
Rethinking“Batch”in BatchNorm
转载:https://www.cnblogs.com/wanghui-garcia/p/14840712.html 值得推荐
转载:https://zhuanlan.zhihu.com/p/373674481
Abstract
BatchNorm是现代卷积神经网络的重要组成部分。它对“batches”而不是单个样本进行操作的独特特性,引入了与深度学习中大多数其他操作显著不同的行为。因此,它会导致许多隐藏的警告,可能以微妙的方式对模型的性能产生负面影响。本文对视觉识别任务中的这类问题进行了深入的研究,指出解决这些问题的关键是在BatchNorm的“batch”概念中重新思考不同的选择。通过提出这些警告和它们的缓解措施,我们希望这篇综述能够帮助研究人员更有效地使用BatchNorm。
1. Introduction
BatchNorm[33]是现代卷积神经网络(CNNs)的一个重要组成部分。经验证明,它可以降低模型对学习率和初始化的敏感性,并可以对各种网络架构进行训练。该方法提高了模型的收敛速度,并为抑制过拟合提供了正则化效果。由于这些吸引人的特性,自BatchNorm发明以来,它已经被包括在几乎所有最先进的CNN架构中[24,28,70,58]。
尽管BatchNorm有很多优点,但是关于如何在不同的场景中应用BatchNorm还有很多微妙的选择。做出次优选择可能会降低模型的性能:模型仍然会进行训练,但可能收敛到较低的准确性上。因此,在CNNs的设计中,BatchNorm有时被视为“necessary evil”[52]。本文的目标是总结在应用BatchNorm时可能会降临到实践者身上的陷阱,并提供克服这些陷阱的建议。
BatchNorm与其他深度学习算子的关键区别在于,它是对成批数据而不是单个样本进行操作的。BatchNorm混合batch的信息以计算归一化统计信息,而其他操作符独立处理batch中的每个样本。因此,BatchNorm的输出不仅取决于单个样本的性质,还取决于将样本分组成batch的方式。为了展示一些样本分组的不同方式,图1(左)说明了BatchNorm操作的batch可能与随机梯度下降(SGD)每一步中使用的mini-batch不同。图1(右)进一步显示了当样本来自不同域时选择BatchNorm的batch的额外选择。

本文研究了BatchNorm中批处理的这些选择。我们证明了天真地应用BatchNorm而不考虑batch构建的不同选择会在许多方面产生负面影响,但是通过在batch概念中谨慎选择,模型性能可以得到改善。
第3节讨论了在推理过程中使用的归一化统计信息,其中BatchNorm的“batch”表示的是整个训练总体。我们重新讨论在mini-batch统计中使用指数移动平均(exponential moving average,EMA)的常见选择,并表明EMA可能给出不准确的估计,从而导致不稳定的验证性能。我们还说明了PreciseBN是一种能更准确地估计总体统计数据的替代方法。
与大多数神经网络操作符不同,BatchNorm在训练和推理过程中表现不同:它在训练过程中使用mini-batch统计数据,在推理过程中使用总体统计数据。第4节重点讨论了这种设置可能导致的不一致性,并演示了在推理过程中使用mini-batch统计信息或在训练过程中使用总体统计信息是有益的情况。
第5节检查了BatchNorm的输入来自不同领域的情况,其要么是由于使用多个数据集,要么是由于层共享。我们表明,在这样的设置,batches的次优选择可能导致域偏移。
BatchNorm在训练期间使用mini-batch统计可能会导致训练样本之间的信息轻微泄漏。第六章研究了这种行为,并表明谨慎选择标准化batches可以减轻这种潜在的有害影响。
在每一章节中,我们都用研究良好的视觉识别任务进行实验,以证明使用BatchNorm看似标准的方法可能会导致次优行为,从而微妙地降低模型性能。在每种情况下,计算BatchNorm的标准化统计信息的另一种不常见的方法都会带来显著的改进。
本文综述了目前存在的问题及解决办法。我们将要讨论的许多主题已经在之前的文献中提到过;然而,它们分散在许多论文中,可能不会被广泛欣赏。根据我们的经验,BatchNorm的这些细微之处经常会在开发新模型时带来麻烦。因此,我们的目标是收集大量关于BatchNorm的“dark knowledge”到一个地方,我们希望这篇综述可以作为参考指南,帮助从业者避免BatchNorm造成的常见陷阱。
2. A Review of BatchNorm
在这里我们简单地回顾一下Batch Normalization,主要集中于其在CNNs中的使用。BatchNorm的输入x是形状为(C,H,W),即有C个channels且空间大小为HxW的CNN特征。BatchNorm使用每个channels的统计数据,即均值和方差![]() 去归一化输入x来计算得到输出y:
去归一化输入x来计算得到输出y:
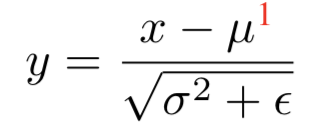
用来计算μ和σ2的机制可能不同。最常用的设置(其给了BatchNorm这个名字)是μ和σ2为mini-batch统计数据![]() ,即在训练中N个特征组成的mini-batch的经验均值和方差。mini-batch是一个形状为(N,C,H,W)的4D tensor,即:
,即在训练中N个特征组成的mini-batch的经验均值和方差。mini-batch是一个形状为(N,C,H,W)的4D tensor,即:
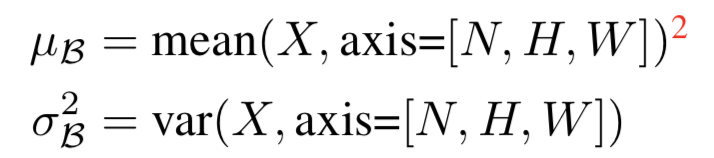
在推理中,μ和σ2不是从mini-batches中计算得到的,总体统计数据![]() 是从训练集中估计得到的,并用于归一化。
是从训练集中估计得到的,并用于归一化。
正如我们将在论文中看到的,关于什么是“batch”,也就是我们计算μ、σ2的数据是什么,可能有许多其他的选择。在不同的场景中,batch的大小、batch的数据源或计算统计数据的算法可能会有所不同,从而导致不一致,最终影响模型的泛化。
我们在本文中对BatchNorm的定义与惯例略有不同:我们不把通常遵循归一化的channel-wise仿射变换视为BatchNorm的一部分。我们的所有实验都像往常一样包含这个仿射变换,但我们把它看作是一个独立的、常规的层,因为它独立于样本(它实际上相当于一个深度为1 × 1的卷积层)。这种区别将我们的注意力集中在BatchNorm中“batch”的独特用法上。
通过排除仿射变换,总体统计![]() 成为BatchNorm唯一的可学习参数。然而,与神经网络中的其他参数不同,梯度下降既不使用也不更新它们。相反,总体统计将使用其他算法(例如EMA)进行训练,第3节将考虑替代算法。把总体统计的计算看作一种训练形式,可以帮助我们用泛化的标准概念诊断这个过程。在第5节中,我们将看到缺乏训练的总体统计数据会由于域偏移而影响泛化。
成为BatchNorm唯一的可学习参数。然而,与神经网络中的其他参数不同,梯度下降既不使用也不更新它们。相反,总体统计将使用其他算法(例如EMA)进行训练,第3节将考虑替代算法。把总体统计的计算看作一种训练形式,可以帮助我们用泛化的标准概念诊断这个过程。在第5节中,我们将看到缺乏训练的总体统计数据会由于域偏移而影响泛化。
3. Whole Population as a Batch
在训练期间,BatchNorm用mini-batch的样本计算归一化统计数据。然而,当模型用于测试时,通常不再有mini-batch的概念。最初的建议是[33],即在测试时,特征应该用总体统计量![]() 来归一化,其是在整个训练集上计算得到的。这里将
来归一化,其是在整个训练集上计算得到的。这里将![]() 定义为使用整个数据作为“batch”计算得到的batch统计数据
定义为使用整个数据作为“batch”计算得到的batch统计数据![]() 。
。
由于![]() 是从数据中计算出来的,因此它们被认为是使用不同的算法对给定数据进行训练得到的。这种训练过程通常是无监督且便宜的,但它对模型的泛化是至关重要的。在本节中,我们将说明广泛使用的EMA算法并不能总是准确地训练总体统计数据,因此我们还将讨论其他算法。
是从数据中计算出来的,因此它们被认为是使用不同的算法对给定数据进行训练得到的。这种训练过程通常是无监督且便宜的,但它对模型的泛化是至关重要的。在本节中,我们将说明广泛使用的EMA算法并不能总是准确地训练总体统计数据,因此我们还将讨论其他算法。
3.1. Inaccuracy of EMA
[33]提出了指数移动平均( exponential moving average,EMA)可以用来有效地计算总体统计。这种方法现在已经成为深度学习库的标准。然而,我们将在本节中看到,尽管EMA普遍存在,但它可能不会产生一个良好的总体统计估计。
