
转载:StyleGAN & StyleGAN2 论文解读
转载:https://boltzmachine.com/2020/11/16/StyleGAN/ 大神写的非常清晰明了,建议前往
转载:https://zhuanlan.zhihu.com/p/263554045
StyleGAN & StyleGAN2 论文解读
论文题目:A Style-Based Generator Architecture for Generative Adversarial Networks, Analyzing and Improving the Image Quality of StyleGAN
论文链接:https://arxiv.org/abs/1812.04948, https://arxiv.org/abs/1912.04958
StyleGAN是Nvidia提出的模型,其不仅达到了state-of-the-art的效果,也在生成的可控性上做到了巨大的提升。
个人认为,StyleGAN的主要贡献有四个:
- 基于style的生成方法,使生成的过程可控
- 隐空间解耦(disentaglement)及新的评价方法
- SOTA(state-of-the-art)的生成效果
- 高清人脸数据集(Flickr-Faces-HQ, FFHQ)
StyleGAN模型是由不同部分组成的,理解了每个部分的功能,就可以理解整个模型。
StyleGAN的整体结构如下图所示,分为左边的Mapping Network和右边的Synthesis Network。

首先值得一提的是,StyleGAN的训练是和Progressive GAN一致的,不过这并不是StyleGAN的重点,所以我不打算在这篇文章里说,如果有不清楚Progressive growing的朋友可以去看一看那篇paper。
Mapping Network
模型左半部分的结构,它的功能非常简单,就是把z∈Z映射成一个w∈W。Z是我们传统的一个隐空间,它通常采样自高斯分布或均匀分布。W是经过特征解耦的隐空间。

用原文中的图来说明。这里颜色代表着输出,实线代表着某一特征为常量的线。例如,在(a)中,我们用横线代表一个人的长发长度(越往上越长),竖线代表一个人男子气概的程度(越往左越man)。那么左下角粉红色的区域就可以代表猛男,右上角黄色区域可以代表仙女。而左上角的区域(长发飘飘的猛男)通常来讲是不存在的,因此是空的。
那么,在传统的以z作为隐变量的GAN(b)中,由于z来自于一个对称的分布,所以它是一个圆形。而为了填补(a)中左上角的空缺,特征的分布必将被扭曲,这就造成了当仅仅改变z的某一维度时,输出图像会有多个特征同时发生变动,设就是entanglement。而StyleGAN中Mapping Network的作用,就是将图(b)映射成(c)。
至于为什么Mapping Network自动能学到解耦的功能,文章中说他们认为generator偏好于基于解耦的特征去生成。
We posit that there is pressure for the generator to do so, as it should be easier to generate realistic images based on a disentangled representation than based on an entangled representa- tion.
Synthesis Network
接下来是真正的生成网络。styleGAN认为,所谓image就是style的集合,而style是有不同规模的
- Coarse styles → pose, hair, face shape
- Middle styles → facial features, eyes
- Fine styles → color scheme
网络分为不同的block,而每个block都是一些上采样、卷积核AdaIN操作。注意在StyleGAN中,隐变量不作为生成网络的初始输入,初始输入是一个可学习的常量矩阵,而隐变量A则输入给每一个AdaIN。
AdaIN
AdaIN,即Adaptive Instance Normalization。本质上是某种标准化(Normalization),先贴公式:
![]()
它和IN(Instance Normalization)的区别在于两个用于放射变换的参数是从输入中得到的。
AdaIN不是StyleGAN提出的,它的原论文地址:
AdaIN原本是用于风格迁移的,原文中的形式长这样
![]()
x代表用于content的输入,y代表用于style的输入。在style transfer中我们认为,一个sample中所有特征空间中共有的信息(spatial invariant)代表了某种style,通常可以用μ和σ表示;而每个特征去掉这些共有信息后,得到就是content的内容信息。
在StyleGAN中,μ和σ变成了ys,i和yb,i,是从w中计算得到的(通过一个可学习的神经网络),代表了给这层注入基于w的风格。
Style mixing
在一次生成过程中,不仅仅是用一个w,而是sample出两个z1,z2,从而得到两个w1,w2。在生成网络的前几层喂w1,后几层喂w2,这样得到的图片就是纯w1和纯w2的混合。

