hadoop简介
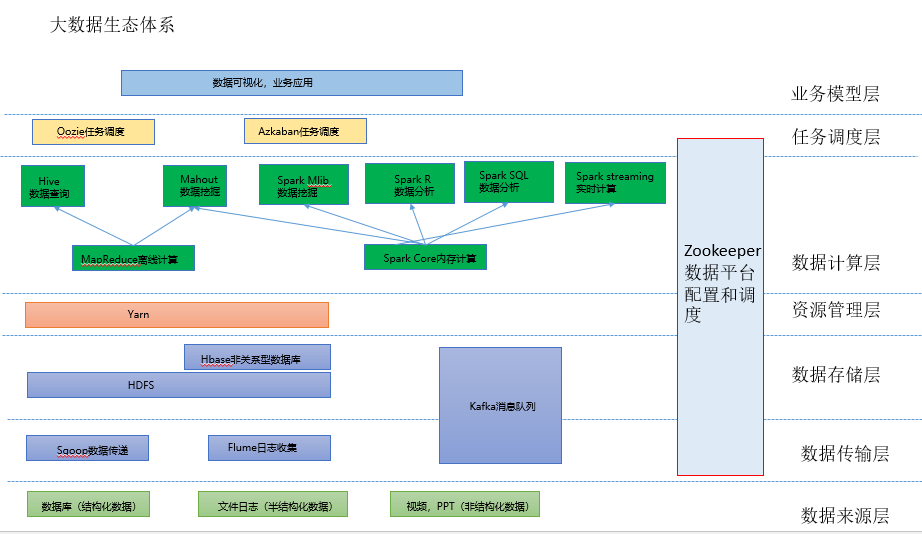
1.大数据生态系统
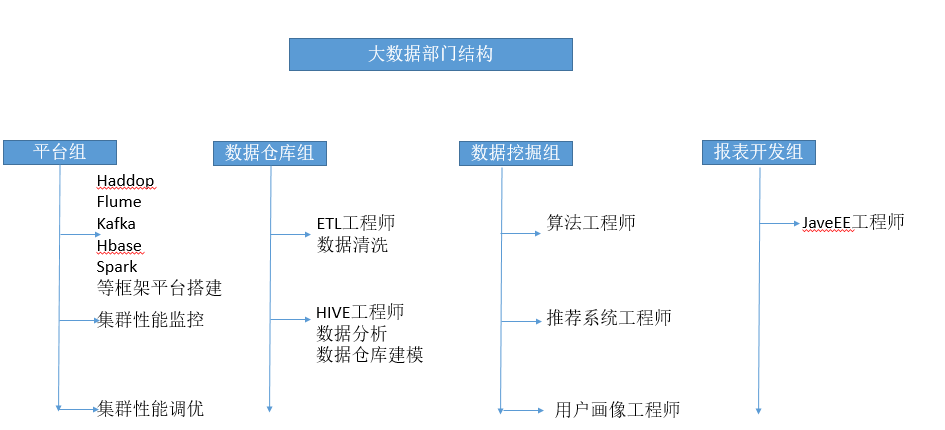
2 大数据部门结构
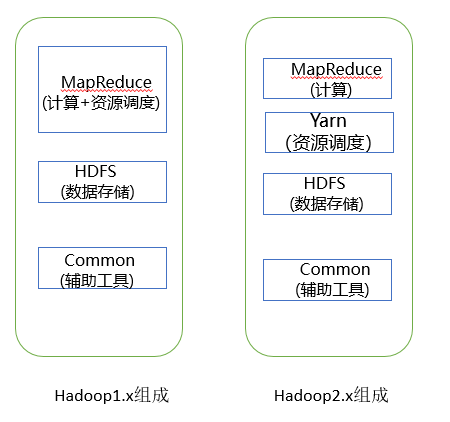
3 Hadoop入门教程
Hadoop是Apache开源组织的一个分布式计算开源框架,用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。
Hadoop框架中最核心设计就是:HDFS和MapReduce,HDFS实现存储,而MapReduce实现原理分析处理,这两部分是hadoop的核心。
4 HDFS文件系统
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。
HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(largedata set)的应用程序。
3.1 HDFS的master/slave构架