为了估计![]() ,EMAs在每个训练迭代中都会进行更新:
,EMAs在每个训练迭代中都会进行更新:

其中![]() 是每次迭代的batch均值和方差,momentum为
是每次迭代的batch均值和方差,momentum为![]()
因为以下的原因,指数平均可能趋向总体统计的次优估计:
- λ较大时统计收敛速度较慢。由于每次更新迭代只对EMA贡献了一小部分(1−λ),因此需要大量的更新才能使EMA收敛到稳定的估计值。随着模型的更新,情况变得更糟:EMA很大程度上是由过去的输入特征主导的,随着模型的发展,这些特征已经过时了。
- 当λ很小的时候,EMA统计被最近少量的mini-batches所主导,并且不能代表整个数据。
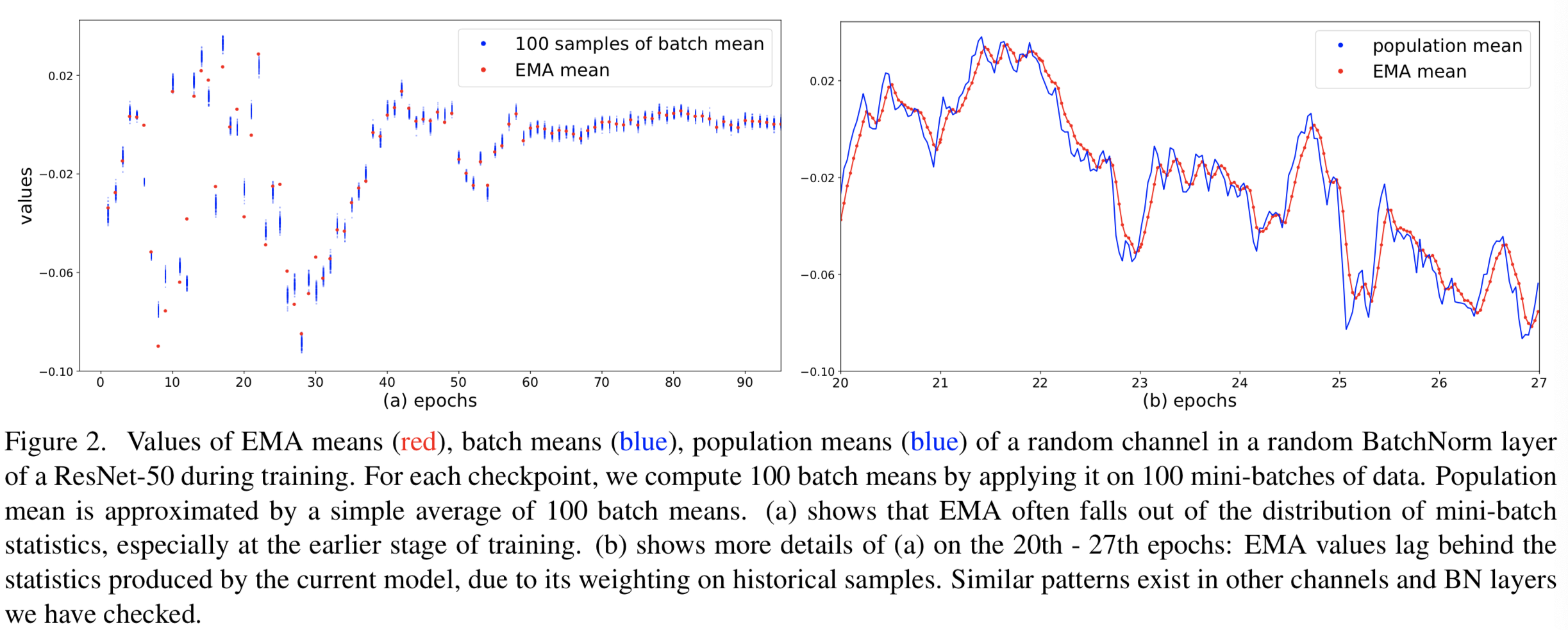
接下来,我们用标准的ImageNet分类来证明EMA的不准确性。我们在ImageNet[14]上训练100个epoch的ResNet-50[24] ,所有实验设置都遵循[18]:我们在256个GPU上使用8192的总mini-batch大小,因此BatchNorm在每个GPU上运行32个样本。EMA使用每个GPU的统计数据进行更新,λ设置为0.9。我们在训练期间经常保存模型的参数,以便绘制出我们从模型中随机选择的BatchNorm层的任意channel的EMA统计![]() 是如何演变的。此外,我们还将在“训练模式”下保存的checkpoints向前运行以计算100个随机mini-batches(每个也有32个样本)的batch统计数据,这些数据与EMA统计数据一起绘制。从图2的图中可以看出,在训练的早期阶段,EMA并不能准确地代表mini-batch统计或总体统计。因此,使用EMA作为“总体统计”可能会损害模型的准确性。我们将在下一节中分析对模型精度的影响。
是如何演变的。此外,我们还将在“训练模式”下保存的checkpoints向前运行以计算100个随机mini-batches(每个也有32个样本)的batch统计数据,这些数据与EMA统计数据一起绘制。从图2的图中可以看出,在训练的早期阶段,EMA并不能准确地代表mini-batch统计或总体统计。因此,使用EMA作为“总体统计”可能会损害模型的准确性。我们将在下一节中分析对模型精度的影响。
3.2. Towards Precise Population Statistics
理想情况下,我们希望根据其定义计算更精确的总体统计:使用整个训练数据集作为一个batch去计算特征的平均值和方差。由于处理如此大的batch可能过于昂贵,我们的目标是通过以下两个步骤来近似真实的总体统计数据:(1)将(固定)模型应用于许多mini-batches,以收集batch统计数据;(2)将每个batch的统计信息汇总为总体统计信息。
这种近似保持了真实总体统计数据不同于EMA的两个重要属性:
(1)统计数据完全从一个固定的模型状态计算出来,不像EMA使用模型的历史状态;
(2)所有样本权重均相等,而EMA不同样本的权重是不同的。
接下来,我们将看到该方法能产生更好的统计数据,从而改进模型性能。我们还将讨论它的实现细节,并表明这种近似方法与真正的总体统计数据一样有效。
由于EMA现在已经成为了BatchNorm的实际标准,当BatchNorm层在推理中使用这个更精确的统计数据时,我们使用“PreciseBN”这个名称,以避免与流行的BatchNorm实现混淆。但是,我们注意到这种方法实际上是[33]中原始BatchNorm的定义。PreciseBN的PyTorch实现在[1]中提供。
PreciseBN stabilizes inference results. 我们按照[18]中的配方在ImageNet上训练ResNet-50,将常用的256大小的总batch size的数据 分布在8个GPU上运行。模型的评估在每个epoch上使用精确的统计和EMA。从图3中绘制的error曲线可以看出,使用PreciseBN评价的验证结果比使用EMA评价的验证结果更好,也更稳定,说明EMA的不准确性对模型性能有负面影响。最终准确度列于表1的第1行。
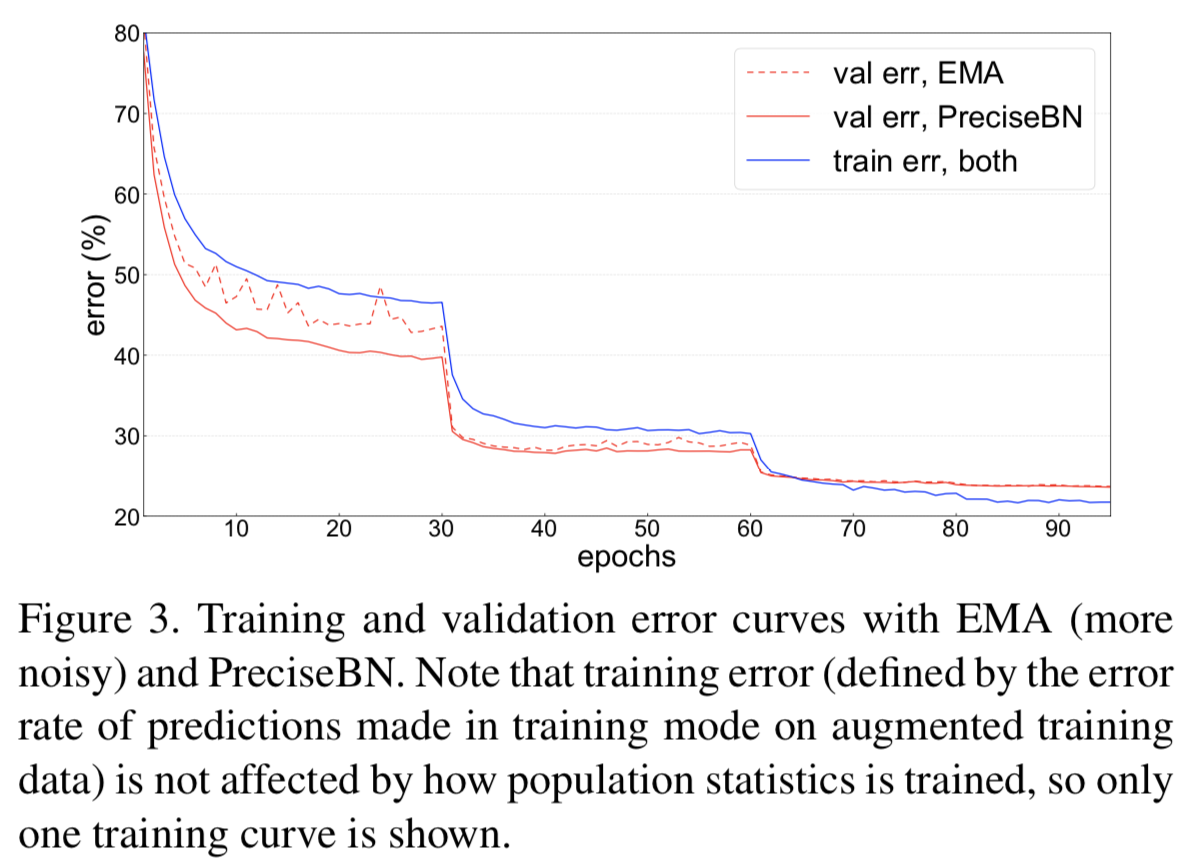
(推理时使用PreciseBN会更加稳定)

(PreciseBN只需要103~104个样本可以得到近似最优)
Large-batch training suffers more from EMA. 我们用8192这个更大的总batch size进行了同样的实验。遵循[18],基本学习率η线性增大到32倍。验证error如图4所示。

(大batch训练对EMA影响更大)
图4显示,EMA在较大的batch size下产生了极高的方差验证结果。[18]的图4也观察到了这一点。训练的前30个epochs,即学习率最大时,该现象是最严重的,与我们在图2(a)中的观察相匹配。我们相信,在large-batch训练中不稳定是由两个因素导致的,其损害了EMA统计数据的收敛:(1)32倍的大学习率导致特性变化更显著;(2)由于减少了总训练迭代次数,EMA的更新次数减少了32倍。另一方面,PreciseBN产生稳定的精度。表1列出了它们在第30 epoch和第100 epoch的准确性。
PreciseBN only requires 103 ∼ 104 samples. 在实践中,估计整个训练集的均值和方差是昂贵的,而准确的总体统计可以从一个足够大的子集获得。在表1中,我们展示了error率在PreciseBN中使用的样本数量不同时如何改变,使用了从以前的实验中获得的三个模型。结果表明,只需N = 103 ~ 104个样本,PreciseBN就能获得稳定的性能。如果我们在ImageNet训练的每个epoch执行一次PreciseBN,我们估计使用PreciseBN只会增加0.5%的总训练成本(假设每个epoch包含106张图,后向传播花销和前向传播相同,这样每个epoch的额外训练花销为![]() )。
)。
PreciseBN虽然只需要103 ~ 104个样本,但很难通过大量训练和使用λ = 0的EMA来实现。我们在附录A.1中对此进行了讨论。
Aggregation of per-batch statistics. 即使![]() ,在一个batch中前向传播足够数量的样本在计算上也是很有挑战的。实际上,mini-batch size为B时,N个样本需要被处理 k = N/B 次。这就提出了如何将每个batch的统计
,在一个batch中前向传播足够数量的样本在计算上也是很有挑战的。实际上,mini-batch size为B时,N个样本需要被处理 k = N/B 次。这就提出了如何将每个batch的统计![]() 聚合为
聚合为![]() 的问题。
的问题。
我们在所有实验中通过![]()
![]() 来聚合统计数据,其中
来聚合统计数据,其中![]() 是k个batches的平均值。我们在附录A.2中讨论了一些可替代的聚合方法,但他们实际中的效果都差不多好。
是k个batches的平均值。我们在附录A.2中讨论了一些可替代的聚合方法,但他们实际中的效果都差不多好。
Small batch causes accumulated errors. 在计算总体统计数据时,batch size B的选择实际上很重要:不同的batch分组将改变标准化统计数据并影响输出特征。这些特性之间的差异可能会累积到更深的BatchNorm层中,并导致不准确的统计数据。
为了验证这一说法,我们使用PreciseBN评估相同的模型,使用相同的N = 104个样本,但不同的batch size B来前向传播这些样本。表2的结果显示,从小mini-batch size估计的总体统计是不准确的,并降低了准确性。在我们的实验中,batch size B≥102就足够了。

(小batch会产生统计量累积错误)
因为EMA必须使用与SGD相同的mini-batch来估计总体统计,我们的结果也表明,当使用小的batch size训练时,EMA不能估计良好的总体统计。另一方面,PreciseBN中的batch size B可以独立选择,并且因为不需要反向传播,所以需要更少的RAM。对于使用大小为2的normalization batch size(NBS)训练的模型(表2中的第2行),正确使用PreciseBN比EMA提高了3.5%的准确性(PreciseBN稳定时为32.0,EMA为35.5)。
3.3. Discussions and Related Works
