

巩固复习(对以前的随笔总结)_03
注:此篇随笔进行读取内容时,所读取的文件可以修改为自己的文件.
Seaborn基础1
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# # 折线图
def sinplot(flip = 1):
x = np.linspace(0,14,100)
for i in range(1,7):
plt.plot(x,np.sin(x+i*0.5) * (7-i) * flip)
sns.set()
# # 默认组合
sinplot()
plt.show()
# # 不带灰色格子
sns.set_style("white")
sinplot()
plt.show()
# 坐标加上竖线
sns.set_style("ticks")
sinplot()
plt.show()
# 将右上角的两条线去掉
sinplot()
sns.despine()
plt.show()
# # 盒图
sns.set_style("whitegrid")
data = np.random.normal(size=(20,6)) + np.arange(6)/2
sns.boxplot(data = data)
plt.show()
Seaborn基础2
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
def sinplot(flip = 1):
x = np.linspace(0,14,100)
for i in range(1,7):
plt.plot(x,np.sin(x+i*0.5) * (7-i) * flip)
data = np.random.normal(size=(20,6)) + np.arange(6)/2
# 使用 despine 进行操作
sns.violinplot(data)
sns.despine(offset = 10)
# offset 设置距离轴的距离
plt.show()
# 底部变为白色
sns.set_style("whitegrid")
# 让左面的竖线消失
sns.boxplot(data = data,palette = "deep")
sns.despine(left = True)
plt.show()
# 五种主题风格 darkgrid whitegrid dark white ticks
# 绘制子图
with sns.axes_style("darkgrid"):
# 第一种风格背景为黑色
plt.subplot(211)
# 分两个一列上面
sinplot()
plt.subplot(212)
sinplot(-1)
plt.show()
# 设置布局,画图的大小和风格
sns.set_context("paper")
# sns.set_context("talk")
# sns.set_context("poster")
# sns.set_context("notebook")
# 线条粗细依次变大
plt.figure(figsize=(8,6))
sinplot()
plt.show()
# 设置坐标字体大小 参数 font_scale
sns.set_context("paper",font_scale=3)
plt.figure(figsize=(8,6))
sinplot()
plt.show()
# 设置线的粗度 rc = {"lines.linewidth":4.5}
sns.set_context("paper",font_scale=1.5,rc={"lines.linewidth":3})
plt.figure(figsize=(8,6))
sinplot()
plt.show()
Seaborn基础3
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
sns.set(rc = {"figure.figsize":(6,6)})
# 调色板
# color_palette() 默认颜色 , 可以传入所有支持颜色
# set_palette() 设置所有图的颜色
# 分类色板,显示十种颜色
current_palette = sns.color_palette()
sns.palplot(current_palette)
plt.show()
current_palette = sns.color_palette("hls",8)
# 设置八种颜色
sns.palplot(current_palette)
plt.show()
# 将八种颜色应用在盒图中
current_palette = sns.color_palette("hls",8)
data = np.random.normal(size = (20,8)) + np.arange(8)/2
sns.boxplot(data = data,palette = current_palette)
plt.show()
# 指定亮度和饱和度
# hls_palette()
# l 亮度 s 饱和度
# 使用饱和度方法
sns.palplot(sns.hls_palette(8,l = 1,s = 5))
# 将两个相邻的颜色相近 使用 Paired 参数
sns.palplot(sns.color_palette("Paired",10))
plt.show()
# 连续型渐变色画板 color_palette("颜色名")
sns.palplot(sns.color_palette("Blues"))
# 从浅到深
plt.show()
# 从深到浅 加上 _r 后缀名
sns.palplot(sns.color_palette("BuGn_r"))
plt.show()
# cubehelix_palette() 调色板
# 八种颜色分别渐变
sns.palplot(sns.color_palette("cubehelix",8))
plt.show()
# 指定 start 值,在区间中颜色的显示也不同
sns.palplot(sns.cubehelix_palette(8,start=5,rot=-0.75))
plt.show()
# 颜色从浅到深 light_palette
sns.palplot(sns.light_palette("green"))
plt.show()
# 颜色从深到浅 dark_palette
sns.palplot(sns.dark_palette("green"))
plt.show()
# 实现反转颜色 在 light_palette 中添加参数 reverse
sns.palplot(sns.light_palette("green",reverse = True))
plt.show()
Seaborn实现单变量分析
import numpy as np
import pandas as pd
from scipy import stats,integrate
import matplotlib.pyplot as plt
import seaborn as sns
# 绘制直方图
sns.set(color_codes=True)
np.random.seed(sum(map(ord,"distributions")))
# 生成高斯数据
x = np.random.normal(size = 100)
#
# sns.distplot(x,kde = False)
# x 数据 kde 是否做密度估计
# 将数据划分为 15 份 bins = 15
sns.distplot(x,kde = False,bins = 15)
plt.show()
# 查看数据分布状况,根据某一个指标画一条线
x = np.random.gamma(6,size = 200)
sns.distplot(x,kde = False,fit = stats.gamma)
plt.show()
mean,cov = [0,1],[(1,5),(0.5,1)]
data = np.random.multivariate_normal(mean,cov,200)
df = pd.DataFrame(data,columns=["x","y"])
# 单变量使用直方图,关系使用散点图
# 关系 joinplot (x,y,data)
sns.jointplot(x = "x",y = "y",data = df)
# 绘制散点图和直方图
plt.show()
# hex 图,数据越多 色越深
mean,cov = [0,1],[(1,8),(0.5,1)]
x,y = np.random.multivariate_normal(mean,cov,500).T
# 注意 .T 进行倒置
with sns.axes_style("white"):
sns.jointplot(x = x,y = y,kind = "hex",color = "k")
plt.show()
Seaborn实现回归分析
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
iris = pd.read_csv("iris.csv")
# 对角线上是单个数据的情况,旁边的图都是关系分布的情况
sns.pairplot(iris)
plt.show()
tips = pd.read_csv("tips.csv")
print(tips.head())
# 画图方式 regplot() 和 lmplot
sns.regplot(x = "total_bill",y = "tip",data = tips)
# x y 都是原数据的列名
plt.show()
# lmplot 画图方式,支持更高级的功能,但是规范多
sns.lmplot(x = "total_bill",y = "tip",data = tips)
plt.show()
sns.lmplot(x = "size",y = "tip",data = tips)
plt.show()
# 加上抖动,使回归更准确
sns.regplot(x = "size",y = "tip",data = tips,x_jitter=0.08)
# x_jitter=0.05 在原始数据集中加上小范围浮动
plt.show()
Seaborn实现多变量分析
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
sns.set(style = "whitegrid",color_codes = True)
np.random.seed(sum(map(ord,"categorical")))
titanic = pd.read_csv("titanic.csv")
tips = pd.read_csv("tips.csv")
iris = pd.read_csv("iris.csv")
# 显示多个点
sns.stripplot(x = "day",y = "total_bill",data = tips)
plt.show()
sns.swarmplot(x = "day",y = "total_bill",data = tips,hue = "sex")
# hue="sex" 生成两个颜色的小圆圈 混合进行查看,进行优化
plt.show()
# 四分位距 IQR 四分之一到四分之三位 之间的距离
# N = 1.5 * IQR
# 离群点 > Q3 + N , < Q1 - N
sns.boxplot(x = "day",y = "total_bill",data = tips)
# hue = "time" 列名
plt.show()
# 小提琴图
sns.violinplot(x = "total_bill",y = "day",hue = "time",data = tips)
plt.show()
# 加入 split 竖着展示
sns.violinplot(x = "day",y = "total_bill",hue = "sex",data = tips,split = True)
plt.show()
由于图片太多,请复制代码后运行查看.文件名修改为自己的文件夹的名字.
将形如 5D, 30s 的字符串转为秒
import sys
def convert_to_seconds(time_str):
# write code here
if 's' in time_str:
return float(time_str[:-1])
elif 'm' in time_str:
return float(time_str[:-1]) * 60
elif 'h' in time_str:
return float(time_str[:-1]) * 3600
elif 'd' in time_str:
return float(time_str[:-1]) * 3600 *24
elif 'D' in time_str:
return float(time_str[:-1]) * 3600 *24
while True:
line = sys.stdin.readline()
line = line.strip()
if line == '':
break
print(convert_to_seconds(line))
获得昨天和明天的日期
import datetime
import sys
def next_day(date_str):
date = datetime.datetime.strptime(date_str, '%Y-%m-%d')
return (date + datetime.timedelta(days=1)).date()
def prev_day(date_str):
date = datetime.datetime.strptime(date_str,'%Y-%m-%d')
return (date - datetime.timedelta(days = 1)).date()
while True:
line = sys.stdin.readline()
line = line.strip()
if line == '':
break
print('前一天:', prev_day(line))
print('后一天:', next_day(line))
计算两个日期相隔的秒数
import datetime
def date_delta(start, end):
# 转换为标准时间
start = datetime.datetime.strptime(start,"%Y-%m-%d %H:%M:%S")
end = datetime.datetime.strptime(end,"%Y-%m-%d %H:%M:%S")
# 获取时间戳
timeStamp_start = start.timestamp()
timeStamp_end = end.timestamp()
return timeStamp_end - timeStamp_start
start = input() # sys.stdin.readline()
end = input() # sys.stdin.readline()
print(date_delta(start, end))
遍历多个 txt 文件进行获取值
import random
def load_config(path):
with open(path,'r') as tou:
return [line for line in tou.readlines()]
headers = {
'User-Agent':load_config('useragents.txt')[random.randint(0,len(load_config('useragents.txt'))-1)].strip("\n"),
'Referer':load_config('referers.txt')[random.randint(0,len(load_config('referers.txt'))-1)].strip("\n"),
'Accept':load_config('acceptall.txt')[random.randint(0,len(load_config('acceptall.txt'))-1)].strip("\n"),
}
print(headers)
安装第三方库
pip install 包名 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
安装第三方库进阶
# 安装 pip 包
from tkinter import *
def getBao():
pip = 'pip install %s -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com'%entry_bao.get()
print(pip)
root = Tk()
root.title("pip包")
root.geometry("250x150+400+300")
url = StringVar()
url_lab1 = Label(text = "请输入包名:")
url_lab1.pack()
entry_bao = Entry(root,textvariable = url)
entry_bao.pack()
btn1 = Button(root,text = "提交",command = getBao,width = 8,height = 2)
btn1.pack()
root.mainloop()
Python第一次实验
'''
计算
1.输入半径,输出面积和周长
2.输入面积,输出半径及周长
3.输入周长,输出半径及面积
'''
# 1.输入半径,输出面积和周长
from math import pi
# 定义半径
r = int(input("请输入半径的值(整数)"))
if r < 0 :
exit("请重新输入半径")
''' S 面积: pi * r * r '''
S = pi * pow(r,2)
print(" 半径为 %d 的圆,面积为 %.2f"%(r,S))
'''C 周长: C = 2 * pi * r '''
C = 2 * pi * r
print(" 半径为 %d 的圆,周长为 %.2f"%(r,C))
# 2.输入面积,输出半径及周长
from math import pi,sqrt
S = float(input("请输入圆的面积(支持小数格式)"))
if S < 0 :
exit("请重新输入面积")
'''r 半径: r = sqrt(S/pi)'''
r = sqrt(S/pi)
print("面积为 %.2f 的圆,半径为 %.2f"%(S,r))
'''C 周长: C = 2 * pi * r '''
C = 2 * pi * r
print("面积为 %.2f 的圆,周长为 %.2f"%(S,C))
# 3.输入周长,输出半径及面积
from math import pi
C = float(input("请输入圆的周长(支持小数格式)"))
if C < 0 :
exit("请重新输入周长")
'''r 半径: r = C/(2*pi)'''
r = C/(2*pi)
print("周长为 %.2f 的圆,半径为 %.2f"%(C,r))
''' S 面积: pi * r * r '''
S = pi * pow(r,2)
print("周长为 %.2f 的圆,面积为 %.2f"%(C,S))
'''
数据结构
列表练习
1.创建列表对象 [110,'dog','cat',120,'apple']
2.在字符串 'dog' 和 'cat' 之间插入空列表
3.删除 'apple' 这个字符串
4.查找出 110、120 两个数值,并以 10 为乘数做自乘运算
'''
# 1.创建列表对象 [110,'dog','cat',120,'apple']
'''创建一个名为 lst 的列表对象'''
lst = [110,'dog','cat',120,'apple']
print(lst)
# 2.在字符串 'dog' 和 'cat' 之间插入空列表
lst = [110,'dog','cat',120,'apple']
'''添加元素到 'dog' 和 'cat' 之间'''
lst.insert(2,[])
print(lst)
# 3.删除 'apple' 这个字符串
lst = [110,'dog','cat',120,'apple']
'''删除最后一个元素'''
lst.pop()
print(lst)
# 4.查找出 110、120 两个数值,并以 10 为乘数做自乘运算
lst = [110,'dog','cat',120,'apple']
try:
# 如果找不到数据,进行异常处理
lst[lst.index(110)] *= 10
lst[lst.index(120)] *= 10
except Exception as e:
print(e)
print(lst)
'''
字典练习
1.创建字典 {'Math':96,'English':86,'Chinese':95.5,'Biology':86,'Physics':None}
2.在字典中添加键值对 {'Histore':88}
3.删除 {'Physisc':None} 键值对
4.将键 'Chinese' 所对应的值进行四舍五入后取整
5.查询键 'Math' 的对应值
'''
# 1.创建字典 {'Math':96,'English':86,'Chinese':95.5,'Biology':86,'Physics':None}
stu_score = {'Math':96,'English':86,'Chinese':95.5,'Biology':86,'Physics':None}
# 2.在字典中添加键值对 {'Histore':88}
stu_score['Histore'] = 88
# 3.删除 {'Physisc':None} 键值对
if 'Physisc' in stu_score.keys():
'''如果存在 "Physisc" '''
del stu_score['Physisc']
# 4.将键 'Chinese' 所对应的值进行四舍五入后取整
if 'Chinese' in stu_score.keys():
# 四舍五入 使用 round
stu_score['Chinese'] = round(stu_score['Chinese'])
# 5.查询键 'Math' 的对应值
print(stu_score.get('Math',"没有找到 Math 的值"))
'''
元组练习
1.创建列表 ['pen','paper',10,False,2.5] 赋给变量并查看变量的类型
2.将变量转换为 tuple 类型,查看变量的类型
3.查询元组中的元素 False 的位置
4.根据获得的位置提取元素
'''
# 1.创建列表 ['pen','paper',10,False,2.5] 赋给变量并查看变量的类型
lst = ['pen','paper',10,False,2.5]
'''查看变量类型'''
print("变量的类型",type(lst))
# 2.将变量转换为 tuple 类型,查看变量的类型
lst = tuple(lst)
print("变量的类型",type(lst))
# 3.查询元组中的元素 False 的位置
if False in lst:
print("False 的位置为(从0开始): ",lst.index(False))
# 4.根据获得的位置提取元素
print("根据获得的位置提取的元素为: ",lst[lst.index(False)])
else:
print("不在元组中")
'''
集合练习
1.创建列表 ['apple','pear','watermelon','peach'] 并赋给变量
2.用 list() 创建列表 ['pear','banana','orange','peach','grape'],并赋给变量
3.将创建的两个列表对象转换为集合类型
4.求两个集合的并集,交集和差集
'''
# 1.创建列表 ['apple','pear','watermelon','peach'] 并赋给变量
lst = ['apple','pear','watermelon','peach']
# 2.用 list() 创建列表 ['pear','banana','orange','peach','grape'],并赋给变量
lst_2 = list({'pear','banana','orange','peach','grape'})
print(lst_2)
# 3.将创建的两个列表对象转换为集合类型
lst_set = set(lst)
lst2_set = set(lst_2)
# 4.求两个集合的并集,交集和差集
''' 并集 | 交集 & 差集 - '''
print("两个集合的 并集为 :",lst_set | lst2_set)
print("两个集合的 交集为 :",lst_set & lst2_set)
print("lst_set 与 lst2_set 的差集为 :",lst_set - lst2_set)
print("lst2_set 与 lst_set 的差集为 :",lst2_set - lst_set)
pip 国内源
常用国内源
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
format 进阶
'''format(数字,str(算术式)+"d或者f")
d 表示 int
f 表示 float
'''
format(5,str(2*4)+"d")
' 5'
format(5,str(2*4)+"f")
'5.000000'
'''使用 .2f 控制小数点个数'''
format(5,str(2*4)+".2f")
' 5.00'
format(5,str(2*15)+"f")
' 5.000000'
'''format(字符串,str(算术式)+"s")'''
format('s',str(2*3)+"s")
's '
进阶删除重复元素
def dedupe(items,key=None):
seen = set()
for item in items:
val = item if key==None else key(item)
#item是否为字典,是则转化为字典key(item),匿名函数调用
if val not in seen:
yield item
seen.add(val)
#集合增加元素val
if __name__=="__main__":
a = [{'x':2,'y':4},{'x':3,'y':5},{'x':5,'y':8},{'x':2,'y':4},{'x':3,'y':5}]
b=[1,2,3,4,1,3,5]
print(b)
print(list(dedupe(b)))
print(a)
print(list(dedupe(a,key=lambda a:(a['x'],a['y']))))
#按照a['x'],a['y']方式
爬虫流程复习2
1.打开网页
urllib.request.urlopen('网址')
例:response = urllib.request.urlopen('http://www.baidu.com/')
返回值为 <http.client.HTTPResponse object at 0x00000224EC2C9490>
2.获取响应头信息
urlopen 对象.getheaders()
例:response.getheaders()
返回值为 [('Bdpagetype', '1'), ('Bdqid', '0x8fa65bba0000ba44'),···,('Transfer-Encoding', 'chunked')]
[('头','信息')]
3.获取响应头信息,带参数表示指定响应头
urlopen 对象.getheader('头信息')
例:response.getheader('Content-Type')
返回值为 'text/html;charset=utf-8'
4.查看状态码
urlopen 对象.status
例:response.status
返回值为 200 则表示成功
5.得到二进制数据,然后转换为 utf-8 格式
二进制数据
例:html = response.read()
HTML 数据格式
例:html = response.read().decode('utf-8')
打印输出时,使用 decode('字符集') 的数据 print(html.decode('utf-8'))
6.存储 HTML 数据
fp = open('文件名.html','模式 wb')
例:fp = open('baidu.html', 'wb')
fp.write(response.read() 对象)
例:fp.write(html)
7.关闭文件
open对象.close()
例:fp.close()
8.使用 ssl 进行抓取 https 的网页
例:
import ssl
content = ssl._create_unverified_context()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'}
request = urllib.request.Request('http://www.baidu.com/', headers = headers)
response = urllib.request.urlopen(request, context = context)
这里的 response 就和上面一样了
9.获取码
response.getcode()
返回值为 200
10.获取爬取的网页 url
response.geturl()
返回值为 https://www.baidu.com/
11.获取响应的报头信息
response.info()
例:
import ssl
request = urllib.request.Request('http://www.baidu.com/', headers = headers)
context = ssl._create_unverified_context()
response = urllib.request.urlopen(request, context = context)
response.info()
获取的为 头信息
--
response = urllib.request.urlopen('http://www.baidu.com/')
response.info()
返回值为 <http.client.HTTPMessage object at 0x00000268D453DA60>
12.保存网页
urllib.request.urlretrieve(url, '文件名.html')
例:urllib.request.urlretrieve(url, 'baidu.html')
13.保存图片
urllib.request.urlretrieve(url, '图片名.jpg')
例:urllib.request.urlretrieve(url, 'Dog.jpg')
其他字符(如汉字)不符合标准时,要进行编码
14.除了-._/09AZaz 都会编码
urllib.parse.quote()
例:
Param = "全文检索:*"
urllib.parse.quote(Param)
返回值为 '%E5%85%A8%E6%96%87%E6%A3%80%E7%B4%A2%3A%2A'
参考链接:https://blog.csdn.net/ZTCooper/article/details/80165038
15.会编码 / 斜线(将斜线也转换为 %.. 这种格式)
urllib.parse.quote_plus(Param)
16.将字典拼接为 query 字符串 如果有中文,进行url编码
dic_object = {
'user_name':'张三',
'user_passwd':'123456'
}
urllib.parse.urlencode(dic_object)
返回值为 'user_name=%E5%BC%A0%E4%B8%89&user_passwd=123456'
17.获取 response 的行
url = 'http://www.baidu.com'
response = urllib.request.urlopen(url)
response.readline()
18.随机获取请求头(随机包含请求头信息的列表)
user_agent = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
ua = random.choice(user_agent)
headers = {'User-Agent':ua}
19.对输入的汉字进行 urlencode 编码
urllib.parse.urlencode(字典对象)
例:
chinese = input('请输入要查询的中文词语:')
wd = {'wd':chinese}
wd = urllib.parse.urlencode(wd)
返回值为 'wd=%E4%BD%A0%E5%A5%BD'
20.常见分页操作
for page in range(start_page, end_page + 1):
pn = (page - 1) * 50
21.通常会进行拼接字符串形成网址
例:fullurl = url + '&pn=' + str(pn)
22.进行拼接形成要保存的文件名
例:filename = 'tieba/' + name + '贴吧_第' + str(page) + '页.html'
23.保存文件
with open(filename,'wb') as f:
f.write(reponse.read() 对象)
24.headers 头信息可以删除的有
cookie、accept-encoding、accept-languag、content-length\connection\origin\host
25.headers 头信息不可以删除的有
Accept、X-Requested-With、User-Agent、Content-Type、Referer
26.提交给网页的数据 formdata
formdata = {
'from':'en',
'to':'zh',
'query':word,
'transtype':'enter',
'simple_means_flag':'3'
}
27.将formdata进行urlencode编码,并且转化为bytes类型
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
28.使用 formdata 在 urlopen() 中
response = urllib.request.urlopen(request, data=formdata)
29.转换为正确数据(导包 json)
read -> decode -> loads -> json.dumps
通过read读取过来为字节码
data = response.read()
将字节码解码为utf8的字符串
data = data.decode('utf-8')
将json格式的字符串转化为json对象
obj = json.loads(data)
禁用ascii之后,将json对象转化为json格式字符串
html = json.dumps(obj, ensure_ascii=False)
json 对象通过 str转换后 使用 utf-8 字符集格式写入
保存和之前的方法相同
with open('json.txt', 'w', encoding='utf-8') as f:
f.write(html)
30.ajax请求自带的头部
'X-Requested-With':'XMLHttpRequest'
31.豆瓣默认都得使用https来进行抓取,所以需要使用ssl模块忽略证书
例:
url = 'http://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action='
page = int(input('请输入要获取页码:'))
start = (page - 1) * 20
limit = 20
key = {
'start':start,
'limit':limit
}
key = urllib.parse.urlencode(key)
url = url + '&' + key
headers = {
'X-Requested-With':'XMLHttpRequest',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
request = urllib.request.Request(url, headers=headers)
# context = ssl._create_unverified_context()
response = urllib.request.urlopen(request)
jsonret = response.read()
with open('douban.txt', 'w', encoding='utf-8') as f:
f.write(jsonret.decode('utf-8'))
print('over')
32.创建处理 http 请求的对象
http_handler = urllib.request.HTTPHandler()
33.处理 https 请求
https_handler = urllib.request.HTTPSHandler()
34.创建支持http请求的opener对象
opener = urllib.request.build_opener(http_handler)
35.创建 reponse 对象
例:opener.open(Request 对象)
request = urllib.request.Request('http://www.baidu.com/')
reponse = opener.open(request)
进行保存
with open('文件名.html', 'w', encoding='utf-8') as f:
f.write(reponse.read().decode('utf-8'))
36.代理服务器
http_proxy_handler = urllib.request.ProxyHandler({'https':'ip地址:端口号'})
例:http_proxy_handler = urllib.request.ProxyHandler({'https':'121.43.178.58:3128'})
37.私密代理服务器(下面的只是一个例子,不一定正确)
authproxy_handler = urllib.request.ProxyHandler({"http" : "user:password@ip:port"})
38.不使用任何代理
http_proxy_handler = urllib.request.ProxyHandler({})
39.使用了代理之后的 opener 写法
opener = urllib.request.build_opener(http_proxy_handler)
40.response 写法
response = opener.open(request)
41.如果访问一个不存在的网址会报错
urllib.error.URLError
42.HTTPError(是URLError的子类)
例:
try:
urllib.request.urlopen(url)
except urllib.error.HTTPError as e:
print(e.code)
print(e.reason)
except urllib.error.URLError as e:
print(e)
43.使用 CookieJar 创建一个 cookie 对象,保存 cookie 值
import http.cookiejar
cookie = http.cookiejar.CookieJar()
44.通过HTTPCookieProcessor构建一个处理器对象,用来处理cookie
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
opener 的写法
opener = urllib.request.build_opener(cookie_handler)
45.使用 r'\x'
\d 表示转义字符 r'\d' 表示 \d
46.设置 正则模式
pattern = re.compile(r'规则', re.xxx )
pattern = re.compile(r'i\s(.*?),')
例:pattern = re.compile(r'LOVE', re.I)
47.match 只匹配开头字符
pattern.match('字符串'[,起始位置,结束位置])
例:m = pattern.match('i love you', 2, 6)
返回值为 <re.Match object; span=(2, 6), match='love'>
48. search 从开始匹配到结尾,返回第一个匹配到的
pattern.search('字符串')
例:m = pattern.search('i love you, do you love me, yes, i love')
返回值为 <re.Match object; span=(2, 6), match='love'>
49.findall 将匹配到的都放到列表中
pattern.findall('字符串')
例:m = pattern.findall('i love you, do you love me, yes, i love')
返回值为 ['love', 'love', 'love']
50.split 使用匹配到的字符串对原来的数据进行切割
pattern.split('字符串',次数)
例:m = pattern.split('i love you, do you love me, yes, i love me', 1)
返回值为 ['i ', ' you, do you love me, yes, i love me']
例:m = pattern.split('i love you, do you love me, yes, i love me', 2)
返回值为 ['i ', ' you, do you ', ' me, yes, i love me']
例:m = pattern.split('i love you, do you love me, yes, i love me', 3)
返回值为 ['i ', ' you, do you ', ' me, yes, i ', ' me']
51.sub 使用新字符串替换匹配到的字符串的值,默认全部替换
pattern.sub('新字符串','要匹配字符串'[,次数])
注:返回的是字符串
例:
string = 'i love you, do you love me, yes, i love me'
m = pattern.sub('hate', string, 1)
m 值为 'i hate you, do you love me, yes, i love me'
52.group 匹配组
m.group() 返回的是匹配都的所有字符
m.group(1) 返回的是第二个规则匹配到的字符
例:
string = 'i love you, do you love me, yes, i love me'
pattern = re.compile(r'i\s(.*?),')
m = pattern.match(string)
m.group()
返回值为 'i love you,'
m.group(1)
返回值为 'love you'
53.匹配标签
pattern = re.compile(r'<div class="thumb">(.*?)<img src=(.*?) alt=(.*?)>(.*?)</div>', re.S)
54.分离出文件名和扩展名,返回二元组
os.path.splitext(参数)
例:
获取路径
image_path = './qiushi'
获取后缀名
extension = os.path.splitext(image_url)[-1]
55.合并多个字符串
os.path.join()
图片路径
image_path = os.path.join(image_path, image_name + extension)