纵轴代表w1,横轴代表w2。越靠上的图片代表w更早切换。可以看到,在更早的层切换会改变粗粒度(coarse)的特征(如脸型、姿势等),在更晚的层切换会改变细粒度(fine)的特征(如颜色和一些微结构等)。
你可能会说这跟interpolation有什么区别,事实上,作者称它为mixing regularization,也就是一种正则化。它是为了将style与style之间解耦,也就是每层负责不同的style。
个人认为 Style mixing 是 StyleGAN 的一大亮点,先来看下什么是 Style mixing,下图中 第一行是 source B, 第一列是source A,source A 和 source B的每张图片由各自相应的latent code 生成,剩余的图片是对 source A 和 souce B 风格的组合。 Style mixing 的本意是去找到控制不同style的latent code的区域位置,具体做法是将两个不同的latent code 和
输入到 mappint network 中,分别得到
和
,分别代表两种不同的 style,然后在 synthesis network 中随机选一个中间的交叉点,交叉点之前的部分使用
,交叉点之后的部分使用
,生成的图像应该同时具有 source A 和 source B 的特征,称为 style mixing。
根据交叉点选取位置的不同,style组合的结果也不同。下图中分为三个部分,第一部分是 Coarse styles from source B,分辨率(4x4 - 8x8)的网络部分使用B的style,其余使用A的style, 可以看到图像的身份特征随souce B,但是肤色等细节随source A;第二部分是 Middle styles from source B,分辨率(16x16 - 32x32)的网络部分使用B的style,这个时候生成图像不再具有B的身份特性,发型、姿态等都发生改变,但是肤色依然随A;第三部分 Fine from B,分辨率(64x64 - 1024x1024)的网络部分使用B的style,此时身份特征随A,肤色随B。由此可以大致推断,低分辨率的style 控制姿态、脸型、配件 比如眼镜、发型等style,高分辨率的style控制肤色、头发颜色、背景色等style。
Stochastic variation
论文中的 Stochastic variation 是为了让生成的人脸的细节部分更随机、更自然,细节部分主要指头发丝、皱纹、皮肤毛孔、胡子茬等。如下图。
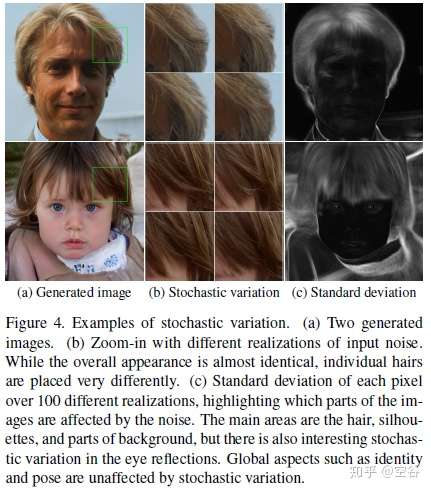
实现这种 Stochastic variation 的方法就是引入噪声,StyleGAN的做法是在每一次卷积操作后都加入噪声,下图是不同网络层加入噪声的对比。
图中的B,在AdaIN之前加入,是在每层、每个像素点上加入独立的噪声,效果是可以产生一些本就随机的东西(例如头发的摆放、胡茬、雀斑、毛孔等)。

