
【工具包使用】xml文件解析
前言
数据集简介
这个数据集是从网络上爬取的,图像尺寸相差较大,小的80*90,大的3000*4300,异质性较大,解析之后训练效果非常差;
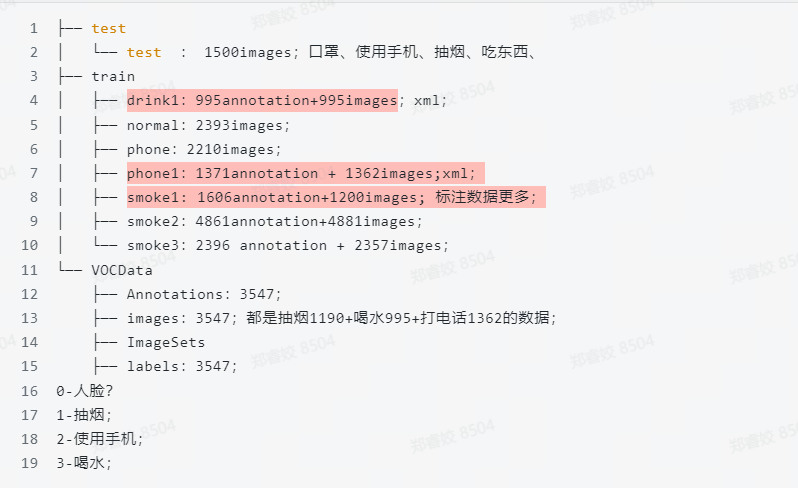
数据集解析


# 20231019: driver behavior. # classid: 0-phone, 1-smoke, 2-drink. import csv import xml.etree.ElementTree as ET import cv2 as cv import os # from PIL import Image, ImageDraw, ImageFont def parse_xml(filepath, filename): """解析xml""" tree = ET.parse(os.path.join(filepath, filename)) # 解析读取xml函数 objects = [] imgname = [] coordinate = [] for xml_name in tree.findall('filename'): # print('xml_name: ', xml_name) # print('xml_name.text: ', xml_name.text) # img_path = os.path.join(pic_path, xml_name.text) # xml_name.text = '6771.jpg' if xml_name.text.split(".")[-1] == "png": xml_name.text = xml_name.text.replace('png','jpg') # print('xml_name.text: ', xml_name.text) imgname.append(xml_name.text) for obj in tree.findall('object'): obj_struct = {'name': obj.find('name').text, 'pose': obj.find('pose').text, 'truncated': int(obj.find('truncated').text), 'difficult': int(obj.find('difficult').text)} bbox = obj.find('bndbox') obj_struct['bbox'] = [int(bbox.find('xmin').text), int(bbox.find('ymin').text), int(bbox.find('xmax').text), int(bbox.find('ymax').text)] objects.append(obj_struct) for obj_one in objects: xmin = int(obj_one['bbox'][0]) ymin = int(obj_one['bbox'][1]) xmax = int(obj_one['bbox'][2]) ymax = int(obj_one['bbox'][3]) label = obj_one['name'] if label == 'face': continue coordinate.append([xmin,ymin,xmax,ymax,label]) if len(coordinate) < 1: # remove bad data print("imgname: ", imgname) return coordinate, imgname def get_bbox(size, box): # Convert xyxy box to YOLOv5 xywh box dw = 1. / size[0] dh = 1. / size[1] xc = (box[0] + box[2])*0.5*dw yc = (box[1] + box[3])*0.5*dh w = (box[2]-box[0])*dw h = (box[3]-box[1])*dh return xc, yc, w, h def xml2coco(path): xmldir = os.path.join(path, 'badbehavior', 'Annotations') imgdir = os.path.join(path, 'badbehavior', 'images') labeldir = os.path.join(path, 'badbehavior', 'label') # classid: 0-phone, 1-smoke, 2-drink. for xmlname in os.listdir(xmldir): labelname = os.path.join(labeldir, xmlname.replace('xml', 'txt')) labelfile = open(labelname, 'w+') tree = ET.parse(os.path.join(xmldir, xmlname)) # 解析读取xml函数 size = tree.find('size') w = int(size.find('width').text) h = int(size.find('height').text) # print('w: ', w) # print('h: ', h) for obj in tree.findall('object'): obj_struct = {'name': obj.find('name').text, 'pose': obj.find('pose').text, 'truncated': int(obj.find('truncated').text), 'difficult': int(obj.find('difficult').text)} bbox = obj.find('bndbox') obj_struct['bbox'] = [int(bbox.find('xmin').text), int(bbox.find('ymin').text), int(bbox.find('xmax').text), int(bbox.find('ymax').text)] xywh = get_bbox((w,h), obj_struct['bbox']) # print('xywh: ', xywh) if obj_struct['name'] == 'phone': classid = 0 elif obj_struct['name'] == 'smoke': classid = 1 elif obj_struct['name'] == 'drink': classid = 2 else: continue info = f"{classid} {' '.join(f'{x:.6f}' for x in xywh)}\n" # print('info: ', info) labelfile.write(info) labelfile.close() def vis_xml(objects, imgdir, imgname): """可视化""" plotdir = os.path.join(path, 'driver_behavior', 'VOCData', 'plot') for _, filename in enumerate(imgname): imgpath = os.path.join(imgdir, filename) img = cv.imread(imgpath) for obj in objects: xmin = obj[0] ymin = obj[1] xmax = obj[2] ymax = obj[3] label = obj[4] cv.rectangle(img, (xmin,ymin), (xmax, ymax), (0, 255, 213), 3) cv.putText(img, label, (xmin, ymin), cv.FONT_HERSHEY_SIMPLEX, 2, (225, 18, 255), 1, cv.LINE_AA) cv.imshow('vis', img) if