ElasticSearch中碰到的C10K问题
Elasticsearch基于Netty解决C10K问题背后的原理是JAVA NIO中的IO多路复用机制,涉及到三大"组件":SelectableChannel、Selector、SelectionKey。普通的"一请求一线程"方式,有一个线程负责accept请求,请求accepted后返回Channel,然后新建一个线程负责处理Channel上的IO事件。显然当请求量达到C10K时,就得创建10K个线程,这对于一台服务器是不可接受的。
ServerSocketChannel ssc = ServerSocketChannel.open( );
ssc.socket( ).bind (new InetSocketAddress (port));
ssc.configureBlocking (false);
while (true) {
System.out.println ("Waiting for connections");
SocketChannel sc = ssc.accept( );
if (sc == null) {
// no connections, snooze a while
Thread.sleep (2000);
}else{
Socket socket = sc.socket();// an accetped request
//一请求一线程方式:new Thread processing sc.socket()
//或者采用线程池方式:ExecutorService.execute(...) processing sc.socket()
}
}
这时候,有人就会提出:accepted连接之后,也可以不创建新线程,使用线程池来处理Channel上的IO事件。有一个线程负责accept请求,请求accepted后返回Channel,然后从线程池中取出一个线程负责处理Channel上的IO事件。这种方式只是当线程池中某个线程处理完Channel上的IO事件后,线程复用,又可以让它处理最新accepted的请求(这里不再new Thread了),但是当线程池中线程被耗尽(在10K的请求量下,线程池中有1w个线程吗?)时,此时也无能为力了。
这种模型表示如下:(参考网友的图:)
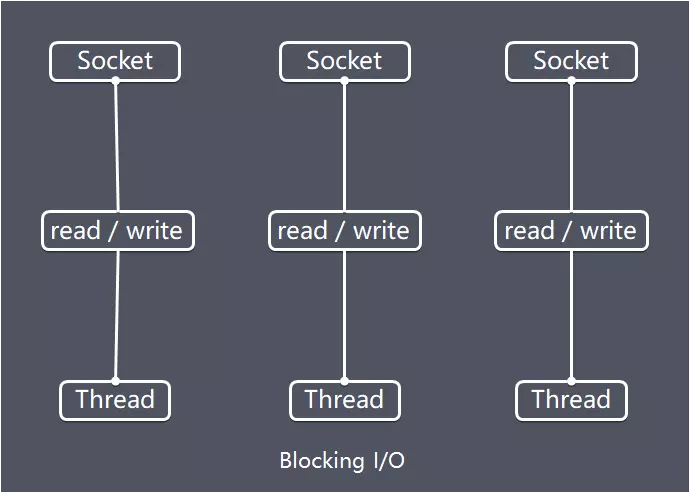
既然采用线程池并没有解决C10K问题,线程池中的线程数量也是有限的,当有大量的IO请求时,IO事件一般都伴随着阻塞操作,这些阻塞操作占用了一个线程,但因为IO阻塞,线程就会被挂起,此时CPU却很空闲。
而假设此时线程池中又没有空闲线程了(要么正在执行业务逻辑、要么IO阻塞操作挂起了),此时就会看到:服务器的CPU利用率并不高,但是却无法接受新的连接请求,这也是为什么在故障检查时发现CPU利用率并不高,但是日志中却有大量被拒绝的连接。
CPU处理的事件有两种类型:IO密集型、CPU密集型。假设CPU的核数为16核,针对IO密集型任务,线程池中的线程数量可以开到64个、128个...(当然不能无限制地达到几万个...),正是因为IO密集型任务有阻塞操作,多开线程可以增加任务处理数量,从而提高CPU的吞吐量和利用率。而对于CPU密集型任务,线程池中线程数量一般设置为17(CPU核数加1),因为CPU密集型任务,几乎不会阻塞,一直在占用CPU运行,这时线程池中创建大量线程反而会使CPU实际利用率(吞吐量)下降了,因为线程上下文切换消耗了大量系统资源。《JAVA并发编程实践》中提到了CPU核数与线程数量之间的关系。
继续分析,既然线程池的方式也不能解决C10K问题,这里候就轮到IO多路复用机制了。(这里引用了Netty中的EventLoopGroup)
原生 JAVA NIO处理、Netty处理的区别就是:Netty中把Channel上发生的IO事件的处理交给了EventLoopGroup来处理,EventLoopGroup实质是个ScheduledThreadPoolExecutor,它管理着若干EventLoop线程,EventLoop在各种文档/资料中有一个专业名称:I/O 事件线程。
这里提个问题:为什么Netty里面建议:不要使用EventLoopGroup处理IO阻塞操作,而是自己创建线程池,把IO阻塞操作代理给自己创建的线程池处理?
IO多路复用机制为什么能解决C10K问题?下面详细分析why?
当新请求到来时,有一个单独的线程负责accept请求,请求 accepted 后返回一个Channel,"使用"Selector在Channel上注册它感兴趣的事件,就是与前面2种方式的本质区别。这样,不管请求量有多大(C10K的请求量),Server 都能够将之accepted,然后仅仅只是在创建的Channel上注册了感兴趣的事件而已(真正的IO事件可能尚未发生)。
通过Selector轮询,检查哪个Channel上注册的事件发生了,如果事件发生了,才"开动"线程去处理(这个线程可以来自EventLoopGroup线程池,也可以是自己 new Thread ,也可以是自已 new 一个ThreadPool中的线程)。这就是IO多路复用机制原理。所以,真正解决C10K问题的原因是基于Selector的IO多路复用机制。
// Allocate an unbound server socket channel
ServerSocketChannel serverChannel = ServerSocketChannel.open( );
// Get the associated ServerSocket to bind it with
ServerSocket serverSocket = serverChannel.socket( );
// Create a new Selector for use below
Selector selector = Selector.open( );
// Set the port the server channel will listen to
serverSocket.bind (new InetSocketAddress (port));
// Set nonblocking mode for the listening socket
serverChannel.configureBlocking (false);
// Register the ServerSocketChannel with the Selector
serverChannel.register (selector, SelectionKey.OP_ACCEPT);
while (true) {
// This may block for a long time. Upon returning, the selected set contains keys of the ready channels.