保存文件
urllib.request.urlretrieve(image_url, image_path)
56.获取 a 标签下的 href 的内容
pattern = re.compile(r'<a href="(.*?)" class="main_14" target="_blank">(.*?)</a>', re.M)
例:
import urllib.parse
import urllib.request
import re
class SmileSpider(object):
"""
爬取笑话网站笑话的排行榜
"""
def __init__(self, url, page=1):
super(SmileSpider, self).__init__()
self.url = url
self.page = page
def handle_url(self):
'''
处理url并且生成request请求对象
'''
self.url = self.url + '?mepage=' + str(self.page)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(self.url, headers=headers)
return request
def xiazai(self, request):
'''
负责下载数据,并且将数据返回
'''
response = urllib.request.urlopen(request)
html = response.read().decode('gbk')
return html
def handle_data(self, data):
'''
开始处理数据,将段子抓取出来并且写入文件
'''
# 这个必须使用多行模式进行抓取,因为是抓取多个a链接
pattern = re.compile(r'<a href="(.*?)" class="main_14" target="_blank">(.*?)</a>', re.M)
# 找到所有的笑话链接
alist = pattern.findall(data)
# print(alist)
# exit()
print('开始下载')
for smile in alist:
# 获取标题
# title = alist[14][1]
title = smile[1]
# 获取url
# smile_url = alist[14][0]
smile_url = smile[0]
# 获取内容
content = self.handle_content(smile_url)
# 将抓取的这一页的笑话写到文件中
with open('xiaohua.html', 'a', encoding='gbk') as f:
f.write('<h1>' + title + '</h1>' + content)
print('下载完毕')
def handle_content(self, smile_url):
# 因为有的href中有中文,所以必须先转码再拼接,如果先拼接再转码,就会将:也给转码了,不符合要求
smile_url = urllib.parse.quote(smile_url)
smile_url = 'http://www.jokeji.cn' + smile_url
# print(smile_url)
# exit()
content = self.xiazai(smile_url)
# 由于抓取的文本中,有的中间有空格,所以使用单行模式进行抓取
pattern = re.compile(r'<span id="text110">(.*?)</span>', re.S)
ret = pattern.search(content)
return ret.group(1)
def start(self):
request = self.handle_url()
html = self.xiazai(request)
self.handle_data(html)
if __name__ == '__main__':
url = 'http://www.jokeji.cn/hot.asp'
spider = SmileSpider(url)
spider.start()
57.href 中有中文的需要先进行转码,然后再拼接
smile_url = urllib.parse.quote(smile_url)
smile_url = 'http://www.jokeji.cn' + smile_url
58.导入 etree
from lxml import etree
59.实例化一个 html 对象,DOM模型
etree.HTML(通过requests库的get方法或post方法获取的信息 其实就是 HTML 代码)
例:html_tree = etree.HTML(text)
返回值为 <Element html at 0x26ee35b2400>
例:type(html_tree)
<class 'lxml.etree._Element'>
60.查找所有的 li 标签
html_tree.xpath('//li')
61.获取所有li下面a中属性href为link1.html的a
result = html_tree.xpath('//标签/标签[@属性="值"]')
例:result = html_tree.xpath('//li/a[@href="link.html"]')
62.获取最后一个 li 标签下 a 标签下面的 href 值
result = html_tree.xpath('//li[last()]/a/@href')
63.获取 class 为 temp 的结点
result = html_tree.xpath('//*[@class = "temp"]')
64.获取所有 li 标签下的 class 属性
result = html_tree.xpath('//li/@class')
65.取出内容
[0].text
例:result = html_tree.xpath('//li[@class="popo"]/a')[0].text
例:result = html_tree.xpath('//li[@class="popo"]/a/text()')
66.将 tree 对象转化为字符串
etree.tostring(etree.HTML对象).decode('utf-8')
例:
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
tostring 转换的是bytes 类型数据
result = etree.tostring(html)
将 bytes 类型数据转换为 str 类型数据
print(result.decode('utf-8'))
67.动态保存图片,使用url后几位作为文件名
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html_tree = etree.HTML(html)
img_list = html_tree.xpath('//div[@class="box picblock col3"]/div/a/img/@src2')
for img_url in img_list:
# 定制图片名字为url后10位
file_name = 'image/' + img_url[-10:]
load_image(img_url, file_name)
load_image内容:
def load_image(url, file_name):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
image_bytes = response.read()
with open(file_name, 'wb') as f:
f.write(image_bytes)
print(file_name + '图片已经成功下载完毕')
例:
def load_page(url):
headers = {
#'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
print(url)
# exit()
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html = response.read()
# 这是专业的图片网站,使用了懒加载,但是可以通过源码来进行查看,并且重新写xpath路径
with open('7image.html', 'w', encoding='utf-8') as f:
f.write(html.decode('utf-8'))
exit()
# 将html文档解析问DOM模型
html_tree = etree.HTML(html)
# 通过xpath,找到需要的所有的图片的src属性,这里获取到的
img_list = html_tree.xpath('//div[@class="box picblock col3"]/div/a/img/@src2')
for img_url in img_list:
# 定制图片名字为url后10位
file_name = 'image/' + img_url[-10:]
load_image(img_url, file_name)
def load_image(url, file_name):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
image_bytes = response.read()
with open(file_name, 'wb') as f:
f.write(image_bytes)
print(file_name + '图片已经成功下载完毕')
def main():
start = int(input('请输入开始页面:'))
end = int(input('请输入结束页面:'))
url = 'http://sc.chinaz.com/tag_tupian/'
for page in range(start, end + 1):
if page == 1:
real_url = url + 'KaTong.html'
else:
real_url = url + 'KaTong_' + str(page) + '.html'
load_page(real_url)
print('第' + str(page) + '页下载完毕')
if __name__ == '__main__':
main()
68.懒图片加载案例
例:
import urllib.request
from lxml import etree
import json
def handle_tree(html_tree):
node_list = html_tree.xpath('//div[@class="detail-wrapper"]')
duan_list = []
for node in node_list:
# 获取所有的用户名,因为该xpath获取的是一个span列表,然后获取第一个,并且通过text属性得到其内容
user_name = node.xpath('./div[contains(@class, "header")]/a/div/span[@class="name"]')[0].text
# 只要涉及到图片,很有可能都是懒加载,所以要右键查看网页源代码,才能得到真实的链接
# 由于这个获取的结果就是属性字符串,所以只需要加上下标0即可
face = node.xpath('./div[contains(@class, "header")]//img/@data-src')[0]
# .代表当前,一个/表示一级子目录,两个//代表当前节点里面任意的位置查找
content = node.xpath('./div[@class="content-wrapper"]//p')[0].text
zan = node.xpath('./div[@class="options"]//li[@class="digg-wrapper "]/span')[0].text
item = {
'username':user_name,
'face':face,
'content':content,
'zan':zan,
}
# 将其存放到列表中
duan_list.append(item)
# 将列表写入到文件中
with open('8duanzi.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(duan_list, ensure_ascii=False) + '\n')
print('over')
def main():
# 爬取百度贴吧,不能加上headers,加上headers爬取不下来
url = 'http://neihanshequ.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
html_bytes = response.read()
# fp = open('8tieba.html', 'w', encoding='utf-8')
# fp.write(html_bytes.decode('utf-8'))
# fp.close()
# exit()
# 将html字节串转化为html文档树
# 文档树有xpath方法,文档节点也有xpath方法
# 【注】不能使用字节串转化为文档树,这样会有乱码
html_tree = etree.HTML(html_bytes.decode('utf-8'))
handle_tree(html_tree)
if __name__ == '__main__':
main()
69. . / 和 // 在 xpath 中的使用
.代表当前目录
/ 表示一级子目录
// 代表当前节点里面任意的位置
70.获取内容的示范
获取内容时,如果为字符串,则不需要使用 text 只需要写[0]
face = node.xpath('./div[contains(@class, "header")]//img/@data-src')[0]
div 下 class 为 "content-wrapper" 的所有 p 标签内容
content = node.xpath('./div[@class="content-wrapper"]//p')[0].text
div 下 class 为 "options" 的所有 li 标签下 class为 "digg-wrapper" 的所有 span 标签内容
zan = node.xpath('./div[@class="options"]//li[@class="digg-wrapper"]/span')[0].text
71.将json对象转化为json格式字符串
f.write(json.dumps(duan_list, ensure_ascii=False) + '\n')
72.正则获取 div 下的内容
1.获取 div 到 img 之间的数据
2.img 下 src 的数据
3.img 下 alt 的数据
4.一直到 div 结束的数据
pattern = re.compile(r'<div class="thumb">(.*?)<img src=(.*?) alt=(.*?)>(.*?)</div>', re.S)
pattern.方法 ,参考上面的正则
73.带有参数的 get 方式
import requests
params = {
'wd':'中国'
}
r = requests.get('http://www.baidu.com/s?', headers=headers, params=params)
requests.get 还可以添加 cookie 参数
74.设置编码
r.encoding='utf-8
75.查看所有头信息
r.request.headers
76.在 requests.get 方法中 url,params,headers,proxies 为参数
url 网址 params 需要的数据 headers 头部 proxies 代理
77.通过 Session 对象,发送请求
s = requests.Session()
78.发送请求
s.post(url,data,headers)
79.接收请求
s.get(url[,proxies])
80.当返回为 json 样式时
例:
city = input('请输入要查询的城市:')
params = {
'city':city
}
r = requests.get(url, params=params)
r.json() 会打印出响应的内容
81.BeautifulSoup 创建对象
from bs4 import BeautifulSoup
soup = BeautifulSoup(open(url,encoding='utf-8),'lxml')
82.查找第一个<title> 标签
soup.title
返回值为 <title>三国猛将</title>
83.查找第一个 a 标签
soup.a
返回值为 <a class="aa" href="http://www.baidu.com" title="baidu">百度</a>
84.查找第一个 ul 标签
soup.ul
85.查看标签名字
a_tag = soup.a
a_tag.name
返回值为 a
86.查看标签内容
a_tag.attrs
返回值为 {'href': 'http://www.baidu.com', 'title': 'baidu', 'class': ['aa']}
87.获取找到的 a 标签的 href 内容(第一个 a)
soup.a.get('href')
返回值为 http://www.baidu.com
88.获取 a 标签下的 title 属性(第一个 a)
soup.a.get('title')
返回值为 baidu
89.查看 a 标签下的内容
soup.标签.string 标签还可以是 head、title等
soup.a.string
返回值为 百度
90.获取 p 标签下的内容
soup.p.string
91.查看 div 的内容,包含 '\n'
soup.div.contents
返回值为
['\n', <div class="div">
<a class="la" href="www.nihao.com">你好</a>
</div>, '\n', <div>
<a href="www.hello.com">世界</a>
</div>, '\n']
92.查看使用的字符集
soup.div.contents[1]
返回值为 <meta charset="utf-8"/>
93.查看body的子节点
soup.标签.children
例:soup.body.children
返回值是一个迭代对象,需要遍历输出
返回值为 <list_iterator object at 0x0000021863886C10>
for child in soup.body.children:
print(child)
返回值为 body 中的所有内容
94.查看所有的子孙节点
soup.标签.descendants
例:soup.div.descendants
返回值为
<div class="div">
<a class="la" href="www.nihao.com">你好</a>
</div>
<a class="la" href="www.nihao.com">你好</a>
你好
95.查看所有的 a 标签
soup.find_all('a')
返回值为 包含所有的 a 标签的列表
96.查看 a 标签中第二个链接的内容
soup.find_all('a')[1].string
97.查看 a 标签中第二个链接的href值
soup.find_all('a')[1].href
98.将 re 正则嵌入进来,找寻所有以 b 开头的标签
soup.findall(re.compile('^b'))
返回值为 <body>标签 <b>
99.找到所有的 a 标签和 b 标签
soup.findall(re.compile(['a','b']))
返回值为 <a> 和 <b> 标签
100.通过标签名获取所有的 a 标签
soup.select('a')
返回值为 所有的 <a> 标签
101.通过 类名 获取标签(在 class 等于的值前面加 .)
soup.select('.aa')
返回值为 class='aa' 的标签
102.通过 id 名获取标签(在 id 等于的值前面加 #)
soup.select('#wangyi')
返回值为 id='wangyi'的标签
103.查看 div 下 class='aa' 的标签
soup.select('标签 .class 等于的值')
soup.select('div .aa')
104.查看 div 下,第一层 class='aa' 的标签
soup.select('.标签名 > .class= 的值')
soup.select('.div > .la')
105.根据属性进行查找,input 标签下class为 haha 的标签
soup.select('input[class="haha"]')
例:
import requests
from bs4 import BeautifulSoup
import json
import lxml
def load_url(jl, kw):
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
}
url = 'http://sou.zhaopin.com/jobs/searchresult.ashx?'
params = {
'jl':jl,
'kw':kw,
}
# 自动完成转码,直接使用即可
r = requests.get(url, params=params, headers=headers)
handle_data(r.text)
def handle_data(html):
# 创建soup对象
soup = BeautifulSoup(html, 'lxml')
# 查找职位名称
job_list = soup.select('#newlist_list_content_table table')
# print(job_list)
jobs = []
i = 1
for job in job_list:
# 因为第一个table只是表格的标题,所以要过滤掉
if i == 1:
i = 0
continue
item = {}
# 公司名称
job_name = job.select('.zwmc div a')[0].get_text()
# 职位月薪
company_name = job.select('.gsmc a')[0].get_text()
# 工作地点
area = job.select('.gzdd')[0].get_text()
# 发布日期
time = job.select('.gxsj span')[0].get_text()
# 将所有信息添加到字典中
item['job_name'] = job_name
item['company_name'] = company_name
item['area'] = area
item['time'] = time
jobs.append(item)
# 将列表转化为json格式字符串,然后写入到文件中
content = json.dumps(jobs, ensure_ascii=False)
with open('python.json', 'w', encoding='utf-8') as f:
f.write(content)
print('over')
def main():
# jl = input('请输入工作地址:')
# kw = input('请输入工作职位:')
load_url(jl='北京', kw='python')
if __name__ == '__main__':
main()
106.将字典进行 json 转换为
import json
str_dict = {"name":"张三", "age":55, "height":180}
print(json.dumps(str_dict, ensure_ascii=False))
使用 ensure_ascii 输出则为 utf-8 编码
107.读取转换的对象,(注意 loads 和 load 方法)
json.loads(json.dumps 对象)
string = json.dumps(str_dict, ensure_ascii=False)
json.loads(string)
{"name":"张三", "age":55, "height":180}
108.将对象序列化之后写入文件
json.dump(字典对象,open(文件名.json,'w',encoding='utf-8,ensure_ascii=False))
json.dump(str_dict, open('jsontest.json', 'w', encoding='utf-8'), ensure_ascii=False)
109.转换本地的 json 文件转换为 python 对象
json.load(open('文件名.json',encoding='utf-8))
110.jsonpath 示例:
book.json文件
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
import json
import jsonpath
obj = json.load(open('book.json', encoding='utf-8'))
所有book
book = jsonpath.jsonpath(obj, '$..book')
print(book)
所有book中的所有作者
authors = jsonpath.jsonpath(obj, '$..book..author')
print(authors)
book中的前两本书 '$..book[:2]'
book中的最后两本书 '$..book[-2:]'
book = jsonpath.jsonpath(obj, '$..book[0,1]')
print(book)
所有book中,有属性isbn的书籍
book = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
print(book)
所有book中,价格小于10的书籍
book = jsonpath.jsonpath(obj, '$.store.book[?(@.price<10)]')
print(book)
numpy第三方库
# 导入numpy 并赋予别名 np
import numpy as np
# 创建数组的常用的几种方式(列表,元组,range,arange,linspace(创建的是等差数组),zeros(全为 0 的数组),ones(全为 1 的数组),logspace(创建的是对数数组))
# 列表方式
np.array([1,2,3,4])
# array([1, 2, 3, 4])
# 元组方式
np.array((1,2,3,4))
# array([1, 2, 3, 4])
# range 方式
np.array(range(4)) # 不包含终止数字
# array([0, 1, 2, 3])
# 使用 arange(初始位置=0,末尾,步长=1)
# 不包含末尾元素
np.arange(1,8,2)
# array([1, 3, 5, 7])
np.arange(8)
# array([0, 1, 2, 3, 4, 5, 6, 7])
# 使用 linspace(起始数字,终止数字,包含数字的个数[,endpoint = False]) 生成等差数组
# 生成等差数组,endpoint 为 True 则包含末尾数字
np.linspace(1,3,4,endpoint=False)
# array([1. , 1.5, 2. , 2.5])
np.linspace(1,3,4,endpoint=True)
# array([1. , 1.66666667, 2.33333333, 3. ])
# 创建全为零的一维数组
np.zeros(3)
# 创建全为一的一维数组
np.ones(4)
# array([1., 1., 1., 1.])
np.linspace(1,3,4)
# array([1. , 1.66666667, 2.33333333, 3. ])
# np.logspace(起始数字,终止数字,数字个数,base = 10) 对数数组
np.logspace(1,3,4)
# 相当于 10 的 linspace(1,3,4) 次方
# array([ 10. , 46.41588834, 215.443469 , 1000. ])
np.logspace(1,3,4,base = 2)
# array([2. , 3.1748021, 5.0396842, 8. ])
# 创建二维数组(列表嵌套列表)
np.array([[1,2,3],[4,5,6]])
'''
array([[1, 2, 3],
[4, 5, 6]])
'''
# 创建全为零的二维数组
# 两行两列
np.zeros((2,2))
'''
array([[0., 0.],
[0., 0.]])
'''
# 三行三列
np.zeros((3,2))
'''
array([[0., 0.],
[0., 0.],
[0., 0.]])
'''
# 创建一个单位数组
np.identity(3)
'''
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
'''
# 创建一个对角矩阵,(参数为对角线上的数字)
np.diag((1,2,3))
'''
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
'''
import numpy as np
x = np.arange(8)
# [0 1 2 3 4 5 6 7]
# 在数组尾部追加一个元素
np.append(x,10)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 10])
# 在数组尾部追加多个元素
np.append(x,[15,16,17])
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 15, 16, 17])
# 使用 数组下标修改元素的值
x[0] = 99
# array([99, 1, 2, 3, 4, 5, 6, 7])
# 在指定位置插入数据
np.insert(x,0,54)
# array([54, 99, 1, 2, 3, 4, 5, 6, 7])
# 创建一个多维数组
x = np.array([[1,2,3],[11,22,33],[111,222,333]])
'''
array([[ 1, 2, 3],
[ 11, 22, 33],
[111, 222, 333]])
'''
# 修改第 0 行第 2 列的元素值
x[0,2] = 9
'''
array([[ 1, 2, 9],
[ 11, 22, 33],
[111, 222, 333]])
'''
# 行数大于等于 1 的,列数大于等于 1 的置为 1
x[1:,1:] = 1
'''
array([[ 1, 2, 9],
[ 11, 1, 1],
[111, 1, 1]])
'''
# 同时修改多个元素值
x[1:,1:] = [7,8]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 7, 8]])
'''
x[1:,1:] = [[7,8],[9,10]]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 9, 10]])
'''
import numpy as np
n = np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 查看数组的大小
n.size
# 10
# 将数组分为两行五列
n.shape = 2,5
'''
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
'''
# 显示数组的维度
n.shape
# (2, 5)
# 设置数组的维度,-1 表示自动计算
n.shape = 5,-1
'''
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
'''
# 将新数组设置为调用数组的两行五列并返回
x = n.reshape(2,5)
'''
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
'''
x = np.arange(5)
# 将数组设置为两行,没有数的设置为 0
x.resize((2,10))
'''
array([[0, 1, 2, 3, 4, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
'''
# 将 x 数组的两行五列形式显示,不改变 x 的值
np.resize(x,(2,5))
'''
array([[0, 1, 2, 3, 4],
[0, 0, 0, 0, 0]])
'''
import numpy as np
n = np.array(([1,2,3],[4,5,6],[7,8,9]))
'''
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
'''
# 第一行元素
n[0]
# array([1, 2, 3])
# 第一行第三列元素
n[0,2]
# 3
# 第一行和第二行的元素
n[[0,1]]
'''
array([[1, 2, 3],
[4, 5, 6]])
'''
# 第一行第三列,第三行第二列,第二行第一列
n[[0,2,1],[2,1,0]]
# array([3, 8, 4])
a = np.arange(8)
# array([0, 1, 2, 3, 4, 5, 6, 7])
# 将数组倒序
a[::-1]
# array([7, 6, 5, 4, 3, 2, 1, 0])
# 步长为 2
a[::2]
# array([0, 2, 4, 6])
# 从 0 到 4 的元素
a[:5]
# array([0, 1, 2, 3, 4])
c = np.arange(16)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
c.shape = 4,4
'''
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
'''
# 第一行,第三个元素到第五个元素(如果没有则输出到末尾截止)
c[0,2:5]
# array([2, 3])
# 第二行元素
c[1]
# array([4, 5, 6, 7])
# 第三行到第六行,第三列到第六列
c[2:5,2:5]
'''
array([[10, 11],
[14, 15]])
'''
# 第二行第三列元素和第三行第四列元素
c[[1,2],[2,3]]
# array([ 6, 11])
# 第一行和第三行的第二列到第三列的元素
c[[0,2],1:3]
'''
array([[ 1, 2],
[ 9, 10]])
'''
# 第一列和第三列的所有横行元素
c[:,[0,2]]
'''
array([[ 0, 2],
[ 4, 6],
[ 8, 10],
[12, 14]])
'''
# 第三列所有元素
c[:,2]
# array([ 2, 6, 10, 14])
# 第二行和第四行的所有元素
c[[1,3]]
'''
array([[ 4, 5, 6, 7],
[12, 13, 14, 15]])
'''
# 第一行的第二列,第四列元素,第四行的第二列,第四列元素
c[[0,3]][:,[1,3]]
'''
array([[ 1, 3],
[13, 15]])
'''
import numpy as np
x = np.array((1,2,3,4,5))
# 使用 * 进行相乘
x*2
# array([ 2, 4, 6, 8, 10])
# 使用 / 进行相除
x / 2
# array([0.5, 1. , 1.5, 2. , 2.5])
2 / x
# array([2. , 1. , 0.66666667, 0.5 , 0.4 ])
# 使用 // 进行整除
x//2
# array([0, 1, 1, 2, 2], dtype=int32)
10//x
# array([10, 5, 3, 2, 2], dtype=int32)
# 使用 ** 进行幂运算
x**3
# array([ 1, 8, 27, 64, 125], dtype=int32)
2 ** x
# array([ 2, 4, 8, 16, 32], dtype=int32)
# 使用 + 进行相加
x + 2
# array([3, 4, 5, 6, 7])
# 使用 % 进行取模
x % 3
# array([1, 2, 0, 1, 2], dtype=int32)
# 数组与数组之间的运算
# 使用 + 进行相加
np.array([1,2,3,4]) + np.array([11,22,33,44])
# array([12, 24, 36, 48])
np.array([1,2,3,4]) + np.array([3])
# array([4, 5, 6, 7])
n = np.array((1,2,3))
# +
n + n
# array([2, 4, 6])
n + np.array([4])
# array([5, 6, 7])
# *
n * n
# array([1, 4, 9])
n * np.array(([1,2,3],[4,5,6],[7,8,9]))
'''
array([[ 1, 4, 9],
[ 4, 10, 18],
[ 7, 16, 27]])
'''
# -
n - n
# array([0, 0, 0])
# /
n/n
# array([1., 1., 1.])
# **
n**n
# array([ 1, 4, 27], dtype=int32)
x = np.array((1,2,3))
y = np.array((4,5,6))
# 数组的内积运算(对应位置上元素相乘)
np.dot(x,y)
# 32
sum(x*y)
# 32
# 布尔运算
n = np.random.rand(4)
# array([0.53583849, 0.09401473, 0.07829069, 0.09363152])
# 判断数组中的元素是否大于 0.5
n > 0.5
# array([ True, False, False, False])
# 将数组中大于 0.5 的元素显示
n[n>0.5]
# array([0.53583849])
# 找到数组中 0.05 ~ 0.4 的元素总数
sum((n > 0.05)&(n < 0.4))
# 3
# 是否都大于 0.2
np.all(n > 0.2)
# False
# 是否有元素小于 0.1
np.any(n < 0.1)
# True
# 数组与数组之间的布尔运算
a = np.array([1,4,7])
# array([1, 4, 7])
b = np.array([4,3,7])
# array([4, 3, 7])
# 在 a 中是否有大于 b 的元素
a > b
# array([False, True, False])
# 在 a 中是否有等于 b 的元素
a == b
# array([False, False, True])
# 显示 a 中 a 的元素等于 b 的元素
a[a == b]
# array([7])
# 显示 a 中的偶数且小于 5 的元素
a[(a%2 == 0) & (a < 5)]
# array([4])
import numpy as np
# 将 0~100 10等分
x = np.arange(0,100,10)
# array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
# 每个数组元素对应的正弦值
np.sin(x)
'''
array([ 0. , -0.54402111, 0.91294525, -0.98803162, 0.74511316,
-0.26237485, -0.30481062, 0.77389068, -0.99388865, 0.89399666])
'''
# 每个数组元素对应的余弦值
np.cos(x)
'''
array([ 1. , -0.83907153, 0.40808206, 0.15425145, -0.66693806,
0.96496603, -0.95241298, 0.6333192 , -0.11038724, -0.44807362])
'''
# 对参数进行四舍五入
np.round(np.cos(x))
# array([ 1., -1., 0., 0., -1., 1., -1., 1., -0., -0.])
# 对参数进行上入整数 3.3->4
np.ceil(x/3)
# array([ 0., 4., 7., 10., 14., 17., 20., 24., 27., 30.])
# 分段函数
x = np.random.randint(0,10,size=(1,10))
# array([[0, 3, 6, 7, 9, 4, 9, 8, 1, 8]])
# 大于 4 的置为 0
np.where(x > 4,0,1)
# array([[1, 1, 0, 0, 0, 1, 0, 0, 1, 0]])
# 小于 4 的乘 2 ,大于 7 的乘3
np.piecewise(x,[x<4,x>7],[lambda x:x*2,lambda x:x*3])
# array([[ 0, 6, 0, 0, 27, 0, 27, 24, 2, 24]])
import numpy as np
x = np.array([1,4,5,2])
# array([1, 4, 5, 2])
# 返回排序后元素的原下标
np.argsort(x)
# array([0, 3, 1, 2], dtype=int64)
# 输出最大值的下标
x.argmax( )
# 2
# 输出最小值的下标
x.argmin( )
# 0
# 对数组进行排序
x.sort( )
import numpy as np
# 生成一个随机数组
np.random.randint(0,6,3)
# array([1, 1, 3])
# 生成一个随机数组(二维数组)
np.random.randint(0,6,(3,3))
'''
array([[4, 4, 1],
[2, 1, 0],
[5, 0, 0]])
'''
# 生成十个随机数在[0,1)之间
np.random.rand(10)
'''
array([0.9283789 , 0.43515554, 0.27117021, 0.94829333, 0.31733981,
0.42314939, 0.81838647, 0.39091899, 0.33571004, 0.90240897])
'''
# 从标准正态分布中随机抽选出3个数
np.random.standard_normal(3)
# array([0.34660435, 0.63543859, 0.1307822 ])
# 返回三页四行两列的标准正态分布数
np.random.standard_normal((3,4,2))
'''
array([[[-0.24880261, -1.17453957],
[ 0.0295264 , 1.04038047],
[-1.45201783, 0.57672288],
[ 1.10282747, -2.08699482]],
[[-0.3813943 , 0.47845782],
[ 0.97708005, 1.1760147 ],
[ 1.3414987 , -0.629902 ],
[-0.29780567, 0.60288726]],
[[ 1.43991349, -1.6757028 ],
[-1.97956809, -1.18713495],
[-1.39662811, 0.34174275],
