

Spark_总结一
1.Spark介绍
1.1什么是Spark?
Apache Spark是一个开源的集群计算框架,使数据计算更快(高效运行,快速开发)
1.2Spark比Hadoop快的两个原因
第一,内存计算
第二,DAG(有向无环图)
2.Spark运行模式(四种 )
| Local | 多用于测试 |
| Standalone | Spark自带的资源调度器(默认情况下就跑在这里面) |
| MeSOS | 资源调度器,同Hadoop中的YARN |
| YARN | 最具前景,公司里大部分都是 Spark on YRAN |
3.Spark内核之RDD的五大特性
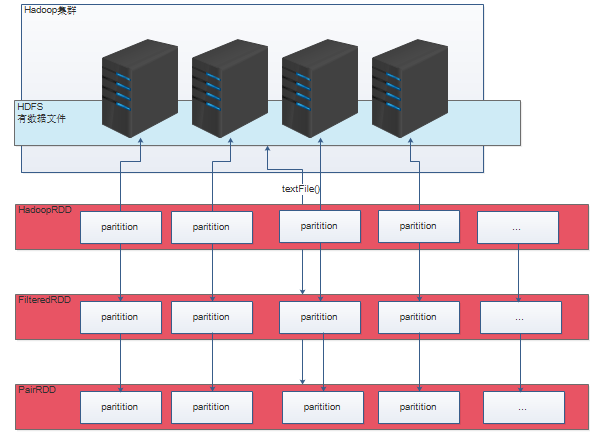
Resilient Distributed Dataset
RDD是基础-->弹性分布式数据集
第一大特性:RDD由一系列的partitions组成(如果数据源在HDFS上,默认partition的数量与block的个数一致,Spark并没有读取HDFS的方法,它是沿用MR的方法,MR读取HDFS上的数据时首先会进行split,RDD中每一个partition与split对应,split默认与block的大小一致,所以默认partition的数量与block的个数一致)
第二大特性:每一个函数实际上是作用在RDD中的每一个partition上
第三大特性:RDD是由一系列的依赖关系的(这里体现出了RDD的弹性,弹性一,数据容错;弹性二,partition可大可小)
第四大特性:partitioner(分区器)是作用在KV格式的RDD上(RDD执行聚合类函数的时候会产生shuffle,Spark产生shuffle肯定会有partitioner,而partitioner是作用在KV格式的RDD上,推测出聚合类函数必须作用在KV格式的RDD上)
第五大特性:每一个RDD提供了最佳的计算位置,告诉我们每一个partition所在的节点,然后相对应的task就会移动到该节点进行计算(移动计算,而不是移动数据)
4.Spark运行机制
开机启动时 Driver 、Worker、和 Application 会将自己的资源信息注册到 Master 中,当初始化的时候,Master 先为 Driver 分配资源然后启动 Driver。
Driver 运行时先从 main()方法开始,任务在 Worker 上执行,Worker 可以是一台真实的物理机,也可以是虚拟机,拥有 RAM 和 Core。然后会将 Task 移动到本地的数据上执行运算。最优计算位置Inputdata 和 Task 在一起(避免了网络间的信息传输)。实际情况很少会这样, 有可能存在当前那个计算节点的计算资源和计算能力都满了,默认配置不变的情况下 Spark 计算框架会等待 3s(spark.locality.wait 设置的,在 SparkConf()可以修改),默认重试 5 次。如果均失败了,会选择一个比较差的本地节点;Spark 分配算法会将其分配到计算数据附近的节点, Task 会通过其所在节点的 BlockManager 来获取数据,BlockManager 发现自己本地没有数据,会通过getRemote()方法,通过 TransferService(网络数据传输组件)从原 task 所在节点的 BlockManager 中,获取数据,通过网络传输回 Task 所在节 点----->(性能大幅度下降,大量的网络 IO 占用资源) 计算后的结果会返回 到 Driver 上