(a)是在所有层中都加入噪声,(b)是无噪声,(c)是在后面的层加入噪声(细粒度),(d)是在前面的层加入噪声(粗粒度)。随机噪声改变了一些局部的特征,并且似乎生成的效果也更好了?比如无噪声的(b)这张图看着就很fake。
我们可以看到,随机噪声是控制一些比较local的特征的,这和style所控制的全局特征是不同的。
Disentanglement studies
StyleGAN的一大亮点就是它解耦的隐空间W,为了评估他们的解耦程度,作者提出了两种新的方法。
Perceptual path Length
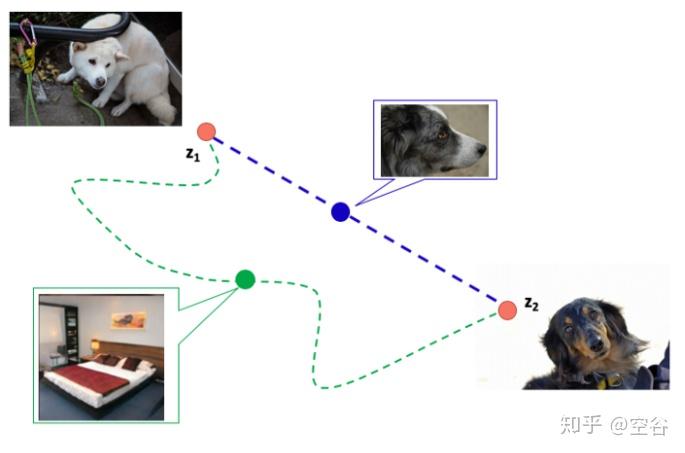
图像生成其实是学习从一个分布到目标分布的迁移过程,如下图,已知input latent code 是z1,或者说白色的狗所表示的latent code是z1,目标图像是黑色的狗,黑狗图像的latent code 是 z2,图中蓝色的虚线是z1 到 z2 最快的路径,绿色的曲线是我们不希望的路径,在蓝色的路径中的中间图像应该是z1 和 z2 的组合,假设这种组合是线性的(当特征充分解耦的时候),蓝色路径上生成的中间图像也是狗( 符合 latent-space interpolation),但是绿色的曲线由于偏离路径太多,生成的中间图像可能是其他的,比如图上的卧室,这是我们不希望的结果。
补充一下,我们可以通过训练好的生成模型得到给定图像的latent code,假设我们有一个在某个数据集上训练好的styleGAN模型,现在要找到一张图像 x 在这个模型中的latent code,设初始latent code 是 z,生成的初始图像是p,通过 p 和 x 之间的差距 设置损失函数,通过损失不断去迭代 z,最后得到图像x的latent code。
Perceptual Path Length (PPL) is an indicator of whether the image changes smoothly in “perceptual”. Uses the distance of the image embedded in the trained model, similar to FID.Roughly speaking, it indicates whether the image changes on the shortest “perceptual” path in the latent space.
Perceptual path length 是一个指标,用于判断生成器是否选择了最近的路线(比如上图蓝色虚线),用训练过程中相邻时间节点上的两个生成图像的距离来表示,公式如下:
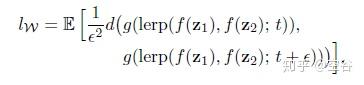
g 表示生成器,d 表示判别器, 表示mapping netwrok,
表示由latent code
得到的中间隐藏码
,
,
表示某一个时间点,
,
表示下一个时间点,lerp 表示线性插值 (linear interpolation),即在 latent space上进行插值。
想象一下我们现在有一张哈士奇图片,我们通过隐空间对它进行改变,得到一张萨摩耶图片。若我们对变换是沿着解耦空间中的某一条等高线(该线上只有一个特征在变化),由于这时一条最快的道路,我们可以认为变化沿着该条路径的积分是最小的。而相反,加入空间是entanglement的,那我们有可能会绕一大圈,比如哈士奇先变成床,再变成萨摩耶。这时,变化沿着路径的积分无疑是很大的。
对于两张图片的差异,我们用VGG16得到图片的embedding来计算embedding之间的差异。
对于Z,由于高斯分布是一个对称的分布,这个路径应当是沿着(超)球面进行的,所以应当使用球面插值(sphere interpolation)。
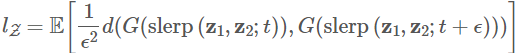
其中,ϵ可以看作积分步长,t∼U(0,1),G是生成器,slerp是球面插值,d(⋅,⋅)衡量了两张图片间的距离,是二次方的,所以前面要乘上一个系数。
对于W,其实就是直接用线性插值:
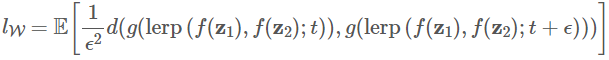
这里用小写g是因为没有包括Mapping Network。

