



python全栈学习--day40()
上一章节内容汇总:
进程 multiprocess
Process ------ 进程 在python中创建一个进程的模块
start
daemon 守护进程
join 等待子进程执行结束
锁 Lock
acquire release
锁是一个同步控制的工具
如果同一时刻有多个进程同时执行一段代码,那么在内存中数据是不会发生冲突的。但是,如果涉及到文件,数据库机会发生资源冲突的问题。我们就需要用锁来把这段代码锁起来。任意一个进程执行了acquire之后,其他所有的进程都会在这里阻塞,等待一个release
信号量 semaphore
锁 + 计数器
set clear is set 控制对象的状态
wait 根据状态的不同执行效果也不同
状态是True ----> pass
状态是False ----> 阻塞
一般wait是和set clear 放在不同的进程中
set/clear 是负责控制状态
我可以在一个进程中控制另外一个或多个进程的运行情况。
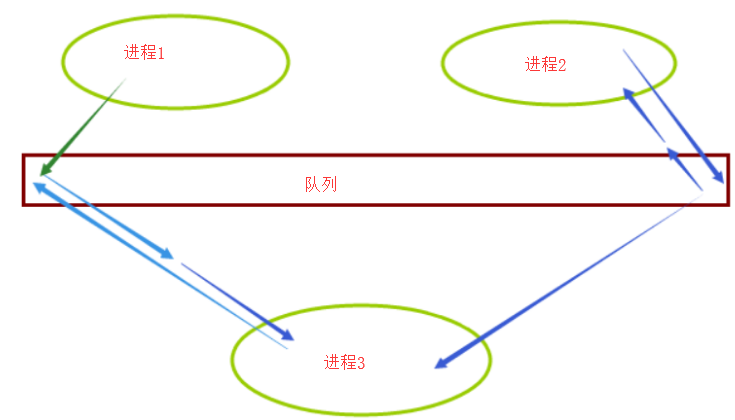
IPC通信
队列 Queue
管道 PIPE
进程间通信——队列和管道(multiprocess.Queue、multiprocess.Pipe)
队列
from multiprocessing import Process,Queue
Queue([maxsize]) 创建共享的进程队列。 参数 :maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。 底层队列使用管道和锁定实现。
Queue([maxsize])
创建共享的进程队列。maxsize是队列中允许的最大项数。如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。另外,还需要运行支持线程以便队列中的数据传输到底层管道中。
Queue的实例q具有以下方法:
q.get( [ block [ ,timeout ] ] )
返回q中的一个项目。如果q为空,此方法将阻塞,直到队列中有项目可用为止。block用于控制阻塞行为,默认为True. 如果设置为False,将引发Queue.Empty异常(定义在Queue模块中)。timeout是可选超时时间,用在阻塞模式中。如果在制定的时间间隔内没有项目变为可用,将引发Queue.Empty异常。
q.get_nowait( )
同q.get(False)方法。
q.put(item [, block [,timeout ] ] )
将item放入队列。如果队列已满,此方法将阻塞至有空间可用为止。block控制阻塞行为,默认为True。如果设置为False,将引发Queue.Empty异常(定义在Queue库模块中)。timeout指定在阻塞模式中等待可用空间的时间长短。超时后将引发Queue.Full异常。
q.qsize()
返回队列中目前项目的正确数量。此函数的结果并不可靠,因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
q.empty()
如果调用此方法时 q为空,返回True。如果其他进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
q.full()
如果q已满,返回为True. 由于线程的存在,结果也可能是不可靠的(参考q.empty()方法)。。
方法介绍
说明
队列可以在创建的时候指定一个容量
如果在程序运行的过程中,队列已经有了足够的数据,在put就会发生阻塞。
如果队列为空,在get就会发生阻塞。内存------制定容量
判断队列是否为空
from multiprocessing import Process,Queue q = Queue() print(q.empty())
执行输出:True
如果队列已满,在增加加值的操作,会被阻塞,知道队列有空余的。
from multiprocessing import Process,Queue
q = Queue(10) #创建一个只能放10个value的队列
for i in range(10):
q.put(i) #增加一个value
print(q.qsize()) #返回队列中目前的正确数量