5.Spark运行时
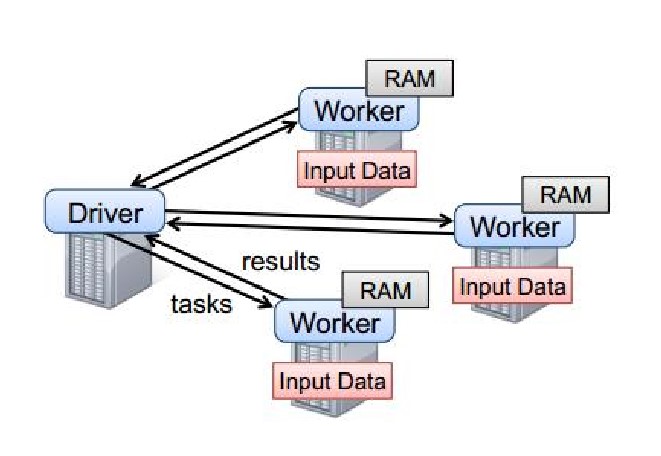
Driver(SparkContext运行所在的节点可以看做一个Driver)作用:
分发task给对应的Worker,可以和其他节点(Worker)进行通信
接收task的计算结果
Worker作用:
Worker 可以是一台真实的物理机,也可以是虚拟机,拥有 RAM 和 Core,执行运算
6.Spark算子--Transformations || Actions
|
Transformations || Actions 这两类算子的区别
|
||
|
Transformations
|
Transformations类的算子会返回一个新的RDD,懒执行 | |
|
Actions
|
Actions类的算子会返回基本类型或者一个集合,能够触发一个job的 执行,代码里面有多少个action类算子,那么就有多少个job | |
常见的算子
| Transformation类算子 | map | 输入一条,输出一条 将原来 RDD 的每个数据项通过 map 中的用户自定义函数映射转变为一个新的 元素。输入一条输出一条; |
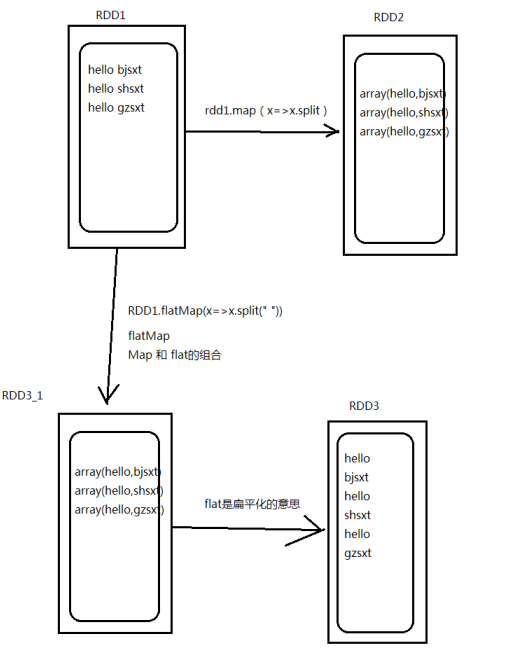
| flatMap | 输入一条输出多条 先进行map后进行flat |
|
| mapPartitions | 与 map 函数类似,只不过映射函数的参数由 RDD 中的每一个元素变成了 RDD 中每一个分区的迭代器。将 RDD 中的所有数据通过 JDBC 连接写入数据库,如果使 用 map 函数,可能要为每一个元素都创建一个 connection,这样开销很大,如果使用 mapPartitions,那么只需要针对每一个分区建立一个 connection。 | |
| mapPartitionsWithIndex | ||
| filter | 依据条件过滤的算子 | |
| join | 聚合类的函数,会产生shuffle,必须作用在KV格式的数据上 join 是将两个 RDD 按照 Key 相同做一次聚合;而 leftouterjoin 是依 据左边的 RDD 的 Key 进行聚 |
|
| union | 不会进行数据的传输,只不过将这两个的RDD标识一下 (代表属于一个RDD) |
|
| reduceByKey | 先分组groupByKey,后聚合根据传入的匿名函数聚合,适合在 map 端进行 combiner | |
| sortByKey | 依据 Key 进行排序,默认升序,参数设为 false 为降序 | |
| mapToPair | 进行一次 map 操作,然后返回一个键值对的 RDD。(所有的带 Pair 的算子返回值均为键值对) | |
| sortBy | 根据后面设置的参数排序 | |
| distinct | 对这个 RDD 的元素或对象进行去重操作 | |