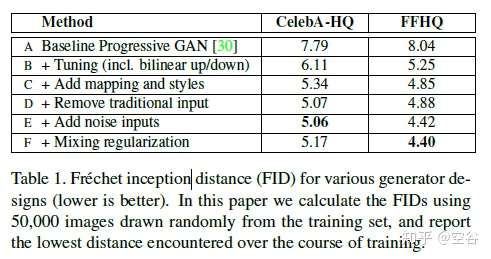
看B、D两行。
full就是我们前面公式所得到的结果,为什么W的分数比Z更坏?作者说这是因为你在两个样本之间插值可能会插出一些不存在的分布(就是左上角那个空缺),所以我们就在端点附近计算吧(end),这样的话lZ应该不受影响而lW下降明显,事实也确实如此。
Truncation Trick
Truncation Trick 不是StyleGAN提出来的,它很早就在GAN里用于图像生成了,感兴趣的可以追踪溯源。从数据分布来说,低概率密度的数据在网络中的表达能力很弱,直观理解就是,低概率密度的数据出现次数少,能影响网络梯度的机会也少,但并不代表低概率密度的数据不重要。可以提高数据分布的整体密度,把分布稀疏的数据点都聚拢到一起,类似于PCA,做法很简单,首先找到数据中的一个平均点,然后计算其他所有点到这个平均点的距离,对每个距离按照统一标准进行压缩,这样就能将数据点都聚拢了,但是又不会改变点与点之间的距离关系。
If we consider the distribution of training data, it is clear that areas of low density are poorly represented and thus likely to be difficult for the generator to learn. This is a significant open problem in all generative modeling techniques.
However, it is known that drawing latent vectors from a truncated or otherwise shrunk sampling space tends to improve average image quality.
,截断或者压缩后的(truncated)w' 公式如下:

是一个实数,表示压缩倍数,下图是truncation对style的影响。

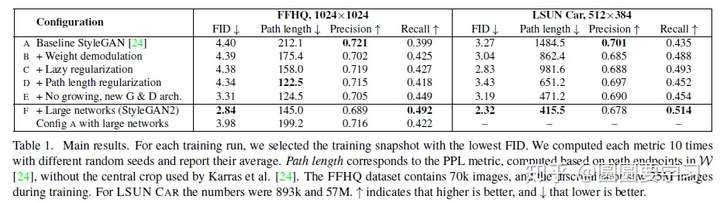
generator 中各个改进点的贡献,不同实验设置的FID结果,见下表:
![]() Linear separability
Linear separability
 Linear separability
Linear separability作者认为如果一个隐空间被充分解耦的话,那么我们一定非常容易在隐空间上做分类,即容易被一些比较弱的分类器(如linear SVM)分类。
那么为了衡量这个隐空间到底容不容易分,我们训练两个分类器,一个就是linear SVM,训练在隐空间上,另一个是训练在图片上的分类器。通过衡量这两个分类器结果的差异,比如用条件熵H(Y|X),我们就可以评价出这个隐空间容不容易分。这个分数也在上表当中。
StyleGAN的细节就到这里了,接下来重点看StyleGAN2。
StyleGAN2
paper:
Analyzing and Improving the Image Quality of StyleGAN
code:
https://github.com/NVlabs/stylegan2
StyleGAN2 的出现当然是因为StyleGAN存在瑕疵,少量生成的图片有明显的水珠,这个水珠也存在于feature map上,如下图:


