
【CV数据集总结】face_landmark_dataset总结
前言
本文主要整理总结face landmark有关的数据集。
https://github.com/open-mmlab/mmpose/blob/main/docs/en/dataset_zoo/2d_face_keypoint.md
关键特征点的个数有5/15/68/98/106...
face detection
Face alignment
Face recognition
数据集
300W dataset
68个点,Indoor和Outdoor目录各300个人脸及其68个点的标注文件;
数据集下载
https://ibug.doc.ic.ac.uk/download/annotations/300w.zip.001
https://ibug.doc.ic.ac.uk/download/annotations/300w.zip.002
https://ibug.doc.ic.ac.uk/download/annotations/300w.zip.003
https://ibug.doc.ic.ac.uk/download/annotations/300w.zip.004
其他数据集下载链接
xm2vts: 只有2360个68点的标注文件
frgc:只有4950个68点的标注文件
https://ibug.doc.ic.ac.uk/download/annotations/frgc.zip
lfpw:
测试和训练集共有2070/2=1035张图像及其68个点标注文件;
https://ibug.doc.ic.ac.uk/download/annotations/lfpw.zip
helen:
测试和训练集共有4660/2=2330个人脸及其68个点标注文件;
https://ibug.doc.ic.ac.uk/download/annotations/helen.zip
AFW:
674/2=337个人脸及其68个点标注文件;
https://ibug.doc.ic.ac.uk/download/annotations/afw.zip
ibug:
270/2=135个人脸及其68个点标注文件;
https://ibug.doc.ic.ac.uk/download/annotations/ibug.zip
ibug_300W_large_face_landmark_dataset.tar.gz
数据集通过以下网站找到下载链接,通过链接下载的;
https://towardsdatascience.com/face-landmarks-detection-with-pytorch-4b4852f5e9c4
http://dlib.net/files/data/ibug_300W_large_face_landmark_dataset.tar.gz
这个数据集是SDM训练需要用到的,使用xml文件表示,下载的xml文件和原代码有些微差别,调试通过即可;
通过查看原数据,发现每张图像都进行了镜像处理,也就是一张图像包括2个数据对,一个是自身,一个是镜像;
数据集目录:
input/ibug_300W_large_face_landmark_dataset ├── afw ├── helen ├── ibug ├── image_metadata_stylesheet.xsl ├── labels_ibug_300W_test.xml ├── labels_ibug_300W_train.xml ├── labels_ibug_300W.xml └── lfpw
xml文件格式:
<images>
<image file='helen/trainset/146827737_1.jpg' width='640' height='790'>
<box top='224' left='70' width='295' height='295'>
<part name='00' x='145' y='355'/>
<part name='01' x='144' y='382'/>
......
<part name='66' x='190' y='492'/>
<part name='67' x='180' y='487'/>
</box>
</image>
......
<images>
数据集解析代码


std::vector<std::string> split(const std::string& s, const std::string& delim) { std::vector<std::string> elems; size_t pos = 0; size_t len = s.length(); size_t delim_len = delim.length(); if (delim_len == 0) return elems; while (pos < len) { int find_pos = s.find(delim, pos); if (find_pos < 0) { elems.push_back(s.substr(pos, len - pos)); break; } elems.push_back(s.substr(pos, find_pos - pos)); pos = find_pos + delim_len; } return elems; } void ReadLabelsFromFile(std::vector<ImageLabel> &Imagelabels, std::string Path = "labels_ibug_300W_train.xml"){ std::string ParentPath(trainFilePath); std::ifstream LabelsFile(ParentPath+Path, std::ios::in); if(!LabelsFile.is_open()){ return; } std::string linestr; while(std::getline(LabelsFile, linestr)){ linestr = trim(linestr); linestr = replace(linestr, "</", ""); linestr = replace(linestr, "/>", ""); linestr = replace(linestr, "<", ""); linestr = replace(linestr, ">", ""); linestr = replace(linestr, "'", ""); std::vector<std::string> strNodes = split(linestr, " "); if(!strNodes.size()) { std::cout << "line is NULL" << std::endl; continue;} static ImageLabel* mImageLabel = NULL; switch (strNodes.size()) { case 1: if(strNodes[0] == "image"){ Imagelabels.push_back(*mImageLabel); delete mImageLabel; } break; case 4: if(strNodes[0] == "image"){ mImageLabel = new ImageLabel(); mImageLabel->imagePath = ParentPath + split(strNodes[1], "=")[1]; }else if(strNodes[0] == "part"){ int index = atoi(split(strNodes[1], "=")[1].data()); mImageLabel->landmarkPos[index] = atoi(split(strNodes[2], "=")[1].data()); mImageLabel->landmarkPos[index+LandmarkPointsNum] = atoi(split(strNodes[3], "=")[1].data()); } break; case 5: if(strNodes[0] == "box"){ mImageLabel->faceBox[0] = atoi(split(strNodes[1], "=")[1].data()); // top mImageLabel->faceBox[1] = atoi(split(strNodes[2], "=")[1].data()); // left mImageLabel->faceBox[2] = atoi(split(strNodes[3], "=")[1].data()); // width mImageLabel->faceBox[3] = atoi(split(strNodes[4], "=")[1].data()); // height } break; default: break; } } LabelsFile.close(); }
解析完成之后,训练集有6666张图像,测试集1008张图像;
WFLW dataset
这是由商汤提供的,98个关键点,还包括occlusion, position, make-up, lighting, blur, and expression等人脸属性;训练集7500images(list_98pt_rect_attr_train.txt),测试集2500images(list_98pt_rect_attr_test.txt);
标签格式:196+4+6+1=207;
coordinates of 98 landmarks (196) + coordinates of upper left corner and lower right corner of detection rectangle (4) + attributes annotations (6) + image name (1) x0 y0 ... x97 y97 x_min_rect y_min_rect x_max_rect y_max_rect pose expression illumination make-up occlusion blur image_name
标注图像

为什么出现两个wflw_annotations.tar文件呢?
