
剪枝
为了尽可能正确分类训练样本,又可能造成分支过多,造成过拟合
剪枝:主动剪掉一些分支来降低过拟合的风险
预剪枝:提前终止某些分支的生长
后剪枝:生成一颗完全数,再回头剪枝
1. 预剪枝
每次生长一次,都会在验证集上做一次预估,看看效果有没有提升;如果有提升,就生长,;如果没有,就停止
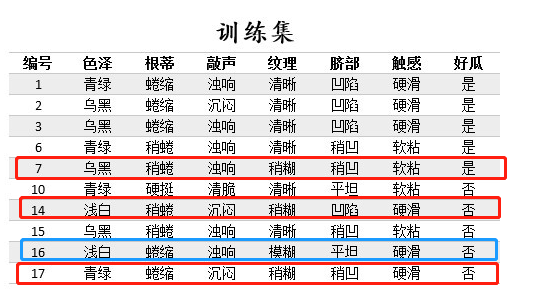
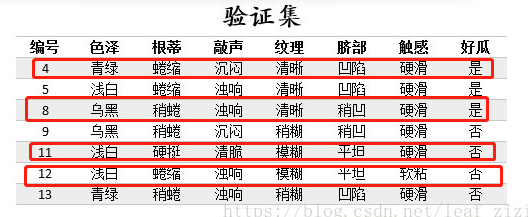
(1)根据信息增益准则,选取“色泽”作为根节点进行划分,会产生3个分支(青绿、乌黑、浅白)。

对根节点“色泽”,若不划分,该节点被标记为叶节点,训练集中正负样本数相等(正5负5),我们将其标记为“是”好瓜(当样本最多的类不唯一时,可任选其中一类,我们默认都选正类)。
那么验证集的7个样本中,3个正样本被正确分类,验证集精度为3/7*100%=42.9%。
对根节点“色泽”划分后,产生图中的3个分支,验证集中的7个样本中,编号为{8,11,12,4}的4个样本被正确分类,验证集精度为4/7*100%=57.1%。
于是节点“色泽”应该进行划分。
2. 后剪枝
先生长完树,然后判断剪之前,和剪之后,验证集有没有提升
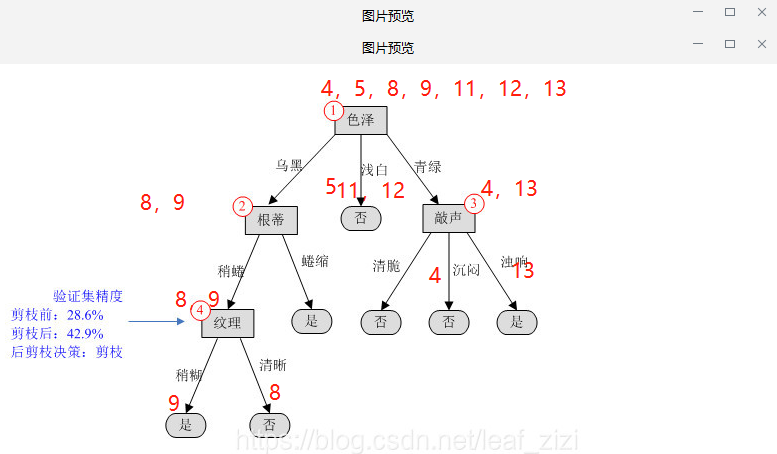
在剪枝前,编号为{11,12}的两个样本被正确分类,因此其验证集精度为2/7*100%=28.6%。
考察编号为4的结点,如果剪掉该分支,该结点应被标记为“是”。进入该分支的验证集样本有{8,9},样本8被正确分类,对整个验证集,编号为{8,11,12}的样本正确分类,因此验证集精度提升为42.9%,决定剪掉该分支。
(3)比较

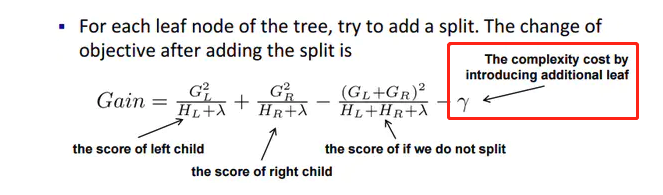
(4)xgboost代价函数里加入正则项
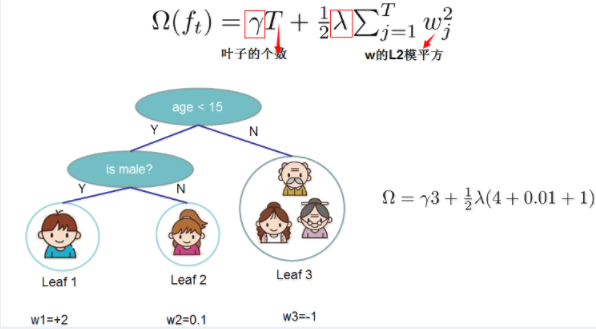
xgboost中树节点分裂时所采用的公式:分裂后的某种值 减去 分裂前的某种值,得到增益。
posted on 2020-10-22 15:49 happygril3 阅读(262) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号