加权,也可以使用用户自己设置的其他加权方法。举个例子:假如距离询问点最近的三个数据点中,有 1 个 A 类和 2 个 B 类,并且假设 A 类离询问点非常近,而两个 B 类距离则稍远。在等权加权中,3NN 会判断问题点为 B 类;而如果使用距离加权,那么 A 类有更高的权重(因为更近),如果它的权重高于两个 B 类的权重的总和,那么算法会判断问题点为 A 类。权重功能的选项应该视应用的场景而定。
algorithm 是分类时采取的算法,有 'brute'、'kd_tree' 和 'ball_tree'。kd_tree 的算法在 kd 树文章中有详细介绍,而 ball_tree 是另一种基于树状结构的 kNN 算法,brute 则是最直接的蛮力计算。根据样本量的大小和特征的维度数量,不同的算法有各自的优势。默认的 'auto' 选项会在学习时自动选择最合适的算法,所以一般来讲选择 auto 就可以。
leaf_size 是 kd_tree 或 ball_tree 生成的树的树叶(树叶就是二叉树中没有分枝的节点)的大小。在 kd 树文章中我们所有的二叉树的叶子中都只有一个数据点,但实际上树叶中可以有多于一个的数据点,算法在达到叶子时在其中执行蛮力计算即可。对于很多使用场景来说,叶子的大小并不是很重要,我们设 leaf_size=1 就好。
metric 和 p,是我们在 kNN 入门文章中介绍过的距离函数的选项,如果 metric ='minkowski' 并且 p=p 的话,计算两点之间的距离就是
模型评估
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import pandas as pd from IPython.display import display import matplotlib.pyplot as plt import mglearn from sklearn.neighbors import KNeighborsClassifier import numpy as np iris_dataset = load_iris() x_train, x_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0) iris_dataframe = pd.DataFrame(x_train, columns=iris_dataset.feature_names) grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o', hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3) # plt.show()
# 构建算法
knn = KNeighborsClassifier(n_neighbors=1, algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, p=2, weights='uniform')
knn.fit(x_train, y_train)
# 我们将这朵花的测量数据转换为二维 NumPy 数组的一行,这是因为 scikit-learn的输入数据必须是二维数组。 X_new = np.array([[5, 2.9, 1, 0.2]]) # print("X_new.shape: {}".format(X_new.shape)) prediction = knn.predict(X_new) # 根据我们模型的预测,这朵新的鸢尾花属于类别 0,也就是说它属于 setosa 品种。但我们 # 怎么知道能否相信这个模型呢?我们并不知道这个样本的实际品种,这也是我们构建模型 # 的重点啊! # print("Prediction: {}".format(prediction)) # print("Predicted target name: {}".format(iris_dataset['target_names'][prediction])) y_pred = knn.predict(x_test) # print("Test set predictions:\n {}".format(y_pred)) print("Test set score: {:.2f}".format(knn.score(x_test, y_test)))
结果:
D:\software\Anaconda3\python.exe D:/MyCode/machineLearning/18.py
Test set score: 0.97
总结:
1、使用from sklearn.datasets import load_iris获得鸢尾花的数据。
2、使用from sklearn.model_selection import train_test_split将数据打乱,并分为训练数据和测试数据。
3、使用import pandas as pd分析数据。
4、使用knn算法做机器学习算法
初始算法:
knn = KNeighborsClassifier(n_neighbors=1, algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, p=2, weights='uniform')
加入训练数据进行学习:
knn.fit(x_train, y_train)
加入测试集合进行测试:
y_pred = knn.predict(x_test) #y_pred就是测试结果
评估:
knn.score(x_test, y_test) 或 print("Test set score: {:.2f}".format(knn.score(x_test, y_test)))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号