[ 0.56457553, -0.83224426]]])
'''
# 创建矩阵
import numpy as np
x = np.matrix([[1,2,3],[4,5,6]])
'''
matrix([[1, 2, 3],
[4, 5, 6]])
'''
y = np.matrix([1,2,3,4,5,6])
# matrix([[1, 2, 3, 4, 5, 6]])
# x 的第二行第二列元素
x[1,1]
# 5
# 矩阵的函数
import numpy as np
# 矩阵的转置
x = np.matrix([[1,2,3],[4,5,6]])
'''
matrix([[1, 2, 3],
[4, 5, 6]])
'''
y = np.matrix([1,2,3,4,5,6])
# matrix([[1, 2, 3, 4, 5, 6]])
# 实现矩阵的转置
x.T
'''
matrix([[1, 4],
[2, 5],
[3, 6]])
'''
y.T
'''
matrix([[1],
[2],
[3],
[4],
[5],
[6]])
'''
# 元素平均值
x.mean()
# 3.5
# 纵向平均值
x.mean(axis = 0)
# matrix([[2.5, 3.5, 4.5]])
# 横向平均值
x.mean(axis = 1)
'''
matrix([[2.],
[5.]])
'''
# 所有元素之和
x.sum()
# 21
# 横向最大值
x.max(axis = 1)
'''
matrix([[3],
[6]])
'''
# 横向最大值的索引下标
x.argmax(axis = 1)
'''
matrix([[2],
[2]], dtype=int64)
'''
# 对角线元素
x.diagonal()
# matrix([[1, 5]])
# 非零元素下标
x.nonzero()
# (array([0, 0, 0, 1, 1, 1], dtype=int64),
# array([0, 1, 2, 0, 1, 2], dtype=int64))
# 矩阵的运算
import numpy as np
x = np.matrix([[1,2,3],[4,5,6]])
'''
matrix([[1, 2, 3],
[4, 5, 6]])
'''
y = np.matrix([[1,2],[4,5],[7,8]])
'''
matrix([[1, 2],
[4, 5],
[7, 8]])
'''
# 矩阵的乘法
x*y
'''
matrix([[30, 36],
[66, 81]])
'''
# 相关系数矩阵,可使用在列表元素数组矩阵
# 负相关
np.corrcoef([1,2,3],[8,5,4])
'''
array([[ 1. , -0.96076892],
[-0.96076892, 1. ]])
'''
# 正相关
np.corrcoef([1,2,3],[4,5,7])
'''
array([[1. , 0.98198051],
[0.98198051, 1. ]])
'''
# 矩阵的方差
np.cov([1,1,1,1,1])
# array(0.)
# 矩阵的标准差
np.std([1,1,1,1,1])
# 0.0
x = [-2.1,-1,4.3]
y = [3,1.1,0.12]
# 垂直堆叠矩阵
z = np.vstack((x,y))
'''
array([[-2.1 , -1. , 4.3 ],
[ 3. , 1.1 , 0.12]])
'''
# 矩阵的协方差
np.cov(z)
'''
array([[11.71 , -4.286 ],
[-4.286 , 2.14413333]])
'''
np.cov(x,y)
'''
array([[11.71 , -4.286 ],
[-4.286 , 2.14413333]])
'''
# 标准差
np.std(z)
# 2.2071223094538484
# 列向标准差
np.std(z,axis = 1)
# array([2.79404128, 1.19558447])
# 方差
np.cov(x)
# array(11.71)
# 特征值和特征向量
A = np.array([[1,-3,3],[3,-5,3],[6,-6,4]])
'''
array([[ 1, -3, 3],
[ 3, -5, 3],
[ 6, -6, 4]])
'''
e,v = np.linalg.eig(A)
# e 为特征值, v 为特征向量
'''
e
array([ 4.+0.00000000e+00j, -2.+1.10465796e-15j, -2.-1.10465796e-15j])
v
array([[-0.40824829+0.j , 0.24400118-0.40702229j,
0.24400118+0.40702229j],
[-0.40824829+0.j , -0.41621909-0.40702229j,
-0.41621909+0.40702229j],
[-0.81649658+0.j , -0.66022027+0.j ,
-0.66022027-0.j ]])
'''
# 矩阵与特征向量的乘积
np.dot(A,v)
'''
array([[-1.63299316+0.00000000e+00j, -0.48800237+8.14044580e-01j,
-0.48800237-8.14044580e-01j],
[-1.63299316+0.00000000e+00j, 0.83243817+8.14044580e-01j,
0.83243817-8.14044580e-01j],
[-3.26598632+0.00000000e+00j, 1.32044054-5.55111512e-16j,
1.32044054+5.55111512e-16j]])
'''
# 特征值与特征向量的乘积
e * v
'''
array([[-1.63299316+0.00000000e+00j, -0.48800237+8.14044580e-01j,
-0.48800237-8.14044580e-01j],
[-1.63299316+0.00000000e+00j, 0.83243817+8.14044580e-01j,
0.83243817-8.14044580e-01j],
[-3.26598632+0.00000000e+00j, 1.32044054-7.29317578e-16j,
1.32044054+7.29317578e-16j]])
'''
# 验证两个乘积是否相等
np.isclose(np.dot(A,v),(e * v))
'''
array([[ True, True, True],
[ True, True, True],
[ True, True, True]])
'''
# 行列式 |A - λE| 的值应为 0
np.linalg.det(A-np.eye(3,3)*e)
# 5.965152994198125e-14j
x = np.matrix([[1,2,3],[4,5,6],[7,8,0]])
'''
matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 0]])
'''
# 逆矩阵
y = np.linalg.inv(x)
'''
matrix([[-1.77777778, 0.88888889, -0.11111111],
[ 1.55555556, -0.77777778, 0.22222222],
[-0.11111111, 0.22222222, -0.11111111]])
注:numpy.linalg.LinAlgError: Singular matrix 矩阵不存在逆矩阵
'''
# 矩阵的乘法
x * y
'''
matrix([[ 1.00000000e+00, 5.55111512e-17, 1.38777878e-17],
[ 5.55111512e-17, 1.00000000e+00, 2.77555756e-17],
[ 1.77635684e-15, -8.88178420e-16, 1.00000000e+00]])
'''
y * x
'''
matrix([[ 1.00000000e+00, -1.11022302e-16, 0.00000000e+00],
[ 8.32667268e-17, 1.00000000e+00, 2.22044605e-16],
[ 6.93889390e-17, 0.00000000e+00, 1.00000000e+00]])
'''
# 求解线性方程组
a = np.array([[3,1],[1,2]])
'''
array([[3, 1],
[1, 2]])
'''
b = np.array([9,8])
# array([9, 8])
# 求解
x = np.linalg.solve(a,b)
# array([2., 3.])
# 验证
np.dot(a,x)
# array([9., 8.])
# 最小二乘解:返回解,余项,a 的秩,a 的奇异值
np.linalg.lstsq(a,b)
# (array([2., 3.]), array([], dtype=float64), 2, array([3.61803399, 1.38196601]))
# 计算向量和矩阵的范数
x = np.matrix([[1,2],[3,-4]])
'''
matrix([[ 1, 2],
[ 3, -4]])
'''
np.linalg.norm(x)
# 5.477225575051661
np.linalg.norm(x,-2)
# 1.9543950758485487
np.linalg.norm(x,-1)
# 4.0
np.linalg.norm(x,1)
# 6.0
np.linalg.norm([1,2,0,3,4,0],0)
# 4.0
np.linalg.norm([1,2,0,3,4,0],2)
# 5.477225575051661
# 奇异值分解
a = np.matrix([[1,2,3],[4,5,6],[7,8,9]])
'''
matrix([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
'''
u,s,v = np.linalg.svd(a)
u
'''
matrix([[-0.21483724, 0.88723069, 0.40824829],
[-0.52058739, 0.24964395, -0.81649658],
[-0.82633754, -0.38794278, 0.40824829]])
'''
s
'''
array([1.68481034e+01, 1.06836951e+00, 4.41842475e-16])
'''
v
'''
matrix([[-0.47967118, -0.57236779, -0.66506441],
[-0.77669099, -0.07568647, 0.62531805],
[-0.40824829, 0.81649658, -0.40824829]])
'''
# 验证
u * np.diag(s) * v
'''
matrix([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
'''
pandas第三方库
# 一维数组与常用操作
import pandas as pd
# 设置输出结果列对齐
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
# 创建 从 0 开始的非负整数索引
s1 = pd.Series(range(1,20,5))
'''
0 1
1 6
2 11
3 16
dtype: int64
'''
# 使用字典创建 Series 字典的键作为索引
s2 = pd.Series({'语文':95,'数学':98,'Python':100,'物理':97,'化学':99})
'''
语文 95
数学 98
Python 100
物理 97
化学 99
dtype: int64
'''
# 修改 Series 对象的值
s1[3] = -17
'''
0 1
1 6
2 11
3 -17
dtype: int64
'''
s2['语文'] = 94
'''
语文 94
数学 98
Python 100
物理 97
化学 99
dtype: int64
'''
# 查看 s1 的绝对值
abs(s1)
'''
0 1
1 6
2 11
3 17
dtype: int64
'''
# 将 s1 所有的值都加 5
s1 + 5
'''
0 6
1 11
2 16
3 -12
dtype: int64
'''
# 在 s1 的索引下标前加入参数值
s1.add_prefix(2)
'''
20 1
21 6
22 11
23 -17
dtype: int64
'''
# s2 数据的直方图
s2.hist()
# 每行索引后面加上 hany
s2.add_suffix('hany')
'''
语文hany 94
数学hany 98
Pythonhany 100
物理hany 97
化学hany 99
dtype: int64
'''
# 查看 s2 中最大值的索引
s2.argmax()
# 'Python'
# 查看 s2 的值是否在指定区间内
s2.between(90,100,inclusive = True)
'''
语文 True
数学 True
Python True
物理 True
化学 True
dtype: bool
'''
# 查看 s2 中 97 分以上的数据
s2[s2 > 97]
'''
数学 98
Python 100
化学 99
dtype: int64
'''
# 查看 s2 中大于中值的数据
s2[s2 > s2.median()]
'''
Python 100
化学 99
dtype: int64
'''
# s2 与数字之间的运算,开平方 * 10 保留一位小数
round((s2**0.5)*10,1)
'''
语文 97.0
数学 99.0
Python 100.0
物理 98.5
化学 99.5
dtype: float64
'''
# s2 的中值
s2.median()
# 98.0
# s2 中最小的两个数
s2.nsmallest(2)
'''
语文 94
物理 97
dtype: int64
'''
# s2 中最大的两个数
s2.nlargest(2)
'''
Python 100
化学 99
dtype: int64
'''
# Series 对象之间的运算,对相同索引进行计算,不是相同索引的使用 NaN
pd.Series(range(5)) + pd.Series(range(5,10))
'''
0 5
1 7
2 9
3 11
4 13
dtype: int64
'''
# pipe 对 Series 对象使用匿名函数
pd.Series(range(5)).pipe(lambda x,y,z :(x**y)%z,2,5)
'''
0 0
1 1
2 4
3 4
4 1
dtype: int64
'''
pd.Series(range(5)).pipe(lambda x:x+3)
'''
0 3
1 4
2 5
3 6
4 7
dtype: int64
'''
pd.Series(range(5)).pipe(lambda x:x+3).pipe(lambda x:x*3)
'''
0 9
1 12
2 15
3 18
4 21
dtype: int64
'''
# 对 Series 对象使用匿名函数
pd.Series(range(5)).apply(lambda x:x+3)
'''
0 3
1 4
2 5
3 6
4 7
dtype: int64
'''
# 查看标准差
pd.Series(range(0,5)).std()
# 1.5811388300841898
# 查看无偏方差
pd.Series(range(0,5)).var()
# 2.5
# 查看无偏标准差
pd.Series(range(0,5)).sem()
# 0.7071067811865476
# 查看是否存在等价于 True 的值
any(pd.Series([3,0,True]))
# True
# 查看是否所有的值都等价于 True
all(pd.Series([3,0,True]))
# False
# 时间序列和常用操作
import pandas as pd
# 每隔五天--5D
pd.date_range(start = '20200101',end = '20200131',freq = '5D')
'''
DatetimeIndex(['2020-01-01', '2020-01-06', '2020-01-11', '2020-01-16',
'2020-01-21', '2020-01-26', '2020-01-31'],
dtype='datetime64[ns]', freq='5D')
'''
# 每隔一周--W
pd.date_range(start = '20200301',end = '20200331',freq = 'W')
'''
DatetimeIndex(['2020-03-01', '2020-03-08', '2020-03-15', '2020-03-22',
'2020-03-29'],
dtype='datetime64[ns]', freq='W-SUN')
'''
# 间隔两天,五个数据
pd.date_range(start = '20200301',periods = 5,freq = '2D')
'''
DatetimeIndex(['2020-03-01', '2020-03-03', '2020-03-05', '2020-03-07',
'2020-03-09'],
dtype='datetime64[ns]', freq='2D')
'''
# 间隔三小时,八个数据
pd.date_range(start = '20200301',periods = 8,freq = '3H')
'''
DatetimeIndex(['2020-03-01 00:00:00', '2020-03-01 03:00:00',
'2020-03-01 06:00:00', '2020-03-01 09:00:00',
'2020-03-01 12:00:00', '2020-03-01 15:00:00',
'2020-03-01 18:00:00', '2020-03-01 21:00:00'],
dtype='datetime64[ns]', freq='3H')
'''
# 三点开始,十二个数据,间隔一分钟
pd.date_range(start = '202003010300',periods = 12,freq = 'T')
'''
DatetimeIndex(['2020-03-01 03:00:00', '2020-03-01 03:01:00',
'2020-03-01 03:02:00', '2020-03-01 03:03:00',
'2020-03-01 03:04:00', '2020-03-01 03:05:00',
'2020-03-01 03:06:00', '2020-03-01 03:07:00',
'2020-03-01 03:08:00', '2020-03-01 03:09:00',
'2020-03-01 03:10:00', '2020-03-01 03:11:00'],
dtype='datetime64[ns]', freq='T')
'''
# 每个月的最后一天
pd.date_range(start = '20190101',end = '20191231',freq = 'M')
'''
DatetimeIndex(['2019-01-31', '2019-02-28', '2019-03-31', '2019-04-30',
'2019-05-31', '2019-06-30', '2019-07-31', '2019-08-31',
'2019-09-30', '2019-10-31', '2019-11-30', '2019-12-31'],
dtype='datetime64[ns]', freq='M')
'''
# 间隔一年,六个数据,年末最后一天
pd.date_range(start = '20190101',periods = 6,freq = 'A')
'''
DatetimeIndex(['2019-12-31', '2020-12-31', '2021-12-31', '2022-12-31',
'2023-12-31', '2024-12-31'],
dtype='datetime64[ns]', freq='A-DEC')
'''
# 间隔一年,六个数据,年初最后一天
pd.date_range(start = '20200101',periods = 6,freq = 'AS')
'''
DatetimeIndex(['2020-01-01', '2021-01-01', '2022-01-01', '2023-01-01',
'2024-01-01', '2025-01-01'],
dtype='datetime64[ns]', freq='AS-JAN')
'''
# 使用 Series 对象包含时间序列对象,使用特定索引
data = pd.Series(index = pd.date_range(start = '20200321',periods = 24,freq = 'H'),data = range(24))
'''
2020-03-21 00:00:00 0
2020-03-21 01:00:00 1
2020-03-21 02:00:00 2
2020-03-21 03:00:00 3
2020-03-21 04:00:00 4
2020-03-21 05:00:00 5
2020-03-21 06:00:00 6
2020-03-21 07:00:00 7
2020-03-21 08:00:00 8
2020-03-21 09:00:00 9
2020-03-21 10:00:00 10
2020-03-21 11:00:00 11
2020-03-21 12:00:00 12
2020-03-21 13:00:00 13
2020-03-21 14:00:00 14
2020-03-21 15:00:00 15
2020-03-21 16:00:00 16
2020-03-21 17:00:00 17
2020-03-21 18:00:00 18
2020-03-21 19:00:00 19
2020-03-21 20:00:00 20
2020-03-21 21:00:00 21
2020-03-21 22:00:00 22
2020-03-21 23:00:00 23
Freq: H, dtype: int64
'''
# 查看前五个数据
data[:5]
'''
2020-03-21 00:00:00 0
2020-03-21 01:00:00 1
2020-03-21 02:00:00 2
2020-03-21 03:00:00 3
2020-03-21 04:00:00 4
Freq: H, dtype: int64
'''
# 三分钟重采样,计算均值
data.resample('3H').mean()
'''
2020-03-21 00:00:00 1
2020-03-21 03:00:00 4
2020-03-21 06:00:00 7
2020-03-21 09:00:00 10
2020-03-21 12:00:00 13
2020-03-21 15:00:00 16
2020-03-21 18:00:00 19
2020-03-21 21:00:00 22
Freq: 3H, dtype: int64
'''
# 五分钟重采样,求和
data.resample('5H').sum()
'''
2020-03-21 00:00:00 10
2020-03-21 05:00:00 35
2020-03-21 10:00:00 60
2020-03-21 15:00:00 85
2020-03-21 20:00:00 86
Freq: 5H, dtype: int64
'''
# 计算OHLC open,high,low,close
data.resample('5H').ohlc()
'''
open high low close
2020-03-21 00:00:00 0 4 0 4
2020-03-21 05:00:00 5 9 5 9
2020-03-21 10:00:00 10 14 10 14
2020-03-21 15:00:00 15 19 15 19
2020-03-21 20:00:00 20 23 20 23
'''
# 将日期替换为第二天
data.index = data.index + pd.Timedelta('1D')
# 查看前五条数据
data[:5]
'''
2020-03-22 00:00:00 0
2020-03-22 01:00:00 1
2020-03-22 02:00:00 2
2020-03-22 03:00:00 3
2020-03-22 04:00:00 4
Freq: H, dtype: int64
'''
# 查看指定日期是星期几
# pd.Timestamp('20200321').weekday_name
# 'Saturday'
# 查看指定日期的年份是否是闰年
pd.Timestamp('20200301').is_leap_year
# True
# 查看指定日期所在的季度和月份
day = pd.Timestamp('20200321')
# Timestamp('2020-03-21 00:00:00')
# 查看日期的季度
day.quarter
# 1
# 查看日期所在的月份
day.month
# 3
# 转换为 python 的日期时间对象
day.to_pydatetime()
# datetime.datetime(2020, 3, 21, 0, 0)
# DateFrame 的创建,包含部分:index , column , values
import numpy as np
import pandas as pd
# 创建一个 DataFrame 对象
dataframe = pd.DataFrame(np.random.randint(1,20,(5,3)),
index = range(5),
columns = ['A','B','C'])
'''
A B C
0 17 9 19
1 14 5 8
2 7 18 13
3 13 16 2
4 18 6 5
'''
# 索引为时间序列
dataframe2 = pd.DataFrame(np.random.randint(5,15,(9,3)),
index = pd.date_range(start = '202003211126',
end = '202003212000',
freq = 'H'),
columns = ['Pandas','爬虫','比赛'])
'''
Pandas 爬虫 比赛
2020-03-21 11:26:00 8 10 8
2020-03-21 12:26:00 9 14 9
2020-03-21 13:26:00 9 5 13
2020-03-21 14:26:00 9 7 7
2020-03-21 15:26:00 11 10 14
2020-03-21 16:26:00 12 7 10
2020-03-21 17:26:00 11 11 13
2020-03-21 18:26:00 8 13 8
2020-03-21 19:26:00 7 7 13
'''
# 使用字典进行创建
dataframe3 = pd.DataFrame({'语文':[87,79,67,92],
'数学':[93,89,80,77],
'英语':[88,95,76,77]},
index = ['张三','李四','王五','赵六'])
'''
语文 数学 英语
张三 87 93 88
李四 79 89 95
王五 67 80 76
赵六 92 77 77
'''
# 创建时自动扩充
dataframe4 = pd.DataFrame({'A':range(5,10),'B':3})
'''
A B
0 5 3
1 6 3
2 7 3
3 8 3
4 9 3
'''
# C:\Users\lenovo\Desktop\总结\Python
# 读取 Excel 文件并进行筛选
import pandas as pd
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额'])
# 打印前十行数据
dataframe[:10]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
4 1005 周七 9:00-14:00 600
5 1006 钱八 14:00-21:00 700
6 1006 钱八 9:00-14:00 850
7 1001 张三 14:00-21:00 600
8 1001 张三 9:00-14:00 1300
9 1002 李四 14:00-21:00 1500
'''
# 跳过 1 2 4 行,以第一列姓名为索引
dataframe2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
skiprows = [1,2,4],
index_col = 1)
'''注:张三李四赵六的第一条数据跳过
工号 日期 时段 交易额 柜台
姓名
王五 1003 20190301 9:00-14:00 800 食品
周七 1005 20190301 9:00-14:00 600 日用品
钱八 1006 20190301 14:00-21:00 700 日用品
钱八 1006 20190301 9:00-14:00 850 蔬菜水果
张三 1001 20190302 14:00-21:00 600 蔬菜水果
'''
# 筛选符合特定条件的数据
# 读取超市营业额数据
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看 5 到 10 的数据
dataframe[5:11]
'''
工号 姓名 日期 时段 交易额 柜台
5 1006 钱八 20190301 14:00-21:00 700 日用品
6 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
7 1001 张三 20190302 14:00-21:00 600 蔬菜水果
8 1001 张三 20190302 9:00-14:00 1300 化妆品
9 1002 李四 20190302 14:00-21:00 1500 化妆品
10 1003 王五 20190302 9:00-14:00 1000 食品
'''
# 查看第六行的数据,左闭右开
dataframe.iloc[5]
'''
工号 1006
姓名 钱八
时段 14:00-21:00
交易额 700
Name: 5, dtype: object
'''
dataframe[:5]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
4 1005 周七 9:00-14:00 600
'''
# 查看第 1 3 4 行的数据
dataframe.iloc[[0,2,3],:]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
'''
# 查看第 1 3 4 行的第 1 2 列
dataframe.iloc[[0,2,3],[0,1]]
'''
工号 姓名
0 1001 张三
2 1003 王五
3 1004 赵六
'''
# 查看前五行指定,姓名、时段和交易额的数据
dataframe[['姓名','时段','交易额']][:5]
'''
姓名 时段 交易额
0 张三 9:00-14:00 2000
1 李四 14:00-21:00 1800
2 王五 9:00-14:00 800
3 赵六 14:00-21:00 1100
4 周七 9:00-14:00 600
'''
dataframe[:5][['姓名','时段','交易额']]
'''
姓名 时段 交易额
0 张三 9:00-14:00 2000
1 李四 14:00-21:00 1800
2 王五 9:00-14:00 800
3 赵六 14:00-21:00 1100
4 周七 9:00-14:00 600
'''
# 查看第 2 4 5 行 姓名,交易额 数据 loc 函数,包含结尾
dataframe.loc[[1,3,4],['姓名','交易额']]
'''
姓名 交易额
1 李四 1800
3 赵六 1100
4 周七 600
'''
# 查看第四行的姓名数据
dataframe.at[3,'姓名']
# '赵六'
# 查看交易额大于 1700 的数据
dataframe[dataframe['交易额'] > 1700]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
'''
# 查看交易额总和
dataframe.sum()
'''
工号 17055
姓名 张三李四王五赵六周七钱八钱八张三张三李四王五赵六周七钱八李四王五张三...
时段 9:00-14:0014:00-21:009:00-14:0014:00-21:009:00...
交易额 17410
dtype: object
'''
# 某一时段的交易总和
dataframe[dataframe['时段'] == '14:00-21:00']['交易额'].sum()
# 8300
# 查看张三在下午14:00之后的交易情况
dataframe[(dataframe.姓名 == '张三') & (dataframe.时段 == '14:00-21:00')][:10]
'''
工号 姓名 时段 交易额
7 1001 张三 14:00-21:00 600
'''
# 查看日用品的销售总额
# dataframe[dataframe['柜台'] == '日用品']['交易额'].sum()
# 查看张三总共的交易额
dataframe[dataframe['姓名'].isin(['张三'])]['交易额'].sum()
# 5200
# 查看交易额在 1500~3000 之间的记录
dataframe[dataframe['交易额'].between(1500,3000)]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
9 1002 李四 14:00-21:00 1500
'''
# 查看数据特征和统计信息
import pandas as pd
# 读取文件
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看所有的交易额信息
dataframe['交易额'].describe()
'''
count 17.000000
mean 1024.117647
std 428.019550
min 580.000000
25% 700.000000
50% 850.000000
75% 1300.000000
max 2000.000000
Name: 交易额, dtype: float64
'''
# 查看四分位数
dataframe['交易额'].quantile([0,0.25,0.5,0.75,1.0])
'''
0.00 580.0
0.25 700.0
0.50 850.0
0.75 1300.0
1.00 2000.0
Name: 交易额, dtype: float64
'''
# 交易额中值
dataframe['交易额'].median()
# 850.0
# 交易额最小的三个数据
dataframe['交易额'].nsmallest(3)
'''
12 580
4 600
7 600
Name: 交易额, dtype: int64
'''
dataframe.nsmallest(3,'交易额')
'''
工号 姓名 日期 时段 交易额 柜台
12 1005 周七 20190302 9:00-14:00 580 日用品
4 1005 周七 20190301 9:00-14:00 600 日用品
7 1001 张三 20190302 14:00-21:00 600 蔬菜水果
'''
# 交易额最大的两个数据
dataframe['交易额'].nlargest(2)
'''
0 2000
1 1800
Name: 交易额, dtype: int64
'''
dataframe.nlargest(2,'交易额')
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
'''
# 查看最后一个日期
dataframe['日期'].max()
# 20190303
# 查看最小的工号
dataframe['工号'].min()
# 1001
# 第一个最小交易额的行下标
index = dataframe['交易额'].idxmin()
# 0
# 第一个最小交易额
dataframe.loc[index,'交易额']
# 580
# 最大交易额的行下标
index = dataframe['交易额'].idxmax()
dataframe.loc[index,'交易额']
# 2000
import pandas as pd
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
dataframe[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
2 1003 王五 9:00-14:00 800 食品
3 1004 赵六 14:00-21:00 1100 食品
4 1005 周七 9:00-14:00 600 日用品
'''
# 按照交易额和工号降序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = False)[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
9 1002 李四 14:00-21:00 1500 化妆品
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
'''
# 按照交易额和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'])[:5]
'''
工号 姓名 时段 交易额 柜台
12 1005 周七 9:00-14:00 580 日用品
7 1001 张三 14:00-21:00 600 蔬菜水果
4 1005 周七 9:00-14:00 600 日用品
14 1002 李四 9:00-14:00 680 蔬菜水果
5 1006 钱八 14:00-21:00 700 日用品
'''
# 按照交易额降序和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = [False,True])[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
9 1002 李四 14:00-21:00 1500 化妆品
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
'''
# 按工号升序排序
dataframe.sort_values(by = ['工号'])[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
7 1001 张三 14:00-21:00 600 蔬菜水果
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
'''
dataframe.sort_values(by = ['工号'],na_position = 'last')[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
7 1001 张三 14:00-21:00 600 蔬菜水果
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
'''
# 按列名升序排序
dataframe.sort_index(axis = 1)[:5]
'''
交易额 姓名 工号 时段 柜台
0 2000 张三 1001 9:00-14:00 化妆品
1 1800 李四 1002 14:00-21:00 化妆品
2 800 王五 1003 9:00-14:00 食品
3 1100 赵六 1004 14:00-21:00 食品
4 600 周七 1005 9:00-14:00 日用品
'''
dataframe.sort_index(axis = 1,ascending = True)[:5]
'''
交易额 姓名 工号 时段 柜台
0 2000 张三 1001 9:00-14:00 化妆品
1 1800 李四 1002 14:00-21:00 化妆品
2 800 王五 1003 9:00-14:00 食品
3 1100 赵六 1004 14:00-21:00 食品
4 600 周七 1005 9:00-14:00 日用品
'''
# 分组与聚合
import pandas as pd
import numpy as np
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
# 对 5 的余数进行分组
dataframe.groupby(by = lambda num:num % 5)['交易额'].sum()
'''
0 4530
1 5000
2 1980
3 3120
4 2780
Name: 交易额, dtype: int64
'''
# 查看索引为 7 15 的交易额
dataframe.groupby(by = {7:'索引为7的行',15:'索引为15的行'})['交易额'].sum()
'''
索引为15的行 830
索引为7的行 600
Name: 交易额, dtype: int64
'''
# 查看不同时段的交易总额
dataframe.groupby(by = '时段')['交易额'].sum()
'''
时段
14:00-21:00 8300
9:00-14:00 9110
Name: 交易额, dtype: int64
'''
# 各柜台的销售总额
dataframe.groupby(by = '柜台')['交易额'].sum()
'''
柜台
化妆品 7900
日用品 2600
蔬菜水果 2960
食品 3950
Name: 交易额, dtype: int64
'''
# 查看每个人在每个时段购买的次数
count = dataframe.groupby(by = '姓名')['时段'].count()
'''
姓名
周七 2
张三 4
李四 3
王五 3
赵六 2
钱八 3
Name: 时段, dtype: int64
'''
#
count.name = '交易人和次数'
'''
'''
# 每个人的交易额平均值并排序
dataframe.groupby(by = '姓名')['交易额'].mean().round(2).sort_values()
'''
姓名
周七 590.00
钱八 756.67
王五 876.67
赵六 1075.00
张三 1300.00
李四 1326.67
Name: 交易额, dtype: float64
'''
# 每个人的交易额
dataframe.groupby(by = '姓名').sum()['交易额'].apply(int)
'''
姓名
周七 1180
张三 5200
李四 3980
王五 2630
赵六 2150
钱八 2270
Name: 交易额, dtype: int64
'''
# 每一个员工交易额的中值
data = dataframe.groupby(by = '姓名').median()
'''
工号 交易额
姓名
周七 1005 590
张三 1001 1300
李四 1002 1500
王五 1003 830
赵六 1004 1075
钱八 1006 720
'''
data['交易额']
'''
姓名
周七 590
张三 1300
李四 1500
王五 830
赵六 1075
