词汇挖掘与实体识别
3.1 概述
实体的获取:
从文本语料库挖掘尽可能多的高质量词汇
领域短语挖掘
同义词挖掘
缩略词挖掘
实体识别
当一个词汇在某个上下文表达的是某个预定义的概念时,该词汇就是一个实体
词汇表:
主题词
关系:等价关系,等级关系
3.2 领域短语挖掘
3.2.1 问题描述
输入:领域预料
输出:高质量短语(High Quality Phrase)
高质量短语:连续出现的单词序列,即w1w2w3....wn,本质上是一个N-Gram,N指短语的长度
如:support vector machine
1-Gram有support , vector ,machine
2-Gram有support vector,vector machine
3-Grame有support vector machine
隐含迪利克雷分布(Latent Dirichlet Allocation LDA)
输入:若干文档
输出:每篇文档的主题分布和每个主体的词分布
领域短语挖掘:
输入:不区分多篇文档,将所有合并为一个大文档
输出:高质量短语
关键词抽取:从语料库中抽取最重要,最具代表性的短语,数量较少
新词发现:发现词汇库中不存在的新词汇
3.2.2 领域短语挖掘方法
无监督学习的领域短语挖掘

(1)候选短语生成:高频得N-Gram(连续得N个字/词序列)
大预料,阈值一般取30,对于中文短语挖掘,如果先分词,则N最大值一般设为6
(2)统计特征计算:计算候选短语得统计特征
TF-IDF(频率-逆文档频率),PMI(点互信息),C-value,NC-value,左邻字熵,右邻字熵
(3)质量评分:特征值融合(如加权求和)
(4)排序输出:根据分数由高到底排序,通常取前K个短语或者根据阈值筛选
监督学习的领域短语挖掘

样本标注
人工标注