PreciseBN. 我们注意到,重新计算像PreciseBN这样的总体统计实际上就是最初的BatchNorm[33]的公式定义,但它没有被广泛使用。本文深入分析了标准ImageNet分类任务下的EMA和PreciseBN,并在适当的情况下论证了PreciseBN的优势。
我们证明,当模型不收敛时,尤其是在large-batch训练期间,EMA无法精确估计总体统计数据。在这样的情况下需要对模型进行评估时,应该使用PreciseBN。除了绘制验证曲线,强化学习还需要在收敛前对模型进行评估。我们在附录A.4回顾了[71]中的一个例子。即使当模型达到收敛时,我们也表明,如果用小batch size训练模型,EMA会产生较差的估计。
然而,我们的实验也表明,在给定足够大的batch size和收敛模型时,EMA获得的最终验证误差往往与来自PreciseBN的相同。因此,EMA方法仍然占主导地位,它的缺点经常被忽视。我们希望我们的分析可以帮助研究人员认识到EMA的问题,并在必要时使用PreciseBN。
Other advantages. 在存在其他train-test不一致的情况下,重新计算总体统计数据也很重要:[8,35]重新计算统计数据是因为模型权重在训练后进行了平均。[42]重新计算总体方差,以补偿dropout推理模式引起的“方差偏移”。[64,31,69]重新计算/重新校准总体统计数据,以补偿测试时间量化导致的分布偏移。在不同的域[43]上重新计算总体统计在域自适应中很常见,这将在第5节中进一步讨论。所有这些例子都涉及模型或数据中额外的train-test不一致,这证明了重新评估总体统计数据的合理性,因为在训练期间估计的EMA统计数据可能与测试期间的特征分布不一致。最先进的视觉模型往往通过强烈的train-test不一致性来使训练规范化[68,29,84,15,82],这也可能以意想不到的方式与BatchNorm交互。
4. Batch in Training and Testing
BatchNorm在训练和测试中通常有不同的行为:归一化统计数据来自不同的“batches”,即分别来自mini-batch和总体。总体统计信息和mini-batch统计信息之间的差距导致了不一致性。在本节中,我们分析了这种不一致性对模型性能的影响,并指出在某些情况下,可以很容易地消除这种不一致性以提高性能。
4.1. Effect of Normalization Batch Size
我们将“normalization batch size”定义为计算标准化统计信息的实际mini-batch的大小。为了避免混淆,本文明确使用“SGD batch size”或“total batch size”来指代SGD算法的mini-batch大小,即计算一个梯度更新所用的样本数量。
在主要深度学习框架的BatchNorm标准实现中,训练时的normalization batch size等于每个GPU的batch size。通过使用附录A.5中讨论的SyncBN[57]、GhostBN[27]等替代实现,我们可以轻松地增加或减少normalization batch size。
normalization batch size对训练噪声和train-test不一致性有直接影响:batch越大,mini-batch统计量越接近总体统计量,从而降低训练噪声和train-test不一致性。为了研究这种效果,我们按照[18]中的配方训练ResNet-50[24]模型,但normalization batch size从2到1024变化。所有模型的SGD batch size固定为1024。为了便于分析,我们考察了3种不同评价方案下各模型的错误率:(1)在训练集上采用mini-batch统计进行评价;(2)在验证集上采用mini-batch统计进行评价;(3)在验证集上用总体统计进行评价。我们将每个模型的最终指标绘制在图5中。通过三种评价方案的消融情况,可以从图中观察到:
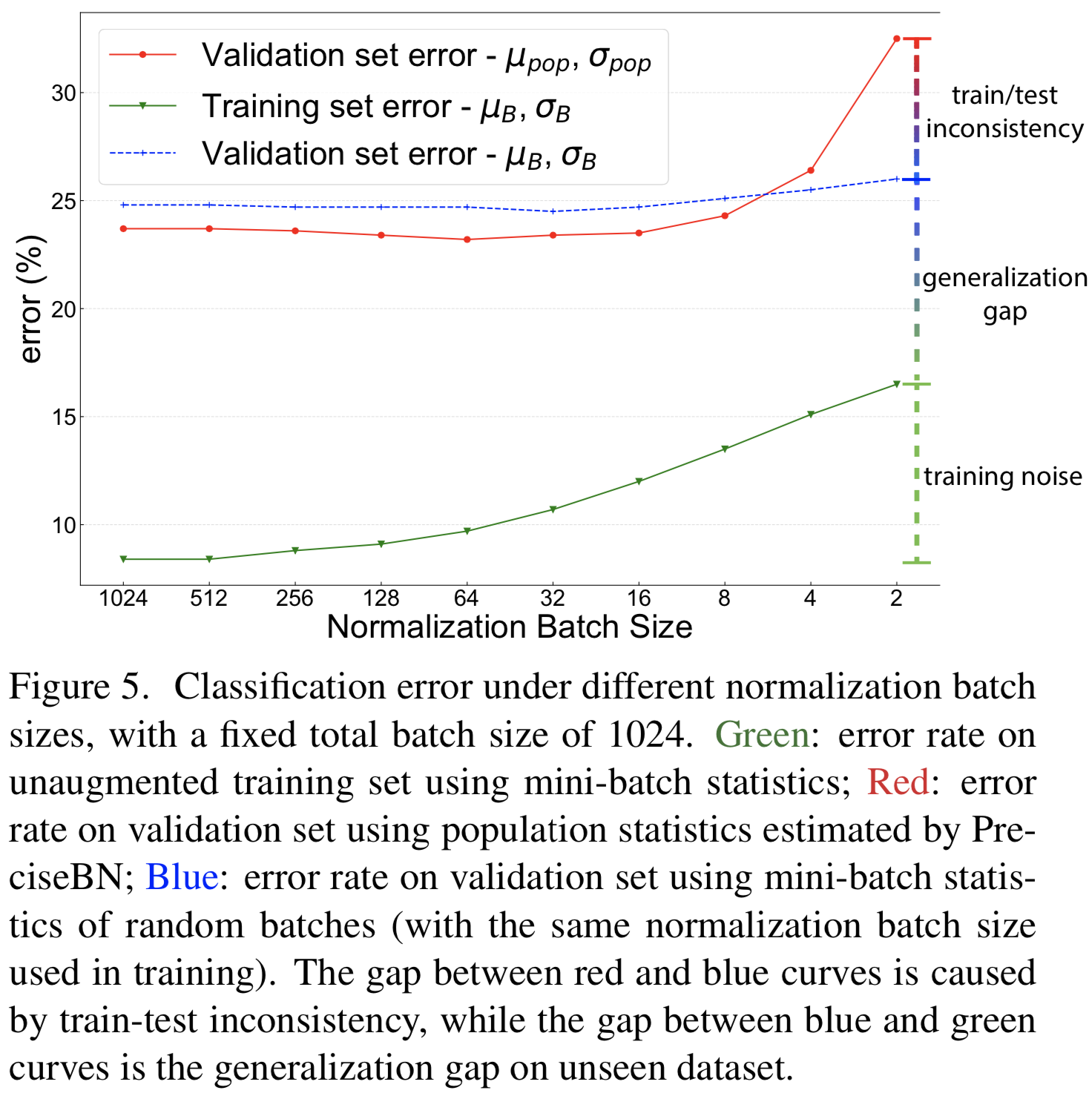
Training noise.训练集error的单调趋势(green)是由SGD过程中训练噪声的数量所决定的。当normalization batch size较小时,同一小批中随机抽取的其他样本对一个样本的特征影响较大,训练精度较差,导致优化困难。
Generalization gap. 当也使用mini-batch统计数据进行评估时,在验证集(blue)上,模型的表现比训练集(green)差。由于数据集的变化,模型的数学计算没有发生变化,两者之间的差距纯粹是泛化差距。泛化gap随着normalization batch size的增加而单调减小,这可能是由于训练噪声和train-test不一致所提供的正则化效果。
Train-test inconsistency. 为了分析由于![]() 导致的不一致性,我们在验证集上(red vs blue曲线)比较了总体统计数据和mini-batch统计数据的使用效果。
导致的不一致性,我们在验证集上(red vs blue曲线)比较了总体统计数据和mini-batch统计数据的使用效果。
一个小的normalization batch size(例如2或4)被认为表现很差[32,76],但是如果使用mini-batch统计(blue曲线),模型实际上有不错的性能。我们的结果表明,mini-batch统计和总体统计之间的不一致性是影响小batch size下性能的主要因素。
另一方面,当normalization batch size较大时,小的不一致性可以提供正则化以减少验证误差。这使得红色曲线比蓝色曲线表现得更好。
在这个实验中,最好的验证error是在normalization batch size为32 ~ 128时发现的,其中噪声和不一致性的数量提供了平衡的正则化。
为了保持train和test的BN统计量一致,作者提出了两种方法来解决不一致问题,一种是推理的时候使用mini-batch统计量,另一种是训练的时候使用population batch统计量。
4.2. Use Mini-batch in Inference
图5的结果表明,在推理中使用mini-batch统计可以减少train-test的不一致性,提高测试时间性能。令人惊讶的是,我们发现使用这种方法,与常规batch size相比,tiny batch size(2)的BatchNorm的性能只下降了不到3%(图5,blue)。然而,在推理中使用mini-batch统计通常不是一个合法的算法,因为模型不再对每个样本进行独立的预测。
R-CNN’s head. 我们现在研究一个案例,其在推理中可以合法地使用mini-batch统计信息。我们看看R-CNN风格的对象检测器的第二阶段(又称“head”)[17,16,59,23]。R-CNN的head对每个输入图像i取Ri个感兴趣区域(region-of-interest, RoIs),并对每个RoI进行预测。在大多数R-CNN的实现中,head的BatchNorm层将所有图像的区域合并成单个大小为![]() 的mini-batch。我们在实验中遵循这一惯例。
的mini-batch。我们在实验中遵循这一惯例。
需要注意的是,即使在推断中只给出了一个输入图像,大小N = R0的“mini-batch”(对于box head来说,通常是102 ~ 103量级的数量)仍然存在,因此mini-batch统计信息可以被合法地使用。
我们使用standard Mask R-CNN[23]基线和预先训练的ResNet-50(在[77]中实现)进行实验。在这个基线模型中没有BatchNorm(只有FrozenBN,章节4.3中讨论过)。为了研究BatchNorm的行为,我们将默认的2fc box head替换为类似[76]的4conv1fc head,并在box head和mask head的每个卷积层后添加BatchNorm。该模型是端到端的调整,而主干中的FrozenBN层保持固定。我们用不同的normalization batches对模型进行训练,用不同的统计量进行评估,如表3所示。

(不使用norm效果略差,使用GN效果更好)
Mini-batch statistics outperform population statistics. 表3的结果表明,在测试时间使用mini-batch统计得到了明显优于总体统计的结果。特别是,当使用![]() 进行推理时,模型的性能很差,而在训练过程中,每个GPU只使用一张图像。这是由于对批处理中的模式过拟合造成的,将在6.1节中进一步讨论。还要注意的是,R-CNN内部的抽样策略会产生额外的train-test不一致性,这可能会让推理中的mini-batches遵循与训练中的mini-batch不同的分布。这表明还有进一步改进的空间。
