
CNN 各layer汇总(flatten, concat, slice, dropout, pooling, overlapping pooling, SPP, relu,leaky relu...)
Flattening:类型为:Flatten
基于某个axis进行偏平的意思,如 axis = 1 ,fattens an input of shape n * c * h * w to a simple vector output of shape n * (c*h*w))
Reshape:(重新调整维度),类型为:Reshape
在不改变数据的情况下,改变输入的维度
layer { name: "reshape" type: "Reshape" bottom: "input" top: "output" reshape_param { shape { dim: 0 # copy the dimension from below dim: 2 dim: 3 dim: -1 # infer it from the other dimensions } } }
有一个可选的参数组shape,用于指定blob数据的各维的值(bolb是一个四维的数据:n*c*w*h)。
dim:0 表示维度不变,即输入和输出是相同的维度。
dim:2 或 dim:3 将原来的维度变成2或3
dim:-1 表示由系统自动计算维度。数据的总量不变,系统会根据blob数据的其它三维来自动计算当前维的维度值 。
假设原数据为:64*3*28*28, 表示64张3通道的28*28的彩色图片
经过reshape变换:

reshape_param {
shape {
dim: 0
dim: 0
dim: 14
dim: -1
}
}
输出数据为:64*3*14*56,系统自己算的。blob里面的数据量不变,知道三个维度,另外一个就知道了
Cocatenation(把多个输入可以串联起来):类型为:Concat
在某个维度,将输入的layer组合起来,是slice的逆过程
Slicing(可以对输入进行切片)类型为:Slice
Slice layer 的作用是将bottom按照需要分解成多个tops。(与split layer的不一样在于spliit的作用是将bottom复制多份,输出到tops)
首先我们先看一下slice layer 在prototxt里面的书写
layer { name: "slice" type: "Slice" bottom: "input" top: "output1" top: "output2" top: "output3" top: "output4" slice_param { axis: 1 slice_point: 1 slice_point: 3 slice_point: 4 } }
这里假设input的维度是N*5*H*W,tops输出的维度分别为N*1*H*W N*2*H*WN*1*H*WN*1*H*W 。
这里需要注意的是,如果有slice_point,slice_point的个数一定要等于top的个数减一。
axis表示要进行分解的维度。
slice_point的作用是将axis按照slic_point 进行分解。
slice_point没有设置的时候则对axis进行均匀分解。
Elementwise Operations(类型为Eltwise), Argmax(类型为ArgMax), Softmax(类型为Softmax),
Mean-Variance Normalization(类型为MVN)
Dropout(防止过拟合的trick):类型为Dropout
可以随机让网络某些隐含层节点的权重不工作
layer { name: "drop7" type: "Dropout" bottom: "fc7-conv" top: "fc7-conv" dropout_param { dropout_ratio: 0.5 } }layer { name: "drop7" type: "Dropout" bottom: "fc7-conv" top: "fc7-conv" dropout_param { dropout_ratio: 0.5 } }
只需要设置一个dropout_ratio就可以了。
Pooling
1. 一般池化(General Pooling)
池化作用于图像中不重合的区域(这与卷积操作不同),我们定义池化窗口的大小为sizeX,即下图中红色正方形的边长,定义两个相邻池化窗口的水平位移/竖直位移为stride。一般池化由于每一池化窗口都是不重复的,所以sizeX=stride,最常见的池化操作为平均池化mean pooling和最大池化max pooling:
平均池化:计算图像区域的平均值作为该区域池化后的值。
最大池化:选图像区域的最大值作为该区域池化后的值。参考图[2]。
2,重叠池化(OverlappingPooling)
重叠池化正如其名字所说的,相邻池化窗口之间会有重叠区域,此时sizeX>stride。
论文中,作者使用了重叠池化,其他的设置都不变的情况下, top-1和top-5 的错误率分别减少了0.4% 和0.3%。[“Imagenet classification with deep convolutional neural networks,”in NIPS,2012]。
3. 空金字塔池化(Spatial Pyramid Pooling)
空间金字塔池化可以把任何尺度的图像的卷积特征转化成相同维度,这不仅可以让CNN处理任意尺度的图像,还能避免cropping和warping操作,导致一些信息的丢失,具有非常重要的意义。
