决策树
决策树的概念
决策树是一个类似于流程图的树结构:其中,每个内部结点表示一个特征或属性,而每个树叶结点代表一个分类。树的最顶层是根结点。使用决策树分类时就是将实例分配到叶节点的类中。该叶节点所属的类就是该节点的分类。(通过下图理解)
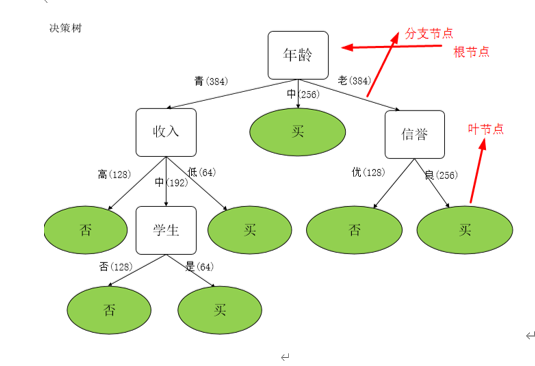
构建决策树三要素
特征选择
基于规则的选择
信息熵
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==>(也就是说)信息量的度量就等于不确定性的多少
通常多个独立事件所产生的不确定性等于各自不确定性之和,也就是每个事件的发生与不发生是相互独立的,这在数学上称为可加性,而满足这样可加性的函数就是我们在高中阶段所学习过的对数函数(log函数)。由此得到第一个不确定性函数I(x)公式:
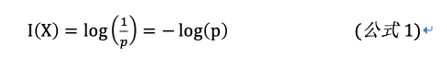
如果对一个随机事件有n种取值:X1,X2,X3…,对应的概率p1,p2…..pn,则该事件的不确定性应该是单个取值的不确定性的期望E,也叫作信息熵,即:

上述若对数的底数取值为2,就是我们平常所说的信息单位bit(比特)。
信息增益
- 用于ID3算法的
- Gain(A) = Info(D) - Info_A(D)
- Gain(A)=以A节点作为分支节点的的信息增益----选择较大的值对应的信息增益
- Info(D)=总体的信息熵-------一般总体的信息熵不变的
- Info_A(D)=以A节点作为分支节点的信息熵----------优选选择较小的熵代表的特征
信息增益率
Gainr(A) =Gain(A) /H(A) :其中H(A)为A的熵
Gini系数
决策树生成
基于规则生成
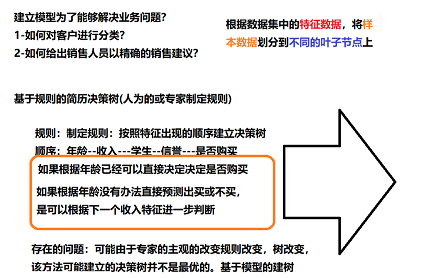
- 问题:
- 可能人工选择的规则是不准确的,需要有一些科学合理的方法选择根节点或分支节点作为当前构建决策树的方法或思路
ID3算法(使用 信息增益 进行特征选择)
- 1-算法思想:首先根据信息增益选择特征,选择信息增益较大的值对应的特征作为根节点或分解节点,如果当前节点不能够很好的对样本进行分类,继续寻找剩余的特征中信息增益较大的值对应的特征,递归构建决策树
- 2-算法输入:样本和特征构成及集合