Lapa dataset
AAAI2020,京东AI-CV研究团队-LaPa-Dataset。
公开22,000多张人脸图像数据集,在表情、姿势和遮挡方面有着丰富的变化,每张LaPa图像都提供了11类像素级标签图和106点特征点,主要用于人脸解析。
LaPa数据集test2000+train18168+val2000,其中labels是像素级标签图,landmarks是106点landmarks标签;能够有效帮助降低在大姿态测试集上的loss;
LaPa简介
- 京东训练hourglassnet作为半自动人脸标注工具;
- 人工后期调整少量的难例样本;
数据集组成
- 提供原始图像、像素级标签图以及106点landmark标签;
- landmark顺序需要自行调整,没有给出具体对应的脸部位置(可视化);
- 像素级标签用于人脸解析,文章里在公开此数据集之外,还用此数据集进行人脸的语义分割和解析模型,因此处与日常工作无关,感兴趣的同学可以自行阅读人脸解析算法部分;
数据集目录
./LaPa
├── test
│ ├── images
│ ├── labels
│ └── landmarks
├── train
│ ├── images
│ ├── labels
│ └── landmarks
└── val
├── images
├── labels
└── landmarks
数据集样例

数据集LaPa解析为人脸bbox的yolov5 coco格式的label文件
# 20240710: parse lapa dataset to coco format bbox for face detection. import os import cv2 as cv import random import shutil percent = 0.8 lapapath = "/media/xxx/485E234682AE9EFD/01_dataset/facelandmarks_dataset/lapa/LaPa" def get_bbox(size, box): # Convert xyxy box to YOLOv5 xywh box dw = 1. / size[0] dh = 1. / size[1] xc = (box[0] + box[2])*0.5*dw yc = (box[1] + box[3])*0.5*dh w = (box[2]-box[0])*dw h = (box[3]-box[1])*dh return xc, yc, w, h def parse_pts(ptsfile): lines = open(ptsfile, 'r').readlines() # print(f'lines len: {len(lines)}, lines[0]: {lines[0]}, lines[1]: {lines[1]}') ptsn = int(lines[0]) pstr = lines[1].split(' ') pt = [int(i.split('.')[0]) for i in pstr] xmin = pt[0] ymin = pt[1] xmax = pt[0] ymax = pt[1] k = 0 for line in lines[2:]: # k = k + 1 pstr = line.split(' ') pt = [int(i.split('.')[0]) for i in pstr] # print(f'k={k}, pt: {pt}') xmin = min(xmin, pt[0]) ymin = min(ymin, pt[1]) xmax = max(xmax, pt[0]) ymax = max(ymax, pt[1]) return xmin, ymin, xmax, ymax def lapa2coco(path): for sub in ['test', 'train', 'val']: imgpath = os.path.join(lapapath, sub, 'images') ldmpath = os.path.join(lapapath, sub, 'landmarks') labelpath = os.path.join(path, 'ccpd_lapa/label') imagepath = os.path.join(path, 'ccpd_lapa/image') files = os.listdir(imgpath) random.shuffle(files) num = len(files) print('files: ', len(files)) i = 0 for filename in files: # if i > 1: # num*percent: if i > num*percent: break i = i + 1 # copy image oldpath = os.path.join(imgpath, filename) newpath = os.path.join(imagepath, filename) shutil.copyfile(oldpath, newpath) # label ldmfile = os.path.join(ldmpath, filename.replace('jpg', 'txt')) xyxy = parse_pts(ldmfile) # [xmin ymin xmax ymax] labelname = os.path.join(labelpath, filename.replace('jpg', 'txt')) image = cv.imread(oldpath) imgh, imgw = image.shape[:2] bbox = get_bbox((imgw, imgh), xyxy) # [xc yc w h] classid = 0 # face info = f"{classid} {' '.join(f'{x:.6f}' for x in bbox)}\n" labelfile = open(labelname, 'w+') labelfile.write(info) labelfile.close() if __name__ == "__main__": rootpath = os.path.dirname(os.path.realpath(__file__)) lapa2coco(rootpath)
JD-landmark
