分布式哈希算法
一,普通的Hash方式
在介绍分布式哈希算法之前,先了解下普通的Hash是如何实现的。JDK中的java.util.HashMap类就实现了一个哈希表,它的特点有:①创建哈希表(HashMap)需要先指定大小,即默认创建一个能够存储多少个元素的哈希表,它的默认大小为16。
②当不断地向HashMap中添加元素时,HashMap越来越满,当添加的元素达到了装载因子乘以表长时,就需要扩容了。扩容时,原来已经映射到哈希表中的某个位置(桶)的元素需要重新再哈希,然后再把原来的数据复制到新的哈希表中。
对于普通的哈希表而言,扩容的代价是很大的。因为普通的Hash计算地址方式如下:Hash(Key)%M,为了演示方便,举个极端的例子如下:
假设哈希函数为 hash(x)=x ,哈希表的长度为5(有5个桶)
key=6时,hash(6)%5 = 1,即Key为6的元素存储在第一个桶中
key=7时,hash(7)%5 = 2,即Key为7的元素存储在第二个桶中
Key=13时,hash(13)%5=3,即Key为13的元素存储在第三个桶中....
假设现在hash表长度扩容成8,那么Key为6,7,13 的数据全都需要重新哈希。因为,
key=6时,hash(6)%8 = 6,即Key为6的元素存储在第六个桶中
key=7时,hash(7)%8 = 7,即Key为7的元素存储在第七个桶中
Key=13时,hash(13)%8=5,即key为13的元素存储在第五个桶中....
从上可以看出:扩容之后,元素的位置全变了。比如:Key为6的元素原来存储在第一个桶中,扩容之后需要存储到第6个桶中。
因此,这是普通哈希的一个不足:扩容可能会影响到所有元素的移动。这也是为什么:为了减少扩容时元素的移动,总是将哈希表扩容成原来大小的两倍的原因。因为,有数学证明,扩容成两倍大小,使得再哈希(rehash)的元素个数最少。
二,一致性哈希方式
在分布式系统中,节点的宕机、某个节点加入或者移出集群是常事。对于分布式存储而言,假设存储集群中有10台机子,如果采用Hash方式对数据分片(即将数据根据哈希函数映射到某台机器上存储),哈希函数应该是这样的:hash(file) % 10。根据上面的介绍,扩容是非常不利的,如果要添加一台机器,很多已经存储到机器上的文件都需要重新分配移动,如果文件很大,这种移动就造成网络的负载。
因此,就出现了一种一致性哈希的方式。关于一致性哈希,可参考:一致性哈希算法学习及JAVA代码实现分析
一致性哈希,其实就是把哈希函数可映射的空间(相当于普通哈希中桶的数目是固定的)固定下来了,比如固定为: 2n-1,并组织成环的形状
每个机器对应着一个n位的ID,并且映射到环中。每个查询键,也是一个 n 位的ID,节点的ID和查询键对应着相同的映射空间。
Each node choose a n-bit ID
Intention is that they be random Though probably a hash of some fixed info IDs are arranged in a ring
Each lookup key is also a n-bit ID
I.e., the hash of the real lookup key
Node IDs and keys occupy the same space!
如下图:有四台机器映射到固定大小为2n-1的哈希环中。四台机器一共将整个环分成了四部分:(A,B)、 (B,C)、 (C,D)、 (D,A)