- 3-算法输出:ID3的决策树
- 4-算法步骤:
- 1-如果所有的属性都被处理完毕,直接返回
- 2-计算所有节点的信息增益的较大的值对应特征当做当前的分支节点或根节点
- 3-如果上述的划分能够将所有的样本划分,停止迭代。否则从剩余的特征中选择信息增益较大的值对应的特征,进一步的划分样本数据
- 4-递归构建决策树
- 5-算法优化
- 6-算法的停止迭代条件
- 算法的迭代次数
- 算法的树的深度
- 树的叶子节点的个数
- 树的分支节点含有样本的个数
- 树的叶子节点含有的样本个数
- 树的最大不纯度的下降速率
有了以上理论基础我们可以接下来通过一个小例子完整计算信息熵和信息增益,从而通过ID3算法构造决策树。
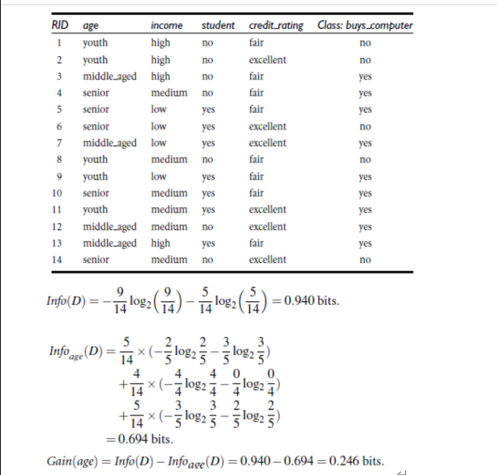
注:整个数据集信息熵与当前节点(划分节点)信息熵的差,就是信息增益
类似,Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
所以,选择age作为第一个根节点
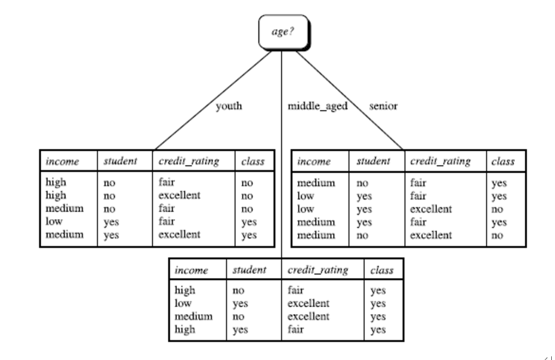
重复上述过程。
C4.5算法(使用 信息增益率 进行特征选择)
C4.5用信息增益率来选择属性,克服用信息增益选择时候偏向选择取值多属性不足(如ID列)
信息增益率:Gainr(A)** =Gain(A) /H(A) :其中H(A)为A的熵
Cart树 (树的剪枝技术)
- Classification and Regression Trees
- 两个用途:用于分类(gini系数)---一个用于回归(平方误差)
- gini系数:经济学上使用gini系数衡量贫富差距,gini系数越小贫富差距越小,gini系数越大贫富差距越大,信息论里面引入了gini系数,gini系数表征信息的纯度,gini系数越小,信息的确定性越好,信息的纯度越高。
决策树的剪枝
什么是剪枝
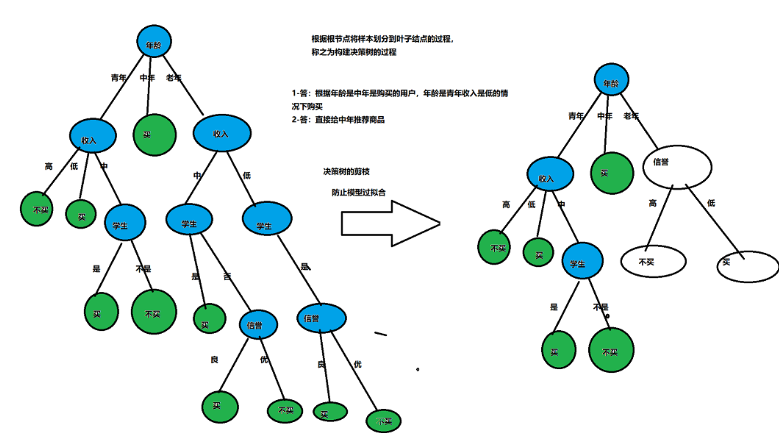
剪枝是指将一颗子树的子节点全部删掉,利用叶子节点替换子树(实质上是后剪枝技术),也可以(假定当前对以root为根的子树进行剪枝)只保留根节点本身而删除所有的叶子,以下图为例:

- 可以利用子树中叶子结点替换子树
- 也可以利用子树中最常出现的分支替换子树
为什么需要剪枝
