数据压缩和存储
1.压缩
压缩技术能够有效减少底层存储系统(HDFS)读写字节数。压缩提高了网络带宽和磁盘空间的效率。
鉴于磁盘I/O和网络带宽是Hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘I/O和网络传输非常有帮助。
压缩Mapreduce的一种优化策略:通过压缩编码对Mapper或者Reducer的输出进行压缩,以减少磁盘IO,提高MR程序运行速度(但相应增加了cpu运算负担)。
注意:压缩特性运用得当能提高性能,但运用不当也可能降低性能。
基本原则:
(1)运算密集型的job,少用压缩
(2)IO密集型的job,多用压缩
MR支持的压缩编码
| 压缩格式 | hadoop自带? | 算法 | 文件扩展名 | 是否可切分 | 换成压缩格式后,原来的程序是否需要修改 |
|---|---|---|---|---|---|
| DEFAULT | 是,直接使用 | DEFAULT | .deflate | 否 | 和文本处理一样,不需要修改 |
| Gzip | 是,直接使用 | DEFAULT | .gz | 否 | 和文本处理一样,不需要修改 |
| bzip2 | 是,直接使用 | bzip2 | .bz2 | 是 | 和文本处理一样,不需要修改 |
| LZO | 否(低版本),需要安装 | LZO | .lzo | 是 | 需要建索引,还需要指定输入格式 |
| Snappy | 否(低版本),需要安装 | Snappy | .snappy | 否 | 和文本处理一样,不需要修改 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示
| 压缩格式 | 对应的编码/解码器 |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩方式选择
Gzip压缩
优点:压缩率比较高,而且压缩/解压速度也比较快;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split。
应用场景:当每个文件压缩之后在140M以内的(1个块大小内),都可以考虑用gzip压缩格式。例如说一天或者一个小时的日志压缩成一个gzip文件,运行mapreduce程序的时候通过多个gzip文件达到并发。hive程序,streaming程序,和java写的mapreduce程序完全和文本处理一样,压缩之后原来的程序不需要做任何修改。
Bzip2压缩
优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native(java和c互操作的API接口);在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
应用场景:适合对速度要求不高,但需要较高的压缩率的时候,可以作为mapreduce作业的输出格式;或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持split,而且兼容之前的应用程序(即应用程序不需要修改)的情况。
Lzo压缩
优点:压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;可以在linux系统下安装lzop命令,使用方便。
缺点:压缩率比gzip要低一些;hadoop本身不支持,需要安装;在应用中对lzo格式的文件需要做一些特殊处理(为了支持split需要建索引,还需要指定inputformat为lzo格式)。
应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越越明显。
Snappy压缩
优点:高速压缩速度和合理的压缩率。
缺点:不支持split;压缩率比gzip要低;hadoop本身不支持,需要安装;
应用场景:当Mapreduce作业的Map输出的数据比较大的时候,作为Map到Reduce的中间数据的压缩格式;或者作为一个Mapreduce作业的输出和另外一个Mapreduce作业的输入。
压缩位置选择
压缩可以在MapReduce作用的任意阶段启用。
压缩配置参数
要在Hadoop中启用压缩,可以配置如下参数:
| 参数 | 默认值 | 阶段 | 建议 |
|---|---|---|---|
| io.compression.codecs (在core-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec | 输入压缩 | Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress(在mapred-site.xml中配置) | false | mapper输出 | 这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress.DefaultCodec | mapper输出 | 使用LZO或snappy编解码器在此阶段压缩数据 |
| mapreduce.output.fileoutputformat.compress(在mapred-site.xml中配置) | false | reducer输出 | 这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec(在mapred-site.xml中配置) | org.apache.hadoop.io.compress. DefaultCodec | reducer输出 | 使用标准工具或者编解码器,如gzip和bzip2 |