cv.waitKey(1) == 27: print('27') aa = os.path.join(plotdir, filename) print('aa: ', aa) cv.imwrite(aa, img) def behavior_show(path): xmldir = os.path.join(path, 'driver_behavior', 'VOCData', 'Annotations') imgdir = os.path.join(path, 'driver_behavior', 'VOCData', 'images') k = 0 for xmlname in os.listdir(xmldir): # xmlname = '6771.xml' # print('xmlname: ', xmlname) # k = k + 1 # if (k>1): # break # parse xml objinfo, imgname = parse_xml(xmldir, xmlname) # vis xml vis_xml(objinfo, imgdir, imgname) def phone_csv_show(path): csvdir = os.path.join(path, 'phone') imgdir = os.path.join(path, 'phone', 'positive') plotdir = os.path.join(path, 'phone', 'plot') # os.mkdir(plotdir) csvfile = open(os.path.join(csvdir, 'labels.csv'), 'r') lines = csv.reader(csvfile) # print('len: ', type(lines)) # print('line0: ', lines[0]) next(lines) # [filename, width, height, xmin, ymin, xmax, ymax, class] # next(lines) # [filename, width, height, xmin, ymin, xmax, ymax, class] annos = [] for line in lines: annos.append(line) line = annos[0] prename = line[0] print('prename: ', prename) imgpath = os.path.join(imgdir, prename) img = cv.imread(imgpath) xmin = int(line[3]) ymin = int(line[4]) xmax = int(line[5]) ymax = int(line[6]) # print('xmin: ', type(xmin)) # print('ymin: ', type(ymin)) # print('xmax: ', type(xmax)) # print('ymax: ', type(ymax)) cv.rectangle(img, (xmin,ymin), (xmax, ymax), (0, 255, 213), 3) for k in range(1, len(annos)): line = annos[k] curname = line[0] print('curname: ', curname) xmin = int(line[3]) ymin = int(line[4]) xmax = int(line[5]) ymax = int(line[6]) if curname == prename: cv.rectangle(img, (xmin,ymin), (xmax, ymax), (0, 255, 213), 3) else: aa = os.path.join(plotdir, prename) print('aa: ', aa) cv.imwrite(aa, img) imgpath = os.path.join(imgdir, curname) img = cv.imread(imgpath) cv.rectangle(img, (xmin,ymin), (xmax, ymax), (0, 255, 213), 3) prename = curname cv.imshow('vis', img) if cv.waitKey(1) == 27: print('27') csvfile.close() def csv2coco(path): csvdir = os.path.join(path, 'badbehavior') imgdir = os.path.join(path, 'badbehavior', 'positive') csvfile = open(os.path.join(csvdir, 'labels.csv'), 'r') lines = csv.reader(csvfile) next(lines) # [filename, width, height, xmin, ymin, xmax, ymax, class] labeldir = os.path.join(path, 'badbehavior', 'label') # classid: 0-phone, 1-smoke, 2-drink. imgs = [] for imgname in os.listdir(imgdir): imgs.append(imgname) print('imgs len: ', len(imgs)) for line in lines: imgname = line[0] print('imgname: ', imgname) if line[0] not in imgs: print(f"{line[0]} is not in imgs.") else: # labelname = os.path.join(labeldir, imgname.replace('xml', 'txt')) labelname = os.path.join(labeldir, imgname.split('.')[0]+'.txt') labelfile = open(labelname, 'a+') w = int(line[1]) h = int(line[2]) xmin = int(line[3]) ymin = int(line[4]) xmax = int(line[5]) ymax = int(line[6]) bbox = [xmin, ymin, xmax, ymax] classid = 0 # phone xywh = get_bbox((w,h), bbox) info = f"{classid} {' '.join(f'{x:.6f}' for x in xywh)}\n" # print('info: ', info) labelfile.write(info) labelfile.close() if __name__ == "__main__": path = os.path.dirname(os.path.realpath(__file__)) # behavior_xml_show(path) # phone_csv_show(path) # xml2coco(path) csv2coco(path)
注意,删除标注数据少的,或者错误的;人脸目标不计算在内;然后将筛选好的数据集整合到一起;
参考
2. XML文件解析--Python_python 解析xml_牧子川的博客-CSDN博客;
完
各美其美,美美与共,不和他人作比较,不对他人有期待,不批判他人,不钻牛角尖。
心正意诚,做自己该做的事情,做自己喜欢做的事情,安静做一枚有思想的技术媛。
版权声明,转载请注明出处:https://www.cnblogs.com/happyamyhope/
心正意诚,做自己该做的事情,做自己喜欢做的事情,安静做一枚有思想的技术媛。
版权声明,转载请注明出处:https://www.cnblogs.com/happyamyhope/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号