进行推理时,模型的性能很差,而在训练过程中,每个GPU只使用一张图像。这是由于对批处理中的模式过拟合造成的,将在6.1节中进一步讨论。还要注意的是,R-CNN内部的抽样策略会产生额外的train-test不一致性,这可能会让推理中的mini-batches遵循与训练中的mini-batch不同的分布。这表明还有进一步改进的空间。
最后,我们证明了在推理中使用mini-batch统计可以有效地减少train-test不一致性。它提高了模型在normalization batch size时的性能,也提高了R-CNN的heads性能。
4.3. Use Population Batch in Training
前一节讨论在推理中使用mini-batch统计信息。作为一种替代方法,在训练中使用总体统计在理论上也可以减少train-test的不一致性。然而,如[33,32]所观察到的,在梯度下降过程中使用EMA进行归一化使得模型不可训练。一种可行的总体统计训练方法是使用冻结的总体统计数据,也称为frozen BatchNorm(c)。
FrozenBN是一个常量仿射变换![]()
![]() ,其中μ和σ是之前计算得到的总体统计数据。作为一种线性变换,它可能会失去normalization层的优化优势。因此,FrozenBN通常是在模型经过normalization优化之后使用的,比如在将预先训练好的模型转移到downstream任务时。因为它不再引入train-test不一致或BatchNorm的其他问题,所以FrozenBN在诸如目标检测等领域是一个流行的替代方案。
,其中μ和σ是之前计算得到的总体统计数据。作为一种线性变换,它可能会失去normalization层的优化优势。因此,FrozenBN通常是在模型经过normalization优化之后使用的,比如在将预先训练好的模型转移到downstream任务时。因为它不再引入train-test不一致或BatchNorm的其他问题,所以FrozenBN在诸如目标检测等领域是一个流行的替代方案。
接下来,我们研究了FrozenBN在减少train-test不一致性方面的作用。对于图5中的每个模型,我们取第80个epoch的checkpoint,然后将所有BatchNorm替换为FrozenBN去训练最后20个epochs。所有的训练设置从最初训练的最后20个epochs保持不变,除了一个epoch的线性热身,从其开始训练以帮助优化。结果如图6所示:FrozenBN也有效地降低了train-test的不一致性,即使在前80个epoch用小的大小为2的normalization batch size训练模型,也能得到25.2%的错误率。当normalization batch size足够大时,使用FrozenBN调优的性能低于常规BN,这在目标检测领域也可以观察到[57,22]。
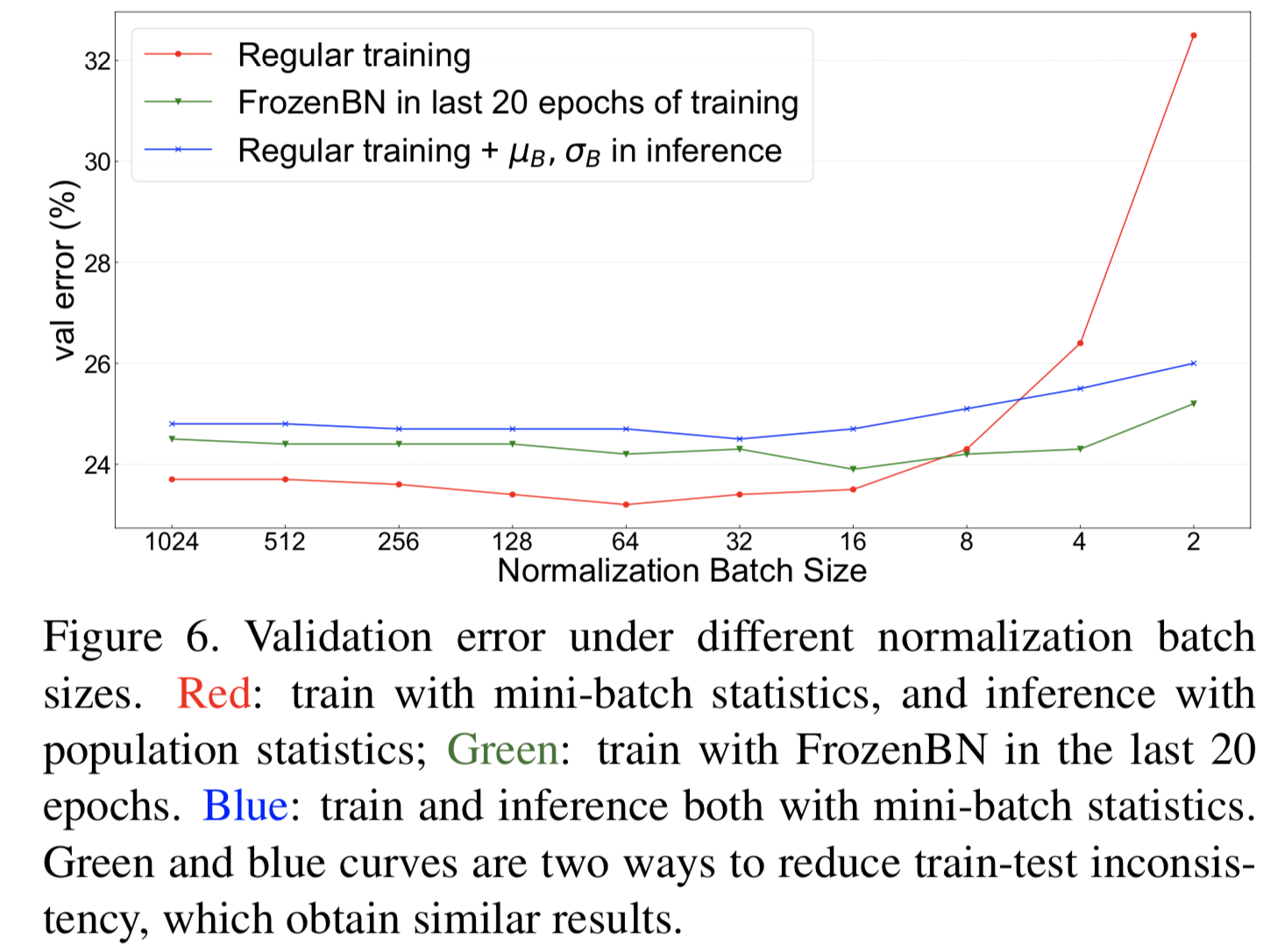
(FrozenBN可以有效缓解训练测试不一致,即使在小normalization batch size,也能达到比较好的性能。但是随着normalization batch size增大,这两种方法都不如常规BN的结果。可见主要要根据normalization batch size去选择方法)
4.4. Discussions and Related Works
我们选择“Normalization batch size”这个术语是为了避免与其他相关的batch size概念混淆。这个概念在以前的工作中已经含蓄地使用过:[18]强调尽管它研究的是large-batch的训练,但normalization batch size应该保持不变。[27]提出使用小的normalization batch size进行正则化。[74,67]在训练过程中使用变化的total batch size,而不是恒定的total batch size。他们都解耦了normalization batch size与total batch size,并分别调整它们。
通过分析图5,我们通过分析图5,得到了在方面对BatchNorm行为的新理解,因为它消融了三个性能差距的来源:训练噪声、泛化gap和train-test不一致性。
(Small normalization batch size)众所周知,较小的normalization batch size有负面影响,正如在以前的工作中观察到的[32,76]。我们分析了潜在的原因,并表明在ImageNet上,使用PreciseBN可以将小normalization batch size和常规normalization batch size之间的大性能差距减少3.5%(表2),然后使用mini-batch统计可以再减少6.5%(图5 red vs blue,normalization batch size=2)。这些改进根本不影响SGD训练。
我们证明了在推理中使用mini-batch统计或在训练中使用FrozenBN可以大大减少train-test不一致性。这两种方法都只是简单地改变“batch”以实现标准化,并显著地提高了standard BatchNorm在小的normalization batch size下的性能。
我们的分析止于normalization batch size为2的情况。与InstanceNorm的关系[72]将在附录A.7中单独讨论。
(Mini-batch statistics in inference)推理中的mini-batch统计可以帮助减少train-test的不一致性。据我们所知,在R-CNN的head中应用这种技术在以前的研究中没有出现过,但[76]也观察到总体统计数据在R-CNN的head中表现不佳。
EvalNorm[66]与在推理中使用mini-batch统计信息密切相关:它的目的是基于单个输入实例的统计信息以及总体统计信息来近似地使用mini-batch统计信息。它通过类似的机制减少了train-test的不一致性,无需在推理中访问mini-batch。
推理中的batch统计信息还有其他潜在用途:[34]将batch统计信息用作随机噪声的来源。[53]在元学习推理中使用batch统计信息进行评估。
在5.3节中,我们回顾了在推理中使用batch统计信息来处理域偏移的文献。
FrozenBN在之前的工作中对预处理过的分类器进行了微调,用于downstream任务,如对象检测[59,23,41],度量学习[50]。当应用于微调时,通常会冻结normalization统计量和随后的仿射变换,以便将它们融合为一个单一的仿射变换(然而,在微调期间,将仿射变换与其他相邻层(例如卷积)融合并不是一个好主意,尽管这是部署的标准优化。请参阅附录A.8)。这种FrozenBN的变体在计算上是高效的,并且通常表现得很好。
即使没有微调的背景,我们已经证明在训练中使用FrozenBN通常有助于减少train-test不一致性,这部分解释了为什么它在迁移学习中有用。在之前的研究中,如[37,79,39]也观察到了在训练过程中切换到FrozenBN的好处。
Reduce training noise in BN. 除了减少train-test不一致性,其他几个归一化方法试图减少BatchNorm的训练噪声。BatchRenorm (BRN)[32]引入了修正项,使训练时间统计更接近EMA,以减少batch统计中的噪声。Moving Average BatchNorm(MABN)[80]通过将EMA应用于batch统计和反向传播梯度来降低训练噪声。两种方法都能改善小batch条件下的BatchNorm。[63,81]还研究了batch统计中的噪声,并在训练中提出了替代的归一化方案。
批无关的归一化方法,如GroupNorm [76], Filter Response normalization [65], EvoNorm[47]不受训练噪声的影响,具有竞争性的准确性。然而,与BatchNorm不同的是,它们都在推理中产生了额外的归一化成本。
Increase training noise in BN. 有时,额外的噪声是可取的,因为它额外的正则化效果。提出了几种在batch统计中注入噪声的方法。例如,TensorFlow的[3]BatchNorm层有一个adjustment=选项来显式地注入随机噪声。[40]提出混合不同样本的统计量以增加噪声。[34]在测试时使用mini-batch统计信息来增加噪音。
5. Batch from Different Domains
BatchNorm模型的训练过程可以看作是两个独立的阶段:一是通过SGD学习得到特征;二是由EMA或PreciseBN使用这些特征训练总体统计。我们将这两个阶段称为“SGD训练”和“总体统计数据训练”。
