We prompt Gemini-1.5 Pro to first generate a cognitive map based on the given video and question, and then to use the predicted map to answer the question.
Visual CoT
《Visual CoT: Advancing Multi-Modal Language Models with a Comprehensive Dataset and Benchmark for Chain-of-Thought Reasoning》
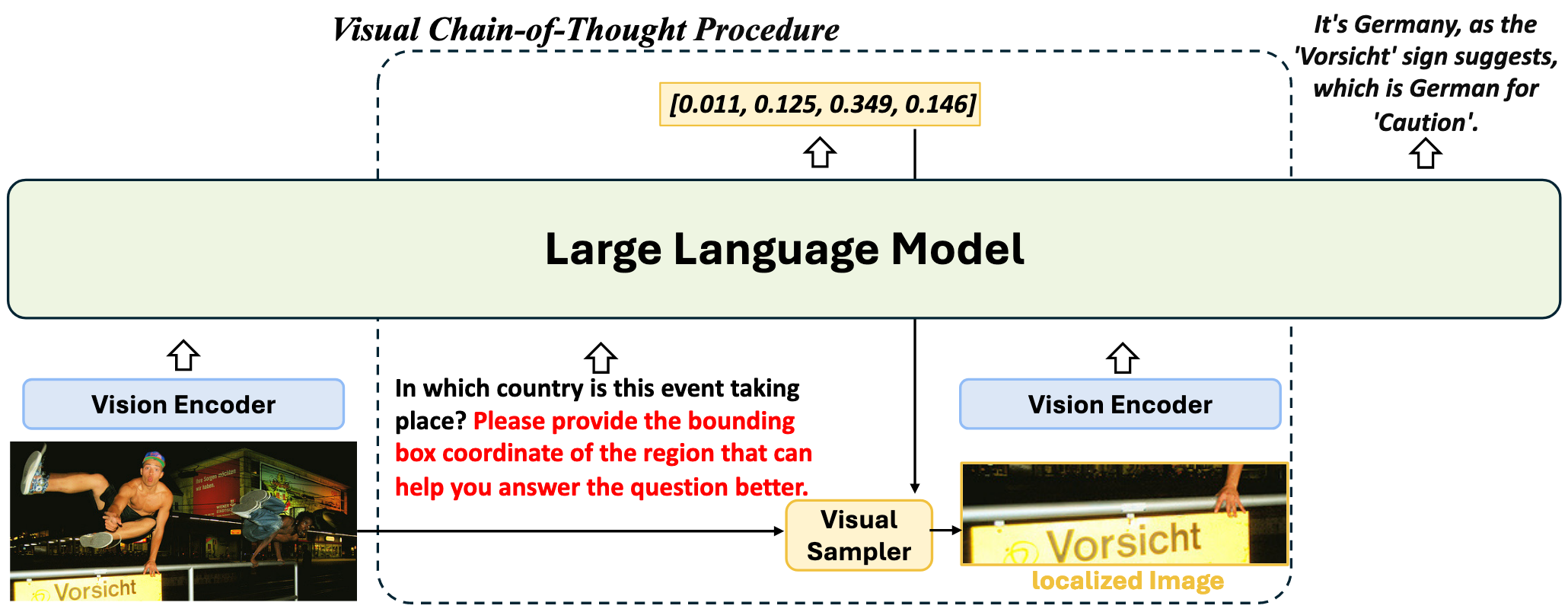
they often lack interpretability and struggle with complex visual inputs, especially when the resolution of the input image is high or when the interested region that could provide key information for answering the question is small. To address these challenges, we collect and introduce the large-scale Visual CoT dataset comprising 438k question-answer pairs, annotated with intermediate bounding boxes highlighting key regions essential for answering the questions.
