HA工作原理
1.Hadoop HA简介及工作原理
Hadoop NameNode官方开始支持HA集群默认是从2.0开始,之前的版本均是不支持NameNode HA的高可用的。
1.1 Hadoop HA简介
Hadoop-HA集群运作机制介绍
-
HA即高可用(7*24小时不中断服务)
-
实现高可用最关键的是消除单点故障
-
分成各个组件的HA机制——HDFS的HA、YARN的HA
HDFS的HA机制详解
通过双namenode消除单点故障,以下为双namenode协调工作的特点:
A、元数据管理方式需要改变:
-
内存中各自保存一份元数据
-
Edits日志只能有一份,只有Active状态的namenode节点可以做写操作
-
两个namenode都可以读取edits
-
共享的edits放在一个共享存储中管理(qjournal和NFS两个主流实现)
B、需要一个状态管理功能模块
-
实现了一个zkfailover,常驻在每一个namenode所在的节点
-
每一个zkfailover负责监控自己所在namenode节点,利用zk进行状态标识
-
当需要进行状态切换时,由zkfailover来负责切换
-
切换时需要防止brain split现象的发生
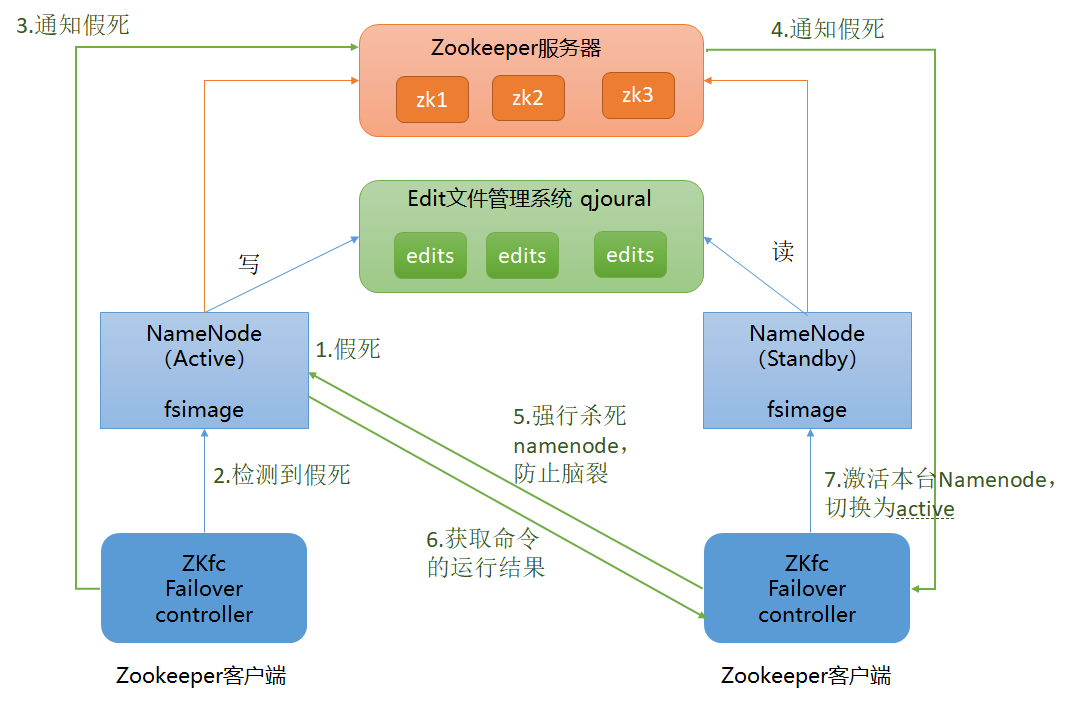
使用 Active NameNode,Standby NameNode 两个结点解决单点问题,两个结点通过JounalNode 共享状态,采用ZKFC选举Active实时监控集群状态,自动进行故障备援。
-
Active NameNode:接受 client 的 RPC 请求并处理,同时写自己的 Editlog 和共享存储上的 Editlog,接收 DataNode 的 Block report, block location updates 和 heartbeat;
-
Standby NameNode:同样会接到来自 DataNode 的 Block report, block location updates 和heartbeat,同时会从共享存储的 Editlog 上读取并执行这些 log 操作,使得自己的 NameNode 中的元数据(Namespcae information + Block locations map)都是和 Active NameNode 中的元数据是同步的。所以说 Standby 模式的 NameNode 是一个热备(Hot Standby NameNode),一旦切换成 Active 模式,马上就可以提供 NameNode 服务
-
JounalNode:用于Active NameNode , Standby NameNode 同步数据,本身由一组 JounnalNode 结点组成,该组结点基数个,支持 Paxos 协议,保证高可用,是 CDH5 唯一支持的共享方式(相对于 CDH4 促在NFS共享方式)
-
ZKFC:监控NameNode进程,自动备援。
posted on 2020-11-22 14:36 happygril3 阅读(728) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号