训练数据集和测试数据集之间的差异不利于机器学习模型的泛化。由于BatchNorm中训练总体统计数据的额外阶段,BatchNorm模型在这样的域偏移下行为唯一。当数据来自多个领域时,输入在(1)SGD训练;(2)总体统计数据训练;(3)测试中 的域gap都能影响泛化效果。
在本节中,我们将分析出现域gap的两个场景: (1)模型在一个领域上进行训练,但在其他领域上进行测试; (2)模型在多个领域上进行训练。我们证明,通过选择要归一化的“batch”,两者都可以使BatchNorm的使用复杂化。
5.1. Domain to Compute Population Statistics
当模型的训练和测试阶段看到不同的数据分布时,就会发生域转移。在BatchNorm模型中,计算总体统计数据的额外训练阶段也受到域偏移的影响。BatchNorm的典型应用是在数据的训练域上计算![]() ,而[43]提出了“Adaptive BatchNorm”来计算测试域的统计。在这里,我们将重新审视这种方法。
,而[43]提出了“Adaptive BatchNorm”来计算测试域的统计。在这里,我们将重新审视这种方法。
Experimental settings. 我们使用在ImageNet上训练的常规ResNet-50模型,遵循[18]的配方,总batch size为1024,normalization batch size为32。为了研究使用这个模型的域偏移,我们在包含各种损坏的ImageNet图像版本的ImageNet- C[26]上评估它。具体来说,我们使用具有3种不同损坏类型(对比、高斯噪声、jpeg压缩)和中等严重程度的ImageNet-C子集。我们在不同的评估数据上评估这个模型的准确性,同时改变用于训练总体统计的数据。
Results. 从表4可以看出,在存在显著的域偏移时,模型在用于评估的域上进行总体统计数据训练后得到的错误率最好,比在SGD训练中使用的数据集上训练的效果好。直观地说,重新计算这些统计量可以减少train-test的不一致性,并改进新数据分布的泛化。
然而,我们也注意到,重新计算目标分布上的总体统计数据可能最终也会损害性能。作为一个例子,我们重新对要进行评估的准确输入计算了上述模型的![]() ,即 使用推理时间预处理的ImageNet验证集而不是训练增强的数据集进行重计算(即val set w/o augs)。尽管在总体统计训练(val set w/o augs)和评估(IN)中观察到相同的数据,但性能略有下降(表4的最后一行,从23.4 -> 23.8)。我们假设这是由于两个训练步骤之间的不一致,将总体统计数据应用于新领域是否有益,仍然是一个需要在不同背景下进行评估的问题。
,即 使用推理时间预处理的ImageNet验证集而不是训练增强的数据集进行重计算(即val set w/o augs)。尽管在总体统计训练(val set w/o augs)和评估(IN)中观察到相同的数据,但性能略有下降(表4的最后一行,从23.4 -> 23.8)。我们假设这是由于两个训练步骤之间的不一致,将总体统计数据应用于新领域是否有益,仍然是一个需要在不同背景下进行评估的问题。
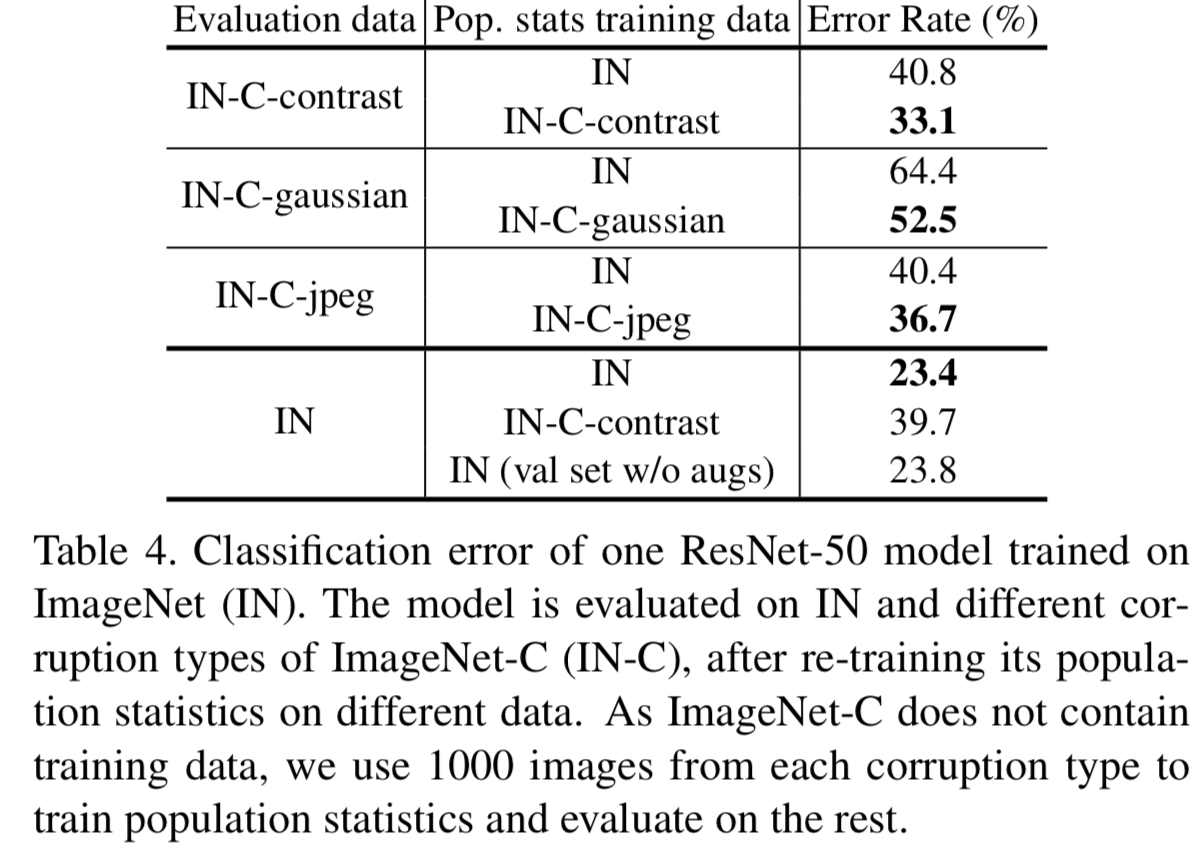
(这几行意思是一样的,就是在评估数据上计算总体统计数据效果更好。如第一行意思是若在IN上计算总体统计数据,在IN-C-contrast上评估效果,得到的error rate为40.8;而在IN-C-contrast上计算总体统计数据,在IN-C-contrast上评估效果,得到的error rate更好,为33.1)
5.2. BatchNorm in Multi-Domain Training
BatchNorm的输出不仅依赖于单个样本,而且还依赖于训练时如何将样本分组成batch。形式上,对于BatchNorm层 f 来说,
![]()
其中X1、X2、...是多个输入batches,[.,.]表示batch维度的串联。当batches来自不同的域(即不同的数据集或不同的特征),等式1的两边决定是将不同的域一起标准化,还是将每个域单独标准化。这种差异可能产生重大影响。
BN in RetinaNet’s Head. 我们使用RetinaNet[46]对象检测器进行了一个案例研究,配备了特征金字塔网络( Feature Pyramid Networks,FPN)[45]。该模型有一系列卷积层(又称“head”),对来自不同特征金字塔级别的5个特征进行预测,如图7所示。head在所有5个特征级别中共享,这意味着它接受来自5个不同分布或领域的输入训练。我们在shared head的所有中间卷积层之后添加了BatchNorm和channel-wise仿射层,并研究了它的行为。
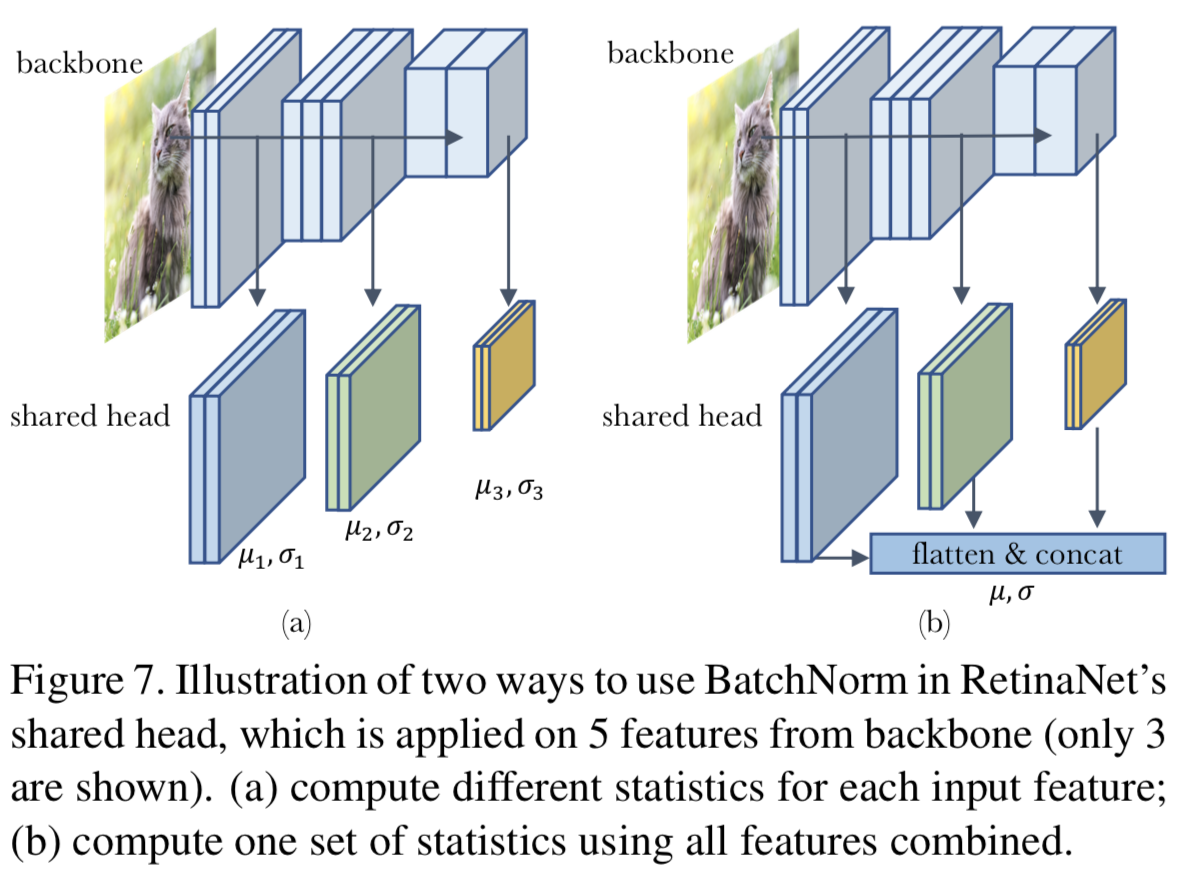
在该模型中,head X1···X5的输入特征来自不同的FPN层次,具有不同的空间维度。因此,以图7(a)的形式训练模型是很简单的,在图7(a)中,head独立应用于特征,每个特征都由自己的统计数据归一化。然而,图7(b)是一个有效的选择:我们将所有输入特征压平并连接,以便计算一组将所有特征归一化在一起的统计数据。我们将这两个选择称为在SGD训练中使用“特定领域的统计信息(domain-specific statistics)”和“共享的统计信息(shared statistics)”。
在如何训练总体统计方面也有类似的选择。我们可以为每个特征级别计算唯一的总体统计数据,并根据输入源使用它们进行推理,如图7(a)所示。或者我们可以使用相同的总体统计集合来标准化所有的特征级别。
我们探讨了上述选择在这个shared head的组合,以显示不一致的选择在两个训练阶段如何影响模型的泛化。此外,我们还实验了在BatchNorm之后共享仿射变换层,或者对每个输入特征使用不同的仿射变换的两种不同选择。
Consistency is crucial. 表5列出了这些组合的实验结果。总之,我们展示了对于在不同领域/特性上多次使用的BatchNorm,其总体统计数据的计算方式应该与SGD优化期间特性的标准化方式一致。否则,这种差距会导致在推理中不能概括这些特性。同时,是否共享仿射层的影响很小。
我们强调,这个head的标准实现设置的表现很差(AP为34.1)。表5中的第3行对应于一个简单的实现,它将:(1)在每个特性上分别应用shared head(即SGD Training使用domain-specific),因为这是head中的其他(卷积)层的应用方式;(2)只维护一组总体统计数据(即Population Stats为Shared),因为这一层在概念上是跨特性“共享”的。附录A.9使用伪代码进一步演示了BatchNorm的正确用法实现起来不那么简单,因此不太常见。
虽然我们使用具有共享层的RetinaNet作为例子,但我们注意到,当在多个数据集上训练模型时,我们讨论的问题也存在:图7(a)和(b)之间的选择仍然存在。与直接在多个数据集上进行训练相比,共享层的多领域特性很容易被忽略。

(SGD training、population statistics training和testing保持一致是非常重要的,并且全部使用domain-specific能取得最好的效果。不使用norm效果略差,使用GN效果更好)
(从上面的实验可见,GroupNorm的效果都很好,推荐使用它)
5.3. Discussions and Related Works
Domain Shift. 第5.1节简要讨论了总体统计数据在域转移方面的作用。首先提出了在目标域上重新计算总体统计数据的思想,即“Adaptive BatchNorm”[43]。接下来是修改BatchNorm用于域自适应的其他研究,比如[10]。防止图像损坏或对抗的例子可以被视为域自适应的特殊案例,[6,62]表明自适应总体统计也有助于这些任务。此外,当测试时间输入作为一个足够大的mini-batch给出时,mini-batch本身可以用作目标域的“总体”。[51,4]表明,直接使用测试时间mini-batch重新计算统计数据也提高了对图像损坏或对抗攻击的鲁棒性。
所有上述方法都需要访问足够数量的目标域数据,而这些数据通常是不可得的。因此,使用BatchNorm的模型比其他归一化方法更容易发生域偏移。[38]和[55]均发现,BatchNorm模型在迁移学习中加入batch无关的归一化后,其泛化gap可以得到改善。
(Domain-specific training)混合多域数据的BatchNorm的特定域训练在以往的工作中经常被提出,称为 “Domain-Specific BN” [11], “Split BN” [83], “Mixture BN” [79], “Auxiliary BN” [78], “Transferable Norm”[73]。在[2]中使用了RetinaNet中特定域的总体统计。这些方法都包含以下三个选择中的一些。