一个HDFS集群是有一个Namenode和一定数目的Datanode组成。
Namenode是一个中心服务器,负责管理文件系统的namespace和客户端对文件的访问。
Datanode在集群中一般是一个节点一个,负责管理节点上它们附带的存储。在内部,一个文件其实分成一个或多个block,这些block存储在Datanode集合里。
3.2 HDFS关键元素
(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块列表所在的DataNode等
(2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和
(3)Secondary NameNode(2nn) :用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照
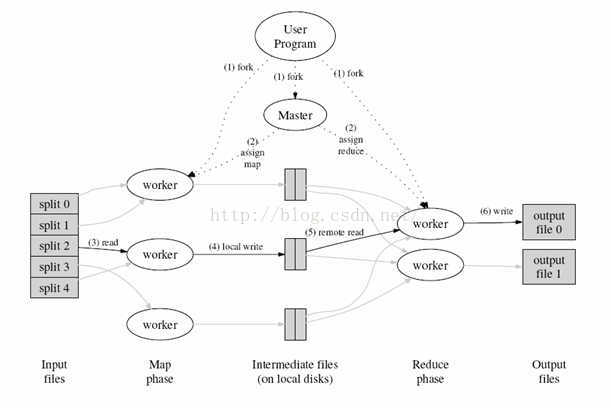
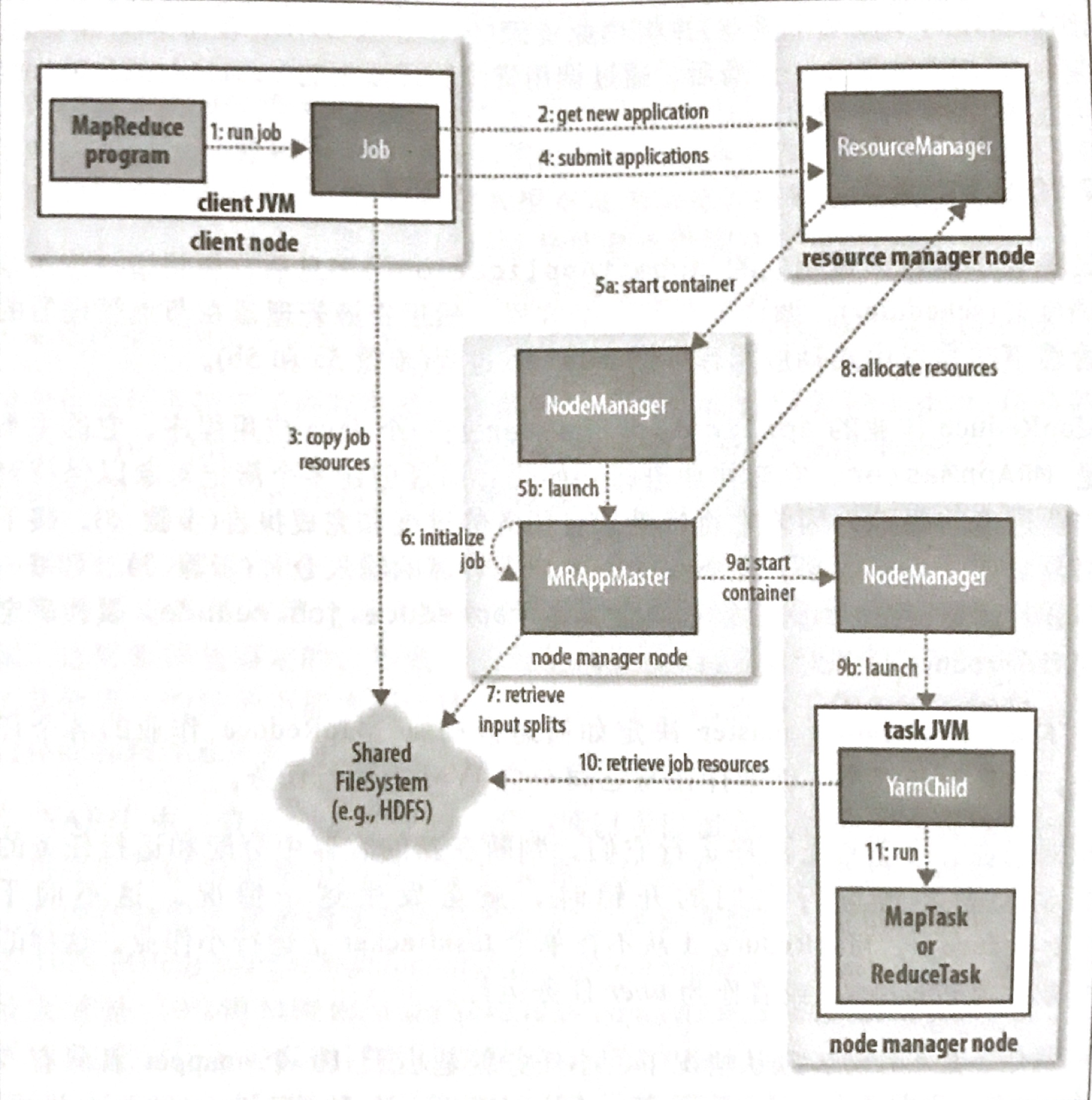
5 MapReduce文件系统