| mapreduce.output.fileoutputformat.compress.type(在mapred-site.xml中配置) | RECORD | reducer输出 | SequenceFile输出使用的压缩类型:NONE和BLOCK |
Map输出端采用压缩
public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); // 开启map端输出压缩 configuration.setBoolean("mapreduce.map.output.compress", true); // 设置map端输出压缩方式 configuration.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class); Job job = Job.getInstance(configuration); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); boolean result = job.waitForCompletion(true); System.exit(result ? 1 : 0); } }
Reduce输出端采用压缩
public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); job.setJarByClass(WordCountDriver.class); job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 设置reduce端输出压缩开启 FileOutputFormat.setCompressOutput(job, true); // 设置压缩的方式 FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class); // FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class); // FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class); boolean result = job.waitForCompletion(true); System.exit(result?1:0); } }
hive方式
1.开启hive中间传输数据压缩功能 set hive.exec.compress.intermediate=true; 2.开启hive最终输出数据压缩功能 SET hive.exec.compress.output=true; //默认不支持压缩 (1)开启map输出阶段压缩功能 1.开启mapreduce中map输出压缩功能 set mapreduce.map.output.compress=true; 2.设置mapreduced中map输出数据的压缩方式 set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec; (2)开启reduce输出阶段压缩功能 1.开启mapreduce最终输出数据压缩 set mapreduce.output.fileoutputformat.compress=true; 2.设置mapreduce最终数据输出压缩方式 SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec; 3.设置mapreduce最终数据输出压缩为块压缩 set mapreduce.output.fileoutputformat.compress.type=BLOCK; 查看hadoop支持的压缩格式 hadoop checknative
2.存储
Hadoop中的文件格式大致上分为面向行和面向列两类:
(1)面向行:同一行的数据存储在一起,即连续存储。
SequenceFile,textFile
如果只需要访问行的一小部分数据,亦需要将整行读入内存,推迟序列化一定程度上可以缓解这个问题,但是从磁盘读取整行数据的开销却无法避免。
面向行的存储适合于整行数据需要同时处理的情况。
面向行的数据在写入失败时可以重新同步到最后一个同步点,所以Flume采用的是面向行的存储格式。
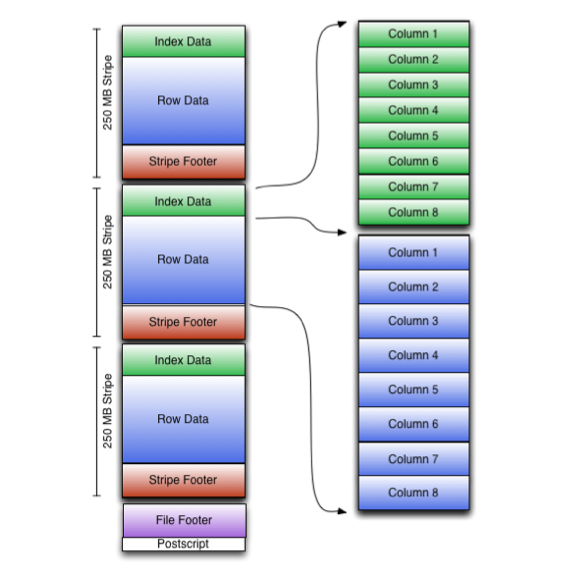
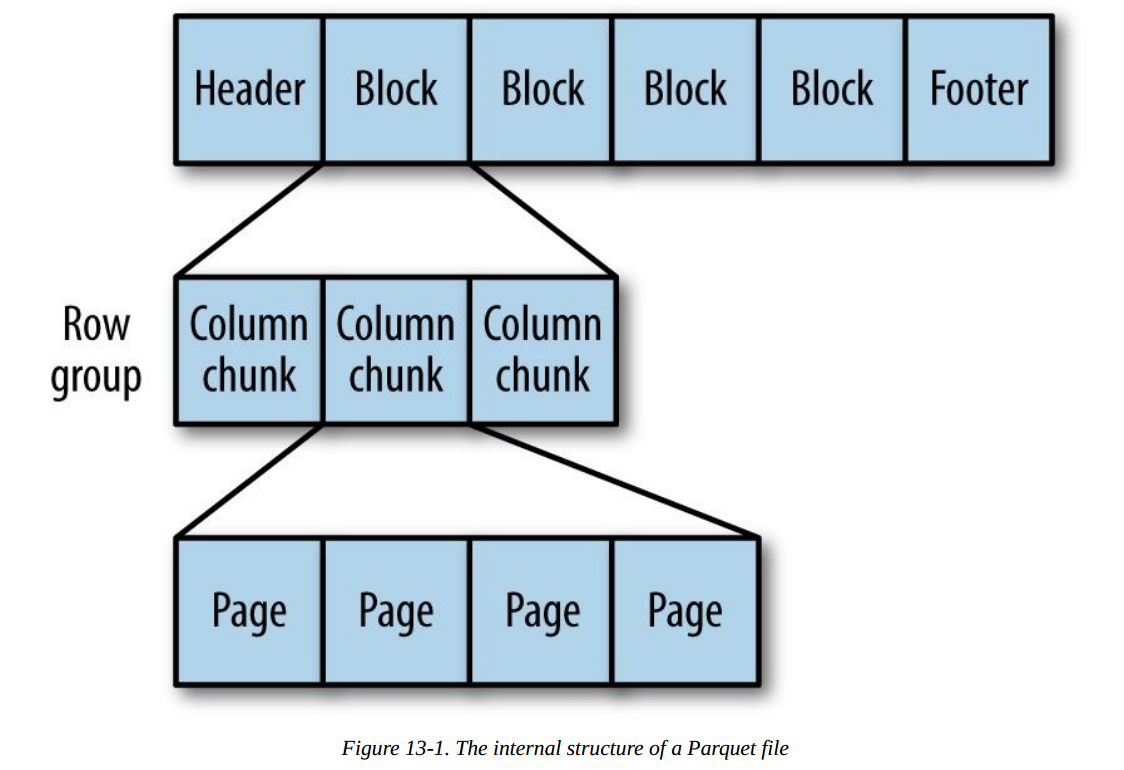
(2)面向列:整个文件被切割为若干列数据,每一列数据一起存储。
ORCFile,Parquet
面向列的格式使得读取数据时,可以跳过不需要的列,适合于只处于行的一小部分字段的情况。
这种格式的读写需要更多的内存空间,因为需要缓存行在内存中(为了获取多行中的某一列)。
不适合流式写入,因为一旦写入失败,当前文件无法恢复
3.
HIVE表的数据存储格式一般选择orc,parquet,压缩格式一般采用snappy,lzo
文件大小:orc>parquet>text
查询效率差不多
--存储格式为orc,orc存储文件默认压缩格式为ZLIB --压缩格式为SNAPPY CREATE external TABLE `student`( `name` string, `age` string, `address` string, ) row format delimited fields yerminated by '\t' stored as orc tblproperties("orc.compress"="SNAPPY");
posted on 2020-11-25 10:03 happygril3 阅读(651) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号