制作了一个438K大小的数据集,包含:
question
answer
Cot-BBox
其中98K数据包含下图所示的步骤指引:
对于包含CoT BBox的训练数据,训练时在问题后面附加"Please provide the bounding box coordinate of the region that can help you answer the question better.",同时根据该问题的真值抠出对应图像区域,将其编码后的特征和完整图像编码后的特征统一送入模型。
训练分为两个阶段:
在图片字幕数据上仅训练projector;
在visual-cot数据集上微调全部模型;
Visual Encoder
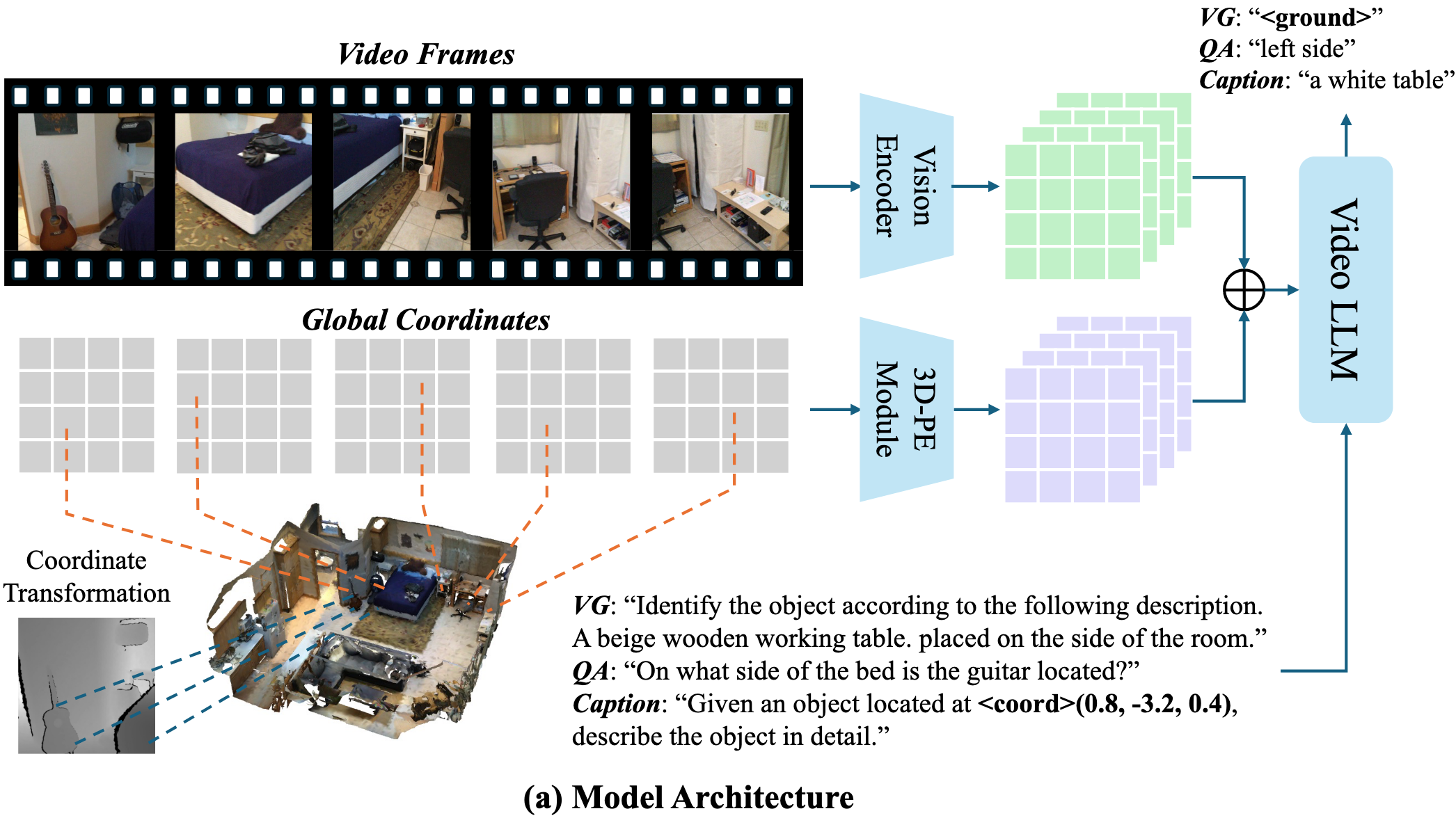
Video-3D LLM
《Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding》
By treating 3D scenes as dynamic videos and incorporating 3D position encoding into these representations, our Video-3D LLM aligns video representations with real-world spatial contexts more accurately.









 浙公网安备 33010602011771号
浙公网安备 33010602011771号