
随机森林
分类与回归两种类型的问题
(1)主体思想:随机森林利用随机的方式将许多决策树组合成一个森林,每个决策树在分类的时候投票决定测试样本的最终类别。
1. 随机选择样本
给定一个训练样本集,数量为N,我们使用有放回采样到N个样本,构成一个新的训练集。
2. 随机选择特征
总量为M的特征向量中,随机选择m个特征,其中m可以等于sqrt(M),然后计算m个特征的增益,选择最优特征(属性)。
计算m个特征的ID3或者C4.5或者基尼系数,然后选择一个最大增益的特征作为划分下一个子节点的走向。
随机选择特征是无放回的选择
(2)重要参数
首先增大n_estimators,提高模型的拟合能力,当模型的拟合能力没有明显提升的时候,则在增大max_features,提高每个子模型的拟合能力
1. Bagging框架的参数
1) n_estimators: 决策树个数,默认是100。
2) oob_score :即是否采用袋外样本来评估模型的好坏。默认识False。个人推荐设置为True,因为袋外分数反应了一个模型拟合后的泛化能力。
3) criterion: 即CART树做划分时对特征的评价标准。
分类RF默认是基尼系数gini,另一个可选择的标准是信息增益。
回归RF默认是均方差mse,另一个是绝对值差mae。
2. CART决策树的参数
1) max_features: 最大特征数,默认是"auto",意味着√N个特征;
如果是"log2"意味着划log2N个特征;
如果是整数,代表考虑的特征绝对数。
如果是浮点数,代表考虑特征百分比
2) max_depth:决策树最大深度: 默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。
一般来说,数据少或者特征少的时候可以不管这个值。
如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
3) min_samples_split: 内部节点再划分所需最小样本数
默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
4) min_samples_leaf:叶子节点最少样本数: 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。
如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
(3)变量重要性衡量指标:精度/节点不纯度平均减少值
方法一:计算每棵树的每个划分特征在划分准则(gini或者entropy)上的提升,然后对聚合所有树得到特征权重
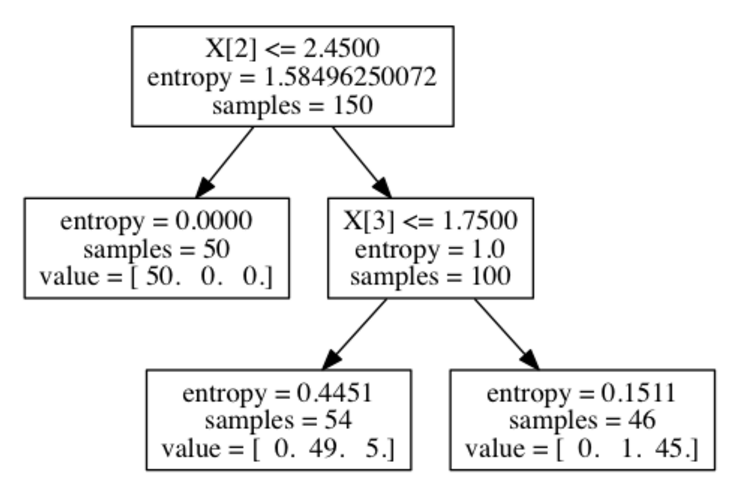
根据上面生成的树,我们计算特征2和特征3的权重
特征2: 1.585*150 - 0*50 - 1.0*100 = 137.35
特征3: 1.0*100 - 0.445*54 - 0.151*46 = 69.024
归一化之后得到[0, 0, 0.665, 0.335]
方法二:袋外数据
1.对于每颗决策树,使用相应的袋外数据(oob)计算误差,记作errorOOB1
2.随机对袋外数据的所有样本加入噪声数据,再次计算误差,记作errorOOB2
3. 假设随机森林有n颗树,则特征X的重要性=Σ(errorOOB2-errorOOB1/)n
(4)填补缺失值
方法一:暴力填补
同一个类别下的数据,如果是类别变量缺失,则用众数补全,如果是连续变量,则用中位数。
方法二:相似度矩阵填补
原理就是如果两个样本落在树的同一个叶子节点的次数越多,则这两个样本的相似度越高。
给缺失值预设一些估计值,选择其余数据的中位数或众数作为当前的估计值
然后,根据估计的数值,建立随机森林,把所有的数据放进随机森林里面跑一遍。记录每一组数据在决策树中一步一步分类的路径.
判断哪组数据和缺失数据路径最相似(同一个叶子节点),引入一个相似度矩阵,来记录数据之间的相似度,比如有N组数据,相似度矩阵大小就是N*N
如果缺失值是类别变量,通过权重投票得到新估计值,如果是数值型变量,通过加权平均得到新的估计值,如此迭代,直到得到稳定的估计值。
(4)优点:
1. 它能够处理很高维度(feature很多)的数据,并且不用做特征选择;
2. 由于随机选择样本导致的每次学习决策树使用不同训练集,所以可以一定程度上避免过拟合;
3. 就算存在大量的数据缺失,随机森林也能较好地保持精确性;
4.当存在分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法;
5.训练速度快,容易做成并行化方法
缺点:
1.随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
2.对于有不同级别的属性的数据,级别划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
posted on 2020-09-10 09:05 happygril3 阅读(424) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号