远程监督标注:用在线知识库(百度百科,维基百科)作为高质量短语的来源,如果一个短语是在线知识库的一个词条,则为高质量短语
分类器学习:二分类模型,决策树,随机森林,支持向量机
预料切割与高质量短语识别相互增强的迭代式短语挖掘过程
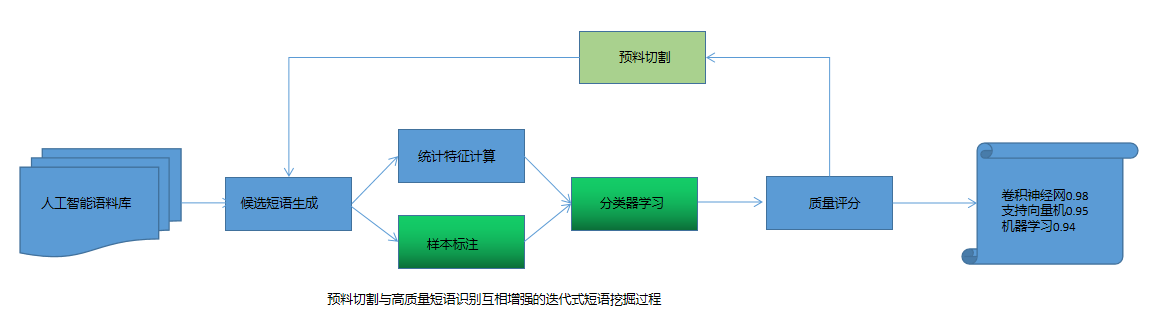
原因:一旦某个父短语(支持向量机)是高质量短语,那么它的一次出现就不应该重复累计到其他任何子短语上
结果:支持向量机,向量机,支持向量的词频从1,1,1改为1,0,0
方法:预料切割与高质量短语识别两者互相增强
3.2.3 统计指标特征

(1)TF-IDF(Term Frequency-Inverse Document Frequency)词频-逆文档频率
思想:如果某个短语在领域预料中频繁出现,但是在外部文档中很少出现--->高质量短语
TF: 语料中该词汇出现的频数f(u)/语料中所有词汇的累计频数
tf(u)=f(u)/ Σu' f(u')
IDF:外部文档总数/包含该词汇的外部文档数 (通常取对数,为避免分母为0,加一个非0正常数δ平滑处理)
idf(u)=log [ |D|+δ / | j:u∈dj |+δ]
|D|:外部文档的总数
dj是第j篇外部文档
(2)C-value
词频,短语的长度,父子短语对于词频统计的影响
C-value(u)= log2 |u| .f(u)u没有父短语
C-value(u)= log2 |u|(f(u)-1/|Tu| Σb∈Tu f(b)) u有父节点
log2 |u|奖励较长的短语
Tu是u的所有父短语,|Tu|是父短语的数量
(3)NC-Value
上下文信息
候选短语u的上下文单词b∈Cu的影响,其中fu(b)指的是b作为u的上下文出现的次数,weight(b)是衡量b的重要性