机器A负责存储落在(D,A)范围内的数据,机器B负责存储落在(A,B)范围内的数据.....
也就是说,对数据进行Hash时,数据的地址会落在环上的某个点上,数据就存储 该点的 顺时针方向上的那台机器上。
相比于普通哈希方式,一致性哈希的好处就是:当添加新机器或者删除机器时,不会影响到全部数据的存储,而只是影响到这台机器上所存储的数据(落在这台机器所负责的环上的数据)。
比如,B机器被移除了,那落在(A,B)范围内的数据 全部需要由 C机器来存储,也就只影响到落在(A,B)这个范围内的数据。
同时,扩容也很方便,比如在(C,D)这段环上再添加一台机器E,只需要将D上的一部分数据拷贝到机器E上即可。
那一致性哈希有没有缺点呢?当然是有的。总结一下就是:没有考虑到每台机器的异构性质,不能实现很好的负载均衡。
举个例子:机器C的配置很高,性能很好,而机器D的配置很低。但是,可能 现实中 大部分数据由于某些特征 都哈希到(C,D)这段环上,直接就导致了机器D的存储压力很大。
另外,一致性哈希还存在“热点”问题(hotspot)。
比如说,由于机器D上存储了大量的数据,为了缓解下机器D的压力,在 环(C,D)段再添加一台机器E,就需要将机器D上的一部分数据拷贝到机器E上。而且只有一台机器:即机器D参与拷贝,这会引起机器D 与 机器 E之间的网络负载突然增大。机器D,就是我们所说的hotspot。
三,引入虚拟节点的一致性哈希方式
为了解决一致性哈希的一些不足,又引入了虚拟节点的概念。
引入虚拟节点,可以有效地防止物理节点(机器)映射到哈希环中出现不均匀的情况。比如上图中的机器A、B、C都映射在环的右半边上。
一般,虚拟节点会比物理节点多很多,并可均衡分布在环上,从而可以提高负载均衡的能力。如下图:
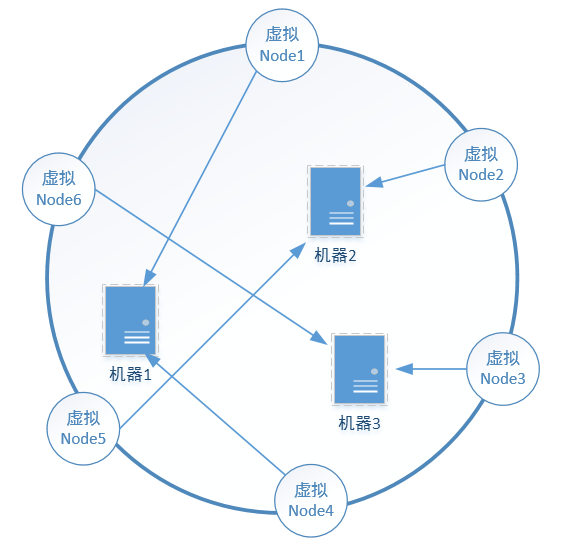
①如果虚拟机器与物理机器映射得好,某一台物理机器宕机后,其上的数据可由其他若干台物理机器共同分担。
②如果新添加一台机器,它可以对应多个不相邻 环段 上的虚拟节点,从而使得hash的数据存储得更分散。
四,分布式哈希的查询过程
当某台机器接受到查询请求时,先待查找的数据是否在本地,如果不在本地,则将查询请求转发到顺时针方向的下一个节点上。

比如,机器N10,接受Client的查询“谁有Key80?对应的数据?”,由于Key80对应的数据存储在 机器N90 上,故故需要沿着顺时针转发:N10-->N32-->N60-->N80
这种查询方式最坏情况下,查询的时间复杂度为O(N)
为了提高查询效率,需要在每台机器上维护一些路由信息:即哪些Key存储在哪些节点上。比如,若机器N10上存储着“Key80的数据在机器N90上”(<key80, N90>)这样的路由信息,那机器N10立即就能把查询请求转发给机器N90,从而不需要顺时针转发了。
那实际系统中的路由信息是如何维护的呢?Chord中实现的查询算法大致如下:
A node’s finger table contains the IP address of a node halfway around the ID space from it, a quarter-of-the-way , and so forth in powers of two.
A node forwards a query for key k to the node in its finger table with the highest ID less than k.
The power-of-two structure of the finger table ensures that the node can always forward the query at least half of the remaining ID-space distance to k.
As a result Chord lookups use O(log N ) messages.
在Chord中,用到一个叫做“Finger Table”的机制:Entry i in the finger table of node n is the first node that succeeds or equals n + 2i
机器1的id就是1,机器2的id就是2,机器6的id就是6。succ表示下一台机器所在的地址。比如机器1上的路由表如下:
i id+2i succ
0 1+2^0=2 2
1 1+2^1=3 6
2 1+2^2=5 6
它指出了 items 为2,3,5 所对应的数据分别在 机器2、机器6、机器6上。
这里解释下它的查询方式如下:
机器1本地存储着 items为1的数据;机器2本地存储着 items为2的数据;机器6本地存储着 items为3,4,5,6的数据;机器0本地存储着items为7,0 的数据。
与此同时,机器1上,还存储着items 为2,3,5 的数据 所在的机器地址。比如,机器1知道,items为5的数据存储在机器6上面。
比如,当机器1接收到 查询 items为7的数据在哪台机器上时,它发现 items=7 比它的路由表中的最大的items5还大,于是将查询请求转发到 items=5所对应的机器6上。
机器6上的路由表指出:items=7的数据在机器0上,于是就找到了items=7的数据 在机器0上了。
对于每步的查询而言,目标就是:尽可能地将查询key发送到离存储这个key最近的那台机器上。比如,上面的机器1接收到 key 为 items7 的查询,机器1上存储着 key为 2,3,5的数据,但是由于items 7 比items 2,3,5都要大,因此它判断出存储 items=5 的那台机器 距离 存储items=7的机器 更近,故把查询请求转发给 items=5 所在的那台机器(机器6)

通过在每台机器上保存路由信息,上面的方式可以做到O(logN)的查询时间复杂度。关于其他实现的时间复杂度,可参考维基百科
另外,比如Amazon Dynamo论文中所说的:Dynamo通过在每台机子上保存足够多路由信息,从而做到O(1)时间的查询。
Dynamo can be characterized as a zero-hop DHT,where each node maintains
enough routing information locally to route a request to the appropriate
node directly
五,参考资料:
https://en.wikipedia.org/wiki/Distributed_hash_table
Distributed Hash Table.pdf 15441 Spring 2004, Jeff Pang
原文:http://www.cnblogs.com/hapjin/p/5760463.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号