https://sites.google.com/view/hailin-shi
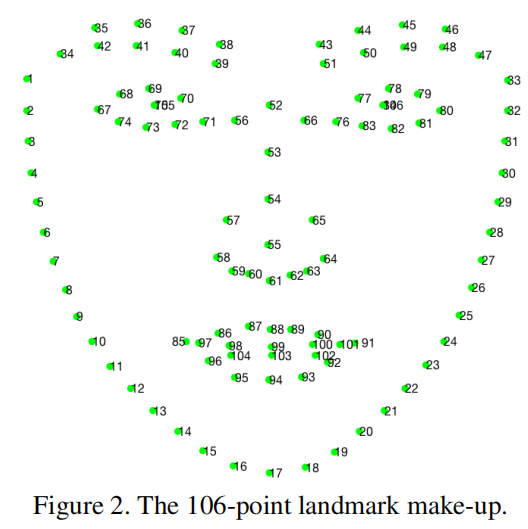
106个关键特征点;
需要注意的是每个图仅仅标注了一张人脸关键点。需要注意的坑是其中#75和#105重合,#84和#106重合。
合并WFLW和JD-landmark两个数据集为98关键点数据集,去除JD-landmark中56/66/57/65/58/64/75/84点。
合并后数据集链接: https://pan.baidu.com/s/179crM6svNbK3w28Z0ycBHg 提取码: 7guh
JD_WFLW_Landmarks数据集解析为人脸bbox的yolov5 coco格式的label文件
# 20240710: parse jd_wflw dataset to coco format bbox for face detection. import os import cv2 as cv import random import shutil jdwflwpath = "/media/xxx/485E234682AE9EFD/01_dataset/facelandmarks_dataset/JD_WFLW_Landmarks" percent = 0.75 def get_bbox(size, box): # Convert xyxy box to YOLOv5 xywh box dw = 1. / size[0] dh = 1. / size[1] xc = (box[0] + box[2])*0.5*dw yc = (box[1] + box[3])*0.5*dh w = (box[2]-box[0])*dw h = (box[3]-box[1])*dh return xc, yc, w, h def jdwflw2coco(path): labelpath = os.path.join(path, 'face/label') lines = open(os.path.join(jdwflwpath, 'labels.txt'), 'r').readlines() print('lines len: ', len(lines)) random.shuffle(lines) num = len(lines) n = 0 for one in lines: if n > num * percent: break n = n + 1 line = one.strip().split() imgname = line[0] print(f'imgname: {imgname}, line len: {len(line)}') kp = line[1:197] kp = [int(i.split('.')[0]) for i in kp] box = line[197:201] box = [int(i) for i in box] # cv2.rectangle(image, (box[0], box[1]), (box[2], box[3]), (0,255, 255), 4) minx = kp[0] miny = kp[1] maxx = kp[0] maxy = kp[1] for i in range(0,98): # cv2.circle(image, (kp[2*i], kp[2*i+1]), 2, (0, 0, 255), 4) minx = min(minx, kp[2*i]) miny = min(miny, kp[2*i+1]) maxx = max(maxx, kp[2*i]) maxy = max(maxy, kp[2*i+1]) # print(f'minx={minx}, miny={miny}, maxx={maxx}, maxy={maxy}') # cv2.rectangle(image, (minx, miny), (maxx, maxy), (255, 0, 255), 4) oldpath = os.path.join(jdwflwpath, 'images', imgname) newpath = os.path.join(path, 'face/image', imgname) shutil.copyfile(oldpath, newpath) image = cv.imread(os.path.join(jdwflwpath, 'images', imgname)) imgh, imgw = image.shape[:2] bbox = get_bbox((imgw, imgh), (minx, miny, maxx, maxy)) classid = 0 # face info = f"{classid} {' '.join(f'{x:.6f}' for x in bbox)}\n" labelname = os.path.join(labelpath, imgname.replace('jpg', 'txt')) labelfile = open(labelname, 'w+') labelfile.write(info) labelfile.close() if __name__ == "__main__": rootpath = os.path.dirname(os.path.realpath(__file__)) jdwflw2coco(rootpath)
Kaggle dataset
Facial Keypoints Detection 4+15points;
P1_Facial_Keypoints
数据集在P1_Facial_Keypoints repo, in the subdirectory
data;landmarks以csv文件存储,每行内容是imgname+68*2共137列数据,也是68个关键点;
https://aistudio.baidu.com/aistudio/projectdetail/1487972
分析总结
68个关键点的数据集:
300w(600) / lfpw(1035) / helen(2330) / AFW(337) / ibug(135);
600+1035+2330+337+135=4437;
