maven_spark
1.创建项目
2.下载apache-maven-3.3.9-bin.tar.gz
3.修改配置文件
<localRepository>D:/module/maven/maven_repository</localRepository>
<mirrors>
<mirror>
<id>aliyunmaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/public </url>
</mirror>
</mirrors>
4.设置idea中的maven环境
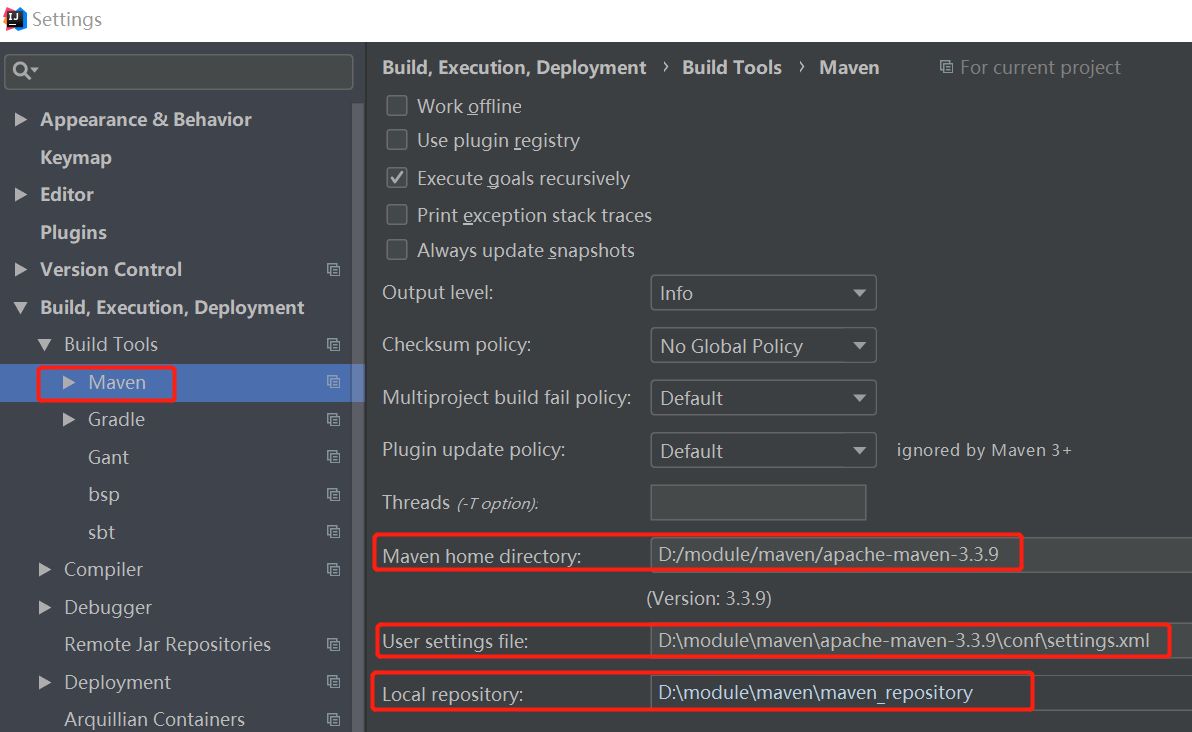
5.pom配置文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>spark_yarn</groupId> <artifactId>yarn</artifactId> <version>1.0-SNAPSHOT</version> <properties> <scala.version>2.11</scala.version> <scala.compat.version>2.11</scala.compat.version> <spark.version>2.2.0</spark.version> <hadoop.version>2.7.2</hadoop.version> <hbase.version>1.0</hbase.version> </properties> <!--<properties>--> <!--<scala.version>2.11</scala.version>--> <!--<scala.compat.version>2.11</scala.compat.version>--> <!--<spark.version>1.6.1</spark.version>--> <!--<hadoop.version>2.7.2</hadoop.version>--> <!--</properties>--> <repositories> <repository> <id>nexus-aliyun</id> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.11.8</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-launcher_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-auth</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <id>scala-compile-first</id> <goals> <goal>compile</goal> </goals> <configuration> <includes> <include>**/*.scala</include> </includes> </configuration> </execution> <execution> <id>scala-test-compile</id> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> </project>
6.wordcout.scala
package atguigu import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.SparkSession object WC { def main(args: Array[String]): Unit = { //集群模式 // val sparkSession: SparkSession = SparkSession.builder().appName("My Scala Word Count").getOrCreate() //本地模式 val sparkSession: SparkSession = SparkSession.builder().appName("My Scala Word Count").master("local").getOrCreate() val spark: SparkContext = sparkSession.sparkContext // val result = spark.textFile(args(0)) // .flatMap(_.split(" ")) // .map((_, 1)) // .reduceByKey(_ + _).saveAsTextFile(args(1)) // val result = spark.textFile("input/hello.txt") // .flatMap(_.split(" ")) // .map((_, 1)) // .reduceByKey(_ + _).saveAsTextFile("out") val dataRDD: RDD[String] = spark.textFile("input/hello.txt") println("dataRDD:") dataRDD.collect().foreach(println) val flatMapRDD: RDD[String] = dataRDD.flatMap(_.split(" ")) println("flatMapRDD:") flatMapRDD.collect().foreach(println) val mapRDD: RDD[(String, Int)] = flatMapRDD .map((_, 1)) println("mapRDD:") mapRDD.collect().foreach(println) val reduceByKeyRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _) println("reduceByKeyRDD:") reduceByKeyRDD.collect().foreach(println) reduceByKeyRDD.saveAsTextFile("out") spark.stop() } }
posted on 2021-02-26 17:17 happygril3 阅读(362) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号