- Domain-specific SGD training: 梯度下降训练中使用的μB、σB是从一个或多个域计算出来的。
- Domain-specific population statistics: 是否在测试所有域时都使用同一组μpop、σpop,还是每个域都各使用一组。这需要知道测试时输入的域。如果多个域来自于层共享(第5.2节),这样的知识是微不足道的,在其他应用程序中不一定可用,例如测试来自多个数据集的输入。
- Domain-specific affine transform: 是否学习特定领域的仿射变换参数,或使用共享仿射变换。这也需要知道测试时输入的域。
通过消融上述三种选择,我们表明在SGD训练和总体统计训练之间使用一致的策略是重要的,尽管这样的实现可能看起来不直观。
处理多个数据域的机器学习模型是常见的。有些算法甚至专门设计来处理这类数据,例如共享层、adversarial defense、GANs等。本节中的分析显示了仔细考虑将什么样的数据域标准化的重要性。
6. Information Leakage within a Batch
我们将BatchNorm的另一种警告描述为“信息泄漏(information leakage)”,即模型学会了利用它不打算使用的信息。由于BatchNorm没有对mini-batch中的每个输入样本进行独立预测,所以会发生信息泄漏(因为BN是对mini-batch的样本计算统计量的,导致在样本进行独立预测时,会利用mini-batch内其他样本的统计信息)。相反,每个样本的预测通过mini-batch统计利用其他样本。
当mini-batch中的其他样本携带有用信息时,模型可以学习利用这些mini-batch信息,而不是学习针对单个样本的泛化表征。这种行为可能出现在各种应用程序中。我们将在本节中回顾几个示例。
6.1. Exploit Patterns in Mini-batches
Artificial pattern in mini-batch. [32]设计了一个实验,其中ImageNet分类器被训练为32个normalization batch size,但是每个这样的batch都是手工制作的,由16个类和每个类2张图像组成。显然,当模型在训练过程中对一个样本进行预测时,它可以利用mini-batch中的另一个样本必须具有相同的标签这一事实来降低训练损失。因此,该模型利用了这种模式,并且在训练后不会泛化。图8是在ResNet-50上进行的实验结果,其他实验细节都在[18]之后。
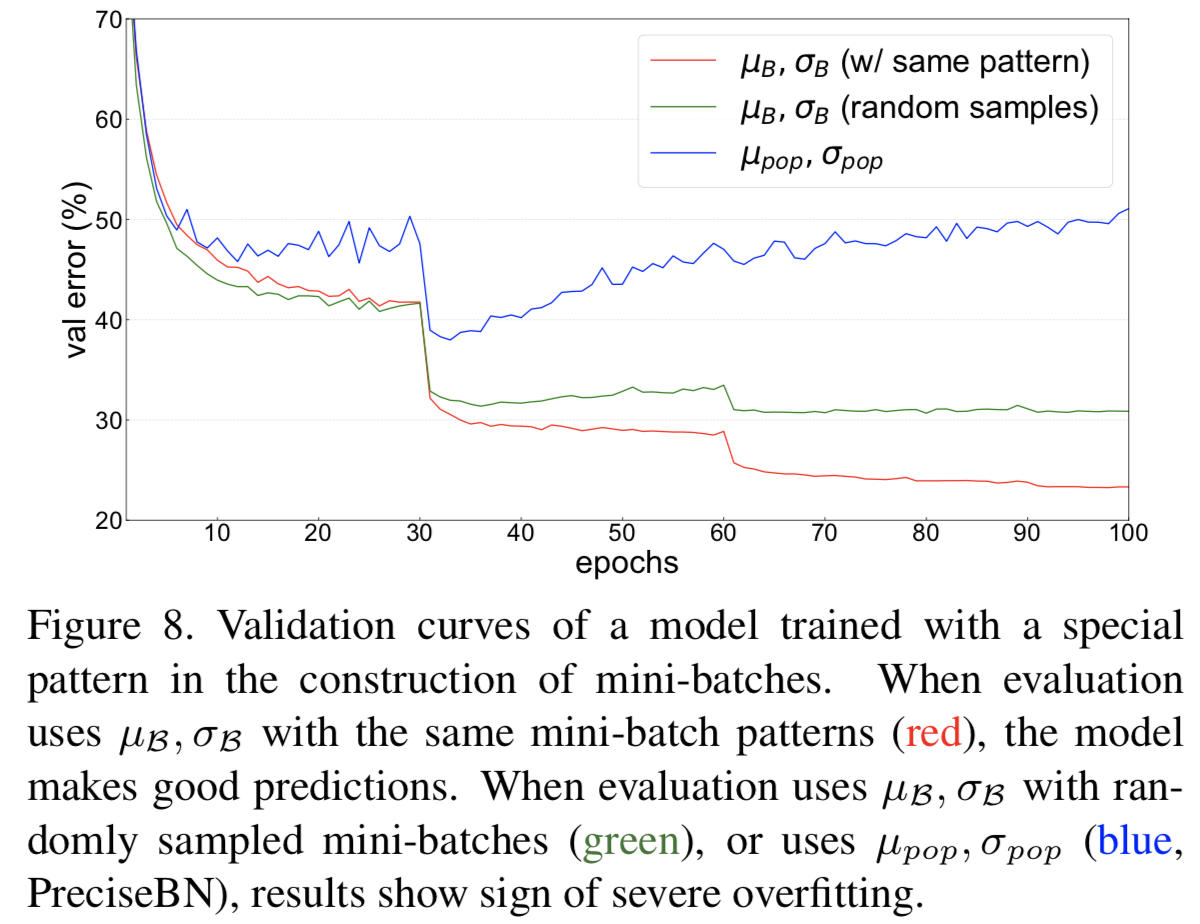
在本例中,可以通过在训练过程中采用“Ghost BatchNorm”(附录A.5)对来自不同类别的16幅图像的子集进行归一化,使每个normalization batch不再包含特殊的模式来解决这个问题。接下来,我们看看出现此问题的现实和常见场景,并展示其他实用的补救方法。
Correlated samples in R-CNN’s head. 我们研究了Mask R-CNN模型的第二阶段(head),设置与4.2节相同。我们在第4.2节中已经说明了,如果在推理中使用总体统计信息,那么在head中添加BatchNorm将导致性能显著下降。我们认为其原因类似于图8:在head中执行per-GPU BatchNorm时,一个mini-batch的样本是由同一幅图像的RoIs组成的。这些RoIs携带关于彼此的有用表征,这些表征可能会因为mini-batch统计而错漏。第4.2节在推理中使用了mini-batch统计信息,这使得模型能够利用推理中的泄漏,从而提高性能。在这里,我们的目的是避免信息泄露。
虽然每个GPU上的mini-batches包含了head中高度相关的RoIs ,但GPUs之间的RoIs是独立的。一种解决方案是使用SyncBN(附录A.5)归一化所有GPUs上的所有RoIs。通过组合来自其他图像的样本,削弱了normalization batch样本之间的相关性。
另一种解决方案是在进入head之前在GPUs之间随机打乱RoI特征。这就给每个GPU分配了一个随机的样本子集来进行归一化处理,同时也削弱了normalization batch中样本之间的相关性。该过程如图9所示。
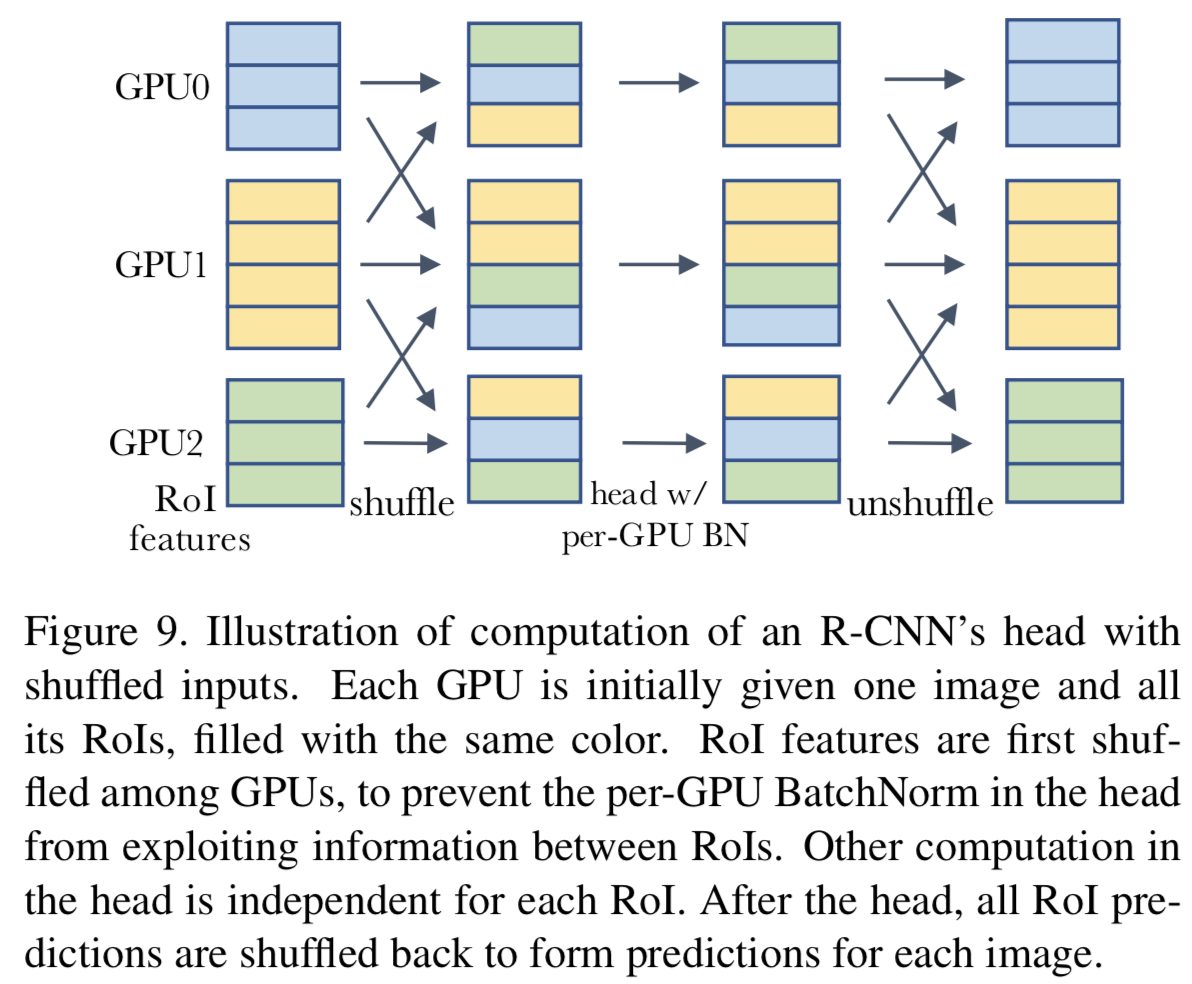
(即如果不打乱,一个mini-batch中的数据相关性太强,这样得到的特征局限,当应用到别的数据上,其效果就比较差,因为泛化性不好)
表6的实验结果表明,shuffling和SyncBN都能有效地解决信息泄漏问题,使得head在测试时能够很好地泛化。在速度方面,我们注意到shuffle对于深度模型需要较少的跨GPU同步,但是每个同步传输的数据比SyncBN层要多。因此,它们的相对效率取决于模型体系结构。
在mini-batches中的模式也可能出现在其他应用程序中。例如,在强化学习中,一个代理在同一事件中获得的训练样本,如果放到一个mini-batch中,也可能显示出可以利用的相关性。在视频理解模型中,一个mini-batch可能包含来自同一视频clip的多个帧。如果这些应用程序受到在相关mini-batches上使用BatchNorm的影响,它们也可以通过确保normalization batches不包含相关样本(如上面的shuffle)的谨慎实现中受益。

6.2. Cheating in Contrastive Learning
在对抗学习或度量学习中,训练目标通常设计为在mini-batch内比较样本。样本在损失函数中同时扮演输入和标签的角色。在这种情况下,BatchNorm会漏掉其他样本的信息,因此允许模型在训练期间作弊(即只是在mini-batch中效果好),而不是学习有效的表征(泛化不行)。
这种作弊行为在[25]中观察到,它采用LayerNorm[5]代替BatchNorm来解决。其他关于对抗学习的工作通过在不同的实现中使用BatchNorm来解决这个问题,类似于我们在6.1节中学习的内容。MoCo[21]将mini-batches中的样本打乱(shuffle),以防止BatchNorm利用其他样本。SimCLR [12], BYOL[19]使用SyncBN来解决这个问题。
由于对抗学习的特性,还有其他补救办法。在许多teacher-student对抗学习框架中,模型的一个分支并不传播梯度。利用这一特性,[44,9]提出不使用mini-batch统计信息,而是在该分支中使用移动平均统计信息(moving average statistics)来防止遗漏。这也有效地避免了作弊。
7. Conclusions
本文讨论了BatchNorm在视觉识别任务中应用时的一些实际问题。下面我们从不同的角度对它们进行总结。
Inconsistency. train-test不一致性在BatchNorm的行为中起着至关重要的作用。在第3节中,我们讨论了计算更精确且不落后于训练时mini-batch统计的总体统计的方法。在第四章中,我们证明了通过在推理中使用mini-batch统计或在训练中使用总体统计可以减少train-test不一致性。在第5节中,我们展示了执行优化的batches、计算总体统计的数据以及评估模型的数据之间的一致性的重要性。第6章中的信息泄漏问题源于mini-batch训练和单个样本测试之间的不一致性。此外,来自其他来源的train-test不一致性也可能与BatchNorm交互,如第3.3节所述。
Concept of “batch”. 我们回顾了BatchNorm的各种非常规用法,这些用法可以解决BatchNorm的警告。它们都只是在不同的上下文中改变了batch的构造方式。在第三章中,我们将整个总体定义为一个batch,并研究了计算其统计量的方法。在4.1节中,我们证明了normalization batch可以不同于梯度下降中使用的mini-batch。第4.2节和4.3节表明,在训练和测试中,可以自由选择batch作为mini-batch或总体。第5.1节讨论了用于构造batch的数据。第5.2节重点讨论了单个域的mini-batch和跨所有域的联合mini-batch之间的区别。第6节表明,当batch的本质定义具有不希望的属性时,我们可以通过shuffle等技术改变batch。
与之前提出的其他归一化方案不同的是,上述方法仍然是在特征的batch维度上进行归一化,但构造batch的方法不同。我们的目的是说明在每个场景中仔细考虑batch概念的重要性。