钱八 720
Name: 交易额, dtype: int64
'''
# 查看交易额对应的排名
data['排名'] = data['交易额'].rank(ascending = False)
data[['交易额','排名']]
'''
交易额 排名
姓名
周七 590 6.0
张三 1300 2.0
李四 1500 1.0
王五 830 4.0
赵六 1075 3.0
钱八 720 5.0
'''
# 每个人不同时段的交易额
dataframe.groupby(by = ['姓名','时段'])['交易额'].sum()
'''
姓名 时段
周七 9:00-14:00 1180
张三 14:00-21:00 600
9:00-14:00 4600
李四 14:00-21:00 3300
9:00-14:00 680
王五 14:00-21:00 830
9:00-14:00 1800
赵六 14:00-21:00 2150
钱八 14:00-21:00 1420
9:00-14:00 850
Name: 交易额, dtype: int64
'''
# 设置各时段累计
dataframe.groupby(by = ['姓名'])['时段','交易额'].aggregate({'交易额':np.sum,'时段':lambda x:'各时段累计'})
'''
交易额 时段
姓名
周七 1180 各时段累计
张三 5200 各时段累计
李四 3980 各时段累计
王五 2630 各时段累计
赵六 2150 各时段累计
钱八 2270 各时段累计
'''
# 对指定列进行聚合,查看最大,最小,和,平均值,中值
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])
'''
工号 交易额
max min sum mean median max min sum mean median
姓名
周七 1005 1005 2010 1005 1005 600 580 1180 590.000000 590
张三 1001 1001 4004 1001 1001 2000 600 5200 1300.000000 1300
李四 1002 1002 3006 1002 1002 1800 680 3980 1326.666667 1500
王五 1003 1003 3009 1003 1003 1000 800 2630 876.666667 830
赵六 1004 1004 2008 1004 1004 1100 1050 2150 1075.000000 1075
钱八 1006 1006 3018 1006 1006 850 700 2270 756.666667 720
'''
# 查看部分聚合后的结果
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])['交易额']
'''
max min sum mean median
姓名
周七 600 580 1180 590.000000 590
张三 2000 600 5200 1300.000000 1300
李四 1800 680 3980 1326.666667 1500
王五 1000 800 2630 876.666667 830
赵六 1100 1050 2150 1075.000000 1075
钱八 850 700 2270 756.666667 720
'''
# 处理异常值缺失值重复值数据差分
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 异常值
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看交易额低于 2000 的三条数据
# dataframe[dataframe.交易额 < 2000]
dataframe[dataframe.交易额 < 2000][:3]
'''
工号 姓名 日期 时段 交易额 柜台
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
3 1004 赵六 20190301 14:00-21:00 1100 食品
'''
# 查看上浮了 50% 之后依旧低于 1500 的交易额,查看 4 条数据
dataframe.loc[dataframe.交易额 < 1500,'交易额'] = dataframe[dataframe.交易额 < 1500]['交易额'].map(lambda num:num*1.5)
dataframe[dataframe.交易额 < 1500][:4]
'''
工号 姓名 日期 时段 交易额 柜台
2 1003 王五 20190301 9:00-14:00 1200.0 食品
4 1005 周七 20190301 9:00-14:00 900.0 日用品
5 1006 钱八 20190301 14:00-21:00 1050.0 日用品
6 1006 钱八 20190301 9:00-14:00 1275.0 蔬菜水果
'''
# 查看交易额大于 2500 的数据
dataframe[dataframe.交易额 > 2500]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# 查看交易额低于 900 或 高于 1800 的数据
dataframe[(dataframe.交易额 < 900)|(dataframe.交易额 > 1800)]
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000.0 化妆品
8 1001 张三 20190302 9:00-14:00 1950.0 化妆品
12 1005 周七 20190302 9:00-14:00 870.0 日用品
16 1001 张三 20190303 9:00-14:00 1950.0 化妆品
'''
# 将所有低于 200 的交易额都替换成 200 处理异常值
dataframe.loc[dataframe.交易额 < 200,'交易额'] = 200
# 查看低于 1500 的交易额个数
dataframe.loc[dataframe.交易额 < 1500,'交易额'].count()
# 9
# 将大于 3000 元的都替换为 3000 元
dataframe.loc[dataframe.交易额 > 3000,'交易额'] = 3000
# 缺失值
# 查看有多少行数据
len(dataframe)
# 17
# 丢弃缺失值之后的行数
len(dataframe.dropna())
# 17
# 包含缺失值的行
dataframe[dataframe['交易额'].isnull()]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# 使用固定值替换缺失值
# dff = copy.deepcopy(dataframe)
# dff.loc[dff.交易额.isnull(),'交易额'] = 999
# 将缺失值设定为 999,包含结尾
# dff.iloc[[1,4,17],:]
# 使用交易额的均值替换缺失值
# dff = copy.deepcopy(dataframe)
# for i in dff[dff.交易额.isnull()].index:
# dff.loc[i,'交易额'] = round(dff.loc[dff.姓名 == dff.loc[i,'姓名'],'交易额'].mean())
# dff.iloc[[1,4,17],:]
# 使用整体均值的 80% 填充缺失值
# dataframe.fillna({'交易额':round(dataframe['交易额'].mean() * 0.8)},inplace = True)
# dataframe.iloc[[1,4,16],:]
# 重复值
dataframe[dataframe.duplicated()]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# dff = dataframe[['工号','姓名','日期','交易额']]
# dff = dff[dff.duplicated()]
# for row in dff.values:
# df[(df.工号 == row[0]) & (df.日期 == row[2]) &(df.交易额 == row[3])]
# 丢弃重复行
dataframe = dataframe.drop_duplicates()
# 查看是否有录入错误的工号和姓名
dff = dataframe[['工号','姓名']]
dff.drop_duplicates()
'''
工号 姓名
0 1001 张三
1 1002 李四
2 1003 王五
3 1004 赵六
4 1005 周七
5 1006 钱八
'''
# 数据差分
# 查看员工业绩波动情况(每一天和昨天的数据作比较)
dff = dataframe.groupby(by = '日期').sum()['交易额'].diff()
'''
日期
20190301 NaN
20190302 1765.0
20190303 -9690.0
Name: 交易额, dtype: float64
'''
# [:5] dataframe.head()
dff.map(lambda num:'%.2f'%(num))[:5]
'''
日期
20190301 nan
20190302 1765.00
20190303 -9690.00
Name: 交易额, dtype: object
'''
# 查看张三的波动情况
dataframe[dataframe.姓名 == '张三'].groupby(by = '日期').sum()['交易额'].diff()[:5]
'''
日期
20190301 NaN
20190302 850.0
20190303 -900.0
Name: 交易额, dtype: float64
'''
# 使用透视表与交叉表查看业绩汇总数据
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 对姓名和日期进行分组,并进行求和
dff = dataframe.groupby(by = ['姓名','日期'],as_index = False).sum()
'''
姓名 日期 工号 交易额
0 周七 20190301 1005 600
1 周七 20190302 1005 580
2 张三 20190301 1001 2000
3 张三 20190302 2002 1900
4 张三 20190303 1001 1300
5 李四 20190301 1002 1800
6 李四 20190302 2004 2180
7 王五 20190301 1003 800
8 王五 20190302 2006 1830
9 赵六 20190301 1004 1100
10 赵六 20190302 1004 1050
11 钱八 20190301 2012 1550
12 钱八 20190302 1006 720
'''
# 将 dff 的索引,列 设置成透视表形式
dff = dff.pivot(index = '姓名',columns = '日期',values = '交易额')
'''
日期 20190301 20190302 20190303
姓名
周七 600.0 580.0 NaN
张三 2000.0 1900.0 1300.0
李四 1800.0 2180.0 NaN
王五 800.0 1830.0 NaN
赵六 1100.0 1050.0 NaN
钱八 1550.0 720.0 NaN
'''
# 查看前一天的数据
dff.iloc[:,:1]
'''
日期 20190301
姓名
周七 600.0
张三 2000.0
李四 1800.0
王五 800.0
赵六 1100.0
钱八 1550.0
'''
# 交易总额小于 4000 的人的前三天业绩
dff[dff.sum(axis = 1) < 4000].iloc[:,:3]
'''
日期 20190301 20190302 20190303
姓名
周七 600.0 580.0 NaN
李四 1800.0 2180.0 NaN
王五 800.0 1830.0 NaN
赵六 1100.0 1050.0 NaN
钱八 1550.0 720.0 NaN
'''
# 工资总额大于 2900 元的员工的姓名
dff[dff.sum(axis = 1) > 2900].index.values
# array(['张三', '李四'], dtype=object)
# 显示前两天每一天的交易总额以及每个人的交易金额
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'sum',margins = True).iloc[:,:2]
'''
日期 20190301 20190302
姓名
周七 600.0 580.0
张三 2000.0 1900.0
李四 1800.0 2180.0
王五 800.0 1830.0
赵六 1100.0 1050.0
钱八 1550.0 720.0
All 7850.0 8260.0
'''
# 显示每个人在每个柜台的交易总额
dff = dataframe.groupby(by = ['姓名','柜台'],as_index = False).sum()
dff.pivot(index = '姓名',columns = '柜台',values = '交易额')
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 1180.0 NaN NaN
张三 4600.0 NaN 600.0 NaN
李四 3300.0 NaN 680.0 NaN
王五 NaN NaN 830.0 1800.0
赵六 NaN NaN NaN 2150.0
钱八 NaN 1420.0 850.0 NaN
'''
# 查看每人每天的上班次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True).iloc[:,:1]
'''
日期 20190301
姓名
周七 1.0
张三 1.0
李四 1.0
王五 1.0
赵六 1.0
钱八 2.0
All 7.0
'''
# 查看每个人每天购买的次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True)
'''
日期 20190301 20190302 20190303 All
姓名
周七 1.0 1.0 NaN 2
张三 1.0 2.0 1.0 4
李四 1.0 2.0 NaN 3
王五 1.0 2.0 NaN 3
赵六 1.0 1.0 NaN 2
钱八 2.0 1.0 NaN 3
All 7.0 9.0 1.0 17
'''
# 交叉表
# 每个人每天上过几次班
pd.crosstab(dataframe.姓名,dataframe.日期,margins = True).iloc[:,:2]
'''
日期 20190301 20190302
姓名
周七 1 1
张三 1 2
李四 1 2
王五 1 2
赵六 1 1
钱八 2 1
All 7 9
'''
# 每个人每天去过几次柜台
pd.crosstab(dataframe.姓名,dataframe.柜台)
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 0 2 0 0
张三 3 0 1 0
李四 2 0 1 0
王五 0 0 1 2
赵六 0 0 0 2
钱八 0 2 1 0
'''
# 将每一个人在每一个柜台的交易总额显示出来
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc='sum')
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 1180.0 NaN NaN
张三 4600.0 NaN 600.0 NaN
李四 3300.0 NaN 680.0 NaN
王五 NaN NaN 830.0 1800.0
赵六 NaN NaN NaN 2150.0
钱八 NaN 1420.0 850.0 NaN
'''
# 每个人在每个柜台交易额的平均值,金额/天数
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc = 'mean').apply(lambda num:round(num,2) )
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 590.0 NaN NaN
张三 1533.33 NaN 600.0 NaN
李四 1650.00 NaN 680.0 NaN
王五 NaN NaN 830.0 900.0
赵六 NaN NaN NaN 1075.0
钱八 NaN 710.0 850.0 NaN
'''
# 重采样 多索引 标准差 协方差
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 将日期设置为 python 中的日期类型
data.日期 = pd.to_datetime(data.日期)
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 1970-01-01 00:00:00.020190301 9:00-14:00 2000 化妆品
1 1002 李四 1970-01-01 00:00:00.020190301 14:00-21:00 1800 化妆品
2 1003 王五 1970-01-01 00:00:00.020190301 9:00-14:00 800 食品
'''
# 每七天营业的总额
data.resample('7D',on = '日期').sum()['交易额']
'''
日期
1970-01-01 17410
Freq: 7D, Name: 交易额, dtype: int64
'''
# 每七天营业总额
data.resample('7D',on = '日期',label = 'right').sum()['交易额']
'''
日期
1970-01-08 17410
Freq: 7D, Name: 交易额, dtype: int64
'''
# 每七天营业额的平均值
func = lambda item:round(np.sum(item)/len(item),2)
data.resample('7D',on = '日期',label = 'right').apply(func)['交易额']
'''
日期
1970-01-08 1024.12
Freq: 7D, Name: 交易额, dtype: float64
'''
# 每七天营业额的平均值
func = lambda num:round(num,2)
data.resample('7D',on = '日期',label = 'right').mean().apply(func)['交易额']
# 1024.12
# 删除工号这一列
data.drop('工号',axis = 1,inplace = True)
data[:2]
'''
姓名 日期 时段 交易额 柜台
0 张三 1970-01-01 00:00:00.020190301 9:00-14:00 2000 化妆品
1 李四 1970-01-01 00:00:00.020190301 14:00-21:00 1800 化妆品
'''
# 按照姓名和柜台进行分组汇总
data = data.groupby(by = ['姓名','柜台']).sum()[:3]
'''
交易额
姓名 柜台
周七 日用品 1180
张三 化妆品 4600
蔬菜水果 600
'''
# 查看张三的汇总数据
data.loc['张三',:]
'''
交易额
柜台
化妆品 4600
蔬菜水果 600
'''
# 查看张三在蔬菜水果的交易数据
data.loc['张三','蔬菜水果']
'''
交易额 600
Name: (张三, 蔬菜水果), dtype: int64
'''
# 多索引
# 重新读取,使用第二列和第六列作为索引,排在前面
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',index_col = [1,5])
data[:5]
'''
工号 日期 时段 交易额
姓名 柜台
张三 化妆品 1001 20190301 9:00-14:00 2000
李四 化妆品 1002 20190301 14:00-21:00 1800
王五 食品 1003 20190301 9:00-14:00 800
赵六 食品 1004 20190301 14:00-21:00 1100
周七 日用品 1005 20190301 9:00-14:00 600
'''
# 丢弃工号列
data.drop('工号',axis = 1,inplace = True)
data[:5]
'''
日期 时段 交易额
姓名 柜台
张三 化妆品 20190301 9:00-14:00 2000
李四 化妆品 20190301 14:00-21:00 1800
王五 食品 20190301 9:00-14:00 800
赵六 食品 20190301 14:00-21:00 1100
周七 日用品 20190301 9:00-14:00 600
'''
# 按照柜台进行排序
dff = data.sort_index(level = '柜台',axis = 0)
dff[:5]
'''
工号 日期 时段 交易额
姓名 柜台
张三 化妆品 1001 20190301 9:00-14:00 2000
化妆品 1001 20190302 9:00-14:00 1300
化妆品 1001 20190303 9:00-14:00 1300
李四 化妆品 1002 20190301 14:00-21:00 1800
化妆品 1002 20190302 14:00-21:00 1500
'''
# 按照姓名进行排序
dff = data.sort_index(level = '姓名',axis = 0)
dff[:5]
'''
工号 日期 时段 交易额
姓名 柜台
周七 日用品 1005 20190301 9:00-14:00 600
日用品 1005 20190302 9:00-14:00 580
张三 化妆品 1001 20190301 9:00-14:00 2000
化妆品 1001 20190302 9:00-14:00 1300
化妆品 1001 20190303 9:00-14:00 1300
'''
# 按照柜台进行分组求和
dff = data.groupby(level = '柜台').sum()['交易额']
'''
柜台
化妆品 7900
日用品 2600
蔬菜水果 2960
食品 3950
Name: 交易额, dtype: int64
'''
#标准差
data = pd.DataFrame({'A':[3,3,3,3,3],'B':[1,2,3,4,5],
'C':[-5,-4,1,4,5],'D':[-45,15,63,40,50]
})
'''
A B C D
0 3 1 -5 -45
1 3 2 -4 15
2 3 3 1 63
3 3 4 4 40
4 3 5 5 50
'''
# 平均值
data.mean()
'''
A 3.0
B 3.0
C 0.2
D 24.6
dtype: float64
'''
# 标准差
data.std()
'''
A 0.000000
B 1.581139
C 4.549725
D 42.700117
dtype: float64
'''
# 标准差的平方
data.std()**2
'''
A 0.0
B 2.5
C 20.7
D 1823.3
dtype: float64
'''
# 协方差
data.cov()
'''
A B C D
A 0.0 0.00 0.00 0.00
B 0.0 2.50 7.00 53.75
C 0.0 7.00 20.70 153.35
D 0.0 53.75 153.35 1823.30
'''
# 指定索引为 姓名,日期,时段,柜台,交易额
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['姓名','日期','时段','柜台','交易额'])
# 删除缺失值和重复值,inplace = True 直接丢弃
data.dropna(inplace = True)
data.drop_duplicates(inplace = True)
# 处理异常值
data.loc[data.交易额 < 200,'交易额'] = 200
data.loc[data.交易额 > 3000,'交易额'] = 3000
# 使用交叉表得到不同员工在不同柜台的交易额平均值
dff = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean')
dff[:5]
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 590.0 NaN NaN
张三 1533.333333 NaN 600.0 NaN
李四 1650.000000 NaN 680.0 NaN
王五 NaN NaN 830.0 900.0
赵六 NaN NaN NaN 1075.0
'''
# 查看数据的标准差
dff.std()
'''
柜台
化妆品 82.495791
日用品 84.852814
蔬菜水果 120.277457
食品 123.743687
dtype: float64
'''
dff.cov()
'''
柜台 化妆品 日用品 蔬菜水果 食品
柜台
化妆品 6805.555556 NaN 4666.666667 NaN
日用品 NaN 7200.0 NaN NaN
蔬菜水果 4666.666667 NaN 14466.666667 NaN
食品 NaN NaN NaN 15312.5
'''
import pandas as pd
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',usecols = ['日期','交易额'])
dff = copy.deepcopy(data)
# 查看周几
dff['日期'] = pd.to_datetime(data['日期']).dt.weekday_name
'''
日期 交易额
0 Thursday 2000
1 Thursday 1800
2 Thursday 800
'''
# 按照周几进行分组,查看交易的平均值
dff = dff.groupby('日期').mean().apply(round)
dff.index.name = '周几'
dff[:3]
'''
交易额
周几
Thursday 1024.0
'''
# dff = copy.deepcopy(data)
# 使用正则规则查看月份日期
# dff['日期'] = dff.日期.str.extract(r'(\d{4}-\d{2})')
# dff[:5]
# 按照日 进行分组查看交易的平均值 -1 表示倒数第一个
# data.groupby(data.日期.str.__getitem__(-1)).mean().apply(round)
# 查看日期尾数为 1 的数据
# data[data.日期.str.endswith('1')][:12]
# 查看日期尾数为 12 的交易数据,slice 为切片 (-2) 表示倒数两个
# data[data.日期.str.slice(-2) == '12']
# 查看日期中月份或天数包含 2 的交易数据
# data[data.日期.str.slice(-5).str.contains('2')][1:9]
import pandas as pd
import numpy as np
# 读取全部数据,使用默认索引
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 修改异常值
data.loc[data.交易额 > 3000,'交易额'] = 3000
data.loc[data.交易额 < 200,'交易额'] = 200
# 删除重复值
data.drop_duplicates(inplace = True)
# 填充缺失值
data['交易额'].fillna(data['交易额'].mean(),inplace = True)
# 使用交叉表得到每人在各柜台交易额的平均值
data_group = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean').apply(round)
# 绘制柱状图
data_group.plot(kind = 'bar')
# <matplotlib.axes._subplots.AxesSubplot object at 0x000001D681607888>
# 数据的合并
data1 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
data2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',sheet_name = 'Sheet2')
df1 = data1[:3]
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
'''
df2 = data2[:4]
'''
工号 姓名 日期 时段 交易额 柜台
0 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
1 1001 张三 20190302 14:00-21:00 600 蔬菜水果
2 1001 张三 20190302 9:00-14:00 1300 化妆品
3 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 使用 concat 连接两个相同结构的 DataFrame 对象
df3 = pd.concat([df1,df2])
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
0 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
1 1001 张三 20190302 14:00-21:00 600 蔬菜水果
2 1001 张三 20190302 9:00-14:00 1300 化妆品
3 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 合并,忽略原来的索引 ignore_index
df4 = df3.append([df1,df2],ignore_index = True)
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
3 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
4 1001 张三 20190302 14:00-21:00 600 蔬菜水果
5 1001 张三 20190302 9:00-14:00 1300 化妆品
6 1002 李四 20190302 14:00-21:00 1500 化妆品
7 1001 张三 20190301 9:00-14:00 2000 化妆品
8 1002 李四 20190301 14:00-21:00 1800 化妆品
9 1003 王五 20190301 9:00-14:00 800 食品
10 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
11 1001 张三 20190302 14:00-21:00 600 蔬菜水果
12 1001 张三 20190302 9:00-14:00 1300 化妆品
13 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 按照列进行拆分
df5 = df4.loc[:,['姓名','柜台','交易额']]
# 查看前五条数据
df5[:5]
'''
姓名 柜台 交易额
0 张三 化妆品 2000
1 李四 化妆品 1800
2 王五 食品 800
3 钱八 蔬菜水果 850
4 张三 蔬菜水果 600
'''
# 合并 merge 、 join
# 按照工号进行合并,随机查看 3 条数据
rows = np.random.randint(0,len(df5),3)
pd.merge(df4,df5).iloc[rows,:]
'''
工号 姓名 日期 时段 交易额 柜台
7 1002 李四 20190301 14:00-21:00 1800 化妆品
4 1002 李四 20190301 14:00-21:00 1800 化妆品
10 1003 王五 20190301 9:00-14:00 800 食品
'''
# 按照工号进行合并,指定其他同名列的后缀
pd.merge(df1,df2,on = '工号',suffixes = ['_x','_y']).iloc[:,:]
'''
工号 姓名_x 日期_x 时段_x ... 日期_y 时段_y 交易额_y 柜台_y
0 1001 张三 20190301 9:00-14:00 ... 20190302 14:00-21:00 600 蔬菜水果
1 1001 张三 20190301 9:00-14:00 ... 20190302 9:00-14:00 1300 化妆品
2 1002 李四 20190301 14:00-21:00 ... 20190302 14:00-21:00 1500 化妆品
'''
# 两个表都设置工号为索引 set_index
df2.set_index('工号').join(df3.set_index('工号'),lsuffix = '_x',rsuffix = '_y').iloc[:]
'''
姓名_x 日期_x 时段_x 交易额_x ... 日期_y 时段_y 交易额_y 柜台_y
工号 ...
1001 张三 20190302 14:00-21:00 600 ... 20190301 9:00-14:00 2000 化妆品
1001 张三 20190302 14:00-21:00 600 ... 20190302 14:00-21:00 600 蔬菜水果
1001 张三 20190302 14:00-21:00 600 ... 20190302 9:00-14:00 1300 化妆品
1001 张三 20190302 9:00-14:00 1300 ... 20190301 9:00-14:00 2000 化妆品
1001 张三 20190302 9:00-14:00 1300 ... 20190302 14:00-21:00 600 蔬菜水果
1001 张三 20190302 9:00-14:00 1300 ... 20190302 9:00-14:00 1300 化妆品
1002 李四 20190302 14:00-21:00 1500 ... 20190301 14:00-21:00 1800 化妆品
1002 李四 20190302 14:00-21:00 1500 ... 20190302 14:00-21:00 1500 化妆品
1006 钱八 20190301 9:00-14:00 850 ... 20190301 9:00-14:00 850 蔬菜水果
'''
函数实现 多个数据求平均值
def average(*args):
print(args)
# (1, 2, 3)
# (1, 2, 3)
print(len(args))
# 3
# 3
print(sum(args, 0.0) / len(args))
average(*[1, 2, 3])
# 2.0
average(1, 2, 3)
# 2.0
使用 * 对传入的列表进行解包
对传入的数据进行分类
def bifurcate(lst, filter):
print(lst)
# ['beep', 'boop', 'foo', 'bar']
print(filter)
# [True, True, False, True]
# 列表名,不是 filter 函数
print(enumerate(lst))
# <enumerate object at 0x0000017EB10B9D00>
print(list(enumerate(lst)))
# [(0, 'beep'), (1, 'boop'), (2, 'foo'), (3, 'bar')]
print([
[x for i, x in enumerate(lst) if filter[i] == True],
[x for i, x in enumerate(lst) if filter[i] == False]
])
'''
filter[i] 主要是对枚举类型前面的索引和传入的 filter 列表进行判断是否重复
'''
bifurcate(['beep', 'boop', 'foo', 'bar'], [True, True, False, True])
进阶 对传入的数据进行分类
def bifurcate_by(lst, fn):
print(lst)
# ['beep', 'boop', 'foo', 'bar']
print(fn('baby'))
# True
print(fn('abc'))
# False
print([
[x for x in lst if fn(x)],
[x for x in lst if not fn(x)]
])
bifurcate_by(
['beep', 'boop', 'foo', 'bar'], lambda x: x[0] == 'b'
)
# [['beep', 'boop', 'bar'], ['foo']]
二进制字符长度
def byte_size(s):
print(s)
# 😀
# Hello World
print(s.encode('utf-8'))
# b'\xf0\x9f\x98\x80'
# b'Hello World'
print(len(s.encode('utf-8')))
# 4
11
byte_size('😀') # 4
byte_size('Hello World') # 11
将包含_或-的字符串最开始的字母小写,其余的第一个字母大写
from re import sub
def camel(s):
print(s)
# some_database_field_name
# Some label that needs to be camelized
# some-javascript-property
# some-mixed_string with spaces_underscores-and-hyphens
print(sub(r"(_|-)+", " ", s))
# some database field name
# Some label that needs to be camelized
# some javascript property
# some mixed string with spaces underscores and hyphens
print((sub(r"(_|-)+", " ", s)).title())
# Some Database Field Name
# Some Label That Needs To Be Camelized
# Some Javascript Property
# Some Mixed String With Spaces Underscores And Hyphens
print((sub(r"(_|-)+", " ", s)).title().replace(" ", ""))
# SomeDatabaseFieldName
# SomeLabelThatNeedsToBeCamelized
# SomeJavascriptProperty
# SomeMixedStringWithSpacesUnderscoresAndHyphens
s = sub(r"(_|-)+", " ", s).title().replace(" ", "")
print(s)
# SomeDatabaseFieldName
# SomeLabelThatNeedsToBeCamelized
# SomeJavascriptProperty
# SomeMixedStringWithSpacesUnderscoresAndHyphens
print(s[0].lower())
# s
# s
# s
# s
print(s[0].lower() + s[1:])
# someDatabaseFieldName
# someLabelThatNeedsToBeCamelized
# someJavascriptProperty
# someMixedStringWithSpacesUnderscoresAndHyphens
# s = sub(r"(_|-)+", " ", s).title().replace(" ", "")
# print(s[0].lower() + s[1:])
camel('some_database_field_name')
# someDatabaseFieldName
camel('Some label that needs to be camelized')
# someLabelThatNeedsToBeCamelized
camel('some-javascript-property')
# someJavascriptProperty
camel('some-mixed_string with spaces_underscores-and-hyphens')
# someMixedStringWithSpacesUnderscoresAndHyphens
无论传入什么数据都转换为列表
def cast_list(val):
print(val)
# foo
# [1]
# ('foo', 'bar')
print(type(val))
# <class 'str'>
# <class 'list'>
# <class 'tuple'>
print(isinstance(val,(tuple, list, set, dict)))
# False
# True
# True
print(list(val) if isinstance(val, (tuple, list, set, dict)) else [val])
'''
如果type(val)在 元组,列表,集合,字典 中,则转换为列表
如果不在,也转换为列表
'''
cast_list('foo')
# ['foo']
cast_list([1])
# [1]
cast_list(('foo', 'bar'))
# ['foo', 'bar']
斐波那契数列进一步讨论性能
'''
生成器求斐波那契数列
不需要担心会使用大量资源
'''
def fibon(n):
a = b = 1
for i in range(n):
yield a
# a 为每次生成的数值
a,b = b,a+b
for x in fibon(1000000):
print(x)
'''
使用列表进行斐波那契数列运算,会直接用尽所有的资源
'''
def fibon(n):
a = b = 1
result = []
for i in range(n):
result.append(a)
# a 为每次生成的数值
a,b = b,a+b
return result
for x in fibon(1000000):
print(x)
生成器使用场景:不想在同一时间将所有计算结果都分配到内存中
迭代器和可迭代对象区别
迭代器:
只要定义了 __next__方法,就是一个迭代器
生成器也是一种迭代器,但是只能迭代一次,因为只保存一次值
yield a
next(yield 对象) 进行遍历
可迭代对象:
只要定义了 __iter__ 方法就是一个可迭代对象
列表,字符串,元组,字典和集合都是可迭代对象
使用 iter(可迭代对象) 可以转换为 迭代器
map 函数基本写法
map(需要对对象使用的函数,要操作的对象)
函数可以是自定义的,也可以是内置函数的,或者 lambda 匿名函数
操作的对象多为 可迭代对象
可以是函数名的列表集合