print(q.full()) #如果q已满,返回为True
q.put(111) #在增加一个值
print(q.empty())
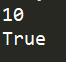
从结果中,可以看出,下面的操作q.put(111)之后的代码被阻塞了。
总结:
队列可以在创建的时候指定一个容量
如果在程序运行的过程中,队列已经有了足够的数据,在put就会发送阻塞
如果队列为空,在get就会发送阻塞
为什么要向队列的长度呢?是为了防止内存爆炸。
一个队列,不能无限制的存储。毕竟,内存是有限制的。
上面提到的put,get,full ,empty都是不准的。
因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
如果其他进程或线程正在往队列中添加项目,可能是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
import time
from multiprocessing import Process,Queue
def wahaha(q):
print(q.get())
q.put(2) #增加数字2
if __name__ == '__main__':
q = Queue()
p = Process(target=wahaha,args=[q,])
p.start()
q.put(1) #增加数字1
time.sleep(0.1)
print(q.get())
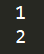
先执行主进程的q.get(),在执行子进程的q.get()
在进程中使用队列可以完成双向通信
队列是进程安全的,内置了锁类保证队列中的每一个数据都不会被多个进程重复取
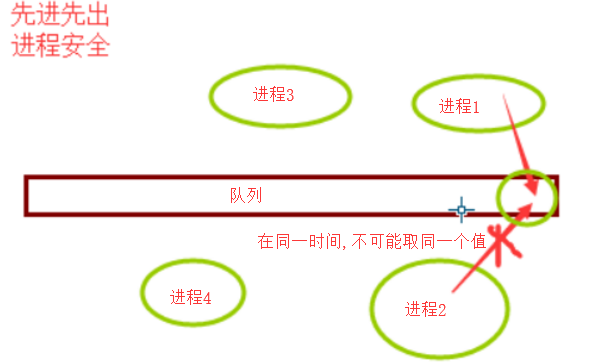
在同一个时刻,只能有一个进程来取值,它内部有一个锁的机制。那么另外一个进程就会被阻塞一会,但是阻塞的时间非常短队列能保证数据安全,同一个数据,不能被多个进程获取。
生产者消费者模型
解决数据供需不平衡的情况
from multiprocessing import Process,Queue
def producer(q,name,food):
for i in range(5):
print('{}生产了{}{}'.format(name,food,i))
if __name__ == '__main__':
q = Queue()
Process(target=producer,args=[q,'四川','蚂蚁上树']).start()
Process(target=producer,args=[q,'广东','龙虎斗']).start()

增加一个消费者
import time
import random
from multiprocessing import Process,Queue
def producer(q,name,food):
for i in range(5):
time.sleep(random.random()) #模拟生产时间
print('{}生产了{}{}'.format(name,food,i))
q.put('{}{}'.format(food,i)) #放入队列
def consumer(q,name):
for i in range(10):
food = q.get() #获取队列
time.sleep(random.random()) #模拟吃时间
print('{}吃了{}'.format(name,food))
if __name__ == '__main__':
q = Queue()
Process(target=producer,args=[q,'四川','麻婆豆腐']).start()
Process(target=producer,args=[q,'广东','八宝冬瓜盅']).start()
Process(target=consumer,args=[q,'John']).start()

注意:必须将消费者的range(10)修改为5,否则程序会卡住。为什么呢?因为队列已经是空的。在取机会阻塞这样才能解决供需平衡。
那么问题来了,如果一个消费者,吃的比较快呢?