int n = selector.select();
if (n == 0) {
continue; // nothing to do
}
// Get an iterator over the set of selected keys
Iterator it = selector.selectedKeys().iterator( );
// Look at each key in the selected set
while (it.hasNext( )) {
SelectionKey key = (SelectionKey) it.next( );
// Is a new connection coming in?
if (key.isAcceptable( )) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel channel = server.accept();
registerChannel (selector, channel,SelectionKey.OP_READ);
sayHello (channel);
}
// Is there data to read on this channel?
if (key.isReadable( )) {
readDataFromSocket (key);
}
//.....
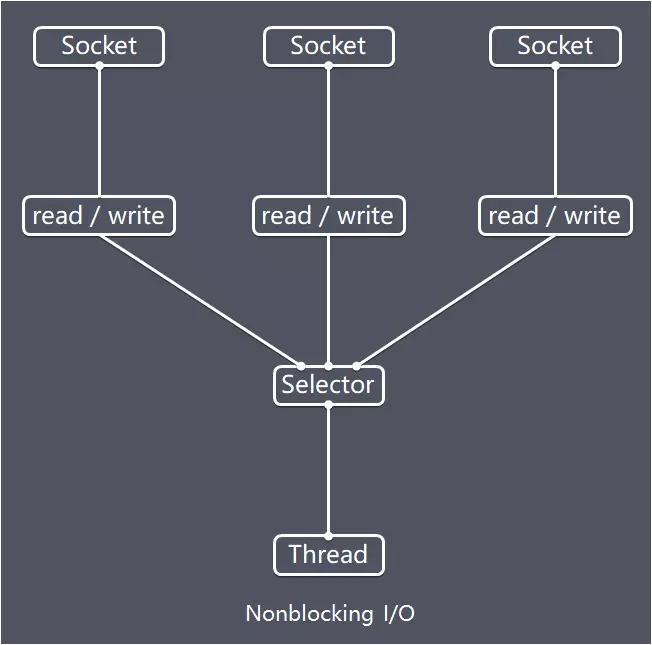
在IO多路复用机制下,Server accepted 连接后返回一个Channel,并在Channel上注册感兴趣的事件(比如读操作对应着读事件)。在实际TCP连接中,建立了连接并不代表就立即发送数据了,IO多路复用基于Selector轮询(epoll),只有当数据发送过来了,底层OS把事件"通知"给Selector,数据就绪后,才"开动"EventLoopGroup中的EventLoop线程去处理数据。(readiness selection),这样Server处理C10K的连接就成为可能了。如下图:每个Socket(Channel)上的相应的事件都注册到Selector,然后有一个线程轮询Selector selector.select(),当某个Socket上的事件发生了时,再进行相应处理。
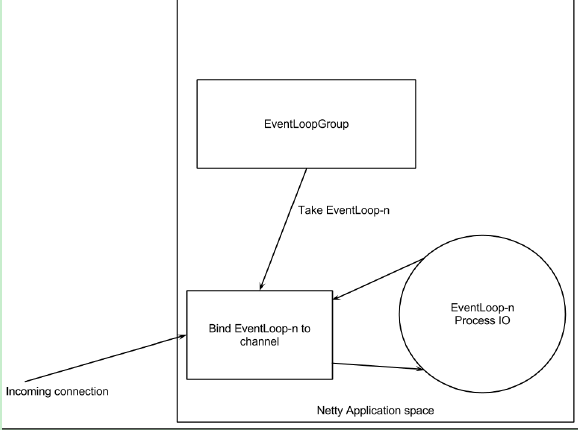
只是在原生的JAVA NIO下,我们需要自己编写代码如何处理每个就绪选择的事件。而基于Netty,已经帮我们封装好了这些处理逻辑,每个Channel上的事件直接交由EventLoopGroup处理,示例图如下:

在这里EventLoopGroup至关重要,因为已就绪的IO事件是交给它来处理的(take EventLoop-n and bind EventLoop-n to Channel),如果EventLoopGroup中的线程执行某种"阻塞"操作(EventLoop-n process IO),那就会影响能够处理已就绪的IO事件数量,进而影响Server能接受/处理多少连接。因此,可以自己再创建一个线程池,把阻塞操作交给该线程池执行,就能保证EventLoopGroup高效地处理已发生的IO事件而不发生阻塞。
实际应用
Kafka Borker处理Client的请求是基于Reactor模式
- acceptor 线程监听Client的连接请求。
- 请求建立后,生成SocketChanel(可理解为Client与Broker之间发消息通道),processor 线程将SocketChannel上的发生的"事件"放到一个请求队列中(queued.max.requests参数),processor 线程 就是 IO事件线程,而IO事件线程最好是不能阻塞的。
- KafkaRequestHandler线程池,这是真正的执行业务逻辑处理的线程。processor线程将 业务逻辑处理(如可能发生的IO阻塞操作)代理给KafkaRequestHandler线程池来处理。该线程池中线程数量由broker参数 num.io.threads指定。
个人理解,可能有错误。
参考资料:
- 一文理解Netty模型架构
- 《Java NIO》
- 《Netty in action》
- ElasticSearch6.3.2 Transport模块和ThreadPool模块的源码
- JAVA IO 以及 NIO 理解
- music of ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号