- 因为决策树容易产生过拟合的线性
如何剪枝
-
先剪枝
-
在决策树生长过程中进行剪枝---容易发生欠拟合
-
方法:
-
算法的迭代次数
-
算法的树的深度
-
树的叶子节点的个数
-
树的分支节点含有样本的个数
-
树的叶子节点含有的样本个数
-
树的最大不纯度的下降速率
-
(1)当阈值a选择的过大的时候,节点的不纯度依然很高就停止了分裂。此时的树由于生长不足,导致决策树过小,分类的错误率过高。因此需要调整a参数的合理范围之内的值。 (2)当阈值a选择的过小的时候,比如a接近0,节点的分割过程近似于原始的分割过程。 -
选择合适的a值,a值是超参数,超参数需要在模型训练之前事先设定
-
-
后剪枝
-
在决策树生成完成之后在进行剪枝
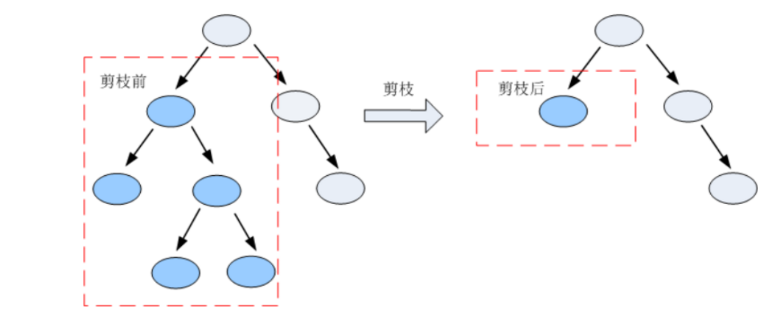
- 可以利用子树中叶子结点替换子树
- 也可以利用子树中最常出现的分支替换子树
- 最小的错误剪枝(MEP)-----剪枝之后和原来是情况相比错误率不能下降的太快
-
剪枝的数学原理(了解)
剪枝总体思路:
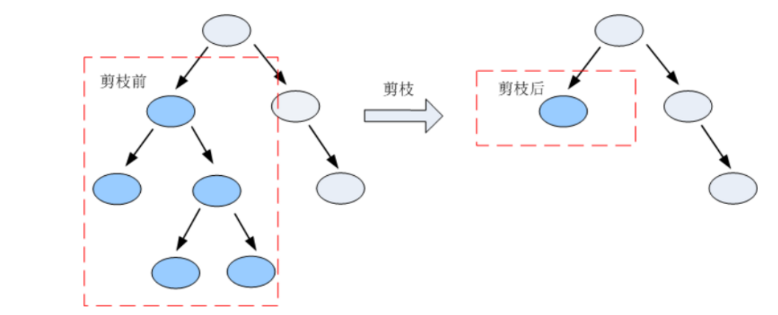
由完全树T0开始,剪枝部分节点得到T1,再次剪枝部分节点得到T2...直到仅剩树根的树Tk;在验证数据集上对这K个树分别评价,选择损失函数最小的树的树Ta。
剪枝系数


剪枝算法
对于给定的决策树T0
- 计算所有内部节点的剪枝系数a
- (a越大,表示单根,就会越安全,a越小表示未剪枝)
- 查找最小剪枝系数a的结点,剪枝得决策树Tk
- 重复以上步骤,直到决策树TK只有1个结点
- 得到决策树序列T0、T1、T2、T3..............Tk
- 使用验证样本集选择最优子树,可以使用损失函数作为评价最优子树的标准
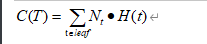
决策树算法的特点
(1) 决策树的优点:
- 直观,便于理解,小规模数据集有效
- 执行效率高,执行只需要一次构建,可反复使用
(2)决策树的缺点:
- 处理连续变量不好,较难预测连续字段
- 类别较多时,错误增加的比较快
- 对于时间序列数据需要做很多的预处理
- 可规模性一般
- 实际分类的时候只能根据一个字段进行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号