Library implementations. 许多库都提供了BatchNorm的“标准”实现。然而,正如我们在本文中看到的,使用现成的实现可能不是最优的,而且使用BatchNorm的替代方法在这样的标准实现中可能并不容易获得。例如,他们使用EMA,但通常不提供重新估计总体统计的方法。这在使用精确的统计数据(3.2节)或域转移(5.1节)方面造成困难。标准实现维护一组总体统计信息,但是根据第5节,每个域的统计信息是有用的。标准实现在训练中使用每个GPU的mini-batch统计,在测试中使用总体统计,但正如第4节所示,这些不一定是最好的选择。第6节中的问题是通过实现技术来解决的,比如shuffling和SyncBN。
此外,由于BatchNorm的独特特性,它经常引入与底层深度学习系统的非标准交互,并导致其他实际问题或bug。附录A.10列举了一些例子。我们希望我们的审查提高人们对标准BatchNorm实现的局限性和潜在误用的认识。
Practical implications. 我们在本文中讨论的许多注意事项在实践中可能并不常见。事实上,当应用于以下常见场景时,常规形式的BatchNorm确实表现得非常好:采用适当的batch size和训练长度的监督训练,使用从单个数据集随机抽取的固定大小的独立同分布batch,不进行层共享训练,并在模型收敛后的相似分布数据上进行测试。
然而,由于BatchNorm和CNN被广泛应用于其他应用和学习范式中,BatchNorm的注意事项值得注意。本文以图像分类和目标检测中的标准视觉模型为实验平台,在有限的视觉表征学习上下文中讨论了这些注意事项。当应用于其他任务时,BatchNorm的独特属性可能会带来新的挑战,需要进一步研究。我们希望这篇综述能帮助研究人员仔细思考他们使用BatchNorm的原因,不要隐藏或阻碍新的研究突破。
A. Appendix
A.1. PreciseBN and EMA with λ = 0
当PreciseBN用于N≤104个样本时,我们可以假设EMA在large-batch训练下与PreciseBN相似,只要momentum λ设为0来剔除所有的历史统计量。但我们注意到这往往不是真的。
首先,即使SGD训练使用大的mini-batch size,归一化通常仍然使用更小的batch,要么是为了平衡正则化(参见4.1节),要么是由于workers之间的大量通信成本。其次,在典型的训练实现中,EMA更新总是紧随SGD优化步骤,这将更新表征,使总体统计再次过时。这与PreciseBN不同,后者是在SGD优化后才计算总体统计数据。
因此,虽然EMA λ = 0在概念上等同于PreciseBN,但只有在large-batch训练下才能与PreciseBN相媲美,需要克服其自身的实现挑战。
A.2. Estimators of Population Variance
给定N = kxB 个从一个随机变量X中得到的独立同分布的样本![]()
![]() ,分成batch size为B的k个batches,我们将使用每个batch的均值
,分成batch size为B的k个batches,我们将使用每个batch的均值![]() 和每个batch的方差
和每个batch的方差![]() 去估计X的方差,定义为:
去估计X的方差,定义为:

每个估计量(estimator)都是无偏差的,但他们有不同的方差。将“样本方差的方差”[13]代入,等式3的方差为:

其中![]() 是X的标准差和峰度(kurtosis)。因此,等式3中小的B会增加估计量的方差。
是X的标准差和峰度(kurtosis)。因此,等式3中小的B会增加估计量的方差。
通过基本代数可以证明,等式2计算所有N个样本的无偏样本方差,当k = 1,B = N时,其等于等式3,因为在实际中B << N,这证明了等式2是更好的估计量。
当在使用N个形状为(H, W)的输入特征的总体数据时,在BatchNorm层中应用等式2,样本总数变为N × H × W,这足够大以至于bessel修正因子可以忽略。
A.3. Compute Population Statistics Layer-by-Layer
根据定义,总体统计应将整个数据集作为一个batch来计算。然而,对于较大的总体大小N,由于内存限制,这通常是不实际的。
另一方面,分割成大小为B的batch,运行N/B次前向传播将导致不同的输出。虽然通过每个batch的聚合矩(aggregating moments)(等式2)可以准确地计算出第一个BatchNorm层的总体统计量,但更深的层会受影响,如第3.2节所述。我们需要一种方法来计算真实的总体统计数据,这样我们就可以知道我们通过分裂和聚合的近似方法是否足够。
为了在有限的内存条件下准确计算总体统计信息,我们可以对统计信息进行逐层估计。为了计算第k个BatchNorm层的统计信息,我们首先获得前k−1个BatchNorm层的真实总体统计信息。然后,通过让前k - 1层使用总体统计信息,第k层使用batch统计信息,以任意batch size来前向传播整个数据集以产生第k层的batch统计信息,这些batch统计信息随后可以通过等式2聚合到总体统计信息中。该算法允许我们使用任何batch size来计算真正的总体统计数据,就好像总体数据是一个batch。
这种逐层算法的时间复杂度是模型深度的二次幂,因此非常昂贵。另一方面,用batch size B前向传播整个模型N/B次更便宜。如表2所示,当B足够大时,后面的近似方法的效果就足够好了。
A.4. PreciseBN in Reinforcement Learning
第3.2节表明,当我们在训练中运行推理时,如绘制验证曲线,PreciseBN是有益的。然而,除了绘制监控曲线外,大多数监督训练任务在训练过程中不需要使用推理模式的模型。
另一方面,在强化学习(RL)中,大多数算法需要在训练的同时运行推理,以便与环境交互并收集经验作为训练数据。因此,RL算法中EMA得到的估计较差:随着模型的演化,EMA可能不能准确地反映统计量。例如,ELF OpenGO[71]的附录描述了它在AlphaZero训练中使用PreciseBN。他们报告说,使用PreciseBN解决他们称之为“moment staleness”的问题后,结果有了明显的改善。
A.5. Changing Normalization Batch Size
在BatchNorm层的经典实现中,normalization batch size等于per-GPU(或每个worker)的batch size。这使得改变normalization batch size变得困难:较大的per-GPU batch size需要更大的内存消耗,而较小的per-GPU batch size在现代硬件上通常是低效的。因此,我们开发了一些BatchNorm的实现来改变normalization batch size,而不需要考虑per-GPU的batch size。
Synchronized BatchNorm (SyncBN) ,也被称为Cross-GPU BatchNorm[57]或Cross-Replica BatchNorm[8],是一个BatchNorm的实现,在数据并行训练中使用高达SGD batch size的大的normalization batch size。它在per-GPU batch size有限的任务中是有效的,例如对象检测[57,22]和语义分割[85]。在SyncBN中,工作人员执行集体通信,以便计算和共享跨多个worker的更大batch的均值和方差。我们在附录A.6中讨论了SyncBN的一些实现细节。(其实就是之前使用多个GPU时,每次迭代,输入被等分成多份,然后分别在不同的GPU上前向(forward)和后向(backward)运算,并且求出梯度。在迭代完成后合并梯度、更新参数,再进行下一次迭代。因为在前向和后向运算的时候,每个GPU上的模型是单独运算的,所以相应的Batch Normalization 也是在GPU内完成,所以实际BN所归一化的样本数量仅仅局限于该GPU内,相当于batch-size减小了。SyncBN的关键是在前向运算的时候拿到全局的均值和方差,在后向运算时候得到相应的全局梯度)
Ghost BatchNorm[27]是BatchNorm的一个实现,它减少了normalization batch size,只需将batch分成sub-batches,并分别标准化它们。当per-GPU batch size较大时,我们发现这可以改善正则化,如[54,67]所示。这些经验证据与我们在第4节中的分析相吻合。