通过C-value值对候选短语进行初步排序-->选取前5%候选短语-->上下文所出现的单词作为b
NV-value(u)=0.8C-value(u)+0.2Σb∈Cu fu(b)weight(b)
weight(b)=t(b)/n
t(b):前5%候选短语与单词b在文本中共出现的次数
n:前5%候选短语的数量
weight(b)越大,说明b越倾向于出现在高质量短语的上下文中,越有助于找到高质量短语
(4)PMI(Pointwise Mutual Information)点互信息
短语组成部分之间的一致性(Concordance)
假设某个短语u由ul与ur两部分组成,ul与ur的PMI值越大,u越有可能是ul与ur的一个有意义组合
PMI(ul,ur)=log p(u)/p(ul)p(ur)
如果 p(u)=p(ul)p(ur),说明两个词语是独立的
如果 p(u)远大于p(ul)p(ur),说明那个部分的共现是一个有意义的搭配
当u=电影院,ul=电影,ur=院,
p(ul):语料中“电影”单独出现的概率
p(ur):语料中“院”单独出现的概率
p(ul,ur):语料中“电影院”单独出现的概率
一个候选短语有多种拆分方式,比如电影院还可以拆分为“电”和“影院”
同一个候选短语在不同的拆分方式下得到的PMI值不同
需要枚举候选短语的所有拆分方式,一般取最小的PMI值作为该短语的最终PMI值
此时p(ur)和p(ul)是各种拆分方式下的最大值,即ul和ur本身都是最常见的单词或短语
尽管“的电影”和“电影院”都有较高的出现频次,但是通过PMI可以识别出“电影院”相对于“的电影”是质量较高的短语
“电影院”的组成部分(“电影”和“院”)之间的一致性明显高于“的电影”的组成部分(“的”和“电影”)之间的一致性。
(5)左邻字熵和右邻字熵
