数据倾斜
map端数据倾斜:输入文件大小不一致
reduce端数据倾斜:partition不一致
小表要放在前面,大表放在后面
例如A表id=3有1条记录,B表id=3有10条记录。
首先读取v[0]发现是A表的记录,用了1次读取操作。然后再读取v[1]发现是B表的操作,这时v[0]和v[1]可以直接关联输出了,累计用了2次操作。
这时候reduce已经知道从v[1]开始后面都是B 表的记录了,因此可以直接用v[0]依次和v[2],v[3]……v[10]做关联操作并输出,累计用了11次操作。
假设A表id=3有10条记录,B表id=3有1条记录。
首先读取v[0]发现是A表的记录,用了1次读取操作。然后再读取v[1]发现依然是A表的记录,累计用了2次读取操作。以此类推,读取v[9]时发现还是A表的记录,累计用了10次读取操作。
然后读取最后1条记录v[10]发现是B表的记录,可以将v[0]和v[10]进行关联输出,累计用了11次操作。
接下来可以直接把v[1]~v[9]分别与v[10]进行关联输出,累计用了20次操作。
(1)group by
当遇到group by字段得某些值特别多,会将相同值拉到同一个reduce任务集合中
优化:
开启map端聚合:hive.map.aggr=true
负载均衡:hive.groupby.skewindata=true
--生成得查询计划会生成两个mapreduce任务
--第一个mapreduce中,map输出结果会随机分配到reduce,相同得key可能分到不同得reduce
--第二个mapreduce中,相同得key分到同一个reduce
(2)count(distinct)
count(distinct)操作是由一个reduce来完成
优化:先group by 再count
select count(id) from (select id from table group by id) a
(3)join
Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join)
Common Join
select u.name, o.orderid from order o join user u on o.uid = u.uid;
Map阶段: 读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;
按照key进行排序
Shuffle阶段 :根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce
Reduce阶段 :根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
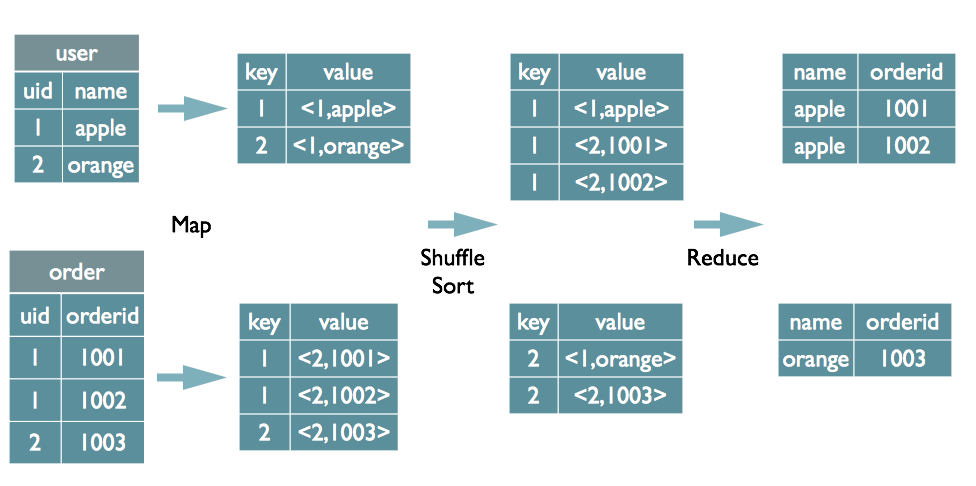
Map Join
(1)大表与小表join
根据mapjoin的计算原理,MapJoin会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配。这种情况下即使笛卡尔积也不会对任务运行速度造成太大的效率影响。
而且hive的where条件本身就是在map阶段进行的操作,所以在where里写入不等值比对的话,也不会造成额外负担。
Hive0.7之前,需要使用hint提示 /+ mapjoin(table) /才会执行MapJoin,否则执行Common Join,
0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true.
1.1 /*+ MAPJOIN(a) */
select /*+ MAPJOIN(a) */ a.start_level, b.*
from dim_level a
join (select * from test) b
where b.xx>=a.start_level and b.xx<end_level
1.2
set hive.auto.convert.join=true;
select count(*) from store_sales join time_dim on (ss_sold_time_sk = t_time_sk)
(2)大表与大表join
2.1 如果一张表null(其他值)比较多,容易导致这些值在reduce阶段集中在一个或者几个reduce上
优化:将null值提取出来,只有map操作,非null值分散到不同reduce上--两次table scan导致map增多
select * from log a
join users b
on a.user_id is not null
and a.user_id = b.user_id
union all select * from log a where a.user_id is null;
2.2 在join时直接把Null值打散成随机值来作为reduce的key
select * from log a
left join users b on case when a.user_id is null then concat(‘hive’,rand() ) else a.user_id end = b.user_id;
2.3 表不大
select /*+mapjoin(x)*/* from log a
left outer join (
select /*+mapjoin(c)*/d.*
from ( select distinct user_id from log ) c
join users d
on c.user_id = d.user_id
) x
on a.user_id = b.user_id;
posted on 2020-09-25 15:07 happygril3 阅读(177) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号