300w_name,包含indoor和outdoor;
lfpw_train/test_name,训练集和测试集的名字重名,需要区分开,直接使用train/test或者0/1指定;
helen,train/test数据集,应该没有重名的,可以直接使用,需要验证注意,因为名字没有规律;
afw,与helen相似,不知道二者有没有重复的;
ibug,有规律,但是不知道会不会和lfpw重复;
故,最好都加上原数据集的名称,然后组成新的数据集,再分割train/valid;
gen68kp.sh
#!/bin/sh ''' generate 68 keypoints face landmark dataset from 300w/lfpw/helen/afw/ibug dataset. 300w 01_Indoor/02_Outdoor 300w_name lfpw trainset/testset lfpw0/1_name helen trainset/testset helen_name afw afw_name ibug ibug_name ''' script_path="$(pwd)" kp68path="$script_path/68kp" # 300w for file in $script_path/300w/300w/01_Indoor/*; do echo $file base=$(basename $file) newfile=$kp68path/"300w_"$base cp $file $newfile done for file in $script_path/300w/300w/02_Outdoor/*; do echo $file base=$(basename $file) newfile=$kp68path/"300w_"$base cp $file $newfile done # lfpw for file in $script_path/lfpw/trainset/*; do echo $file base=$(basename $file) newfile=$kp68path/"lfpw0_"$base cp $file $newfile done for file in $script_path/lfpw/testset/*; do echo $file base=$(basename $file) newfile=$kp68path/"lfpw1_"$base cp $file $newfile done # helen/afw/ibug # jpg ---> png for file in $kp68path/*.jpg; do # for file in $script_path/aaa/*jpg; do pngname=${file%.jpg}.png # convert "$file" "${file%.jpg}.png" ffmpeg -pix_fmt rgb24 -i $file -pix_fmt rgb24 $pngname rm $file done # split dataset to train/valid with png/pts. ''' .dataset68 ├── train │ ├── png │ └── pts └── valid ├── png └── pts ''' dataset_path="$script_path/dataset68" cd $script_path find $script_path/68kp/ -name "*.png" > $script_path/image.txt rm -r $dataset_path mkdir $dataset_path cd $dataset_path mkdir train valid cd train mkdir png pts cd ../valid mkdir png pts cd $script_path python genpath.py # 分割数据集
98个关键点的数据集:
wflw(10000) / JD-landmarks-98(unavaiable?)
合并WFLW和JD-landmark两个数据集为98关键点数据集,去除JD-landmark中56/66/57/65/58/64/75/84点。
二者合并之后的数据集,合并后数据集链接: https://pan.baidu.com/s/179crM6svNbK3w28Z0ycBHg 提取码: 7guh
共有25393个数据图像,也就是JD-landmarks-98数据集共有15393个数据;
106个关键点的数据集:
JD-landmark(?) / Lapa(22000)
可以先使用68个点的进行训练,后续再训练98/106的,需要预处理数据集;
参考
- Face 2D Keypoint ‒ MMPose 1.1.0 documentation;
- mmlab_2d_face_keypoint;
- Look at Boundary: A Boundary-Aware Face Alignment Algorithm;
- GitHub - lucia123/lapa-dataset: A large-scale dataset for face parsing (AAAI2020);
- GitHub - JDAI-CV/lapa-dataset: A large-scale dataset for face parsing (AAAI2020) ;
- Grand Challenge of 106-p Facial Landmark Localization;
- Facial Keypoints Detection;
完
各美其美,美美与共,不和他人作比较,不对他人有期待,不批判他人,不钻牛角尖。
心正意诚,做自己该做的事情,做自己喜欢做的事情,安静做一枚有思想的技术媛。
版权声明,转载请注明出处:https://www.cnblogs.com/happyamyhope/
心正意诚,做自己该做的事情,做自己喜欢做的事情,安静做一枚有思想的技术媛。
版权声明,转载请注明出处:https://www.cnblogs.com/happyamyhope/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号