好的短语应该有好的左邻字集合和右邻字集合,反之,如果左右邻字总是某一词汇,则说明本身不是好的词汇
如“亚里斯多”的右邻字比较固定。总是“德”,所以一般不会把它当作一个短语
H(u)=-Σx∈X p(x)log p(x)
p(x):某个左(右)邻字x出现的概率
X:u所有左(右)邻字的集合
希望一个候选短语的左邻字熵和右邻字熵都较大,最后选择左邻字熵和右邻字熵的较小值来衡量该短语的质量
3.3 同义词识别
3.3.1 概述
同义词:语义相似或相同,形式上可能完全不相关
同义关系:
不同国家之间的语言互译:如“玩具”英文“toy”
具有相同含义的词:男孩和男生
中国人的字,号,名,雅号,尊号等:如苏轼和苏东坡
动植物,药品,疾病等的别名或俗称:番茄和西红柿
简称:江西省简称赣
3.3.2 典型方法
(1)基于同义词资源
字典/网络字典/百科词条
维基百科/百度百科
(2)基于模式匹配
X 又称/简称/亦称/别名/全称/俗称 Y
X(Y)
(3)自举法(Bootstrapping)
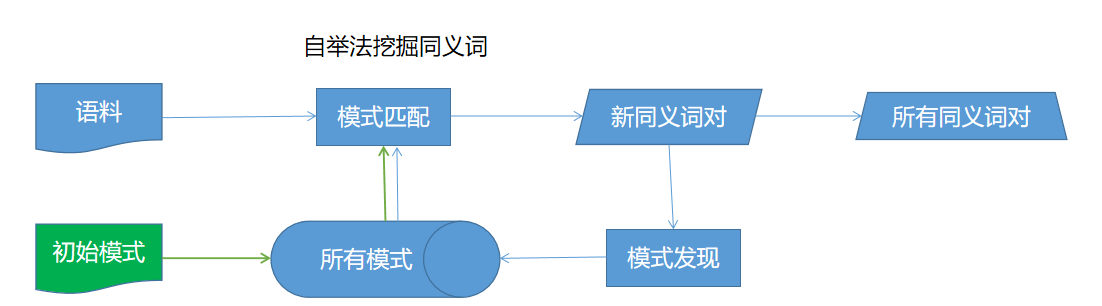
基于模式匹配的改进,从预定义的模式出发,不断从语料中学习同义词在文本中的新表达模式
(4)序列标注模型
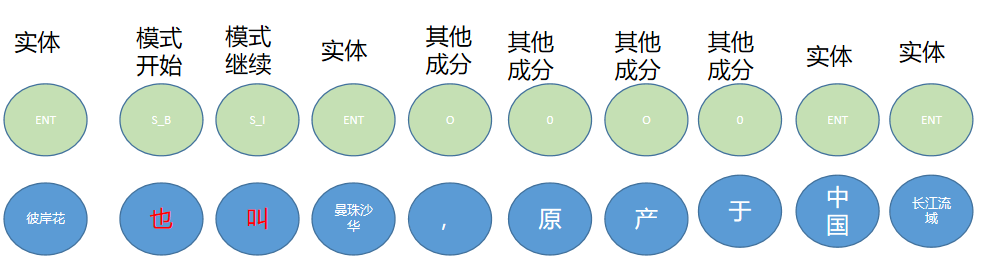
挖掘同义词的文本描述模式
(5)图模型
基于词与词之间的相似性可以构建一张词汇关联图,同义词在图上呈现“抱团”的结构特征
同义词之间关联紧密,不同词之间关联稀疏---.社团发现
图结构:计算每队词语对应的词向量之间的余弦相似度,如果大于阈值,则添加边。
图划分:最大化模块度(Modularity)对图进行划分
3.4 缩略词抽取
3.4.1 缩略词的检测和抽取
(1)基于文本模式的抽取