发现了问题,就开始定位问题,最后找到了,原论文如下,
We pinpoint the problem to the AdaIN operation that normalizes the mean and variance of each feature map separately, thereby potentially destroying any information found in the magnitudes of the features relative to each other.
导致水珠的原因是 Adain 操作,Adain对每个feature map进行归一化,因此有可能会破坏掉feature之间的信息。emmmm,懵懵懂懂,最重要的是实验证明 当去除Adain的归一化操作后,水珠就消失了,所以Adain就背锅吧。
With supports from the experimental results, the changes in StyleGAN2 made include:
- Remove (simplify) how the constant is processed at the beginning.
- The mean is not needed in normalizing the features.
- Move the noise module outside the style module.
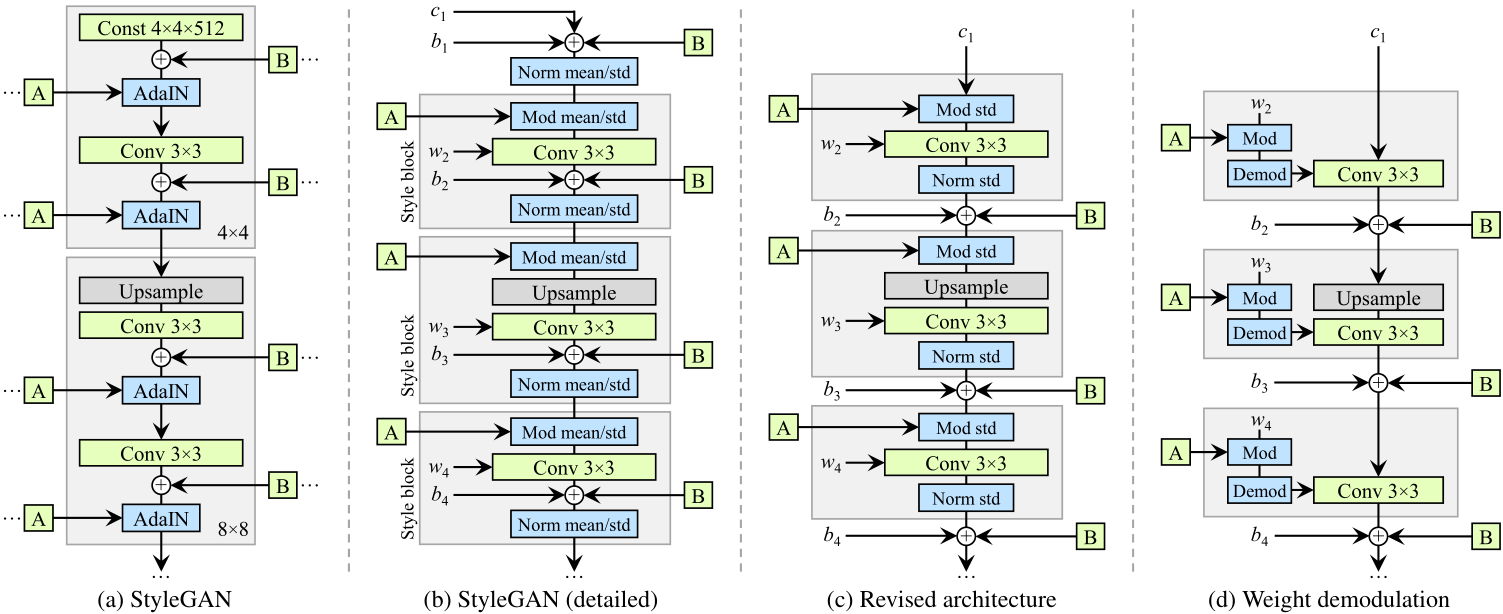

上面两张图说明了从 styleGAN 到 styleGAN2 ,在网络结构上的变换,去除normalization之后水珠消失了,但是styleGAN的一个亮点是 style mixing,仅仅只改网络结构,虽然能去除水珠,但是无法对style mixing 有 scale-specific级别的控制,原论文如下:
In practice, style modulation may amplify certain feature maps by an order of magnitude or more. For style mixing towork, we must explicitly counteract this amplification on a per-sample basis—otherwise the subsequent layers would
not be able to operate on the data in a meaningful way.
If we were willing to sacrifice scale-specific controls (see video), we could simply remove the normalization, thus removing the artifacts and also improving FID slightly.
We will now propose a better alternative that removes the artifacts while retaining full controllability.
除了网络结构上的改进,还有就是 Weight demodulation,公式如下:
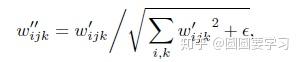
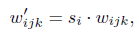