filter 函数基本写法
filter 返回一个符合要求的元素所构成的新列表
filter(函数,可迭代对象)

map 和 filter 混合使用
将 lst_num 中为偶数的取出来进行加2 和 乘2 操作

functools 中的 reduce 函数基本写法
reduce 返回的往往是一整个可迭代对象的 操作结果
reduce(函数,可迭代对象)
注:lambda x,y 两个参数

三元运算符
条件为真执行的语句 if 条件 else 条件为假执行的语句
注:执行的语句,单独包含一个关键字时可能会出错

学装饰器之前必须要了解的四点
装饰器:
通俗理解:修改其他函数的功能的函数
学习装饰器之前,下面的点都要掌握
1.万物皆对象,当将函数名赋值给另一个对象之后
原来的对象删除,不会影响赋值过的新对象
2.函数内定义函数
注:外部函数返回内部函数,内部函数调用外部函数的参数 才可以称为闭包
3.从函数中返回函数,外部定义的函数返回内部定义的函数名
4.将函数作为参数传递给另一个函数


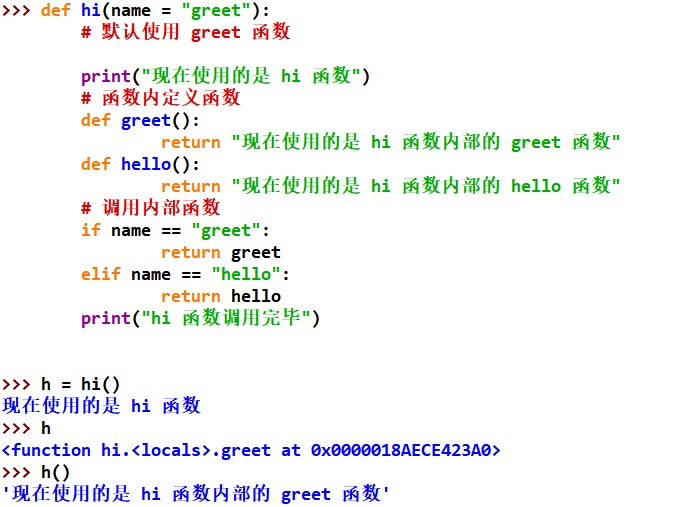

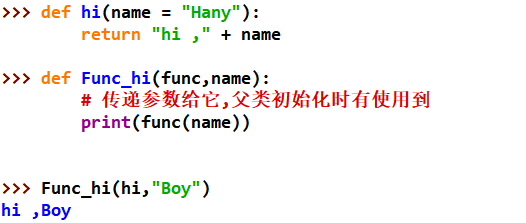
列表推导式,最基本写法
普通写法:
[对象 for 对象 in 可迭代对象]
[对象 for 对象 in 可迭代对象 if 条件]
注: 对象可以进行表达式运算


字典推导式,最基本写法
普通写法
{
对象对 键的操作:对象对 值的操作
for 对象 in 字典 的keys() 或者 values() 或者 items() 方法
}
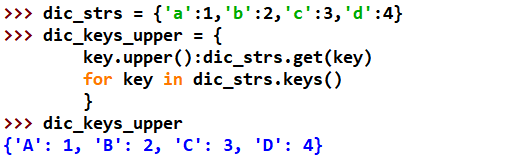

集合推导式,最基本写法
普通写法
{
对象的操作 for 对象 in 可迭代对象
}

状态码
100: ('continue',),
101: ('switching_protocols',),
102: ('processing',),
103: ('checkpoint',),
122: ('uri_too_long', 'request_uri_too_long'),
200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'),
201: ('created',),
202: ('accepted',),
203: ('non_authoritative_info', 'non_authoritative_information'),
204: ('no_content',),
205: ('reset_content', 'reset'),
206: ('partial_content', 'partial'),
207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'),
208: ('already_reported',),
226: ('im_used',),
# 重定向错误.
300: ('multiple_choices',),
301: ('moved_permanently', 'moved', '\\o-'),
302: ('found',),
303: ('see_other', 'other'),
304: ('not_modified',),
305: ('use_proxy',),
306: ('switch_proxy',),
307: ('temporary_redirect', 'temporary_moved', 'temporary'),
308: ('permanent_redirect',
'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# 客户端错误.
400: ('bad_request', 'bad'),
401: ('unauthorized',),
402: ('payment_required', 'payment'),
403: ('forbidden',),
404: ('not_found', '-o-'),
405: ('method_not_allowed', 'not_allowed'),
406: ('not_acceptable',),
407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'),
408: ('request_timeout', 'timeout'),
409: ('conflict',),
410: ('gone',),
411: ('length_required',),
412: ('precondition_failed', 'precondition'),
413: ('request_entity_too_large',),
414: ('request_uri_too_large',),
415: ('unsupported_media_type', 'unsupported_media', 'media_type'),
416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'),
417: ('expectation_failed',),
418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'),
421: ('misdirected_request',),
422: ('unprocessable_entity', 'unprocessable'),
423: ('locked',),
424: ('failed_dependency', 'dependency'),
425: ('unordered_collection', 'unordered'),
426: ('upgrade_required', 'upgrade'),
428: ('precondition_required', 'precondition'),
429: ('too_many_requests', 'too_many'),
431: ('header_fields_too_large', 'fields_too_large'),
444: ('no_response', 'none'),
449: ('retry_with', 'retry'),
450: ('blocked_by_windows_parental_controls', 'parental_controls'),
451: ('unavailable_for_legal_reasons', 'legal_reasons'),
499: ('client_closed_request',),
# 服务器错误.
500: ('internal_server_error', 'server_error', '/o\\', '✗'),
501: ('not_implemented',),
502: ('bad_gateway',),
503: ('service_unavailable', 'unavailable'),
504: ('gateway_timeout',),
505: ('http_version_not_supported', 'http_version'),
506: ('variant_also_negotiates',),
507: ('insufficient_storage',),
509: ('bandwidth_limit_exceeded', 'bandwidth'),
510: ('not_extended',),
511: ('network_authentication_required', 'network_auth', 'network_authentication'),
爬虫流程复习3
111.requests.get 方法的流程
r = requests.get('https://www.baidu.com/').content.decode('utf-8')
从状态码到 二进制码到 utf-8 编码
112.对 soup 对象进行美化
html = soup.prettify()
<title>
百度一下,你就知道
</title>
113.将内容 string 化
html.xpath('string(//*[@id="cnblogs_post_body"])')
114.获取属性
soup.p['name']
115.嵌套选择
soup.head.title.string
116.获取父节点和祖孙节点
soup.a.parent
list(enumerate(soup.a.parents))
117.获取兄弟节点
soup.a.next_siblings
list(enumerate(soup.a.next_siblings))
soup.a.previous_siblings
list(enumerate(soup.a.previous_siblings))
118.按照特定值查找标签
查找 id 为 list-1 的标签
soup.find_all(attrs={'id': 'list-1'})
soup.find_all(id='list-1')
119.返回父节点
find_parents()返回所有祖先节点
find_parent()返回直接父节点
120.返回后面兄弟节点
find_next_siblings()返回后面所有兄弟节点
find_next_sibling()返回后面第一个兄弟节点。
121.返回前面兄弟节点
find_previous_siblings()返回前面所有兄弟节点
find_previous_sibling()返回前面第一个兄弟节点。
122.返回节点后符合条件的节点
find_all_next()返回节点后所有符合条件的节点
find_next()返回第一个符合条件的节点
123.返回节点前符合条件的节点
find_all_previous()返回节点前所有符合条件的节点
find_previous()返回第一个符合条件的节点
124.requests 的请求方式
requests.post(url)
requests.put(url)
requests.delete(url)
requests.head(url)
requests.options(url)
125.GET请求
response = requests.get(url)
print(response.text)
126.解析 json
response.json()
json.loads(response.text)
127.发送 post 请求
response = requests.post(url, data=data, headers=headers)
response.json()
128.文件上传
在 post 方法内部添加参数 files 字典参数
import requests
files = {'file': open('favicon.ico', 'rb')}
response = requests.post("http://httpbin.org/post", files=files)
print(response.text)
129.获取 cookie
response.cookie
返回值是 字典对象
for key, value in response.cookies.items():
print(key + '=' + value)
130.模拟登录
requests.get('http://httpbin.org/cookies/set/number/123456789')
response = requests.get('http://httpbin.org/cookies')
131.带有 Session 的登录
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
response = s.get('http://httpbin.org/cookies')
132.证书验证
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn', verify=False)
response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
133.超时设置
from requests.exceptions import ReadTimeout
response = requests.get("http://httpbin.org/get", timeout = 0.5)
response = urllib.request.urlopen(url, timeout=1)
134.认证设置
from requests.auth import HTTPBasicAuth
r = requests.get('http://120.27.34.24:9001', auth=HTTPBasicAuth('user', '123'))
r = requests.get('http://120.27.34.24:9001', auth=('user', '123'))
135.异常处理
超时 ReadTimeout
连接出错 ConnectionError
错误 RequestException
136.URL 解析
from urllib.parse import urlparse
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment')
result = urlparse('www.baidu.com/index.html;user?id=5#comment', scheme='https')
result = urlparse('http://www.baidu.com/index.html;user?id=5#comment',allow_fragments=False)
136.urllib.parse.urlunparse
data = ['http', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))
http://www.baidu.com/index.html;user?a=6#comment
137.合并 url
urllib.parse.urljoin
urljoin('http://www.baidu.com', 'FAQ.html')
http://www.baidu.com/FAQ.html
urljoin('www.baidu.com#comment', '?category=2')
www.baidu.com?category=2
由于思维导图过大,不能全部截图进来,所以复制了文字,进行导入
注释导入xxx 是对上一行的解释:
爬虫基础
导包
import requests
from urllib.parse import urlencode
# 导入解析模块
from urllib.request import Request
# Request 请求
from urllib.parse import quote
# 使用 quote 解析中文
from urllib.request import urlopen
# urlopen 打开
from fake_useragent import UserAgent
# 导入 ua
import ssl
# 使用 ssl 忽略证书
from urllib.request import HTTPHandler
from urllib.request import build_opener
# 导入 build_opener
from urllib.request import ProxyHandler
# 导入 私人代理
from http.cookiejar import MozillaCookieJar
# 导入 cookie , 从 http.cookiejar 中
from urllib.error import URLError
# 捕捉 URL 异常
from lxml import etree
# 导入 etree,使用 xpath 进行解析
import http.cookiejar
# 导入 cookiejar
import json
# 导入 json
import jsonpath
# 导入 jsonpath
from selenium import webdriver
# 导入外部驱动
from selenium.webdriver.common.keys import Keys
# 要想调用键盘按键操作需要引入keys包
headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
}
headers = {
'User-Agent':UserAgent().random
}
from fake_useragent import UserAgent
headers = {
'User-Agent':UserAgent().chrome
}
使用 ua 列表
user_agent = [
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
ua = random.choice(user_agent)
headers = {'User-Agent':ua}
url
url = 'https://www.baidu.com/'
# 要进行访问的 URL
url = 'https://www.baidu.com/s?wd={}'.format(quote('瀚阳的小驿站'))
args = {
'wd':"Hany驿站",
"ie":"utf-8"
}
url = 'https://www.baidu.com/s?wd={}'.format(urlencode(args))
获取 response
get 请求
params = {
'wd':'Python'
}
response = requests.get(url,params = params,headers = headers)
params = {
'wd':'ip'
}
proxies = {
'http':'代理'
# "http":"http://用户名:密码@120.27.224.41:16818"
}
response = requests.get(url, params=params, headers=headers, proxies=proxies)
response = requests.get(url,headers = headers)
response = requests.get(url,verify = False,headers = headers)
Request 请求
form_data = {
'user':'账号',
'password':'密码'
}
f_data = urlencode(form_data)
request = Request(url = url,headers = headers,data = f_data)
handler = HTTPCookieProcessor()
opener = build_opener(handler)
response = opener.open(request)
request = Request(url = url,headers = headers)
response = urlopen(request)
request = Request(url,headers=headers)
handler = HTTPHandler()
# 构建 handler
opener = build_opener(handler)
# 将 handler 添加到 build_opener中
response = opener.open(request)
request = urllib.request.Request(url)
request.add_header('User-Agent', ua)
context = ssl._create_unverified_context()
reponse = urllib.request.urlopen(request, context = context)
response = urllib.request.urlopen(request, data=formdata)
# 构建请求体
formdata = {
'from':'en',
'to':'zh',
'query':word,
'transtype':'enter',
'simple_means_flag':'3'
}
# 将formdata进行urlencode编码,并且转化为bytes类型
formdata = urllib.parse.urlencode(formdata).encode('utf-8')
request = urllib.request.Request(url, headers=headers)
# 创建一个HTTPHandler对象,用来处理http请求
http_handler = urllib.request.HTTPHandler()
# 构建一个HTTPHandler 处理器对象,支持处理HTTPS请求
# 通过build_opener,创建支持http请求的opener对象
opener = urllib.request.build_opener(http_handler)
# 创建请求对象
# 抓取https,如果开启fiddler,则会报证书错误
# 不开启fiddler,抓取https,得不到百度网页,
request = urllib.request.Request('http://www.baidu.com/')
# 调用opener对象的open方法,发送http请求
reponse = opener.open(request)
使用 proxies 代理进行请求
proxies = {
'http':'代理'
# "http":"http://用户名:密码@120.27.224.41:16818"
}
response = requests.get(url,headers = headers,proxies = proxies)
request = Request(url,headers = headers)
handler = ProxyHandler({"http":"110.243.3.207"})
# 代理网址
opener = build_opener(handler)
response = opener.open(request)
post 请求
data = {
'user':'用户名',
'password':'密码'
}
response = requests.post(url,headers = headers,data = data)
# 使用 data 传递参数
使用 session
session = requests.Session()
get 请求
session.get(info_url,headers = headers)
post 请求
params = {
'user':'用户名',
'password':'密码'
}
session.post(url,headers = headers,data = params)
使用 ssl 忽略证书
context = ssl._create_unverified_context()
response = urlopen(request,context = context)
使用 cookie
form_data = {
'user':'用户名',
'password':'密码'
}
f_data = urlencode(form_data).encode()
request = Request(url = login_url,headers = headers,data = f_data)
cookie_jar = MozillaCookieJar()
handler = HTTPCookieProcessor(cookie_jar)
opener = build_opener(handler)
response = opener.open(request)
cookie_jar.save('cookie.txt',ignore_discard=True,ignore_expires=True)
# 失效或者过期依旧进行保存
request = Request(url = info_url,headers = headers)
cookie_jar = MozillaCookieJar()
cookie_jar.load('cookie.txt',ignore_expires=True,ignore_discard=True)
handler = HTTPCookieProcessor(cookie_jar)
opener = build_opener(handler)
response = opener.open(request)
设置时间戳
response = requests.get(url,timeout = 0.001)
# 设置时间戳
cookie = http.cookiejar.CookieJar()
# 通过CookieJar创建一个cookie对象,用来保存cookie值
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
# 通过HTTPCookieProcessor构建一个处理器对象,用来处理cookie
opener = urllib.request.build_opener(cookie_handler)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer':'https://passport.weibo.cn/signin/login?entry=mweibo&r=http%3A%2F%2Fweibo.cn%2F&backTitle=%CE%A2%B2%A9&vt=',
'Content-Type':'application/x-www-form-urlencoded',
# 'Host': 'passport.weibo.cn',
# 'Connection': 'keep-alive',
# 'Content-Length': '173',
# 'Origin':'https://passport.weibo.cn',
# 'Accept': '*/*',
}
url = 'https://passport.weibo.cn/sso/login'
formdata = {
'username':'17701256561',
'password':'2630030lzb',
'savestate':'1',
'r':'http://weibo.cn/',
'ec':'0',
'pagerefer':'',
'entry':'mweibo',
'wentry':'',
'loginfrom':'',
'client_id':'',
'code':'',
'qq':'',
'mainpageflag':'1',
'hff':'',
'hfp':''
}
formdata = urllib.parse.urlencode(formdata).encode()
# post表单里面的数据要转化为bytes类型,才能发送过去
request = urllib.request.Request(url, headers=headers)
response = opener.open(request, data=formdata)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer':'https://coding.net/login',
'Content-Type':'application/x-www-form-urlencoded',
}
post_url = 'https://coding.net/api/v2/account/login'
data = {
'account': 'wolfcode',
'password': '7c4a8d09ca3762af61e59520943dc26494f8941b',
'remember_me': 'false'
}
data = urllib.parse.urlencode(data).encode()
# 向指定的post地址发送登录请求
request = urllib.request.Request(post_url, headers=headers)
response = opener.open(request, data=data)
# 通过opener登录
# 登录成功之后,通过opener打开其他地址即可
response 属性和方法
response.getcode()
# 获取 HTTP 响应码 200
response.geturl()
# 获取访问的网址信息
response.info()
# 获取服务器响应的HTTP请求头
info = response.read()
# 读取内容
info.decode()
# 打印内容
response.read().decode()
print(request.get_header("User-agent"))
# 获取请求头信息
response.text
# 获取内容
response.encoding = 'utf-8'
response.json()
# 获取响应信息(json 格式字符串)
response.request.headers
# 请求头内容
response.cookie
# 获取 cookie
response.readline()
# 获取一行信息
response.status
# 查看状态码
正则表达式
$通配符,匹配字符串结尾
ret = re.match("[\w]{4,20}@163\.com$", email)
# \w 匹配字母或数字
# {4,20}匹配前一个字符4到20次
re.match匹配字符(仅匹配开头)
ret = re.findall(r"\d+","Hany.age = 22, python.version = 3.7.5")
# 输出全部找到的结果 \d + 一次或多次
ret = re.search(r"\d+",'阅读次数为:9999')
# 只要找到规则即可,从头到尾
re中匹配 [ ] 中列举的字符
ret = re.match("[hH]","hello Python")
# 大小写h都可以的情况
ret = re.match("[0-3,5-9]Hello Python","7Hello Python")
# 匹配0到3 5到9的数字
re中匹配不是以4,7结尾的手机号码
ret = re.match("1\d{9}[0-3,5-6,8-9]", tel)
re中匹配中奖号码
import re
# 匹配中奖号码
str2 = '17711602423'
pattern = re.compile('^(1[3578]\d)(\d{4})(\d{4})$')
print(pattern.sub(r'\1****\3',str2))
# r 字符串编码转化
'''177****2423'''
re中匹配中文字符
pattern = re.compile('[\u4e00-\u9fa5]')
strs = '你好 Hello hany'
print(pattern.findall(strs))
# ['你', '好']
pattern = re.compile('[\u4e00-\u9fa5]+')
print(pattern.findall(strs))
# ['你好']
re中将括号中字符作为一个分组
ret = re.match("\w{4,20}@163\.com", "test@163.com")
print(ret.group()) # test@163.com
re中对分组起别名
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>")
print(ret.group())
<html><h1>www.itcast.cn</h1></html>
re中匹配数字
# 使用\d进行匹配
ret = re.match("嫦娥\d号","嫦娥1号发射成功")
print(ret.group())
re中匹配左右任意一个表达式
ret = re.match("[1-9]?\d$|100","78")
print(ret.group()) # 78
re中匹配多个字符 问号
ret = re.match("[1-9]?\d[1-9]","33")
print(ret.group())
# 33
ret = re.match("[1-9]?\d","33")
print(ret.group())
# 33
re中匹配多个字符 星号
ret = re.match("[A-Z][a-z]*","MnnM")
print(ret.group())
# Mnn
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
# Aabcdef
re中匹配多个字符 加号
import re
#匹配前一个字符出现1次或无限次
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[\w]*",name)
if ret:
print("变量名 %s 符合要求" % ret.group())
else:
print("变量名 %s 非法" % name)
变量名 name1 符合要求
变量名 _name 符合要求
变量名 2_name 非法
变量名 __name__ 符合要求
re中引用分组匹配字符串
# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>hh</html>")
# </\1>匹配第一个规则
print(ret.group())
# <html>hh</html>
ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", label)
re中的贪婪和非贪婪
ret = re.match(r"aa(\d+)","aa2343ddd")
# 尽量多的匹配字符
print(ret.group())
# aa2343
# 使用? 将re贪婪转换为非贪婪
ret = re.match(r"aa(\d+?)","aa2343ddd")
# 只输出一个数字
print(ret.group())
# aa2
re使用split切割字符串
str1 = 'one,two,three,four'
pattern = re.compile(',')
# 按照,将string分割后返回
print(pattern.split(str1))
# ['one', 'two', 'three', 'four']
str2 = 'one1two2three3four'
print(re.split('\d+',str2))
# ['one', 'two', 'three', 'four']
re匹配中subn,进行替换并返回替换次数
pattern = re.compile('\d+')
strs = 'one1two2three3four'
print(pattern.subn('-',strs))
# ('one-two-three-four', 3) 3为替换的次数
re匹配中sub将匹配到的数据进行替换
pattern = re.compile('\d')
str1 = 'one1two2three3four'
print(pattern.sub('-',str1))
# one-two-three-four
print(re.sub('\d','-',str1))
# one-two-three-four
获取图片
src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
ret = re.search(r"https://.*?\.jpg", src)
print(ret.group())
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
re匹配前一个字符出现m次
res = re.compile('[a-zA-Z]{1}')
strs = '123abc456'
print(re.search(res,strs).group( ))
# a
res = re.compile('[a-zA-Z]{1}')
strs = '123abc456'
print(re.findall(res,strs)) #findall返回列表元素对象不具有group函数
# ['a', 'b', 'c']
分组 group
strs = 'hello 123,world 456'
pattern = re.compile('(\w+) (\d+)')
for i in pattern.finditer(strs):
print(i.group(0))
print(i.group(1))
print(i.group(2))#当存在第二个分组时
hello 123
hello
123
world 456
world
456
print(pattern.sub(r'\2 \1',strs))
# 先输出第二组,后输出第一组
# 123 hello,456 world
print(pattern.sub(r'\1 \2',strs))
# 先输出第一组,后输出第二组
# hello 123,world 456
忽略警告
requests.packages.urllib3.disable_warnings()
quote 编码
urllib.parse.quote() 除了-._/09AZaz 都会编码
urllib.parse.quote_plus() 还会编码 /
url = 'kw=中国'
urllib.parse.quote(url)
urllib.parse.quote_plus(url)
保存网址内容为某个文件格式
urllib.request.urlretrieve(url, '名称.后缀名')
json
# 将字节码解码为utf8的字符串
data = data.decode('utf-8')
# 将json格式的字符串转化为json对象
obj = json.loads(data)
# 禁用ascii之后,写入数据,就是正确的
html = json.dumps(obj, ensure_ascii=False)
# 将json对象通过str函数强制转化为字符串然后按照utf-8格式写入,这样就可以写成中文汉字了
# 写文件的时候要指定encoding,否则会按照系统的编码集写文件
loads
引号中为列表
string = '[1, 2, 3, 4, "haha"]'
json.loads(string)
引号中为字典
str_dict = '{"name":"goudan", "age":100, "height":180}'
json.loads(str_dict)
obj = json.load(open('jsontest.json', encoding='utf-8'))
# load 读取文件中json形式的字符串 转化成python对象
dumps
json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
json.dump(str_dict, open('jsontest.json', 'w', encoding='utf-8'), ensure_ascii=False)
# dump将对象序列化之后写入文件
load
obj = json.load(open('book.json', encoding='utf-8'))
book = jsonpath.jsonpath(obj, '$..book')
保存文件
# 得到html为bytes类型
html = response.read()
# 将bytes类型转化为字符串类型
html = html.decode('utf-8')
# 输出文件时,需要将bytes类型使用wb写入文件,否则出错
fp = open('baidu.html', 'w')
fp.write(html)
fp.close()
html = reponse.read()
with open(filename, 'wb') as f:
f.write(html)
# 通过read读取过来为字节码
data = response.read()
# 将字节码解码为utf8的字符串
data = data.decode('utf-8')
# 将json格式的字符串转化为json对象
obj = json.loads(data)
# 禁用ascii之后,写入数据,就是正确的
html = json.dumps(obj, ensure_ascii=False)
# 将json对象通过str函数强制转化为字符串然后按照utf-8格式写入,这样就可以写成中文汉字了
# 写文件的时候要指定encoding,否则会按照系统的编码集写文件
with open('json.txt', 'w', encoding='utf-8') as f:
f.write(html)
etree
html_tree = etree.parse('文件名.html')
# 通过读取文件得到tree对象
xpath 用法
result = html_tree.xpath('//li')
# 获取所有的li标签
result = html_tree.xpath('//li/@class')
# 获取所有li标签的class属性
result = html_tree.xpath('//li/a[@href="link1.html"]')
# 获取所有li下面a中属性href为link1.html的a
result = html_tree.xpath('//li[last()]/a/@href')
# 获取最后一个li的a里面的href,结果为一个字符串
result = html_tree.xpath('//*[@class="mimi"]')
# 获取class为mimi的节点
result = html_tree.xpath('//li[@class="popo"]/a')
# 符合条件的所有li里面的所有a节点
result = html_tree.xpath('//li[@class="popo"]/a/text()')
# 符合条件的所有li里面的所有a节点的内容
result = html_tree.xpath('//li[@class="popo"]/a')[0].text
# 符合条件的所有li里面的 a节点的内容
xpath使用后,加上 .extract()
只有一个元素可以使用 .extract_first()
tostring
etree.tostring(result[0]).decode('utf-8')
# 将tree对象转化为字符串
html = etree.tostring(html_tree)
print(html.decode('utf-8'))
etree.HTML
html_tree = etree.HTML('文件名.html')
# 将html字符串解析为文档类型
html_bytes = response.read()
html_tree = etree.HTML(html_bytes.decode('utf-8'))
response = requests.get(url,headers = headers)
e = etree.HTML(response.text)
img_path = '//article//img/@src'
img_urls = e.xpath(img_path)
string(.) 方法
xpath获取到的对象列表中的某一个元素
ret = score.xpath('string(.)').extract()[0]
BeautifulSoup
获取 soup
soup = BeautifulSoup(open('文件名.html', encoding='utf-8'), 'lxml')
soup = BeautifulSoup(driver.page_source, 'lxml')
# 在所有内容中第一个符合要求的标签
soup.title
soup.a
soup.ul
a_tag = soup.a
a_tag.name
# 获得标签名字
a_tag.attrs
# 得到标签的所有属性,字典类型
a_tag.get('href')
# 获取 href
a_tag['title']
# 查看 a 标签的 title 值
a_tag.string
# 获取 a 标签的内容
获取标签下的子节点
contents
soup.div.contents
# 获取 div 标签下所有子节点
soup.head.contents[1]
# 获取 div 下第二个子节点
children
# .children属性得到的是一个生成器,可以遍历生成器
# 遍历生成器打印对象
for child in soup.body.children:
print(child)
# 只遍历直接子节点
for child in soup.div.children:
print(child)
# descendants会递归遍历子孙节点
for child in soup.div.descendants:
print(child)
find_all 方法,查找所有的内容
soup.find_all(re.compile('^b'))
# 传入正则表达式 找到所有以b开头的标签
soup.find_all(['a', 'b'])
# 传入列表 找到所有的a标签和b标签
select 方法
soup.select('a')
# 通过类名
soup.select('.aa')
# 通过id名
soup.select('#wangyi')
# 组合查找
soup.select('div .la')
# 直接层级
soup.select('.div > .la')
# 根据属性查找
soup.select('input[class="haha"]')
# 查找 input 标签下 class 为 haha 的 标签
soup.select('.la')[0].get_text()
# 找到节点之后获取内容 通过get_text()方法,并且记得添加下标
jsonpath
jsonpath 方法
obj = json.load(open('book.json', encoding='utf-8'))
book = jsonpath.jsonpath(obj, '$..book')
# 所有book
authors = jsonpath.jsonpath(obj, '$..book..author')
# 所有book中的所有作者
# book中的前两本书 '$..book[:2]'
# book中的最后两本书 '$..book[-2:]'
book = jsonpath.jsonpath(obj, '$..book[0,1]')
# 获取前面的两本书
book = jsonpath.jsonpath(obj, '$..book[?(@.isbn)]')
# 所有book中,有属性isbn的书籍
book = jsonpath.jsonpath(obj, '$.store.book[?(@.price<10)]')
# 所有book中,价格小于10的书籍
xpath和jsonpath
补充资料
day01
http
状态码
协议简介
fiddler
简介
环境安装
类型
问题
day02
day03
day04
常用函数
webdriver 方法
设置 driver
driver = webdriver.PhantomJS()
driver = webdriver.PhantomJS(executable_path="./phantomjs")
# 如果没有在环境变量指定PhantomJS位置
driver 方法
text
# 获取标签内容
get_attribute('href')
# 获取标签属性
获取id标签值
element = driver.find_element_by_id("passwd-id")
driver.find_element_by_id('kw').send_keys('中国')
driver.find_element_by_id('su').click()
# 点击百度一下
yanzheng = input('请输入验证码:')
driver.find_element_by_id('captcha_field').send_keys(yanzheng)
for x in range(1, 3):
driver.find_element_by_id('loadMore').click()
time.sleep(3)
driver.save_screenshot(str(x) + '.png')
获取name标签值
element = driver.find_element_by_name("user-name")
获取标签名值
element = driver.find_element_by_tag_name("input")
可以通过XPath来匹配
element = driver.find_element_by_xpath("//input[@id='passwd-id']")
通过css来匹配
element = driver.find_element_by_css_selector("#food span.dairy.aged")
获取当前url
driver.current_url
关闭浏览器
driver.quit()
driver.save_screenshot('图片名.png')
# 保存当前网址为一张图片
driver.execute_script(js)
# 调用js方法,同时执行javascript脚本
实例
小说 三寸人间
list 和 [ ] 的功能不相同
对于一个对象:
list(对象) 可以进行强制转换
[对象] 不能够进行强制转换,只是在外围加上 [ ]