X(Y), X.*(Y), Y is the abbreviation of X, X also known as Y, X and Y are synoyms
(2)抽取结果的清洗和筛选
利用缩略词的统计指标进行识别
频率(原词出现的频率,缩略词出现的频率,共出现的频率)
卡方检验
互信息
最大熵
使用机器学习模型构建二分类模型
统计特征
文本特征
字符匹配程度:缩略词是否包含全程以外的词,编辑距离,长度差异,位置
如:“上海交通大学”,“上海交”位置靠前的三个字,“上交大”比较均匀
词性特征:全称和缩略词中包含的词性标签
如:“北京大学”,北京为地名(ns),大学为普通名词(n),缩略词只保留地名或者缩略词都是不合理的。
(3) 枚举并剪枝
首先穷举所有可能的缩略形式-->排除没有在文本中出现过的或者出现次数太少的缩略词-->选择上下文相似的缩略词
3.4.2 缩略词的预测
输入:全称的相关文本,通过模型预测可能的缩略形式
(1)基于规则
针对特定字符和词语形式的局部规则:
基于词性:数字常会被保留,如“北京市第四中学”-->“北京四中”
基于位置“国家名用第一个字作简称,如”中国“-->"中"
基于词之间的相互关联:相邻同类型词往往会保留一部分,如”中国日本友好协会“-->"中日友协"
依赖语言环境的全局规则
”南大“一般指的是”南京大学“,因此在预测”南开大学“时需要避开”南大“
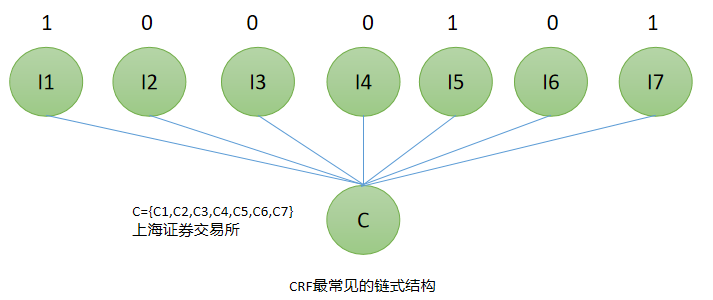
(2)条件随机场(CRF)
绝大多数的缩略词都由全程中包含的字符组成,且字符间的顺序往往会保留--->序列标注模型

输入字符序列C=c1c2......cT,输出标签序列L=l1l2....lT
预测模型需要用到的特征:
字符级特征:字符本身表示机构的字(所,局)
词级别特征:大学(大),地名
位置特征:第一个和最后一个