Virtual BatchNorm[61]是一种昂贵的增加normalization batch size的方法,不需要在GPUs之间同步:它只是使用额外的输入图像来计算batch统计数据。请注意,这不同于增加per-GPU batch size:额外的输入图像不会产生梯度,因此不会有显著的内存成本。但它仍然需要额外的正向计算成本。[20]中也提出了类似的想法。通过包含额外的训练图像来组成虚拟BatchNorm,虚拟BatchNorm也可以是在测试时使用mini-batch统计信息的合法(但昂贵)方法。
Gradient Accumulation. 我们注意到常见的“radient Accumulation”技术(在Caffe[36]中称为“iter_size”)不会改变normalization batch size。然而,它可以增加SGD batch size, 给定固定的per-GPU batch size和固定的GPUs数量。
A.6. Implementation of SyncBN
当数据并行worker(或GPUs)具有相同的batch size时,SyncBN的简单实现只需要执行大小为2 x #channels 的all-reduce操作去计算分布在workers的大batch ![]() 的mini-batch统计数据
的mini-batch统计数据![]() 和
和![]() 。然后使用
。然后使用![]() 计算方差。(最简单的实现方法是先同步求均值,再发回各GPU然后同步求方差,但是这样就同步了两次。为了只同步一次,使用上面的计算方法,这样就只用在各GPU上计算x和x2的和,然后同步一次就能够通过全局求和去计算均值和方差)
计算方差。(最简单的实现方法是先同步求均值,再发回各GPU然后同步求方差,但是这样就同步了两次。为了只同步一次,使用上面的计算方法,这样就只用在各GPU上计算x和x2的和,然后同步一次就能够通过全局求和去计算均值和方差)
在某些应用中,“batch size”的定义比较模糊。例如,在目标检测中,workers通常拥有相同数量的图像,但每幅图像的像素数不同,或者每幅图像的RoIs(对于R-CNN风格的模型)数量不同。在这些场景中,workers最终可能会得到不同数量的需要标准化的元素。与前面提到的简单实现不同,SyncBN可以考虑worker之间的mini-batch size的差异。然而,我们注意到,这似乎没有必要,且经验告诉我们其对结果并没有产生显著差异。
我们还注意到SyncBN的实现可能容易出错,需要仔细验证。SyncBN的实现于2019年3月被添加到PyTorch中,但并没有像detectron2中首次报道的那样产生正确的梯度,后来在2020年4月进行了修正。TensorFlow Keras在2020年2月添加了一个实现,但它直到2020年10月才产生正确的输出。
A.7. InstanceNorm and BatchNorm
InstanceNorm (IN)[72]可以大致看作是normalization batch size为1的BatchNorm,但有一些关键的区别:(1)在测试过程中,IN计算instance统计信息的方式与训练时的方式一致;(2)在训练过程中,每个样本的输出取决于其输入,没有来自mini-batch中其他样本的噪声或随机性。因此,第4.1节中的不一致性和正则化分析不再适用于IN。作为参考,在与第4.1节实验相同的训练配方下,根据[76],IN得到了约28%的验证误差。
A.8. Affine Fusion Before Fine-tuning
当使用FrozenBN时,该常数仿射层的权重可以与相邻的线性层(如卷积层)融合。这种融合是部署的标准技术,因为模型在融合后执行数学等价计算。然而,我们提醒读者,这种融合在数学上不再等同于微调。
我们使用一个toy例子去阐述它:使用步长为1的梯度下降去最小化关于x的函数![]() ,其中设置一个frozen常量λ=0.5,x初始化为非0值。因为
,其中设置一个frozen常量λ=0.5,x初始化为非0值。因为![]() ,每个GD step为
,每个GD step为![]() ,这将使x收敛为0。但是,如果在优化时融合frozen λ和x,优化任务将变为在x的新初始化值下最小化
,这将使x收敛为0。但是,如果在优化时融合frozen λ和x,优化任务将变为在x的新初始化值下最小化![]() 。然后GD step变为
。然后GD step变为![]() ,这将不会收敛。在现实中,像融合这样的linear reparameterization可以极大地改变某些参数的有效步长,使模型更难优化。因此,与相邻层融合的FrozenBN会导致微调的不利结果。
,这将不会收敛。在现实中,像融合这样的linear reparameterization可以极大地改变某些参数的有效步长,使模型更难优化。因此,与相邻层融合的FrozenBN会导致微调的不利结果。
A.9. Implementation of RetinaNet head
在算法1中,我们使用PyTorch风格的伪代码提供了表5中第1、3、6行对应的RetinaNet头的参考实现。为了实现当前在深度学习库中可用的BatchNorm抽象方法,row1引入了显著的复杂性,而row6不再跨输入“共享”相同的head。以row3的样式实现它很简单,但会导致性能较差。
row6的另一种实现是通过一个层,该层在每次调用它时循环多个统计信息。然而,这将引入另一层的状态,该状态取决于调用它的次数,这可能会导致其他并发症。

A.10. Non-standard Interaction with Libraries
我们在本文中讨论的BatchNorm的独特属性不同于大多数其他深度学习原语。因此,它以独特的方式与底层的深度学习系统相互作用,如果不加以注意,很容易导致bugs。我们现在列出了由这种交互引起的几种类型的问题,其中许多与[7]中给出的具体例子相呼应。
Missing updates. BatchNorm的参数不会被梯度更新修改,而是经常被EMA修改。在声明式计算图执行库中,这需要在训练期间显式执行这些额外的更新操作。在TensorFlow v1[3]提供的BatchNorm层实现中,使用UPDATE_OPS操作符集合来跟踪这些操作。因为没有BatchNorm的模型不需要执行这些操作,所以用户在使用BatchNorm时很可能忘记执行这些操作,从而导致总体统计信息无法更新。TensorFlow提供了一个提示来提醒用户这种误用。
出于同样的原因,如果BatchNorm被用于符号条件分支(如tf.cond)中,则很难更新统计信息。此类问题已被报道过多次。为了避免这些问题,Tensorpack[75]和现在已弃用的tf.contrib.layers提供了允许BatchNorm在前向过程中更新统计数据的选项,而不是作为额外的操作。然而,如果不小心使用,这可能会导致意外更新的问题。
Unintended updates. 像PyTorch[56]这样的强制性深度学习库必须更新BatchNorm参数作为前向计算的一部分。这确保了更新将被执行,但它可能会导致意外的更新:当模型处于“训练模式”时,即使没有任何反向传播,简单的前向传递也将更新模型参数。我们注意到一些开放源代码以这种方式对验证集进行训练,可能是无意的,也可能是有意的。
Empty inputs. 当一个batch处理包含0个样本时(在某些模型中很常见,比如R-CNN), BatchNorm会对底层库提出更多挑战。它可能需要控制流支持来不更新EMA,因为统计数据是未定义的。在使用SyncBN时,在没有通信死锁的情况下处理空输入和控制流也是一个挑战。
Freezing. 一些高级训练库引入了“frozen”层的概念,或将层设置为“不可训练”状态。这样的概念对于BatchNorm来说是不明确的,因为它不像其他层一样通过梯度下降进行训练,因此可能会导致混淆或误用。例如,这些讨论揭示了在Keras普遍存在的滥用问题。
Numerical precision. 除法是一种归一化操作,在其他深度学习原语中很少看到。如果在某些应用中输入几乎相同(例如稀疏特征、使用模拟器输入的强化学习),那么除以一个小的数字很容易引入数值的不稳定性。[8]在分母中增加ε来应对此类问题。
作为归一化的一部分,大量减法也是不稳定的潜在来源。在混合精度训练[49]中,由于半精度范围的限制,这种减法往往必须在全精度下进行。
Batch splitting. 基于流水线并行度的训练系统更倾向于将mini-batch分解成更小的micro-batches,从而实现[30]的高效流水线。流水线和batch splitting也可以在具有有限RAM[48]的定制训练硬件中看到。虽然splitting是对其他层的等效变换,但它影响了BatchNorm的计算,使系统的设计更加复杂。
posted on 2021-12-14 20:41 Sanny.Liu-CV&&ML 阅读(296) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号