在修改range值?太low 了,能者多劳嘛。不能使用q.empty(),他是不准确的。看下图,有可能一开始,队列就空了。
看下图的0.1更快

看下面的解决方案:
import time
import random
from multiprocessing import Process,Queue
def producer(q,name,food):
for i in range(5):
time.sleep(random.random()) #模拟生产时间
print('{}生产了{}{}'.format(name,food,i))
q.put('{}{}'.format(food,i)) #放入队列
def consumer(q,name):
for i in range(10):
food = q.get() #获取队列
time.sleep(random.random()) #模拟吃时间
print('{}吃了{}'.format(name,food))
if __name__ == '__main__':
q = Queue()#创建队列对象,如果不提供maxsize,则队列数无限制
p1 = Process(target=producer,args=[q,'四川','麻婆豆腐'])
p2 = Process(target=producer,args=[q,'广东','八宝冬瓜盅'])
p1.start() #启动进程
p2.start() #启动进程
Process(target=consumer,args=[q,'John']).start()
Process(target=consumer, args=[q, 'jenny']).start()
p1.join()
p2.join()
q.put('鲫鱼豆腐')
q.put('大酱肘子')
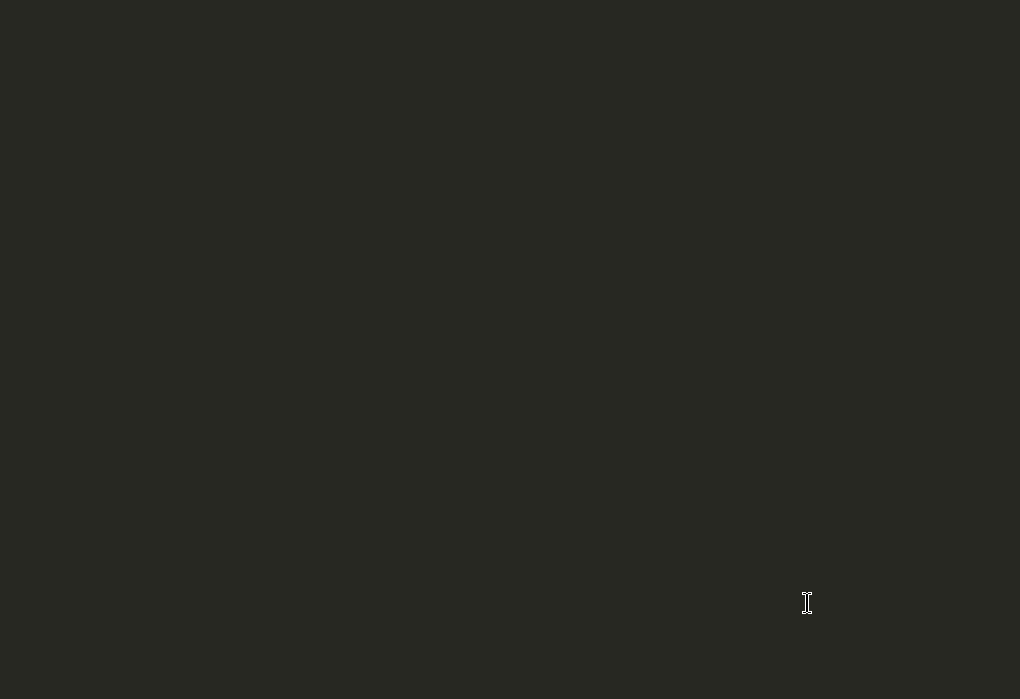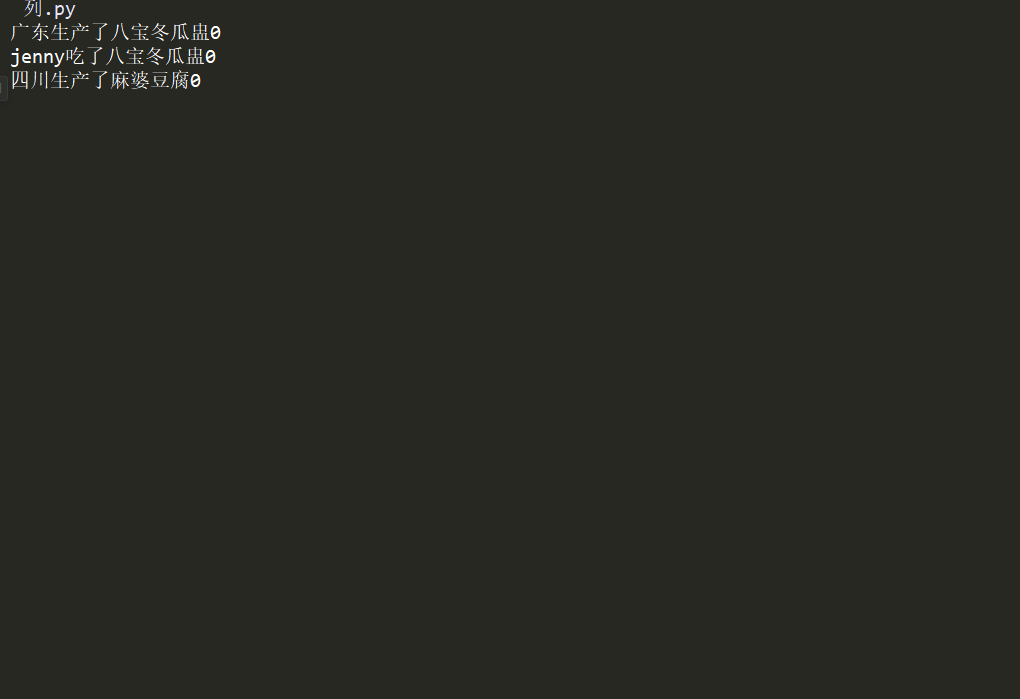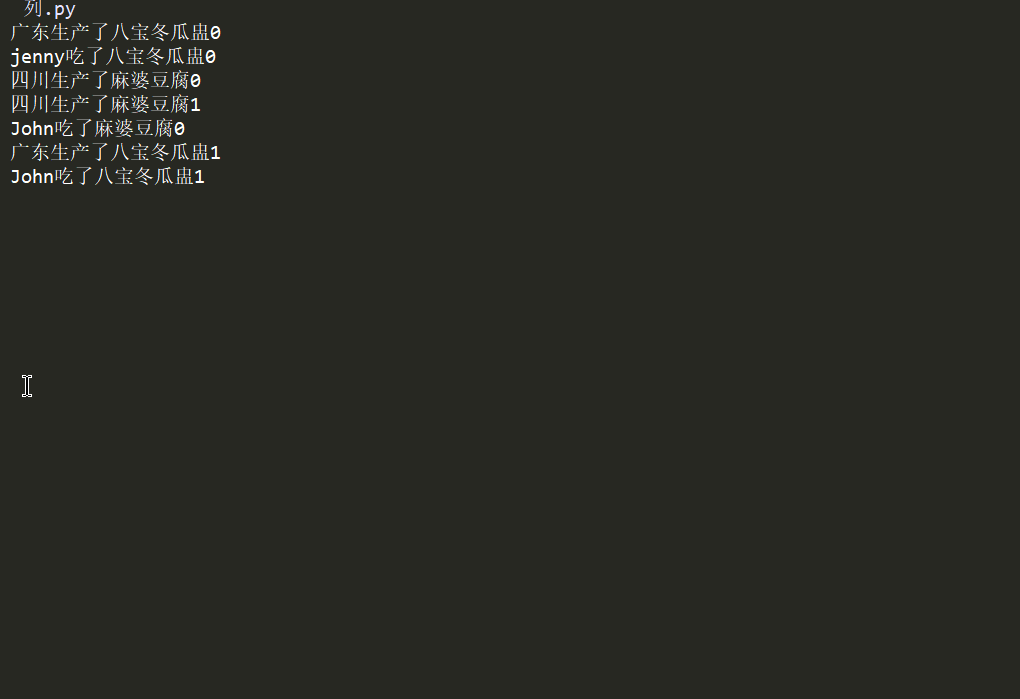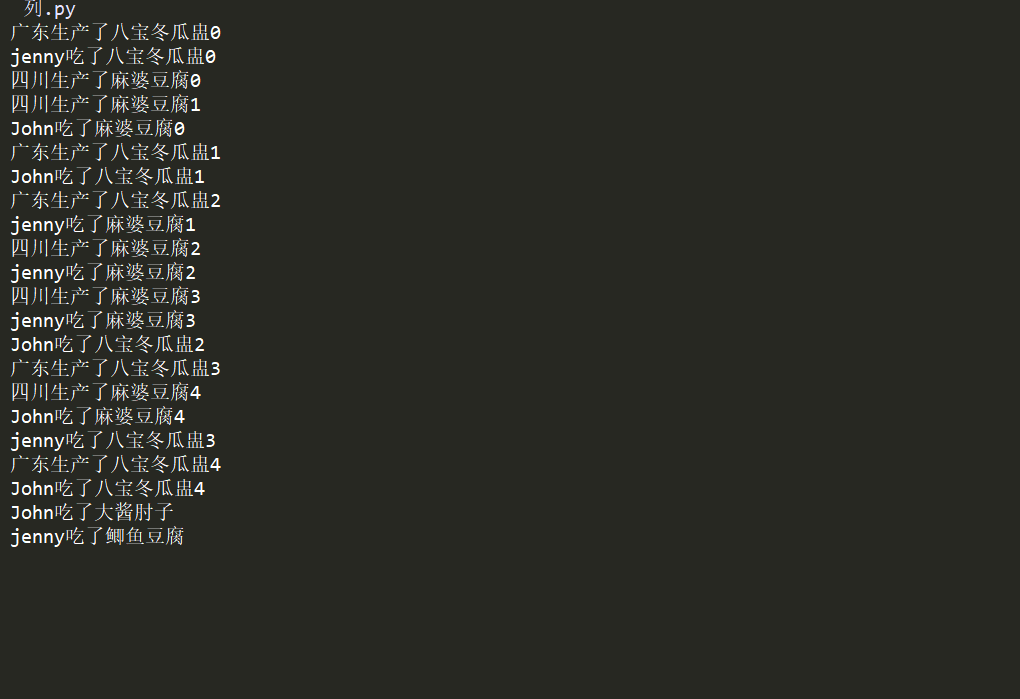
为什么要有2个done ?因为有两个2消费者
为什么要有2个join ? 因为必须要等厨师做完菜才可以。
最后输出2个done,表示通知2个顾客,菜已经上完了,顾客要结账了。
2个消费者,都会执行break。通俗的来讲,亲,您一共消费了xx元,请付款!
上面的解决方案,代码太长了,有一个消费者,就得done一次。
下面介绍JoinableQueue
JoinableQueue([maxsize])
创建可连接的共享进程队列。这就像是一个Queue对象,但队列允许项目的使用者通知生产者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
JoinableQueue的实例p除了与Queue对象相同的方法之外,还具有以下方法:
q.task_done()
使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常。
q.join()
生产者将使用此方法进行阻塞,直到队列中所有项目均被处理。阻塞将持续到为队列中的每个项目均调用q.task_done()方法为止。
下面的例子说明如何建立永远运行的进程,使用和处理队列上的项目。生产者将项目放入队列,并等待它们被处理。

JoinableQueue的实例p除了与Queue对象相同的方法之外,还具有以下方法: q.task_done() 使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常。 q.join() 生产者将使用此方法进行阻塞,直到队列中所有项目均被处理。阻塞将持续到为队列中的每个项目均调用q.task_done()方法为止。 下面的例子说明如何建立永远运行的进程,使用和处理队列上的项目。生产者将项目放入队列,并等待它们被处理。
JoinableQueue队列实现消费之生产者模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号