列表推导式中相同

数据库设计基础知识
流程:
1.用户需求分析
2.概念结构设计
3.逻辑结构设计(规范化)
4.数据库的物理结构设计
E-R 模型 -> 关系数据模型步骤
①为每个实体建立-张表
②为每个表选择一一个主键(建议添加一-个没有实际意义的字段作为主键)
③使用外键表示实体间关系
④定义约束条件
⑤评价关系的质量,并进行必要的改进(关于范式等知识请参考其他数据库书籍)
⑥为每个字段选择合适的数据类型、属性和索引等
关系:
一对一
将 一 方的主键放入到 另一方 中
一对多
将 一 方的主键 放到 多方 中
多对多
两边都将主键拿出,放入到一个新的表中
最少满足第三范式
定义属性 类型 索引
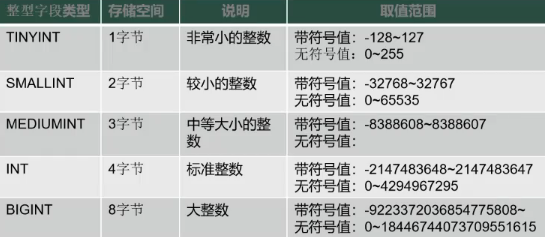
注:
1.当超出范围时,取类型的最大值
2.当无符号数时,给出负数,赋值为 0

字符串类型
可存储图像或声音之类的二进制数据
可存储用 gzip 压缩的数据
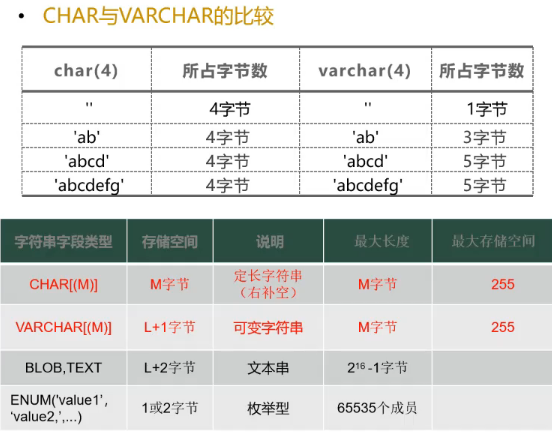
char 使用环境(推荐)
如果字段值长度固定或者相差不多(如性别)
数据库要进行大量字符运算(如比较、排序等)
varchar
如果字段长度变化较大的(如文章标题)
BLOB保存二进制数据(相片、 电影、压缩包)
ENUM('','') 枚举类型
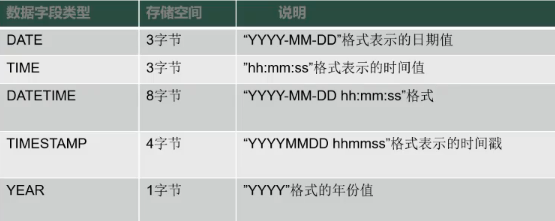

字段属性
UNSIGNED 不允许字段出现负数,可以使最大允许长度增加
ZEROFILL 用零填充,数值之前自动用0补齐不足的位数,只用于设置数值类型
auto_ increment 自动增量属性,默认从整数1开始递增,步长为1
可以指定自增的初始值 auto_ increment=n
如果将 NULL 添加到一个auto increment列,MySQL将自动生成下一个序列编号
DEFAULT 指定一个默认值
索引
确保数据的唯一性
优化查询
对索引字段中文本的搜索进行优化
使用 you-get 下载免费电影或电视剧
安装 you-get 和 ffmpeg
ffmpeg 主要是下载之后,合并音频和视频
pip install you-get -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install ffmpeg -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
you-get 下载指令:
you-get 视频网址
此处以 完美关系第二集为例:
https://v.qq.com/x/cover/mzc0020095tf0wm/s00338f1hq8.html?ptag=qqbrowser
注:
此下载方式会下载到 C:\Users\lenovo 目录下
选择下载路径使用 -o 文件夹位置
you-get -o + 文件要保存到的位置 +视频链接