改进后的效果如下,水珠消失了。

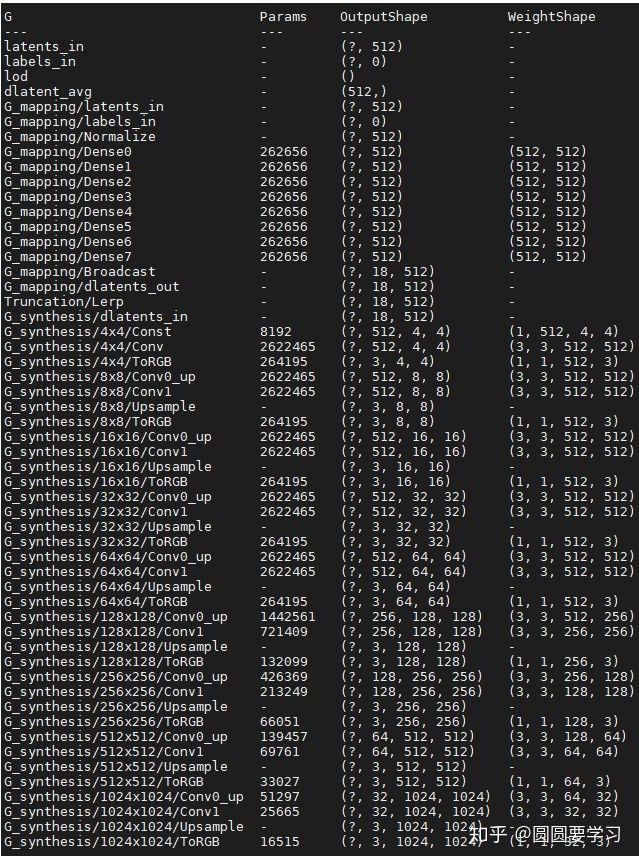
StyleGAN2 的网络结构:
图中 dlatents_out 表示 disentangled latent code,即 。
StyleGAN2 的改进点:
Lazy regularization
损失 是由损失函数和正则项组成,优化的时候也是同时优化这两项的,lazy regularization就是正则项可以减少优化的次数,比如每16个minibatch才优化一次正则项,这样可以减少计算量,同时对效果也没什么影响。
Path length regularization
在生成人脸的同时,我们希望能够控制人脸的属性,不同的latent code能得到不同的人脸,当确定latent code变化的具体方向时,该方向上不同的大小应该对应了图像上某一个具体变化的不同幅度。为了达到这个目的,设计了 Path length regularization ,它的原理也很简单,在图像上的梯度 用 图像乘上变换的梯度 来表示,下列公式中 表示由latent code
得到的disentangled latent code,
表示图像,这个图像的像素是符合正态分布的,
是生成器
对
的一阶矩阵,表示图像在
上的变化,
是
动态的移动平均值,随着优化动态调整,自动找到一个全局最优值。
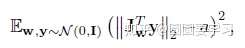
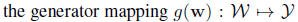
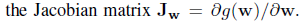
path length can be used to measure GAN’s performance. Another possible sign of trouble is the path distance varies a lot between different segments along the interpolation path. In short, we prefer the linear interpolated points to have similar image distances between consecutive points. In another word, the same displacement in the latent space should yield the same magnitude change in the image space, regardless of the value of the latent factor. Cost is added when the change in the image space is different from the ideal expected displacement. The change in the image space is computed from the gradient which is available for the backpropagation and the expected displacement is approximated by the running average so far.
更具体的实现如下,就直接放论文了,