| Actions类算子 | foreach | foreach 对 RDD 中的每个元素都应用函数操作,传入一条处理一条数据,返回值为空 |
| collect | 返回一个集合(RDD[T] => Seq[T]) collect 相当于 toArray, collect 将分布式的 RDD 返回为一个单机的 Array 数组。 |
|
| count | 一个 action 算子,计数功能,返回一个 Long 类型的对象 | |
| take(n) | 取前N条数据 | |
| save | 将RDD的数据存入磁盘或者HDFS | |
| reduce | 返回T和原来的类型一致(RDD[T] => T) | |
| foreachPartition | foreachPartition 也是根据传入的 function 进行处理,但不 同处在于 function 的传入参数是一个 partition 对应数据的 iterator,而不是直接使用 iterator 的 foreach。 |
map和flatMap者两个算子的区别
7.Spark中WordCount演变流程图_Scala和Java代码
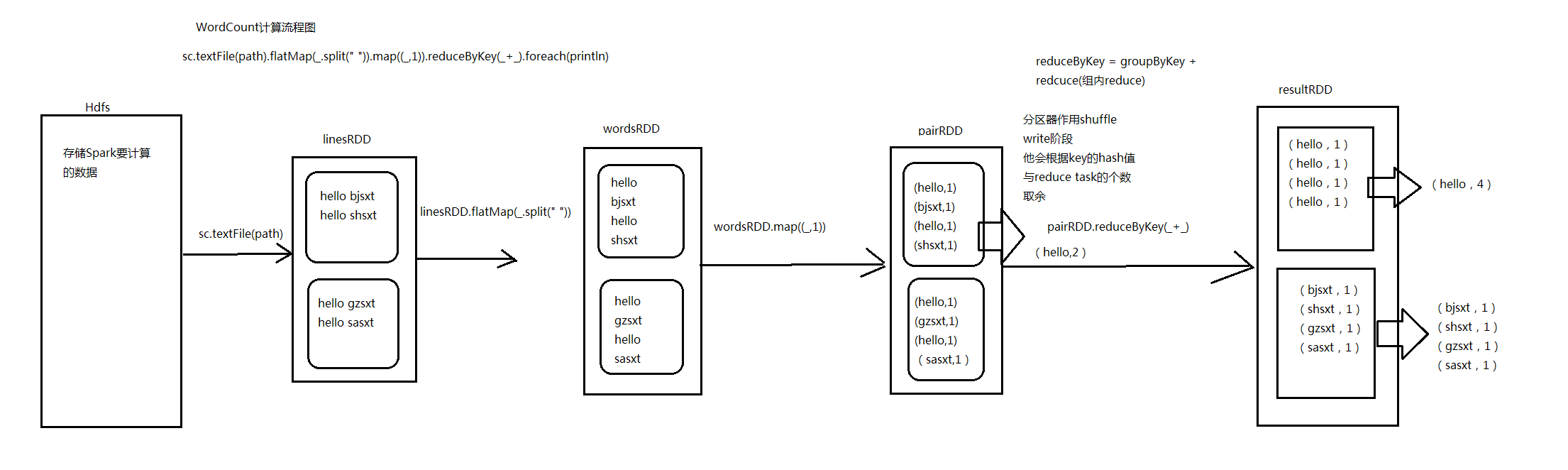
这里以Scala代码为例
package com.hzf.spark.exerciseimport org.apache.spark.SparkConfimport org.apache.spark.SparkContext/*** 统计每一个单词出现的次数*/object WordCount{def main(args:Array[String]):Unit={/*** 设置Spark运行时候环境参数 ,可以在SparkConf对象里面设置* 我这个应用程序使用多少资源 appname 运行模式*/val conf =newSparkConf().setAppName("WordCount").setMaster("local")/*** 创建Spark的上下文 SparkContext** SparkContext是通往集群的唯一通道。* Driver*/val sc =newSparkContext(conf)//将文本中数据加载到linesRDD中val linesRDD = sc.textFile("userLog")//对linesRDD中每一行数据进行切割val wordsRDD = linesRDD.flatMap(_.split(" "))val pairRDD = wordsRDD.map{(_,1)}/*** reduceByKey是一个聚合类的算子,实际上是由两步组成** 1、groupByKey* 2、recuce*/val resultRDD = pairRDD.reduceByKey(_+_)/*(you,2)(Hello,2)(B,2)(a,1)(SQL,2)(A,3)(how,2)(core,2)(apple,1)(H,1)(C,1)(E,1)(what,2)(D,2)(world,2)*/resultRDD.foreach(println)/*(Spark,5)(A,3)(are,2)(you,2)(Hello,2)*/val sortRDD = resultRDD.map(x=>(x._2,x._1))val topN = sortRDD.sortByKey(false).map(x=>(x._2,x._1)).take(5)topN.foreach(println)}}