关联特征:以”大学“结尾时。地名会保留
(3)深度学习
词或字符被表示为一个低维度稠密空间中的向量
3.5 实体识别
3.5.1 概述
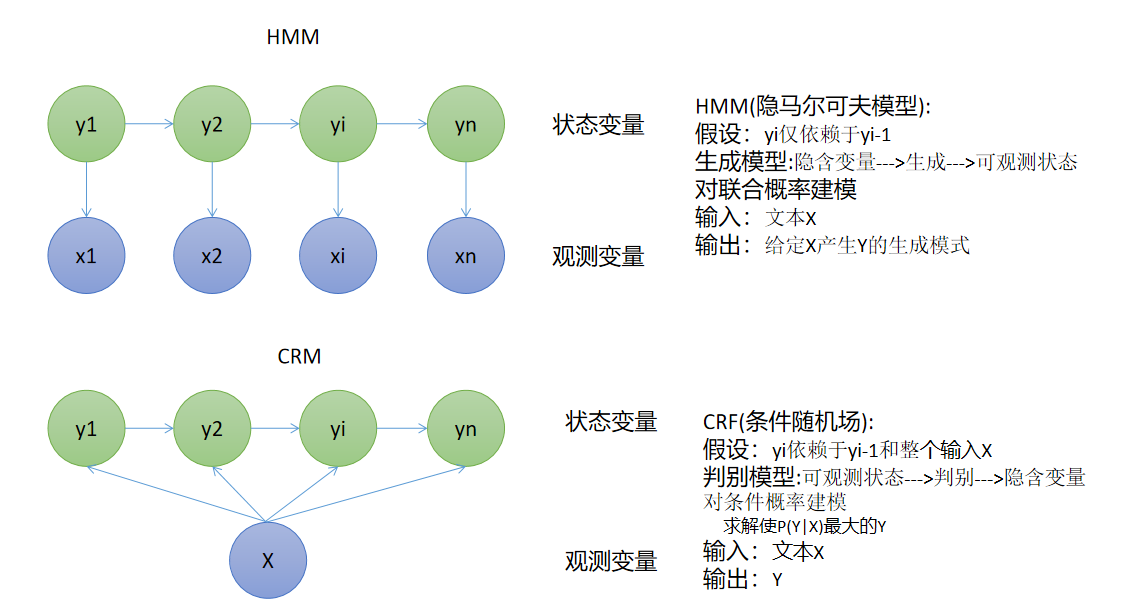
命名实体识别(Named Entity Recognition,NER)
输入:一个句子对应的单词序列s=<w1,w2,.........wN>
输出:三元组组合<Is,Ie,t>
Is:命名实体的开始位置
Ie:命名实体的结束位置
t:实体类型
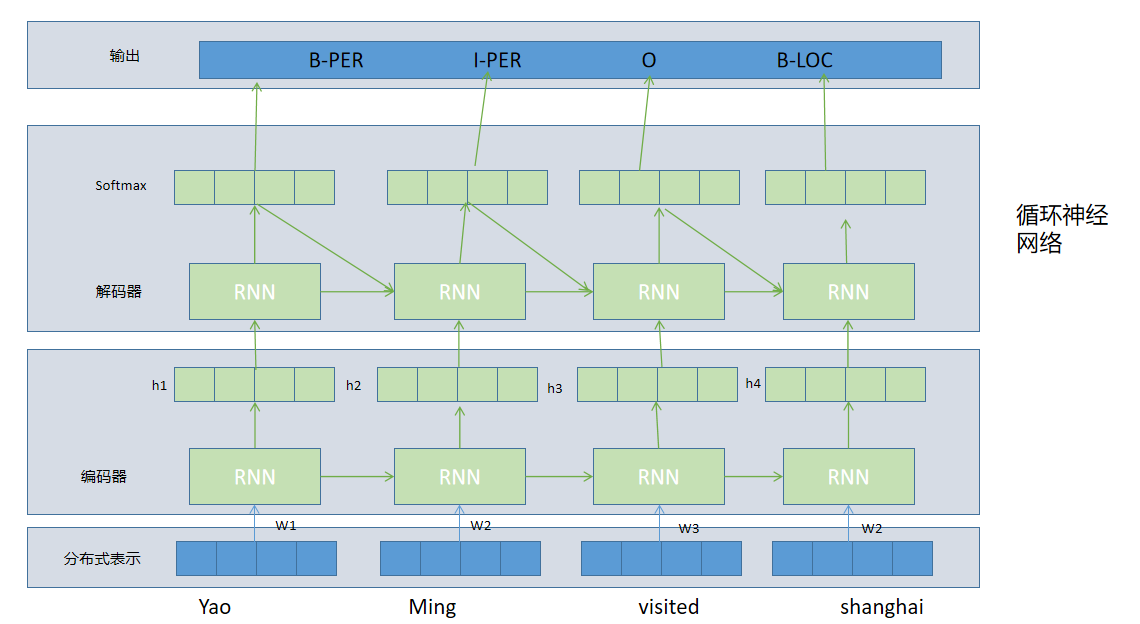
如输入序列"Yao Ming was born in Shanghai ",NER会识别输出
<1,2,Person>(对应实体Yao Ming)
<6,6,Location>(对应实体Shanghai)
3.5.2 传统的NER方法
(1)基于规则,词典和在线知识库的方法
基于规则,词典和在线知识库,依赖语言专家手工构造规则。
每条规则赋予权值
规则冲突时,选择全职最高的规则判别命名实体的类型
(2)监督学习方法
NER被建模为序列标注问题
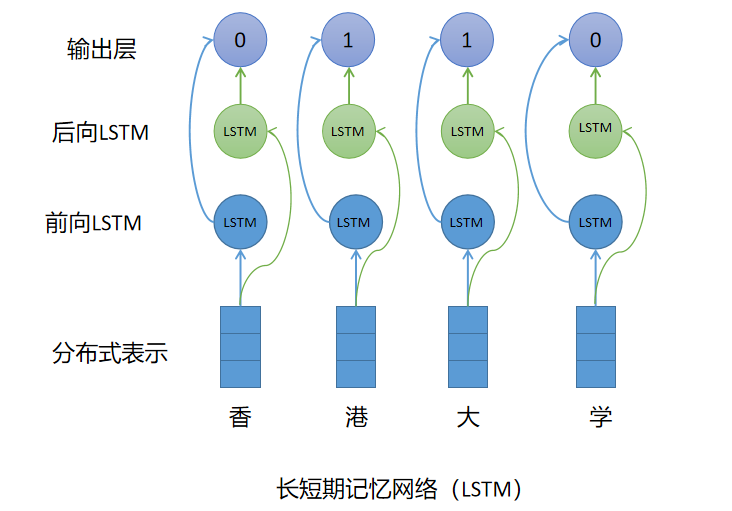
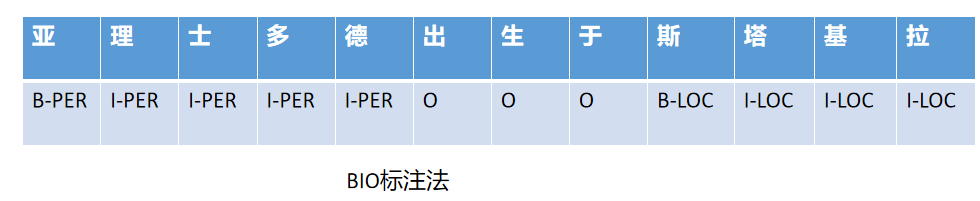
NER任务使用BIO标注法,B表示实体的起点,I表示实体的中间位置或者结束位置,O表示相应字符不是实体
HMM和CRF
特征:核心词特征,词典特征,构词特征,词形特征,词缀特征,词性特征

(3)半监督学习方法
自举法:
从少量标注数据和一小组初始假设或分类器开始,迭代生成更多的标注数据,直到达到某个阈值

协同训练(Co-training):
两套不同的实体识别规则,每一类规则为另一类规则提供弱监督
