任务划分
1.任务调度
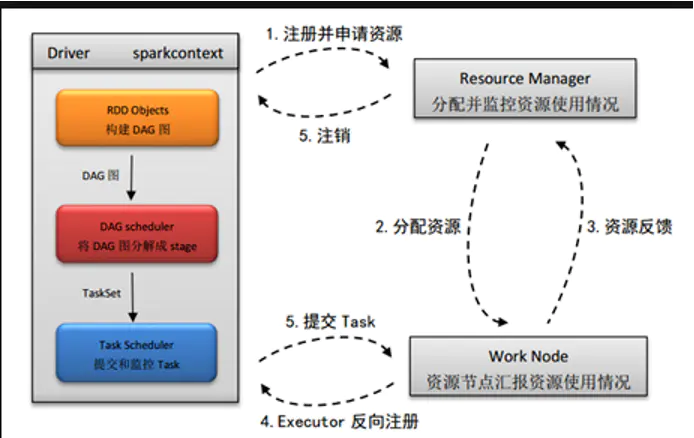
(1)在使用spark-summit或者spark-shell提交spark程序后,根据提交时指定(deploy-mode)的位置,创建driver进程,driver进程根据sparkconf中的配置,初始化sparkcontext。Sparkcontext的启动后,创建DAG Scheduler(将DAG图分解成stage)和Task Scheduler(提交和监控)两个调度task模块。
(2)driver进程根据配置参数向resourcemanager(资源管理器)申请资源(主要是用来执行的executor),resourcemanager接到到了Application的注册请求之后,会使用自己的资源调度算法,在spark集群的nodemanager上,通知nodemanager为application启动多个Executor。(以上是以yarn为平台的描述,如果是以standalone为平台,resourcemanager一般称之为master,nodemanager称之为worker)
(3)executor创建后,会向resourcemanager进行资源及状态反馈,以便resourcemanager对executor进行状态监控,如监控到有失败的executor,则会立即重新创建。
(4)Executor会向taskScheduler反向注册,以便获取taskScheduler分配的task。
(5)Driver完成SparkContext初始化,继续执行application程序;
当执行到Action时,就会创建Job。
并且由DAGScheduler将Job划分多个Stage;
每个Stage 由TaskSet 组成,并将TaskSet提交给taskScheduler;
taskScheduler把TaskSet中的task依次提交给Executor,;
Executor在接收到task之后,会使用taskRunner(封装task的线程池)来封装task;从Executor的线程池中取出一个线程来执行task。
就这样Spark的每个Stage被作为TaskSet提交给Executor执行,每个Task对应一个RDD的partition,执行我们的定义的算子和函数。直到所有操作执行完为止。如下图所示:
2.RDD任务切分中间分为:Application、Job、Stage和Task