一般的CNN都需要输入图像的大小是固定的,这是因为全连接层的输入需要固定输入维度,但在卷积操作是没有对图像尺度有限制,所有作者提出了空间金字塔池化,先让图像进行卷积操作,然后转化成维度相同的特征输入到全连接层,这个可以把CNN扩展到任意大小的图像。
空间金字塔池化的思想来自于Spatial Pyramid Model,它一个pooling变成了多个scale的pooling。用不同大小池化窗口作用于卷积特征,我们可以得到1X1,2X2,4X4的池化结果,由于conv5中共有256个过滤器,所以得到1个256维的特征,4个256个特征,以及16个256维的特征,然后把这21个256维特征链接起来输入全连接层,通过这种方式把不同大小的图像转化成相同维度的特征,后面通常接FC。
对于不同的图像要得到相同大小的pooling结果,就需要根据图像的大小动态的计算池化窗口的大小和步长。假设conv5输出的大小为a*a,需要得到n*n大小的池化结果,可以让窗口大小sizeX为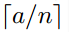
SPP其实就是一种多个scale的pooling,可以获取图像中的多尺度信息;在CNN中加入SPP后,可以让CNN处理任意大小的输入,这让模型变得更加的flexible。
参考Kaiming He:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition,2014
4,Global average Pooling
global average pooling 这个概念出自于 network in network ,主要是用来解决全连接的问题,其主要是是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量进行softmax中进行计算。举个例子:
假如,最后的一层的数据是10个6*6的特征图,global average pooling是将每一张特征图计算所有像素点的均值,输出一个数据值,
这样10 个特征图就会输出10个数据点,将这些数据点组成一个1*10的向量的话,就成为一个特征向量,就可以送入到softmax的分类中计算了。
原文中介绍这样做主要是进行全连接的替换,减少参数的数量,这样计算的话,global average pooling层是没有数据参数的,这也与network in network 有关,其文章中提出了一种非线性的 类似卷积核的mlpconv的感知器的方法,计算图像的分块的值可以得到空间的效果,这样就取代了pooling的作用,但是会引入一些参数,但是为了平衡,作者提出了使用global average pooling。
5,ReLU和LeakyReLU区别
1、ReLU(Rectified Line Unit,ReLU):修正线性单元,神经网络中常用的激活函数。ReLU的输入是x,当x>0, 其梯度不为0, 可用于权重更新;当x<0, 其梯度为0, 权重无法更新,后续训练中处于静默状态(学习速率变慢,神经元处于不学习状态)。
函数图像:
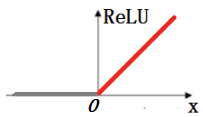
表达式:
(1)前向过程:ReLU(x)=max(0,x)
(2)后向传播:
a) 将ReLU看作神经网络中的一层,设第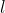 层输出是
层输出是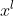 , 然后输入ReLU激活函数后输出是
, 然后输入ReLU激活函数后输出是
b)设损失函数L关于第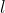 层输出
层输出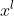 的偏导是
的偏导是
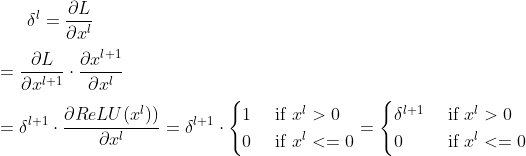
2、Leaky Relu:(与Relu的不同之处在于负轴保留了非常小的常数leak,使得输入信息小于0时,信息没有完全丢掉,进行了相应的保留),即ReLU在取值小于零部分没有梯度,LeakyReLU在取值小于0部分给一个很小的梯度
函数图像:

表达式:
(1)前向过程:
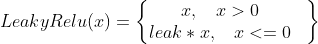
leak是小数,例如leak=0.01
(2)后向传播:
a) 将Leaky ReLU看作神经网络中的一层,设第层输出是, 然后输入Leaky ReLU激活函数后输出是
b)设损失函数L关于第层输出的偏导是
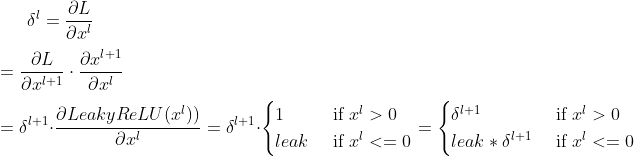
参考:
1,http://m.blog.csdn.net/m0_37407756/article/details/72235667
2,https://blog.csdn.net/mao_kun/article/details/50507376
3,https://blog.csdn.net/losteng/article/details/51520555
4,https://blog.csdn.net/qq_37342061/article/details/99090590
LED照明:依古齐尼(深圳)照明科技有限公司
13723451660 刘先生
posted on 2018-01-05 18:01 Sanny.Liu-CV&&ML 阅读(3247) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号