拼写规则:如人物名称通常是首字母大写(Yao Ming YM)
上下文规则:出现”president“周围的名字应该是人物名字
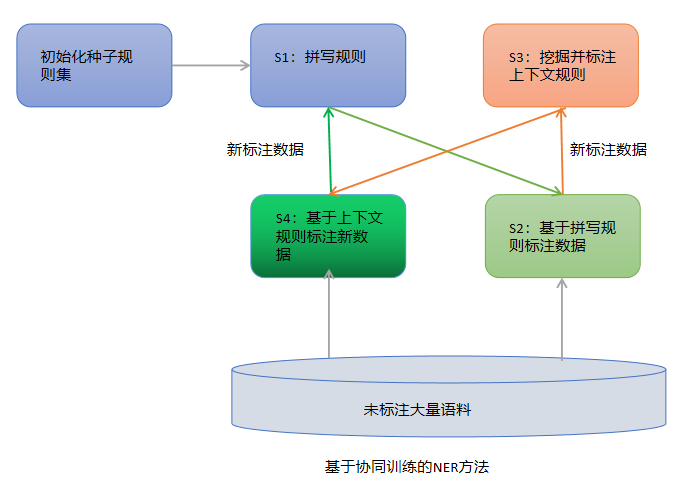
3.5.3 基于深度学习的NER方法
(1)输入的分布式表示(Distribute Representation)
词向量:无监督算法,词袋模型(CBOW)和Skip-Gram模型
字向量:CNN,RNN
混合表示:词向量+字向量+传统工程向量
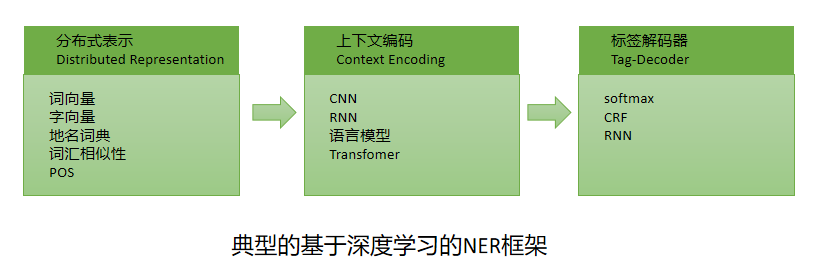
(2)上下文编码器(Context Encoder)
卷积神经网络:整个句子作为输入
使用一层卷积神经网络结构,在每个单词的周围提取局部特征
组合卷积层提取的局部特征向量来构造全局特征向量
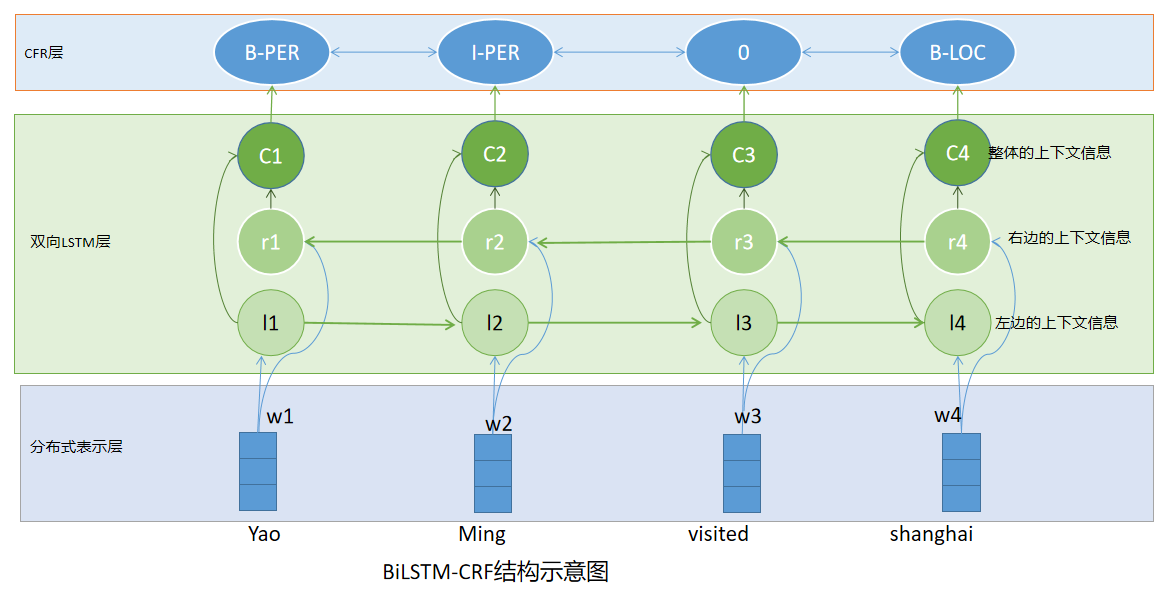
循环神经网络:考虑前后字符之间的相互影响
(3)标签解码器(Tag Decoder)
输入:编码的上下文表示
输出:输入句子的标签
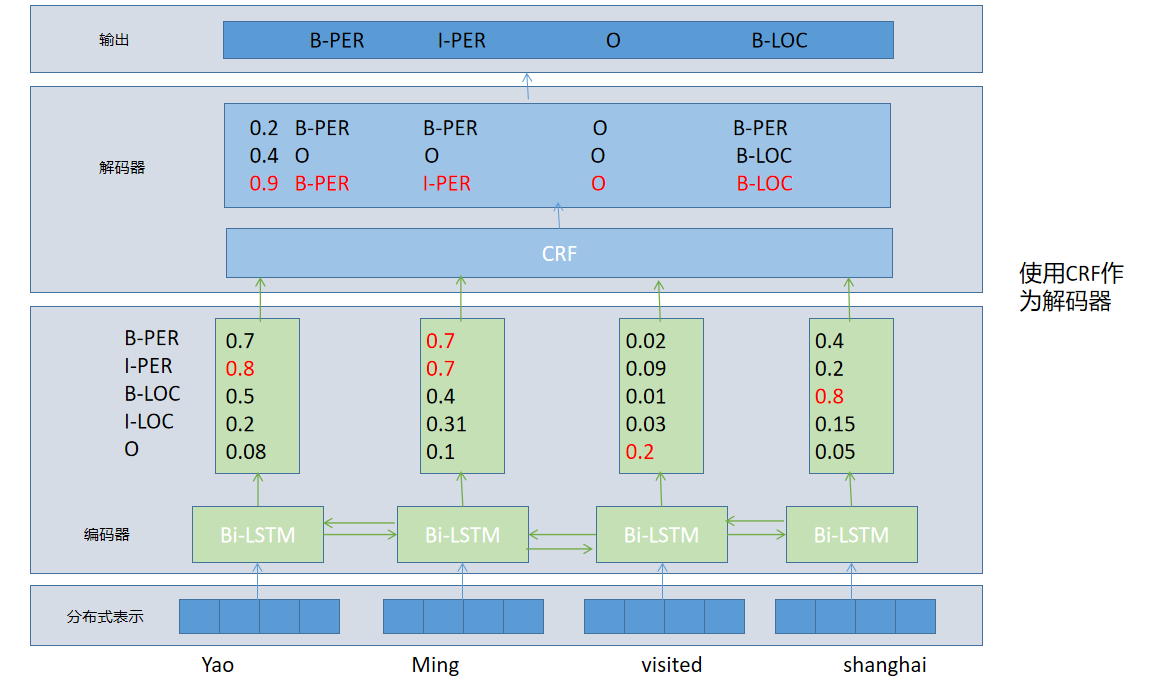
全连接层+softmax:序列标注问题视为分类问题,独立的预测每个单词的标签
每个单词中间层向量表示-->全连接层-->产生标签分值向量Y=(y1,y2,....yi,.....)-->softmax层-->产生最终的标签概率分布
条件随机场(CRF):当前的预测标签不仅与当前的输入特征相关,还与前序输出的标签相关。
(3)循环神经网络(RNN)
posted on 2020-01-14 14:40 happygril3 阅读(2866) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号