python 连接 mysql 的三种驱动
连接 mysql 驱动
mysq1-client
python2,3都能直接使用
对myaq1安装有要求,必须指定位置存在 配置文件
python-mysql
python3 不支持
pymysql
python2, python3都支持
还可以伪装成前面的库
个人在使用 import mysql.connector
使用 pip 命令来安装 mysql-connector:
python -m pip install mysql-connector
创建数据库连接
可以使用以下代码来连接数据库:
import mysql.connector
mydb = mysql.connector.connect(
host="localhost", # 数据库主机地址
user="yourusername", # 数据库用户名
passwd="yourpassword" # 数据库密码
)
print(mydb)
创建数据库
创建数据库使用 "CREATE DATABASE" 语句,以下创建一个名为 runoob_db 的数据库:
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456"
)
mycursor = mydb.cursor()
mycursor.execute("CREATE DATABASE runoob_db")
创建数据表
创建数据表使用 "CREATE TABLE" 语句,创建数据表前,需要确保数据库已存在,以下创建一个名为 sites 的数据表:
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database="website"
)
mycursor = mydb.cursor()
mycursor.execute("CREATE TABLE sites (name VARCHAR(255), url VARCHAR(255))")
主键设置
mycursor.execute("ALTER TABLE sites ADD COLUMN id INT AUTO_INCREMENT PRIMARY KEY")
mycursor.execute("CREATE TABLE sites (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), url VARCHAR(255))")
插入数据
sql = "INSERT INTO sites (字段名, 字段名) VALUES (%s, %s)"
val = ("字段值", "字段值")
mycursor.execute(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
mycursor = mydb.cursor()
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = ("hany", "值1")
mycursor.execute(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
批量插入数据
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = [
('Google', 'https://www.google.com'),
('Github', 'https://www.github.com'),
('Taobao', 'https://www.taobao.com'),
('stackoverflow', 'https://www.stackoverflow.com/')
]
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
查询全部数据
mycursor = mydb.cursor()
mycursor.execute("SELECT * FROM sites")
myresult = mycursor.fetchall() # fetchall() 获取所有记录
for x in myresult:
print(x)
查询一条数据
myresult = mycursor.fetchone()
关于查询的 sql 语句
sql = "SELECT * FROM sites WHERE name ='RUNOOB'"
sql = "SELECT * FROM sites WHERE url LIKE '%oo%'"
sql = "SELECT * FROM sites WHERE name = %s"
sql = "SELECT * FROM sites ORDER BY name"
sql = "SELECT * FROM sites ORDER BY name DESC"
mycursor.execute("SELECT * FROM sites LIMIT 3")
mycursor.execute("SELECT * FROM sites LIMIT 3 OFFSET 1")
注: # 0 为 第一条,1 为第二条,以此类推
删除记录
sql = "DELETE FROM sites WHERE name = 'stackoverflow'"
mycursor.execute(sql)
sql = "DELETE FROM sites WHERE name = %s"
na = ("stackoverflow", )
mycursor.execute(sql, na)
删除表
sql = "DROP TABLE IF EXISTS sites" # 删除数据表 sites mycursor.execute(sql)
更新记录
sql = "UPDATE sites SET name = 'ZH' WHERE name = 'Zhihu'"
mycursor.execute(sql)
sql = "UPDATE sites SET name = %s WHERE name = %s"
val = ("Zhihu", "ZH")
mycursor.execute(sql, val)
mydb.commit()
pandas_DateFrame的创建
# DateFrame 的创建,包含部分:index , column , values
import numpy as np
import pandas as pd
# 创建一个 DataFrame 对象
dataframe = pd.DataFrame(np.random.randint(1,20,(5,3)),
index = range(5),
columns = ['A','B','C'])
'''
A B C
0 17 9 19
1 14 5 8
2 7 18 13
3 13 16 2
4 18 6 5
'''
# 索引为时间序列
dataframe2 = pd.DataFrame(np.random.randint(5,15,(9,3)),
index = pd.date_range(start = '202003211126',
end = '202003212000',
freq = 'H'),
columns = ['Pandas','爬虫','比赛'])
'''
Pandas 爬虫 比赛
2020-03-21 11:26:00 8 10 8
2020-03-21 12:26:00 9 14 9
2020-03-21 13:26:00 9 5 13
2020-03-21 14:26:00 9 7 7
2020-03-21 15:26:00 11 10 14
2020-03-21 16:26:00 12 7 10
2020-03-21 17:26:00 11 11 13
2020-03-21 18:26:00 8 13 8
2020-03-21 19:26:00 7 7 13
'''
# 使用字典进行创建
dataframe3 = pd.DataFrame({'语文':[87,79,67,92],
'数学':[93,89,80,77],
'英语':[88,95,76,77]},
index = ['张三','李四','王五','赵六'])
'''
语文 数学 英语
张三 87 93 88
李四 79 89 95
王五 67 80 76
赵六 92 77 77
'''
# 创建时自动扩充
dataframe4 = pd.DataFrame({'A':range(5,10),'B':3})
'''
A B
0 5 3
1 6 3
2 7 3
3 8 3
4 9 3
'''
pandas_一维数组与常用操作
# 一维数组与常用操作
import pandas as pd
# 设置输出结果列对齐
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
# 创建 从 0 开始的非负整数索引
s1 = pd.Series(range(1,20,5))
'''
0 1
1 6
2 11
3 16
dtype: int64
'''
# 使用字典创建 Series 字典的键作为索引
s2 = pd.Series({'语文':95,'数学':98,'Python':100,'物理':97,'化学':99})
'''
语文 95
数学 98
Python 100
物理 97
化学 99
dtype: int64
'''
# 使用索引下标进行修改
# 修改 Series 对象的值
s1[3] = -17
'''
0 1
1 6
2 11
3 -17
dtype: int64
'''
s2['语文'] = 94
'''
语文 94
数学 98
Python 100
物理 97
化学 99
dtype: int64
'''
# 查看 s1 的绝对值
abs(s1)
'''
0 1
1 6
2 11
3 17
dtype: int64
'''
# 将 s1 所有的值都加 5、使用加法时,对所有元素都进行
s1 + 5
'''
0 6
1 11
2 16
3 -12
dtype: int64
'''
# 在 s1 的索引下标前加入参数值
s1.add_prefix(2)
'''
20 1
21 6
22 11
23 -17
dtype: int64
'''
# s2 数据的直方图
s2.hist()
# 每行索引后面加上 hany
s2.add_suffix('hany')
'''
语文hany 94
数学hany 98
Pythonhany 100
物理hany 97
化学hany 99
dtype: int64
'''
# 查看 s2 中最大值的索引
s2.argmax()
# 'Python'
# 查看 s2 的值是否在指定区间内
s2.between(90,100,inclusive = True)
'''
语文 True
数学 True
Python True
物理 True
化学 True
dtype: bool
'''
# 查看 s2 中 97 分以上的数据
s2[s2 > 97]
'''
数学 98
Python 100
化学 99
dtype: int64
'''
# 查看 s2 中大于中值的数据
s2[s2 > s2.median()]
'''
Python 100
化学 99
dtype: int64
'''
# s2 与数字之间的运算,开平方 * 10 保留一位小数
round((s2**0.5)*10,1)
'''
语文 97.0
数学 99.0
Python 100.0
物理 98.5
化学 99.5
dtype: float64
'''
# s2 的中值
s2.median()
# 98.0
# s2 中最小的两个数
s2.nsmallest(2)
'''
语文 94
物理 97
dtype: int64
'''
# s2 中最大的两个数
s2.nlargest(2)
'''
Python 100
化学 99
dtype: int64
'''
# Series 对象之间的运算,对相同索引进行计算,不是相同索引的使用 NaN
pd.Series(range(5)) + pd.Series(range(5,10))
'''
0 5
1 7
2 9
3 11
4 13
dtype: int64
'''
# 对 Series 对象使用匿名函数
pd.Series(range(5)).pipe(lambda x,y,z :(x**y)%z,2,5)
'''
0 0
1 1
2 4
3 4
4 1
dtype: int64
'''
pd.Series(range(5)).pipe(lambda x:x+3)
'''
0 3
1 4
2 5
3 6
4 7
dtype: int64
'''
pd.Series(range(5)).pipe(lambda x:x+3).pipe(lambda x:x*3)
'''
0 9
1 12
2 15
3 18
4 21
dtype: int64
'''
# 对 Series 对象使用匿名函数
pd.Series(range(5)).apply(lambda x:x+3)
'''
0 3
1 4
2 5
3 6
4 7
dtype: int64
'''
# 查看标准差
pd.Series(range(0,5)).std()
# 1.5811388300841898
# 查看无偏方差
pd.Series(range(0,5)).var()
# 2.5
# 查看无偏标准差
pd.Series(range(0,5)).sem()
# 0.7071067811865476
# 查看是否存在等价于 True 的值
any(pd.Series([3,0,True]))
# True
# 查看是否所有的值都等价于 True
all(pd.Series([3,0,True]))
# False
pandas_使用属性接口实现高级功能
C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx
这个文档自己创建就可以,以下几篇文章仅作为参考
import pandas as pd
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',usecols = ['日期','交易额'])
dff = copy.deepcopy(data)
# 查看周几
dff['日期'] = pd.to_datetime(data['日期']).dt.weekday_name
'''
日期 交易额
0 Thursday 2000
1 Thursday 1800
2 Thursday 800
'''
# 按照周几进行分组,查看交易的平均值
dff = dff.groupby('日期').mean().apply(round)
dff.index.name = '周几'
dff[:3]
'''
交易额
周几
Thursday 1024.0
'''
# dff = copy.deepcopy(data)
# 使用正则规则查看月份日期
# dff['日期'] = dff.日期.str.extract(r'(\d{4}-\d{2})')
# dff[:5]
# 按照日 进行分组查看交易的平均值 -1 表示倒数第一个
# data.groupby(data.日期.str.__getitem__(-1)).mean().apply(round)
# 查看日期尾数为 1 的数据
# data[data.日期.str.endswith('1')][:12]
# 查看日期尾数为 12 的交易数据,slice 为切片 (-2) 表示倒数两个
# data[data.日期.str.slice(-2) == '12']
# 查看日期中月份或天数包含 2 的交易数据
# data[data.日期.str.slice(-5).str.contains('2')][1:9]
pandas_使用透视表与交叉表查看业绩汇总数据
# 使用透视表与交叉表查看业绩汇总数据
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 对姓名和日期进行分组,并进行求和
dff = dataframe.groupby(by = ['姓名','日期'],as_index = False).sum()
'''
姓名 日期 工号 交易额
0 周七 20190301 1005 600
1 周七 20190302 1005 580
2 张三 20190301 1001 2000
3 张三 20190302 2002 1900
4 张三 20190303 1001 1300
5 李四 20190301 1002 1800
6 李四 20190302 2004 2180
7 王五 20190301 1003 800
8 王五 20190302 2006 1830
9 赵六 20190301 1004 1100
10 赵六 20190302 1004 1050
11 钱八 20190301 2012 1550
12 钱八 20190302 1006 720
'''
# 将 dff 的索引,列 设置成透视表形式
dff = dff.pivot(index = '姓名',columns = '日期',values = '交易额')
'''
日期 20190301 20190302 20190303
姓名
周七 600.0 580.0 NaN
张三 2000.0 1900.0 1300.0
李四 1800.0 2180.0 NaN
王五 800.0 1830.0 NaN
赵六 1100.0 1050.0 NaN
钱八 1550.0 720.0 NaN
'''
# 查看前一天的数据
dff.iloc[:,:1]
'''
日期 20190301
姓名
周七 600.0
张三 2000.0
李四 1800.0
王五 800.0
赵六 1100.0
钱八 1550.0
'''
# 交易总额小于 4000 的人的前三天业绩
dff[dff.sum(axis = 1) < 4000].iloc[:,:3]
'''
日期 20190301 20190302 20190303
姓名
周七 600.0 580.0 NaN
李四 1800.0 2180.0 NaN
王五 800.0 1830.0 NaN
赵六 1100.0 1050.0 NaN
钱八 1550.0 720.0 NaN
'''
# 工资总额大于 2900 元的员工的姓名
dff[dff.sum(axis = 1) > 2900].index.values
# array(['张三', '李四'], dtype=object)
# 显示前两天每一天的交易总额以及每个人的交易金额
dataframe.pivot_table(values = '交易额',index = '姓名',
columns = '日期',aggfunc = 'sum',margins = True).iloc[:,:2]
'''
日期 20190301 20190302
姓名
周七 600.0 580.0
张三 2000.0 1900.0
李四 1800.0 2180.0
王五 800.0 1830.0
赵六 1100.0 1050.0
钱八 1550.0 720.0
All 7850.0 8260.0
'''
# 显示每个人在每个柜台的交易总额
dff = dataframe.groupby(by = ['姓名','柜台'],as_index = False).sum()
dff.pivot(index = '姓名',columns = '柜台',values = '交易额')
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 1180.0 NaN NaN
张三 4600.0 NaN 600.0 NaN
李四 3300.0 NaN 680.0 NaN
王五 NaN NaN 830.0 1800.0
赵六 NaN NaN NaN 2150.0
钱八 NaN 1420.0 850.0 NaN
'''
# 查看每人每天的上班次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True).iloc[:,:1]
'''
日期 20190301
姓名
周七 1.0
张三 1.0
李四 1.0
王五 1.0
赵六 1.0
钱八 2.0
All 7.0
'''
# 查看每个人每天购买的次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True)
'''
日期 20190301 20190302 20190303 All
姓名
周七 1.0 1.0 NaN 2
张三 1.0 2.0 1.0 4
李四 1.0 2.0 NaN 3
王五 1.0 2.0 NaN 3
赵六 1.0 1.0 NaN 2
钱八 2.0 1.0 NaN 3
All 7.0 9.0 1.0 17
'''
# 交叉表
# 每个人每天上过几次班
pd.crosstab(dataframe.姓名,dataframe.日期,margins = True).iloc[:,:2]
'''
日期 20190301 20190302
姓名
周七 1 1
张三 1 2
李四 1 2
王五 1 2
赵六 1 1
钱八 2 1
All 7 9
'''
# 每个人每天去过几次柜台
pd.crosstab(dataframe.姓名,dataframe.柜台)
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 0 2 0 0
张三 3 0 1 0
李四 2 0 1 0
王五 0 0 1 2
赵六 0 0 0 2
钱八 0 2 1 0
'''
# 将每一个人在每一个柜台的交易总额显示出来
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc='sum')
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 1180.0 NaN NaN
张三 4600.0 NaN 600.0 NaN
李四 3300.0 NaN 680.0 NaN
王五 NaN NaN 830.0 1800.0
赵六 NaN NaN NaN 2150.0
钱八 NaN 1420.0 850.0 NaN
'''
# 每个人在每个柜台交易额的平均值,金额/天数
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc = 'mean').apply(lambda num:round(num,2) )
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 590.0 NaN NaN
张三 1533.33 NaN 600.0 NaN
李四 1650.00 NaN 680.0 NaN
王五 NaN NaN 830.0 900.0
赵六 NaN NaN NaN 1075.0
钱八 NaN 710.0 850.0 NaN
'''
pandas_分类与聚合
# 分组与聚合
import pandas as pd
import numpy as np
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
# 对 5 的余数进行分组
dataframe.groupby(by = lambda num:num % 5)['交易额'].sum()
'''
0 4530
1 5000
2 1980
3 3120
4 2780
Name: 交易额, dtype: int64
'''
# 查看索引为 7 15 的交易额
dataframe.groupby(by = {7:'索引为7的行',15:'索引为15的行'})['交易额'].sum()
'''
索引为15的行 830
索引为7的行 600
Name: 交易额, dtype: int64
'''
# 查看不同时段的交易总额
dataframe.groupby(by = '时段')['交易额'].sum()
'''
时段
14:00-21:00 8300
9:00-14:00 9110
Name: 交易额, dtype: int64
'''
# 各柜台的销售总额
dataframe.groupby(by = '柜台')['交易额'].sum()
'''
柜台
化妆品 7900
日用品 2600
蔬菜水果 2960
食品 3950
Name: 交易额, dtype: int64
'''
# 查看每个人在每个时段购买的次数
count = dataframe.groupby(by = '姓名')['时段'].count()
'''
姓名
周七 2
张三 4
李四 3
王五 3
赵六 2
钱八 3
Name: 时段, dtype: int64
'''
#
count.name = '交易人和次数'
'''
'''
# 每个人的交易额平均值并排序
dataframe.groupby(by = '姓名')['交易额'].mean().round(2).sort_values()
'''
姓名
周七 590.00
钱八 756.67
王五 876.67
赵六 1075.00
张三 1300.00
李四 1326.67
Name: 交易额, dtype: float64
'''
# 每个人的交易额,apply(int) 转换为整数
dataframe.groupby(by = '姓名').sum()['交易额'].apply(int)
'''
姓名
周七 1180
张三 5200
李四 3980
王五 2630
赵六 2150
钱八 2270
Name: 交易额, dtype: int64
'''
# 每一个员工交易额的中值
data = dataframe.groupby(by = '姓名').median()
'''
工号 交易额
姓名
周七 1005 590
张三 1001 1300
李四 1002 1500
王五 1003 830
赵六 1004 1075
钱八 1006 720
'''
data['交易额']
'''
姓名
周七 590
张三 1300
李四 1500
王五 830
赵六 1075
钱八 720
Name: 交易额, dtype: int64
'''
# 查看交易额对应的排名
data['排名'] = data['交易额'].rank(ascending = False)
data[['交易额','排名']]
'''
交易额 排名
姓名
周七 590 6.0
张三 1300 2.0
李四 1500 1.0
王五 830 4.0
赵六 1075 3.0
钱八 720 5.0
'''
# 每个人不同时段的交易额
dataframe.groupby(by = ['姓名','时段'])['交易额'].sum()
'''
姓名 时段
周七 9:00-14:00 1180
张三 14:00-21:00 600
9:00-14:00 4600
李四 14:00-21:00 3300
9:00-14:00 680
王五 14:00-21:00 830
9:00-14:00 1800
赵六 14:00-21:00 2150
钱八 14:00-21:00 1420
9:00-14:00 850
Name: 交易额, dtype: int64
'''
# 设置各时段累计
dataframe.groupby(by = ['姓名'])['时段','交易额'].aggregate({'交易额':np.sum,'时段':lambda x:'各时段累计'})
'''
交易额 时段
姓名
周七 1180 各时段累计
张三 5200 各时段累计
李四 3980 各时段累计
王五 2630 各时段累计
赵六 2150 各时段累计
钱八 2270 各时段累计
'''
# 对指定列进行聚合,查看最大,最小,和,平均值,中值
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])
'''
工号 交易额
max min sum mean median max min sum mean median
姓名
周七 1005 1005 2010 1005 1005 600 580 1180 590.000000 590
张三 1001 1001 4004 1001 1001 2000 600 5200 1300.000000 1300
李四 1002 1002 3006 1002 1002 1800 680 3980 1326.666667 1500
王五 1003 1003 3009 1003 1003 1000 800 2630 876.666667 830
赵六 1004 1004 2008 1004 1004 1100 1050 2150 1075.000000 1075
钱八 1006 1006 3018 1006 1006 850 700 2270 756.666667 720
'''
# 查看部分聚合后的结果
dataframe.groupby(by = '姓名').agg(['max','min','sum','mean','median'])['交易额']
'''
max min sum mean median
姓名
周七 600 580 1180 590.000000 590
张三 2000 600 5200 1300.000000 1300
李四 1800 680 3980 1326.666667 1500
王五 1000 800 2630 876.666667 830
赵六 1100 1050 2150 1075.000000 1075
钱八 850 700 2270 756.666667 720
'''
pandas_处理异常值缺失值重复值数据差分
# 处理异常值缺失值重复值数据差分
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 异常值
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看交易额低于 2000 的三条数据
# dataframe[dataframe.交易额 < 2000]
dataframe[dataframe.交易额 < 2000][:3]
'''
工号 姓名 日期 时段 交易额 柜台
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
3 1004 赵六 20190301 14:00-21:00 1100 食品
'''
# 查看上浮了 50% 之后依旧低于 1500 的交易额,查看 4 条数据
dataframe.loc[dataframe.交易额 < 1500,'交易额'] = dataframe[dataframe.交易额 < 1500]['交易额'].map(lambda num:num*1.5)
dataframe[dataframe.交易额 < 1500][:4]
'''
工号 姓名 日期 时段 交易额 柜台
2 1003 王五 20190301 9:00-14:00 1200.0 食品
4 1005 周七 20190301 9:00-14:00 900.0 日用品
5 1006 钱八 20190301 14:00-21:00 1050.0 日用品
6 1006 钱八 20190301 9:00-14:00 1275.0 蔬菜水果
'''
# 查看交易额大于 2500 的数据
dataframe[dataframe.交易额 > 2500]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# 查看交易额低于 900 或 高于 1800 的数据
dataframe[(dataframe.交易额 < 900)|(dataframe.交易额 > 1800)]
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000.0 化妆品
8 1001 张三 20190302 9:00-14:00 1950.0 化妆品
12 1005 周七 20190302 9:00-14:00 870.0 日用品
16 1001 张三 20190303 9:00-14:00 1950.0 化妆品
'''
# 将所有低于 200 的交易额都替换成 200
dataframe.loc[dataframe.交易额 < 200,'交易额'] = 200
# 查看低于 1500 的交易额个数
dataframe.loc[dataframe.交易额 < 1500,'交易额'].count()
# 9
# 将大于 3000 元的都替换为 3000 元
dataframe.loc[dataframe.交易额 > 3000,'交易额'] = 3000
# 缺失值
# 查看有多少行数据
len(dataframe)
# 17
# 丢弃缺失值之后的行数
len(dataframe.dropna())
# 17
# 包含缺失值的行
dataframe[dataframe['交易额'].isnull()]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# 使用固定值替换缺失值
# dff = copy.deepcopy(dataframe)
# dff.loc[dff.交易额.isnull(),'交易额'] = 999
# 将缺失值设定为 999
# dff.iloc[[1,4,17],:]
# 使用交易额的均值替换缺失值
# dff = copy.deepcopy(dataframe)
# for i in dff[dff.交易额.isnull()].index:
# dff.loc[i,'交易额'] = round(dff.loc[dff.姓名 == dff.loc[i,'姓名'],'交易额'].mean())
# dff.iloc[[1,4,17],:]
# 使用整体均值的 80% 填充缺失值
# dataframe.fillna({'交易额':round(dataframe['交易额'].mean() * 0.8)},inplace = True)
# dataframe.iloc[[1,4,16],:]
# 重复值
dataframe[dataframe.duplicated()]
'''
Empty DataFrame
Columns: [工号, 姓名, 日期, 时段, 交易额, 柜台]
Index: []
'''
# dff = dataframe[['工号','姓名','日期','交易额']]
# dff = dff[dff.duplicated()]
# for row in dff.values:
# df[(df.工号 == row[0]) & (df.日期 == row[2]) &(df.交易额 == row[3])]
# 丢弃重复行
dataframe = dataframe.drop_duplicates()
# 查看是否有录入错误的工号和姓名
dff = dataframe[['工号','姓名']]
dff.drop_duplicates()
'''
工号 姓名
0 1001 张三
1 1002 李四
2 1003 王五
3 1004 赵六
4 1005 周七
5 1006 钱八
'''
# 数据差分
# 查看员工业绩波动情况(每一天和昨天的数据作比较)
dff = dataframe.groupby(by = '日期').sum()['交易额'].diff()
'''
日期
20190301 NaN
20190302 1765.0
20190303 -9690.0
Name: 交易额, dtype: float64
'''
dff.map(lambda num:'%.2f'%(num))[:5]
'''
日期
20190301 nan
20190302 1765.00
20190303 -9690.00
Name: 交易额, dtype: object
'''
# 数据差分
# 查看张三的波动情况
dataframe[dataframe.姓名 == '张三'].groupby(by = '日期').sum()['交易额'].diff()[:5]
'''
日期
20190301 NaN
20190302 850.0
20190303 -900.0
Name: 交易额, dtype: float64
'''
pandas_数据拆分与合并
import pandas as pd
import numpy as np
# 读取全部数据,使用默认索引
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 修改异常值
data.loc[data.交易额 > 3000,'交易额'] = 3000
data.loc[data.交易额 < 200,'交易额'] = 200
# 删除重复值
data.drop_duplicates(inplace = True)
# inplace 表示对源数据也进行修改
# 填充缺失值
data['交易额'].fillna(data['交易额'].mean(),inplace = True)
# 使用交叉表得到每人在各柜台交易额的平均值
data_group = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean').apply(round)
# 绘制柱状图
data_group.plot(kind = 'bar')
# <matplotlib.axes._subplots.AxesSubplot object at 0x000001D681607888>
# 数据的合并
data1 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
data2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',sheet_name = 'Sheet2')
df1 = data1[:3]
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
'''
df2 = data2[:4]
'''
工号 姓名 日期 时段 交易额 柜台
0 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
1 1001 张三 20190302 14:00-21:00 600 蔬菜水果
2 1001 张三 20190302 9:00-14:00 1300 化妆品
3 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 使用 concat 连接两个相同结构的 DataFrame 对象
df3 = pd.concat([df1,df2])
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
0 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
1 1001 张三 20190302 14:00-21:00 600 蔬菜水果
2 1001 张三 20190302 9:00-14:00 1300 化妆品
3 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 合并,忽略原来的索引 ignore_index
df4 = df3.append([df1,df2],ignore_index = True)
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
2 1003 王五 20190301 9:00-14:00 800 食品
3 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
4 1001 张三 20190302 14:00-21:00 600 蔬菜水果
5 1001 张三 20190302 9:00-14:00 1300 化妆品
6 1002 李四 20190302 14:00-21:00 1500 化妆品
7 1001 张三 20190301 9:00-14:00 2000 化妆品
8 1002 李四 20190301 14:00-21:00 1800 化妆品
9 1003 王五 20190301 9:00-14:00 800 食品
10 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
11 1001 张三 20190302 14:00-21:00 600 蔬菜水果
12 1001 张三 20190302 9:00-14:00 1300 化妆品
13 1002 李四 20190302 14:00-21:00 1500 化妆品
'''
# 按照列进行拆分
df5 = df4.loc[:,['姓名','柜台','交易额']]
# 查看前五条数据
df5[:5]
'''
姓名 柜台 交易额
0 张三 化妆品 2000
1 李四 化妆品 1800
2 王五 食品 800
3 钱八 蔬菜水果 850
4 张三 蔬菜水果 600
'''
# 合并 merge 、 join
# 按照工号进行合并,随机查看 3 条数据
rows = np.random.randint(0,len(df5),3)
pd.merge(df4,df5).iloc[rows,:]
'''
工号 姓名 日期 时段 交易额 柜台
7 1002 李四 20190301 14:00-21:00 1800 化妆品
4 1002 李四 20190301 14:00-21:00 1800 化妆品
10 1003 王五 20190301 9:00-14:00 800 食品
'''
# 按照工号进行合并,指定其他同名列的后缀
pd.merge(df1,df2,on = '工号',suffixes = ['_x','_y']).iloc[:,:]
'''
工号 姓名_x 日期_x 时段_x ... 日期_y 时段_y 交易额_y 柜台_y
0 1001 张三 20190301 9:00-14:00 ... 20190302 14:00-21:00 600 蔬菜水果
1 1001 张三 20190301 9:00-14:00 ... 20190302 9:00-14:00 1300 化妆品
2 1002 李四 20190301 14:00-21:00 ... 20190302 14:00-21:00 1500 化妆品
'''
# 两个表都设置工号为索引 set_index
df2.set_index('工号').join(df3.set_index('工号'),lsuffix = '_x',rsuffix = '_y').iloc[:]
'''
姓名_x 日期_x 时段_x 交易额_x ... 日期_y 时段_y 交易额_y 柜台_y
工号 ...
1001 张三 20190302 14:00-21:00 600 ... 20190301 9:00-14:00 2000 化妆品
1001 张三 20190302 14:00-21:00 600 ... 20190302 14:00-21:00 600 蔬菜水果
1001 张三 20190302 14:00-21:00 600 ... 20190302 9:00-14:00 1300 化妆品
1001 张三 20190302 9:00-14:00 1300 ... 20190301 9:00-14:00 2000 化妆品
1001 张三 20190302 9:00-14:00 1300 ... 20190302 14:00-21:00 600 蔬菜水果
1001 张三 20190302 9:00-14:00 1300 ... 20190302 9:00-14:00 1300 化妆品
1002 李四 20190302 14:00-21:00 1500 ... 20190301 14:00-21:00 1800 化妆品
1002 李四 20190302 14:00-21:00 1500 ... 20190302 14:00-21:00 1500 化妆品
1006 钱八 20190301 9:00-14:00 850 ... 20190301 9:00-14:00 850 蔬菜水果
'''
pandas_数据排序
import pandas as pd
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
dataframe[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
2 1003 王五 9:00-14:00 800 食品
3 1004 赵六 14:00-21:00 1100 食品
4 1005 周七 9:00-14:00 600 日用品
'''
# 按照交易额和工号降序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = False)[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
9 1002 李四 14:00-21:00 1500 化妆品
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
'''
# 按照交易额和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'])[:5]
'''
工号 姓名 时段 交易额 柜台
12 1005 周七 9:00-14:00 580 日用品
7 1001 张三 14:00-21:00 600 蔬菜水果
4 1005 周七 9:00-14:00 600 日用品
14 1002 李四 9:00-14:00 680 蔬菜水果
5 1006 钱八 14:00-21:00 700 日用品
'''
# 按照交易额降序和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = [False,True])[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
9 1002 李四 14:00-21:00 1500 化妆品
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
'''
# 按工号升序排序
dataframe.sort_values(by = ['工号'])[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
7 1001 张三 14:00-21:00 600 蔬菜水果
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
'''
dataframe.sort_values(by = ['工号'],na_position = 'last')[:5]
'''
工号 姓名 时段 交易额 柜台
0 1001 张三 9:00-14:00 2000 化妆品
7 1001 张三 14:00-21:00 600 蔬菜水果
8 1001 张三 9:00-14:00 1300 化妆品
16 1001 张三 9:00-14:00 1300 化妆品
1 1002 李四 14:00-21:00 1800 化妆品
'''
# 按列名升序排序
dataframe.sort_index(axis = 1)[:5]
'''
交易额 姓名 工号 时段 柜台
0 2000 张三 1001 9:00-14:00 化妆品
1 1800 李四 1002 14:00-21:00 化妆品
2 800 王五 1003 9:00-14:00 食品
3 1100 赵六 1004 14:00-21:00 食品
4 600 周七 1005 9:00-14:00 日用品
'''
dataframe.sort_index(axis = 1,ascending = True)[:5]
'''
交易额 姓名 工号 时段 柜台
0 2000 张三 1001 9:00-14:00 化妆品
1 1800 李四 1002 14:00-21:00 化妆品
2 800 王五 1003 9:00-14:00 食品
3 1100 赵六 1004 14:00-21:00 食品
4 600 周七 1005 9:00-14:00 日用品
'''
pandas_时间序列和常用操作
# 时间序列和常用操作
import pandas as pd
# 每隔五天--5D
pd.date_range(start = '20200101',end = '20200131',freq = '5D')
'''
DatetimeIndex(['2020-01-01', '2020-01-06', '2020-01-11', '2020-01-16',
'2020-01-21', '2020-01-26', '2020-01-31'],
dtype='datetime64[ns]', freq='5D')
'''
# 每隔一周--W
pd.date_range(start = '20200301',end = '20200331',freq = 'W')
'''
DatetimeIndex(['2020-03-01', '2020-03-08', '2020-03-15', '2020-03-22',
'2020-03-29'],
dtype='datetime64[ns]', freq='W-SUN')
'''
# 间隔两天,五个数据
pd.date_range(start = '20200301',periods = 5,freq = '2D')
# periods 几个数据 ,freq 间隔时期,两天
'''
DatetimeIndex(['2020-03-01', '2020-03-03', '2020-03-05', '2020-03-07',
'2020-03-09'],
dtype='datetime64[ns]', freq='2D')
'''
# 间隔三小时,八个数据
pd.date_range(start = '20200301',periods = 8,freq = '3H')
'''
DatetimeIndex(['2020-03-01 00:00:00', '2020-03-01 03:00:00',
'2020-03-01 06:00:00', '2020-03-01 09:00:00',
'2020-03-01 12:00:00', '2020-03-01 15:00:00',
'2020-03-01 18:00:00', '2020-03-01 21:00:00'],
dtype='datetime64[ns]', freq='3H')
'''
# 三点开始,十二个数据,间隔一分钟
pd.date_range(start = '202003010300',periods = 12,freq = 'T')
'''
DatetimeIndex(['2020-03-01 03:00:00', '2020-03-01 03:01:00',
'2020-03-01 03:02:00', '2020-03-01 03:03:00',
'2020-03-01 03:04:00', '2020-03-01 03:05:00',
'2020-03-01 03:06:00', '2020-03-01 03:07:00',
'2020-03-01 03:08:00', '2020-03-01 03:09:00',
'2020-03-01 03:10:00', '2020-03-01 03:11:00'],
dtype='datetime64[ns]', freq='T')
'''
# 每个月的最后一天
pd.date_range(start = '20190101',end = '20191231',freq = 'M')
'''
DatetimeIndex(['2019-01-31', '2019-02-28', '2019-03-31', '2019-04-30',
'2019-05-31', '2019-06-30', '2019-07-31', '2019-08-31',
'2019-09-30', '2019-10-31', '2019-11-30', '2019-12-31'],