(1)Application:初始化一个SparkContext即生成一个Application;Application个数=SparkContext个数
(2)Job:一个Action算子就会生成一个Job;Job个数=Action算子个数
(3)Stage:Stage等于宽依赖的个数加1;
(4)Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
注意:Application->Job->Stage->Task每一层都是1对n的关系。
3.Stage任务切分
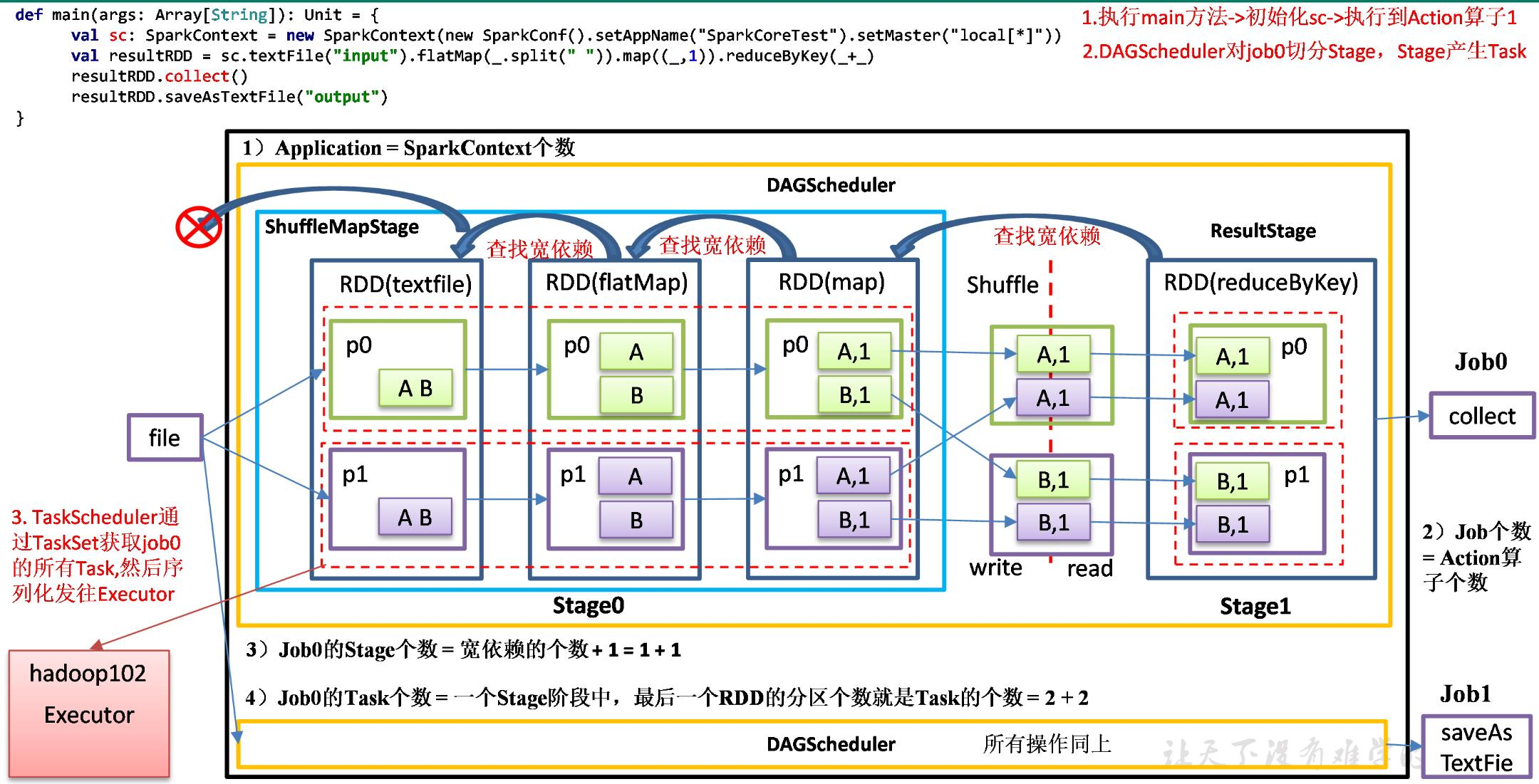
(1)程序从main进入到方法中,代码读到sc,会初始化生成一个Application应用。
(2)接着执行代码,执行到第一个collect行动算子,会形成一个Job。
(3)Job会启动DAGScheduler。
(4)DAGScheduler先找到最后一个RDD,然后往前找宽依赖,找到宽依赖,就切开,创建前面的ScheduleMapStage,创建宽依赖后面的是ResultStage。(Stage的个数=宽依赖+1)
(5)Task的个数就是在Stage阶段中,最后一个RDD分区的个数相加。(=宽依赖+1)
(6)任务划分完成后,由TaskSchedule把Task发往对应的Executor端执行
4.以算子的角度考虑RDD的创建和执行
(1)首先针对一段应用代码,driver会以action算子为边界生成响应的DAG图
(2)DAG Scheduler从DAG图的末端开始,以图中的shuffle算子为边界来划分stage,stage划分完成后,将每个stage划分为多个task,DAG Scheduler将taskSet传给Task Scheduler来调用
(3)Task Scheduler根据一定的调度算法,将接收到的task池中的task分给work node节点中的executor执行
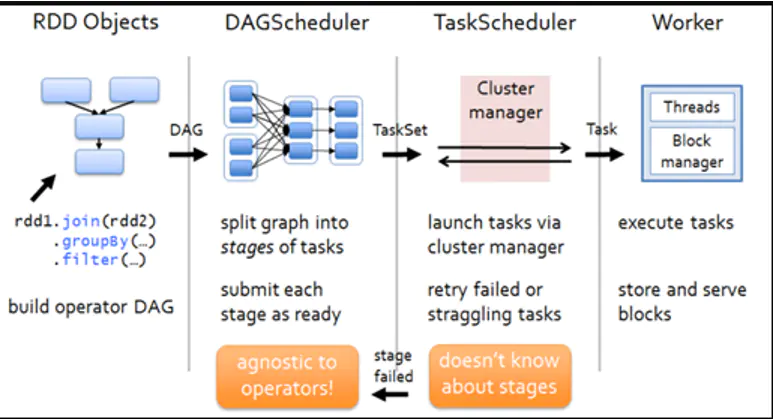
4.1、DAG Scheduler工作流程
4.2、TASK Scheduler工作流程
posted on 2020-12-31 09:47 happygril3 阅读(301) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号