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。MapReduce将分成两个部分"Map(映射)"和"Reduce(归约)"。
当你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。Reduce任务的主要目标就是把前面若干个Map的输出汇总到一起并输出。
步骤1:首先对输入数据源进行切片
步骤2:master调度worker执行map任务
步骤4:worker读取输入源片段,worker执行map任务,将任务输出保存在本地
步骤5:master调度worker执行reduce任务
步骤6:worker读取map任务的输出文件,worker执行执行reduce任务,将任务输出保存到HDFS
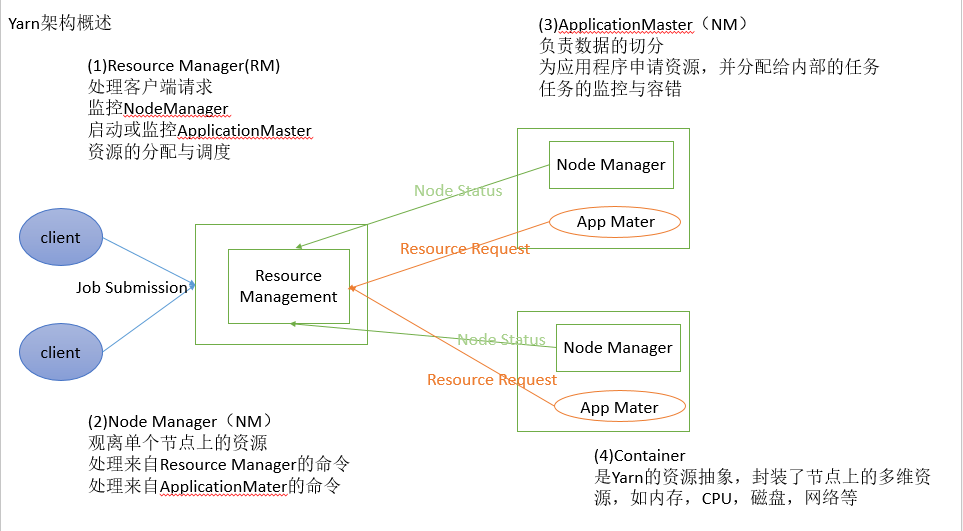
6 Yarn
posted on 2020-10-30 16:44 happygril3 阅读(160) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号