
HDFS读写流程与API
一、读写机制
-
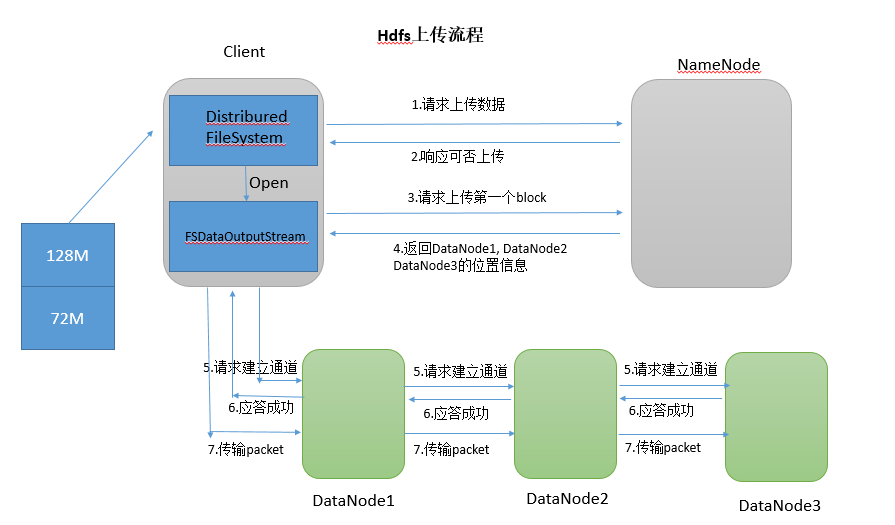
客户端访问NameNode请求上传文件;
-
NameNode检查目标文件和目录是否已经存在;
-
NameNode响应客户端是否可以上传;
-
客户端请求NameNode文件块Block01上传服务位置;
-
NameNode响应返回3个DataNode节点;
-
客户端通过输入流建立DataNode01传输通道;
-
DataNode01调用DataNode02,DataNode02调用DataNode03,通信管道建立完成;
-
DataNode01、DataNode02、DataNode03逐级应答客户端。
-
客户端向DataNode01上传第一个文件块Block;
-
DataNode01接收后传给DataNode02,DataNode02传给DataNode03;
-
Block01传输完成之后,客户端再次请求NameNode上传第二个文件块;
-
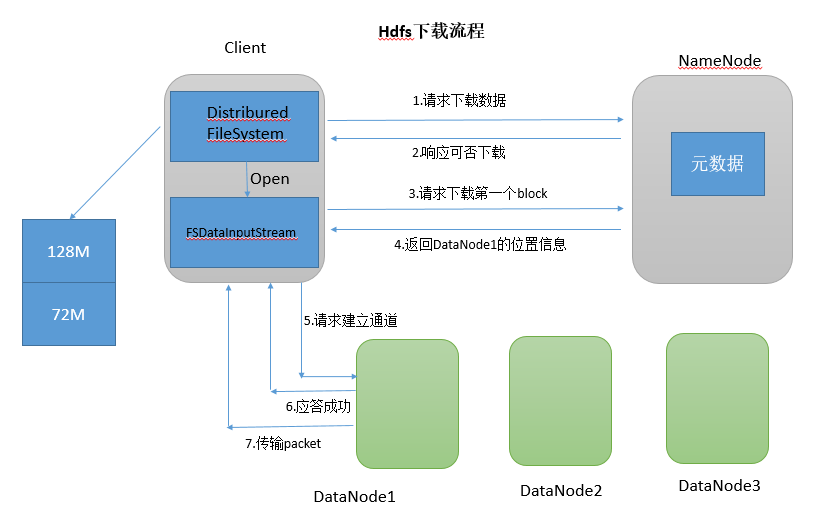
客户端通过向NameNode请求下载文件;
-
NameNode查询获取文件元数据并返回;
-
客户端通过元数据信息获取文件DataNode地址;
-
就近原则选择一台DataNode服务器,请求读取数据;
-
DataNode传输数据返回给客户端;
-
客户端以本地处理目标文件;
二、基础API案例
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.atguigu</groupId> <artifactId>hdfs</artifactId> <version>1.0-SNAPSHOT</version> <properties> <scala.version>2.11</scala.version> <scala.compat.version>2.11</scala.compat.version> <spark.version>2.2.0</spark.version> <hadoop.version>2.7.2</hadoop.version> <hbase.version>1.0</hbase.version> <mysql.version>8.0.15</mysql.version> </properties> <repositories> <repository> <id>nexus-aliyun</id> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </repository> </repositories> <dependencies> <!-- hadoop --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <!-- hadoop的客户端,用于访问HDFS --> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-auth</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-api</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-server-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-server-web-proxy</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> </project>
package com.atguigu.hdfsclient; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import java.io.FileInputStream; import java.net.URI; import org.apache.hadoop.io.IOUtils; import org.junit.Test; public class HdfsClient { @Test public void put() throws Exception { //TODO 1.