并行化:把一个本地集合或数据转化为RDD的过程就是并行化
7.Spark_RDD持久化
7.1cache需要注意的事项
1.cache的返回值,必须赋值给一个新的变量(或者原来的是var类型的变量),然后在其他job中直接使用这个变量即可
2.cache是一个懒执行的算子,所以必须有Actions类型的算子(比如:count)触发它
3.cache算子的后面不能立即添加Actions类型的算子(比如:val aRDD = linesRDD.cache()是正确的,而val bRDD = linesRDD.cache().count就是错误的)
7.2cache 和 persist 联系 || 区别?
联系:cache和persist都为懒执行,所以需要触发Actions类型的算子才会将RDD的结果持久化到内存
区别:cache是persist的一个简化版(cache是持久化到内存),persist里面可以手动指定其他持久化级别
liensRDD = liensRDD.cache() 等价于 liensRDD = liensRDD.persist(StorageLevel.MEMORY_ONLY)

参数的含义:
(1)持久化到磁盘
(2)持久化到内存
(3)使用对外内存(一般都是 false)
(4) 表示“不序列化”:true 表示不序列化;false 表示序列化
(5)表示副本个数
持久化的单位是partition,上面的2是指partition的备份数,不是指持久化到几个节点上
7.3另一个持久化的算子--checkpoint
checkpoin也是懒执行,为了使RDD持久化的数据更加安全,可以使用checkpoint
checkpoint流程
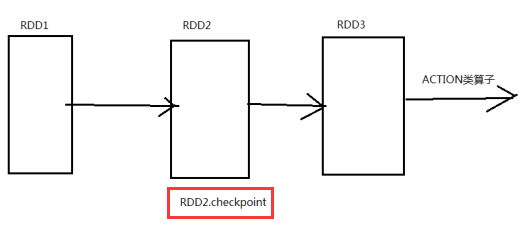
1.在RDD的job执行完成之后,会自动的从finalRDD(RDD3)从后往前进行回溯(为什么能够回溯?因为RDD的第三大特性,RDD之间是有一系列的依赖关系),遇到哪一个RDD(这里是RDD2)调用了checkpoint这个方法,就会对这个RDD做一个标记maked for checkpoint
2.另外重新启动一个新的job,重新计算被标记的RDD,将RDD的结果写入到HDFS中
3.如何对第二步进行优化:重新计算被标记的RDD,这样的话这个RDD就被计算了两次,最好调用checkpoint之前进行cache一下,这样的话,重新启动这个job只需要将内存中的数据拷贝到HDFS上就可以(省去了计算的过程)
4.checkpoint的job执行完成之后,会将这个RDD的依赖关系切断(即RDD2不需要再依赖RDD1,因为已经将RDD2这一步持久化了,以后需要数据的时候直接从持久化的地方取就可以了),并统一更名为checkpointRDD(RDD3的父RDD更名为checkpointRDD)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号