dtype='datetime64[ns]', freq='M')
'''
# 间隔一年,六个数据,年末最后一天
pd.date_range(start = '20190101',periods = 6,freq = 'A')
'''
DatetimeIndex(['2019-12-31', '2020-12-31', '2021-12-31', '2022-12-31',
'2023-12-31', '2024-12-31'],
dtype='datetime64[ns]', freq='A-DEC')
'''
# 间隔一年,六个数据,年初最后一天
pd.date_range(start = '20200101',periods = 6,freq = 'AS')
'''
DatetimeIndex(['2020-01-01', '2021-01-01', '2022-01-01', '2023-01-01',
'2024-01-01', '2025-01-01'],
dtype='datetime64[ns]', freq='AS-JAN')
'''
# 使用 Series 对象包含时间序列对象,使用特定索引
data = pd.Series(index = pd.date_range(start = '20200321',periods = 24,freq = 'H'),data = range(24))
'''
2020-03-21 00:00:00 0
2020-03-21 01:00:00 1
2020-03-21 02:00:00 2
2020-03-21 03:00:00 3
2020-03-21 04:00:00 4
2020-03-21 05:00:00 5
2020-03-21 06:00:00 6
2020-03-21 07:00:00 7
2020-03-21 08:00:00 8
2020-03-21 09:00:00 9
2020-03-21 10:00:00 10
2020-03-21 11:00:00 11
2020-03-21 12:00:00 12
2020-03-21 13:00:00 13
2020-03-21 14:00:00 14
2020-03-21 15:00:00 15
2020-03-21 16:00:00 16
2020-03-21 17:00:00 17
2020-03-21 18:00:00 18
2020-03-21 19:00:00 19
2020-03-21 20:00:00 20
2020-03-21 21:00:00 21
2020-03-21 22:00:00 22
2020-03-21 23:00:00 23
Freq: H, dtype: int64
'''
# 查看前五个数据
data[:5]
'''
2020-03-21 00:00:00 0
2020-03-21 01:00:00 1
2020-03-21 02:00:00 2
2020-03-21 03:00:00 3
2020-03-21 04:00:00 4
Freq: H, dtype: int64
'''
# 三分钟重采样,计算均值
data.resample('3H').mean()
'''
2020-03-21 00:00:00 1
2020-03-21 03:00:00 4
2020-03-21 06:00:00 7
2020-03-21 09:00:00 10
2020-03-21 12:00:00 13
2020-03-21 15:00:00 16
2020-03-21 18:00:00 19
2020-03-21 21:00:00 22
Freq: 3H, dtype: int64
'''
# 五分钟重采样,求和
data.resample('5H').sum()
'''
2020-03-21 00:00:00 10
2020-03-21 05:00:00 35
2020-03-21 10:00:00 60
2020-03-21 15:00:00 85
2020-03-21 20:00:00 86
Freq: 5H, dtype: int64
'''
# 计算OHLC open,high,low,close
data.resample('5H').ohlc()
'''
open high low close
2020-03-21 00:00:00 0 4 0 4
2020-03-21 05:00:00 5 9 5 9
2020-03-21 10:00:00 10 14 10 14
2020-03-21 15:00:00 15 19 15 19
2020-03-21 20:00:00 20 23 20 23
'''
# 将日期替换为第二天
data.index = data.index + pd.Timedelta('1D')
# 查看前五条数据
data[:5]
'''
2020-03-22 00:00:00 0
2020-03-22 01:00:00 1
2020-03-22 02:00:00 2
2020-03-22 03:00:00 3
2020-03-22 04:00:00 4
Freq: H, dtype: int64
'''
# 查看指定日期是星期几
# pd.Timestamp('20200321').weekday_name
# 'Saturday'
# 查看指定日期的年份是否是闰年
pd.Timestamp('20200301').is_leap_year
# True
# 查看指定日期所在的季度和月份
day = pd.Timestamp('20200321')
# Timestamp('2020-03-21 00:00:00')
# 查看日期的季度
day.quarter
# 1
# 查看日期所在的月份
day.month
# 3
# 转换为 python 的日期时间对象
day.to_pydatetime()
# datetime.datetime(2020, 3, 21, 0, 0)
pandas_学习的时候总会忘了的知识点
对Series 对象使用匿名函数
使用 pipe 函数对 Series 对象使用 匿名函数
pd.Series(range(5)).pipe(lambda x,y,z :(x**y)%z,2,5)
pd.Series(range(5)).pipe(lambda x:x+3).pipe(lambda x:x*3)
使用 apply 函数对 Series 对象使用 匿名函数
pd.Series(range(5)).apply(lambda x:x+3)
# 查看无偏标准差,使用 sem 函数
pd.Series(range(0,5)).sem()
# 按照日 进行分组查看交易的平均值 -1 表示倒数第一个
# data.groupby(data.日期.str.__getitem__(-1)).mean().apply(round)
# 查看日期尾数为 1 的数据
# data[data.日期.str.endswith('1')][:12]
# 查看日期尾数为 12 的交易数据,slice 为切片 (-2) 表示倒数两个
# data[data.日期.str.slice(-2) == '12']
# 查看日期中月份或天数包含 2 的交易数据
# data[data.日期.str.slice(-5).str.contains('2')][1:9]
# 对姓名和日期进行分组,并进行求和
dff = dataframe.groupby(by = ['姓名','日期'],as_index = False).sum()
# 使用 pivot 进行设置透视表
# 将 dff 的索引,列 设置成透视表形式
dff = dff.pivot(index = '姓名',columns = '日期',values = '交易额')
index 设置行索引
columns 设置列索引
values 对应的值
# 查看第一天的数据
dff.iloc[:,:1]
# 显示前两天每一天的交易总额以及每个人的交易金额
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'sum',margins = True).iloc[:,:2]
# 查看每个人每天购买的次数
dataframe.pivot_table(values = '交易额',index = '姓名',columns = '日期',aggfunc = 'count',margins = True)
# 每个人每天去过几次柜台,使用交叉表 crosstab
pd.crosstab(dataframe.姓名,dataframe.柜台)
# 每个人在每个柜台交易额的平均值,金额/天数
pd.crosstab(dataframe.姓名,dataframe.柜台,dataframe.交易额,aggfunc = 'mean').apply(lambda num:round(num,2) )
# 对 5 的余数进行分组
by 可以为匿名函数,字典,字符串
dataframe.groupby(by = lambda num:num % 5)['交易额'].sum()
dataframe.groupby(by = {7:'索引为7的行',15:'索引为15的行'})['交易额'].sum()
dataframe.groupby(by = '时段')['交易额'].sum()
# sort_values() 进行排序
# 查看交易额对应的排名
data['排名'] = data['交易额'].rank(ascending = False)
# 每个人不同时段的交易额
dataframe.groupby(by = ['姓名','时段'])['交易额'].sum()
# 查看上浮了 50% 之后依旧低于 1500 的交易额,查看 4 条数据
# 对 DataFrame 对象使用 map 匹配函数
dataframe.loc[dataframe.交易额 < 1500,'交易额'] = dataframe[dataframe.交易额 < 1500]['交易额'].map(lambda num:num*1.5)
# 丢弃缺失值之后的行数
len(dataframe.dropna())
# 包含缺失值的行
dataframe[dataframe['交易额'].isnull()]
# 使用整体均值的 80% 填充缺失值
# dataframe.fillna({'交易额':round(dataframe['交易额'].mean() * 0.8)},inplace = True)
# dataframe.iloc[[1,4,16],:]
# 重复值
dataframe[dataframe.duplicated()]
# 丢弃重复行
dataframe = dataframe.drop_duplicates()
# 查看是否有录入错误的工号和姓名
dff = dataframe[['工号','姓名']]
dff.drop_duplicates()
# 使用 diff 对数据进行差分
# 查看员工业绩波动情况(每一天和昨天的数据作比较)
dff = dataframe.groupby(by = '日期').sum()['交易额'].diff()
# 使用交叉表得到每人在各柜台交易额的平均值
data_group = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean').apply(round)
# 使用 concat 连接两个相同结构的 DataFrame 对象
df3 = pd.concat([df1,df2])
# 合并 merge 、 join
# 按照工号进行合并,随机查看 3 条数据
# 合并 df4 和 df5 两个DataFrame 对象
rows = np.random.randint(0,len(df5),3)
pd.merge(df4,df5).iloc[rows,:]
# 按照工号进行合并,指定其他同名列的后缀
# on 对应索引列名 suffixes 区分两个连接的对象
pd.merge(df1,df2,on = '工号',suffixes = ['_x','_y']).iloc[:,:]
# 两个表都设置工号为索引 set_index,设置两个连接对象的索引
df2.set_index('工号').join(df3.set_index('工号'),lsuffix = '_x',rsuffix = '_y').iloc[:]
# 读取 csv 对象时使用 usecols
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额','柜台'])
# 按照交易额降序和工号升序排序,查看五条数据
dataframe.sort_values(by = ['交易额','工号'],ascending = [False,True])[:5]
# 按工号升序排序
dataframe.sort_values(by = ['工号'])[:5]
# 三分钟重采样,计算均值
data.resample('3H').mean()
# 计算OHLC open,high,low,close
data.resample('5H').ohlc()
# 将日期替换为第二天
data.index = data.index + pd.Timedelta('1D')
# 查看指定日期的年份是否是闰年
pd.Timestamp('20200301').is_leap_year
# 查看所有的交易额信息
dataframe['交易额'].describe()
# 第一个最小交易额的行下标
index = dataframe['交易额'].idxmin()
# 最大交易额的行下标
index = dataframe['交易额'].idxmax()
dataframe.loc[index,'交易额']
# 2000
# 跳过 1 2 4 行,以第一列姓名为索引
dataframe2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
skiprows = [1,2,4],
index_col = 1)
skiprows 跳过的行
index_col 指定的列
dataframe.iloc[[0,2,3],:]
# 查看第四行的姓名数据
dataframe.at[3,'姓名']
pandas_查看数据特征和统计信息
# 查看数据特征和统计信息
import pandas as pd
# 读取文件
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看所有的交易额信息
dataframe['交易额'].describe()
'''
count 17.000000
mean 1024.117647
std 428.019550
min 580.000000
25% 700.000000
50% 850.000000
75% 1300.000000
max 2000.000000
Name: 交易额, dtype: float64
'''
# 查看四分位数
dataframe['交易额'].quantile([0,0.25,0.5,0.75,1.0])
'''
0.00 580.0
0.25 700.0
0.50 850.0
0.75 1300.0
1.00 2000.0
Name: 交易额, dtype: float64
'''
# 交易额中值
dataframe['交易额'].median()
# 850.0
# 交易额最小的三个数据
dataframe['交易额'].nsmallest(3)
'''
12 580
4 600
7 600
Name: 交易额, dtype: int64
'''
dataframe.nsmallest(3,'交易额')
'''
工号 姓名 日期 时段 交易额 柜台
12 1005 周七 20190302 9:00-14:00 580 日用品
4 1005 周七 20190301 9:00-14:00 600 日用品
7 1001 张三 20190302 14:00-21:00 600 蔬菜水果
'''
# 交易额最大的两个数据
dataframe['交易额'].nlargest(2)
'''
0 2000
1 1800
Name: 交易额, dtype: int64
'''
# 查看最大的交易额数据
dataframe.nlargest(2,'交易额')
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 20190301 9:00-14:00 2000 化妆品
1 1002 李四 20190301 14:00-21:00 1800 化妆品
'''
# 查看最后一个日期
dataframe['日期'].max()
# 20190303
# 查看最小的工号
dataframe['工号'].min()
# 1001
# 第一个最小交易额的行下标
index = dataframe['交易额'].idxmin()
# 0
# 第一个最小交易额
dataframe.loc[index,'交易额']
# 580
# 最大交易额的行下标
index = dataframe['交易额'].idxmax()
dataframe.loc[index,'交易额']
# 2000
pandas_读取Excel并筛选特定数据
# C:\Users\lenovo\Desktop\总结\Python
# 读取 Excel 文件并进行筛选
import pandas as pd
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
# 读取工号姓名时段交易额,使用默认索引
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['工号','姓名','时段','交易额'])
# 打印前十行数据
dataframe[:10]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
4 1005 周七 9:00-14:00 600
5 1006 钱八 14:00-21:00 700
6 1006 钱八 9:00-14:00 850
7 1001 张三 14:00-21:00 600
8 1001 张三 9:00-14:00 1300
9 1002 李四 14:00-21:00 1500
'''
# 跳过 1 2 4 行,以第一列姓名为索引
dataframe2 = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
skiprows = [1,2,4],
index_col = 1)
'''注:张三李四赵六的第一条数据跳过
工号 日期 时段 交易额 柜台
姓名
王五 1003 20190301 9:00-14:00 800 食品
周七 1005 20190301 9:00-14:00 600 日用品
钱八 1006 20190301 14:00-21:00 700 日用品
钱八 1006 20190301 9:00-14:00 850 蔬菜水果
张三 1001 20190302 14:00-21:00 600 蔬菜水果
'''
# 筛选符合特定条件的数据
# 读取超市营业额数据
dataframe = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 查看 5 到 10 的数据
dataframe[5:11]
'''
工号 姓名 日期 时段 交易额 柜台
5 1006 钱八 20190301 14:00-21:00 700 日用品
6 1006 钱八 20190301 9:00-14:00 850 蔬菜水果
7 1001 张三 20190302 14:00-21:00 600 蔬菜水果
8 1001 张三 20190302 9:00-14:00 1300 化妆品
9 1002 李四 20190302 14:00-21:00 1500 化妆品
10 1003 王五 20190302 9:00-14:00 1000 食品
'''
# 查看第六行的数据
dataframe.iloc[5]
'''
工号 1006
姓名 钱八
时段 14:00-21:00
交易额 700
Name: 5, dtype: object
'''
dataframe[:5]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
4 1005 周七 9:00-14:00 600
'''
# 查看第 1 3 4 行的数据
dataframe.iloc[[0,2,3],:]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
2 1003 王五 9:00-14:00 800
3 1004 赵六 14:00-21:00 1100
'''
# 查看第 1 3 4 行的第 1 2 列
dataframe.iloc[[0,2,3],[0,1]]
'''
工号 姓名
0 1001 张三
2 1003 王五
3 1004 赵六
'''
# 查看前五行指定,姓名、时段和交易额的数据
dataframe[['姓名','时段','交易额']][:5]
'''
姓名 时段 交易额
0 张三 9:00-14:00 2000
1 李四 14:00-21:00 1800
2 王五 9:00-14:00 800
3 赵六 14:00-21:00 1100
4 周七 9:00-14:00 600
'''
dataframe[:5][['姓名','时段','交易额']]
'''
姓名 时段 交易额
0 张三 9:00-14:00 2000
1 李四 14:00-21:00 1800
2 王五 9:00-14:00 800
3 赵六 14:00-21:00 1100
4 周七 9:00-14:00 600
'''
# 查看第 2 4 5 行 姓名,交易额 数据 loc 函数
dataframe.loc[[1,3,4],['姓名','交易额']]
'''
姓名 交易额
1 李四 1800
3 赵六 1100
4 周七 600
'''
# 查看第四行的姓名数据
dataframe.at[3,'姓名']
# '赵六'
# 查看交易额大于 1700 的数据
dataframe[dataframe['交易额'] > 1700]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
'''
# 查看交易额总和
dataframe.sum()
'''
工号 17055
姓名 张三李四王五赵六周七钱八钱八张三张三李四王五赵六周七钱八李四王五张三...
时段 9:00-14:0014:00-21:009:00-14:0014:00-21:009:00...
交易额 17410
dtype: object
'''
# 某一时段的交易总和
dataframe[dataframe['时段'] == '14:00-21:00']['交易额'].sum()
# 8300
# 查看张三在下午14:00之后的交易情况
dataframe[(dataframe.姓名 == '张三') & (dataframe.时段 == '14:00-21:00')][:10]
'''
工号 姓名 时段 交易额
7 1001 张三 14:00-21:00 600
'''
# 查看日用品的销售总额
# dataframe[dataframe['柜台'] == '日用品']['交易额'].sum()
# 查看张三总共的交易额
dataframe[dataframe['姓名'].isin(['张三'])]['交易额'].sum()
# 5200
# 查看交易额在 1500~3000 之间的记录
dataframe[dataframe['交易额'].between(1500,3000)]
'''
工号 姓名 时段 交易额
0 1001 张三 9:00-14:00 2000
1 1002 李四 14:00-21:00 1800
9 1002 李四 14:00-21:00 1500
'''
pandas_重采样多索引标准差协方差
# 重采样 多索引 标准差 协方差
import pandas as pd
import numpy as np
import copy
# 设置列对齐
pd.set_option("display.unicode.ambiguous_as_wide",True)
pd.set_option("display.unicode.east_asian_width",True)
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx')
# 将日期设置为 python 中的日期类型
data.日期 = pd.to_datetime(data.日期)
'''
工号 姓名 日期 时段 交易额 柜台
0 1001 张三 1970-01-01 00:00:00.020190301 9:00-14:00 2000 化妆品
1 1002 李四 1970-01-01 00:00:00.020190301 14:00-21:00 1800 化妆品
2 1003 王五 1970-01-01 00:00:00.020190301 9:00-14:00 800 食品
'''
# 每七天营业的总额
data.resample('7D',on = '日期').sum()['交易额']
'''
日期
1970-01-01 17410
Freq: 7D, Name: 交易额, dtype: int64
'''
# 每七天营业总额
data.resample('7D',on = '日期',label = 'right').sum()['交易额']
'''
日期
1970-01-08 17410
Freq: 7D, Name: 交易额, dtype: int64
'''
# 每七天营业额的平均值
func = lambda item:round(np.sum(item)/len(item),2)
data.resample('7D',on = '日期',label = 'right').apply(func)['交易额']
'''
日期
1970-01-08 1024.12
Freq: 7D, Name: 交易额, dtype: float64
'''
# 每七天营业额的平均值
func = lambda num:round(num,2)
data.resample('7D',on = '日期',label = 'right').mean().apply(func)['交易额']
# 1024.12
# 删除工号这一列
data.drop('工号',axis = 1,inplace = True)
data[:2]
'''
姓名 日期 时段 交易额 柜台
0 张三 1970-01-01 00:00:00.020190301 9:00-14:00 2000 化妆品
1 李四 1970-01-01 00:00:00.020190301 14:00-21:00 1800 化妆品
'''
# 按照姓名和柜台进行分组汇总
data = data.groupby(by = ['姓名','柜台']).sum()[:3]
'''
交易额
姓名 柜台
周七 日用品 1180
张三 化妆品 4600
蔬菜水果 600
'''
# 查看张三的汇总数据
data.loc['张三',:]
'''
交易额
柜台
化妆品 4600
蔬菜水果 600
'''
# 查看张三在蔬菜水果的交易数据
data.loc['张三','蔬菜水果']
'''
交易额 600
Name: (张三, 蔬菜水果), dtype: int64
'''
# 多索引
# 重新读取,使用第二列和第六列作为索引,排在前面
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',index_col = [1,5])
data[:5]
'''
工号 日期 时段 交易额
姓名 柜台
张三 化妆品 1001 20190301 9:00-14:00 2000
李四 化妆品 1002 20190301 14:00-21:00 1800
王五 食品 1003 20190301 9:00-14:00 800
赵六 食品 1004 20190301 14:00-21:00 1100
周七 日用品 1005 20190301 9:00-14:00 600
'''
# 丢弃工号列
data.drop('工号',axis = 1,inplace = True)
data[:5]
'''
日期 时段 交易额
姓名 柜台
张三 化妆品 20190301 9:00-14:00 2000
李四 化妆品 20190301 14:00-21:00 1800
王五 食品 20190301 9:00-14:00 800
赵六 食品 20190301 14:00-21:00 1100
周七 日用品 20190301 9:00-14:00 600
'''
# 按照柜台进行排序
dff = data.sort_index(level = '柜台',axis = 0)
dff[:5]
'''
工号 日期 时段 交易额
姓名 柜台
张三 化妆品 1001 20190301 9:00-14:00 2000
化妆品 1001 20190302 9:00-14:00 1300
化妆品 1001 20190303 9:00-14:00 1300
李四 化妆品 1002 20190301 14:00-21:00 1800
化妆品 1002 20190302 14:00-21:00 1500
'''
# 按照姓名进行排序
dff = data.sort_index(level = '姓名',axis = 0)
dff[:5]
'''
工号 日期 时段 交易额
姓名 柜台
周七 日用品 1005 20190301 9:00-14:00 600
日用品 1005 20190302 9:00-14:00 580
张三 化妆品 1001 20190301 9:00-14:00 2000
化妆品 1001 20190302 9:00-14:00 1300
化妆品 1001 20190303 9:00-14:00 1300
'''
# 按照柜台进行分组求和
dff = data.groupby(level = '柜台').sum()['交易额']
'''
柜台
化妆品 7900
日用品 2600
蔬菜水果 2960
食品 3950
Name: 交易额, dtype: int64
'''
#标准差
data = pd.DataFrame({'A':[3,3,3,3,3],'B':[1,2,3,4,5],
'C':[-5,-4,1,4,5],'D':[-45,15,63,40,50]
})
'''
A B C D
0 3 1 -5 -45
1 3 2 -4 15
2 3 3 1 63
3 3 4 4 40
4 3 5 5 50
'''
# 平均值
data.mean()
'''
A 3.0
B 3.0
C 0.2
D 24.6
dtype: float64
'''
# 标准差
data.std()
'''
A 0.000000
B 1.581139
C 4.549725
D 42.700117
dtype: float64
'''
# 标准差的平方
data.std()**2
'''
A 0.0
B 2.5
C 20.7
D 1823.3
dtype: float64
'''
# 协方差
data.cov()
'''
A B C D
A 0.0 0.00 0.00 0.00
B 0.0 2.50 7.00 53.75
C 0.0 7.00 20.70 153.35
D 0.0 53.75 153.35 1823.30
'''
# 指定索引为 姓名,日期,时段,柜台,交易额
data = pd.read_excel(r'C:\Users\lenovo\Desktop\总结\Python\超市营业额.xlsx',
usecols = ['姓名','日期','时段','柜台','交易额'])
# 删除缺失值和重复值,inplace = True 直接丢弃
data.dropna(inplace = True)
data.drop_duplicates(inplace = True)
# 处理异常值
data.loc[data.交易额 < 200,'交易额'] = 200
data.loc[data.交易额 > 3000,'交易额'] = 3000
# 使用交叉表得到不同员工在不同柜台的交易额平均值
dff = pd.crosstab(data.姓名,data.柜台,data.交易额,aggfunc = 'mean')
dff[:5]
'''
柜台 化妆品 日用品 蔬菜水果 食品
姓名
周七 NaN 590.0 NaN NaN
张三 1533.333333 NaN 600.0 NaN
李四 1650.000000 NaN 680.0 NaN
王五 NaN NaN 830.0 900.0
赵六 NaN NaN NaN 1075.0
'''
# 查看数据的标准差
dff.std()
'''
柜台
化妆品 82.495791
日用品 84.852814
蔬菜水果 120.277457
食品 123.743687
dtype: float64
'''
# 协方差
dff.cov()
'''
柜台 化妆品 日用品 蔬菜水果 食品
柜台
化妆品 6805.555556 NaN 4666.666667 NaN
日用品 NaN 7200.0 NaN NaN
蔬菜水果 4666.666667 NaN 14466.666667 NaN
食品 NaN NaN NaN 15312.5
'''
Numpy random函数
import numpy as np
# 生成一个随机数组
np.random.randint(0,6,3)
# array([1, 1, 3])
# 生成一个随机数组(二维数组)
np.random.randint(0,6,(3,3))
'''
array([[4, 4, 1],
[2, 1, 0],
[5, 0, 0]])
'''
# 生成十个随机数在[0,1)之间
np.random.rand(10)
'''
array([0.9283789 , 0.43515554, 0.27117021, 0.94829333, 0.31733981,
0.42314939, 0.81838647, 0.39091899, 0.33571004, 0.90240897])
'''
# 从标准正态分布中随机抽选出3个数
np.random.standard_normal(3)
# array([0.34660435, 0.63543859, 0.1307822 ])
# 返回三页四行两列的标准正态分布数
np.random.standard_normal((3,4,2))
'''
array([[[-0.24880261, -1.17453957],
[ 0.0295264 , 1.04038047],
[-1.45201783, 0.57672288],
[ 1.10282747, -2.08699482]],
[[-0.3813943 , 0.47845782],
[ 0.97708005, 1.1760147 ],
[ 1.3414987 , -0.629902 ],
[-0.29780567, 0.60288726]],
[[ 1.43991349, -1.6757028 ],
[-1.97956809, -1.18713495],
[-1.39662811, 0.34174275],
[ 0.56457553, -0.83224426]]])
'''
Numpy修改数组中的元素值
import numpy as np
x = np.arange(8)
# [0 1 2 3 4 5 6 7]
# 在数组尾部追加一个元素
np.append(x,10)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 10])
# 在数组尾部追加多个元素
np.append(x,[15,16,17])
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 15, 16, 17])
# 使用 数组下标修改元素的值
x[0] = 99
# array([99, 1, 2, 3, 4, 5, 6, 7])
# 在指定位置插入数据
np.insert(x,0,54)
# array([54, 99, 1, 2, 3, 4, 5, 6, 7])
# 创建一个多维数组
x = np.array([[1,2,3],[11,22,33],[111,222,333]])
'''
array([[ 1, 2, 3],
[ 11, 22, 33],
[111, 222, 333]])
'''
# 修改第 0 行第 2 列的元素值
x[0,2] = 9
'''
array([[ 1, 2, 9],
[ 11, 22, 33],
[111, 222, 333]])
'''
# 行数大于等于 1 的,列数大于等于 1 的置为 0
x[1:,1:] = 1
'''
array([[ 1, 2, 9],
[ 11, 1, 1],
[111, 1, 1]])
'''
# 同时修改多个元素值
x[1:,1:] = [7,8]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 7, 8]])
'''
x[1:,1:] = [[7,8],[9,10]]
'''
array([[ 1, 2, 9],
[ 11, 7, 8],
[111, 9, 10]])
'''
Numpy创建数组
# 导入numpy 并赋予别名 np
import numpy as np
# 创建数组的常用的几种方式(列表,元组,range,arange,linspace(创建的是等差数组),zeros(全为 0 的数组),ones(全为 1 的数组),logspace(创建的是对数数组))
# 列表方式
np.array([1,2,3,4])
# array([1, 2, 3, 4])
# 元组方式
np.array((1,2,3,4))
# array([1, 2, 3, 4])
# range 方式
np.array(range(4)) # 不包含终止数字
# array([0, 1, 2, 3])
# 使用 arange(初始位置=0,末尾,步长=1)
np.arange(1,8,2)
# array([1, 3, 5, 7])
np.arange(8)
# array([0, 1, 2, 3, 4, 5, 6, 7])
# 使用 linspace(起始数字,终止数字,包含数字的个数[,endpoint = False]) 生成等差数组
# 生成等差数组,endpoint 为 True 则包含末尾数字
np.linspace(1,3,4,endpoint=False)
# array([1. , 1.5, 2. , 2.5])
np.linspace(1,3,4,endpoint=True)
# array([1. , 1.66666667, 2.33333333, 3. ])
# 创建全为零的一维数组
np.zeros(3)
# 创建全为一的一维数组
np.ones(4)
# array([1., 1., 1., 1.])
np.linspace(1,3,4)
# array([1. , 1.66666667, 2.33333333, 3. ])
# np.logspace(起始数字,终止数字,数字个数,base = 10) 对数数组
np.logspace(1,3,4)
# 相当于 10 的 linspace(1,3,4) 次方
# array([ 10. , 46.41588834, 215.443469 , 1000. ])
np.logspace(1,3,4,base = 2)
# 2 的 linspace(1,3,4) 次方
# array([2. , 3.1748021, 5.0396842, 8. ])
# 创建二维数组(列表嵌套列表)
np.array([[1,2,3],[4,5,6]])
'''
array([[1, 2, 3],
[4, 5, 6]])
'''
# 创建全为零的二维数组
# 两行两列
np.zeros((2,2))
'''
array([[0., 0.],
[0., 0.]])
'''
# 三行三列
np.zeros((3,2))
'''
array([[0., 0.],
[0., 0.],
[0., 0.]])
'''
# 创建一个单位数组
np.identity(3)
'''
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
'''
# 创建一个对角矩阵,(参数为对角线上的数字)
np.diag((1,2,3))
'''
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
'''
Numpy改变数组的形状
import numpy as np
n = np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 查看数组的大小
n.size
# 10
# 将数组分为两行五列
n.shape = 2,5
'''
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
'''
# 显示数组的维度
n.shape
# (2, 5)
# 设置数组的维度,-1 表示自动计算
n.shape = 5,-1
'''
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
'''
# 将新数组设置为调用数组的两行五列并返回
x = n.reshape(2,5)
'''
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
'''
x = np.arange(5)
# 将数组设置为两行,没有数的设置为 0
x.resize((2,10))
'''
array([[0, 1, 2, 3, 4, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
'''
# 将 x 数组的两行五列形式显示,不改变 x 的值
np.resize(x,(2,5))
'''
array([[0, 1, 2, 3, 4],
[0, 0, 0, 0, 0]])
'''
Numpy数组排序
import numpy as np
x = np.array([1,4,5,2])
# array([1, 4, 5, 2])
# 返回排序后元素的原下标
np.argsort(x)
# array([0, 3, 1, 2], dtype=int64)
# 输出最大值的下标
x.argmax( )
# 2
# 输出最小值的下标
x.argmin( )
# 0
# 对数组进行排序
x.sort( )
print(x)
# [1 2 4 5]
Numpy数组的函数
import numpy as np
# 将 0~100 10等分
x = np.arange(0,100,10)
# array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
# 每个数组元素对应的正弦值
np.sin(x)
'''
array([ 0. , -0.54402111, 0.91294525, -0.98803162, 0.74511316,
-0.26237485, -0.30481062, 0.77389068, -0.99388865, 0.89399666])
'''
# 每个数组元素对应的余弦值
np.cos(x)
'''
array([ 1. , -0.83907153, 0.40808206, 0.15425145, -0.66693806,
0.96496603, -0.95241298, 0.6333192 , -0.11038724, -0.44807362])
'''
# 对参数进行四舍五入
np.round(np.cos(x))
# array([ 1., -1., 0., 0., -1., 1., -1., 1., -0., -0.])
# 对参数进行上入整数 3.3->4
np.ceil(x/3)
# array([ 0., 4., 7., 10., 14., 17., 20., 24., 27., 30.])
# 分段函数
x = np.random.randint(0,10,size=(1,10))
# array([[0, 3, 6, 7, 9, 4, 9, 8, 1, 8]])
# 大于 4 的置为 0
np.where(x > 4,0,1)
# array([[1, 1, 0, 0, 0, 1, 0, 0, 1, 0]])
# 小于 4 的乘 2 ,大于 7 的乘3
np.piecewise(x,[x<4,x>7],[lambda x:x*2,lambda x:x*3])
# array([[ 0, 6, 0, 0, 27, 0, 27, 24, 2, 24]])
Numpy数组的运算
import numpy as np
x = np.array((1,2,3,4,5))
# 使用 * 进行相乘
x*2
# array([ 2, 4, 6, 8, 10])
# 使用 / 进行相除
x / 2
# array([0.5, 1. , 1.5, 2. , 2.5])
2 / x
# array([2. , 1. , 0.66666667, 0.5 , 0.4 ])
# 使用 // 进行整除
x//2
# array([0, 1, 1, 2, 2], dtype=int32)
10//x
# array([10, 5, 3, 2, 2], dtype=int32)
# 使用 ** 进行幂运算
x**3
# array([ 1, 8, 27, 64, 125], dtype=int32)
2 ** x
# array([ 2, 4, 8, 16, 32], dtype=int32)
# 使用 + 进行相加
x + 2
# array([3, 4, 5, 6, 7])
# 使用 % 进行取模
x % 3
# array([1, 2, 0, 1, 2], dtype=int32)
# 数组与数组之间的运算
# 使用 + 进行相加
np.array([1,2,3,4]) + np.array([11,22,33,44])
# array([12, 24, 36, 48])
np.array([1,2,3,4]) + np.array([3])
# array([4, 5, 6, 7])
n = np.array((1,2,3))
# +
n + n
# array([2, 4, 6])
n + np.array([4])
# array([5, 6, 7])
# *
n * n
# array([1, 4, 9])
n * np.array(([1,2,3],[4,5,6],[7,8,9]))
'''
array([[ 1, 4, 9],
[ 4, 10, 18],
[ 7, 16, 27]])
'''
# -
n - n
# array([0, 0, 0])
# /
n/n
# array([1., 1., 1.])
# **
n**n
# array([ 1, 4, 27], dtype=int32)
x = np.array((1,2,3))
y = np.array((4,5,6))
# 数组的内积运算(对应位置上元素相乘)
np.dot(x,y)
# 32
sum(x*y)
# 32
# 布尔运算
n = np.random.rand(4)
# array([0.53583849, 0.09401473, 0.07829069, 0.09363152])
# 判断数组中的元素是否大于 0.5
n > 0.5
# array([ True, False, False, False])
# 将数组中大于 0.5 的元素显示
n[n>0.5]
# array([0.53583849])
# 找到数组中 0.05 ~ 0.4 的元素总数
sum((n > 0.05)&(n < 0.4))
# 3
# 是否都大于 0.2
np.all(n > 0.2)
# False
# 是否有元素小于 0.1
np.any(n < 0.1)
# True
# 数组与数组之间的布尔运算
a = np.array([1,4,7])
# array([1, 4, 7])
b = np.array([4,3,7])
# array([4, 3, 7])
# 在 a 中是否有大于 b 的元素
a > b
# array([False, True, False])
# 在 a 中是否有等于 b 的元素
a == b
# array([False, False, True])
# 显示 a 中 a 的元素等于 b 的元素
a[a == b]
# array([7])
# 显示 a 中的偶数且小于 5 的元素
a[(a%2 == 0) & (a < 5)]
# array([4])
Numpy访问数组元素
import numpy as np
n = np.array(([1,2,3],[4,5,6],[7,8,9]))
'''
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
'''
# 第一行元素
n[0]
# array([1, 2, 3])
# 第一行第三列元素
n[0,2]
# 3
# 第一行和第二行的元素
n[[0,1]]
'''
array([[1, 2, 3],
[4, 5, 6]])
'''
# 第一行第三列,第三行第二列,第二行第一列
n[[0,2,1],[2,1,0]]
# array([3, 8, 4])
a = np.arange(8)
# array([0, 1, 2, 3, 4, 5, 6, 7])
# 将数组倒序
a[::-1]
# array([7, 6, 5, 4, 3, 2, 1, 0])
# 步长为 2
a[::2]
# array([0, 2, 4, 6])
# 从 0 到 4 的元素
a[:5]
# array([0, 1, 2, 3, 4])
c = np.arange(16)
# array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15])
c.shape = 4,4
'''
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
'''
# 第一行,第三个元素到第五个元素(如果没有则输出到末尾截止)
c[0,2:5]
# array([2, 3])
# 第二行元素
c[1]
# array([4, 5, 6, 7])
# 第三行到第六行,第三列到第六列
c[2:5,2:5]
'''
array([[10, 11],
[14, 15]])
'''
# 第二行第三列元素和第三行第四列元素
c[[1,2],[2,3]]
# array([ 6, 11])
# 第一行和第三行的第二列到第三列的元素
c[[0,2],1:3]
'''
array([[ 1, 2],
[ 9, 10]])
'''
# 第一列和第三列的所有横行元素
c[:,[0,2]]
'''
array([[ 0, 2],
[ 4, 6],
[ 8, 10],
[12, 14]])
'''
# 第三列所有元素
c[:,2]
# array([ 2, 6, 10, 14])
# 第二行和第四行的所有元素
c[[1,3]]
'''
array([[ 4, 5, 6, 7],
[12, 13, 14, 15]])
'''
# 第一行的第二列,第四列元素,第四行的第二列,第四列元素
c[[0,3]][:,[1,3]]
'''
array([[ 1, 3],
[13, 15]])
'''
2020-07-25
本文来自博客园,作者:Hany47315,转载请注明原文链接:https://www.cnblogs.com/hany-postq473111315/p/13376095.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号