获取一个HDFS的抽象封装对象 //设置配置文件 Configuration configuration=new Configuration(); configuration.setInt("dfs.replication",2); FileSystem fileSystem = FileSystem.get(URI.create("hdfs://hadoop102:9000"),configuration,"atguigu"); //TODO 2.通过这个对象操作文件系统 // 文件上传:copyFromLocalFile fileSystem.copyFromLocalFile(new Path("input/2.txt"),new Path("/")); // 文件下载:copyToLocalFile fileSystem.copyToLocalFile(new Path("/README.txt"),new Path("input/")); //修改文件名:rename fileSystem.rename(new Path("/1.txt"),new Path("/2.txt")); //删除文件夹:delete fileSystem.delete(new Path("/2.txt"),true); //流式拷贝 FSDataOutputStream out = fileSystem.append(new Path("/1.txt"),1024); FileInputStream in = new FileInputStream("input/2.txt"); IOUtils.copyBytes(in,out,1024,true); //查看文件:listStatus(即可以查看文件,又可以查看文件夹) FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/")); for(FileStatus fileStatus:fileStatuses){ if (fileStatus.isFile()){ System.out.println("file:"+ fileStatus.getPath()); }if(fileStatus.isDirectory()){ System.out.println("directory:"+ fileStatus.getPath()); } } //查看文件:listFiles(只查看文件,可以获取块信息) RemoteIterator<LocatedFileStatus> files = fileSystem.listFiles(new Path("/"), true); while (files.hasNext()){ LocatedFileStatus file = files.next(); System.out.println("****************"); System.out.println(file.getPath()); BlockLocation[] blockLocations = file.getBlockLocations(); for(BlockLocation blockLocation:blockLocations){ String[] hosts = blockLocation.getHosts(); for(String host:hosts){ System.out.println(host); } } System.out.println(); } //TODO 3.关闭文件系统 fileSystem.close(); } }
三、机架感知
第一个副本和client在一个节点里,如果client不在集群范围内,则这第一个node是随机选取的;
第二个副本和第一个副本放在相同的机架上随机选择;
第三个副本在不同的机架上随机选择,减少了机架间的写流量,通常可以提高写性能,机架故障的概率远小于节点故障的概率,因此该策略不会影响数据的稳定性。
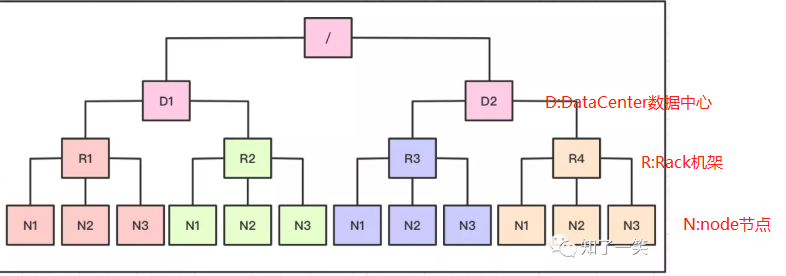
Distance(/D1/R1/N1,/D1/R1/N1)=0 相同的节点
Distance(/D1/R1/N1,/D1/R1/N2)=2 同一机架下的不同节点
Distance(/D1/R1/N1,/D1/R2/N1)=4 同一IDC下的不同datanode
Distance(/D1/R1/N1,/D2/R3/N1)=6 不同IDC下的datanode
posted on 2020-11-11 17:01 happygril3 阅读(123) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号