
树模型
1.正则化
(1) 随机森林
样本有放回随机采样,特征值采样(每个结点都采一次样,而不是一颗树采一次);
剪枝,控制tree深度,控制gain或者gini变化大小
以及控制结点样本数等情况,随机森林中没有剪枝操作,但是有max_depth,min_size等进行控制(2)GBDT
和Adaboost一样,我们也需要对GBDT进行正则化,防止过拟合。GBDT的正则化主要有三种方式:
第一种是和Adaboost类似的正则化项,即步长(learning rate),防止过拟合就要稍微加大步长:f_k(x)=f_{k−1}(x)+νh_k(x)
第二种正则化的方式是通过子采样比例(subsample)。
第三种是对于弱学习器即CART回归树进行正则化剪枝。
(3)XGBOOST
xgboost在代价函数里加入了正则化项,用于控制模型的复杂度。正则化项里包含了:
树的叶子节点个数
每个叶子节点上输出的score=L2模的平方和。
Shrinkage(缩减),相当于学习速率。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了消弱每棵树的影响,让后面有更大的学习空间。
2.归一化
GBDT的“梯度提升”体现在那个阶段
在构建cart树时使用了损失函数的负梯度,但是在平方损失的情况下,残差=真值-预测值;另外使用损失函数的梯度可以保证损失函数最小值。所以GBDT的梯度提升体现在构建cart树的所需的负梯度阶段,其利用最速下降的近似方法。
- 随机森林:不需要归一化,概率树模型
- GBDT:需要归一化,梯度下降
- XGBOOST:不需要归一化,概率树模型
3.缺失值
- 随机森林:自动处理缺失值:暴力填补:如果是类别变量缺失,则用众数补全,如果是连续变量,则用中位数。相似度矩阵填补:如果是分类变量,则用没有缺失的观测实例的相似度中的权重进行投票;如果是连续性变量,则用相似度矩阵进行加权求均值。
- GBDT:
- XGBOOST:自动处理缺失值:xgboost把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计算损失,选择较优的那一个。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树。
4.异常值
- 随机森林:异常值不敏感
- GBDT:异常值敏感
- XGBOOST:
5.连续性/离散型变量
- 随机森林:连续值和离散值
- gbdt:连续值和离散值
- XGBOOST:连续值和离散值:Xgb中需要将离散特征one-hot编码
6.特征选择
- 随机森林(Random Forest):用袋外数据 (OOB) 做预测。
随机森林在每次重抽样建立决策树时,都会有一些样本没有被选中,那么就可以用这些样本去做交叉验证,这也是随机森林的优点之一。它可以不用做交叉验证,直接用oob _score_去对模型性能进行评估。
具体的方法就是:
1. 对于每一棵决策树,用OOB 计算袋外数据误差,记为 errOOB1;
2. 然后随机对OOB所有样本的特征i加入噪声干扰,再次计算袋外数据误差,记为errOOB2;
3. 假设有N棵树,特征i的重要性为sum(errOOB2-errOOB1)/N;
如果加入随机噪声后,袋外数据准确率大幅下降,说明这个特征对预测结果有很大的影响,进而说明它的重要程度比较高
- GBDT:计算特征i在单棵树中重要度的平均值

- XGboost:该特征每棵树中分裂次数的和去计算的,比如这个特征在第一棵树分裂1次,第二棵树2次……,那么这个特征的得分就是(1+2+...)。
7.损失函数
8.采样
- 随机森林:样本采样(有放回)/特征采样(无放回)
- GBDT:样本采样(无放回):比如有100个样本,subsample=0.8,第一棵树训练时随机从100个样本中抽取80%,有80个样本训练模型;第二棵树再在100个样本再随机采样80%数据,也就是80个样本,训练模型;以此类推。
- XGBOOST:样本采样(有放回)/特征采样
9.并行
-
随机森林:模型并行处理
-
GBDT:模型串行
-
XGBOOST:特征并行处理:将特征列排序后以block的形式存储在内存中,在后面的迭代中重复使用这个结构。这个block也使得并行化成为了可能,
![]()
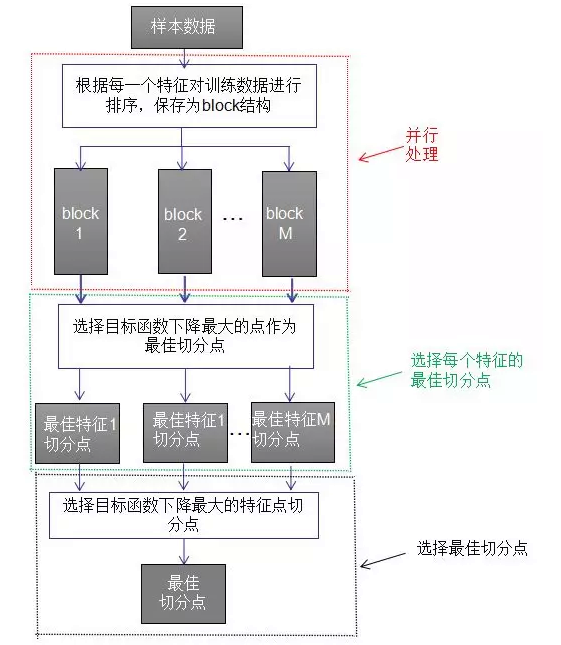
10.特征选择
随机森林:能处理很高维度的数据,并且不用做特征选择
11.分类/回归
- 随机森林:回归树,分类树
- GBDT:回归树:GBDT是加法模型,分类模型的结果加减没意义;GBDT主要是利用损失函数的负梯度拟合残差,这就意味每棵树的值是连续。
- xgboost:回归树,分类树
12.分裂点
- 随机森林:遍历一个节点内的所有特征,按照公式计算出按照每一个特征分割的信息增益,找到信息增益最大的点进行树的分割。
- gbdt:遍历一个节点内的所有特征,按照公式计算出通过最小化平方误差
- XGBoost:不会枚举所有的特征值,而会对特征值进行聚合统计,按照特征值的密度分布,构造直方图计算特征值分布的面积,然后划分分布形成若干个bucket(桶),每个bucket的面积相同,将bucket边界上的特征值作为splitpoint的候选,遍历所有的候选分裂点来找到最佳分裂点。
posted on 2020-10-14 09:42 happygril3 阅读(572) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号