No Progressive growth
StyleGAN使用的Progressive growth会有一些缺点,如下图,当人脸向左右偏转的时候,牙齿却没有偏转,即人脸的一些细节如牙齿、眼珠等位置比较固定,没有根据人脸偏转而变化,造成这种现象是因为采用了Progressive growth训练,Progressive growth是先训练低分辨率,等训练稳定后,再加入高一层的分辨率进行训练,训练稳定后再增加分辨率,即每一种分辨率都会去输出结果,这会导致输出频率较高的细节,如下图中的牙齿,而忽视了移动的变化。paper的解释如下:
We believe the problem is that in progressive growing each resolution serves momentarily as the output resolution, forcing it to generate maximal frequency details, which then leads to the trained network to have excessively high frequencies in the intermediate layers, compromising shift invariance.
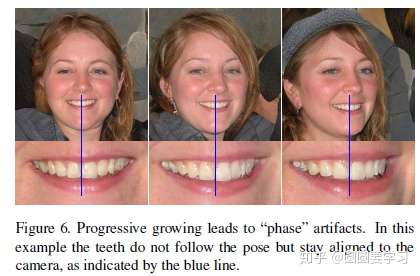
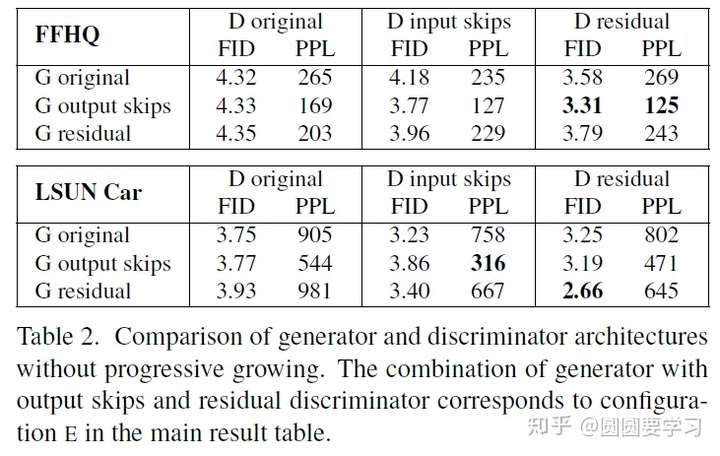
使用Progressive growth的原因是高分辨率图像生成需要的网络比较大比较深,当网络过深的时候不容易训练,但是skip connection可以解决深度网络的训练,因此有了下图中的三种网络结构,都采用了skip connection,三种网络结构的效果也进行了实验评估,如下下图。
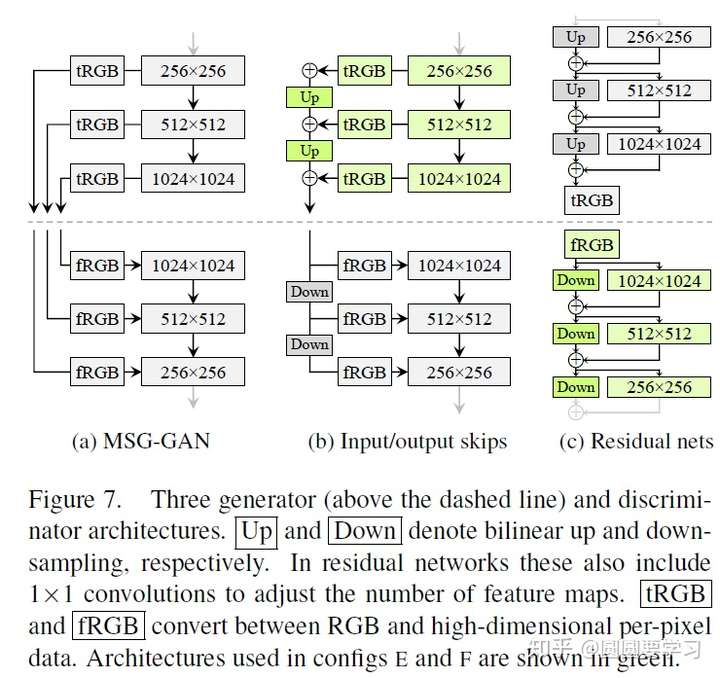
对上述三种网络结构的实验比较如下图:
How to project image to latent code
为什么要把图像生成隐藏编码呢?StyleGAN可以做很多有趣的事情,比如style mixing,但是如何混合指定图像的风格呢,而不是随机假图,这就需要得到指定图像的latent code,这个latent code输入到网络中去,能够复原指定图像。
那么如何生成指定图像的 latent code 呢?论文《Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?》讲的很详尽,有兴趣的可以详细阅读。有两种方法可以将图像映射成 latent code,(1)训练一个编码器,编码器输入是图像,输出是隐藏编码,这种方法的优点是速度快,缺点是不能处理训练数据集以外的图片;(2)选一个随机的latent code,输入到预训练好的网络(比如StyleGAN),根据生成图像与目标图像的损失,通过反向传播对latent code进行迭代,这种方法的泛化性很好,但是速度很慢,因为要迭代很多次。
In general, there are two existing approaches to embed instances from the image space to the latent space: i) learn an encoder that maps a given image to the latent space (e.g. the Variational Auto-Encoder); ii) select a random initial latent code and optimize it using gradient descent.

上图是第二种方法的算法流程, 表示感知损失,即用预训练的VGG网络提取的不同层的feature map特征,这个特征可以表示图像的高层语义特征。
StyleGAN2 中 project image to latent code 的实现细节:
1)StyleGAN2需要找到 和 每一层的噪声
,
表示网络层的索引,
,
表示分辨率,从4x4到1024x1024;
2)

3)
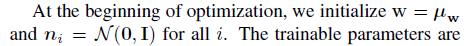

大致就到这里吧,再具体的就请详看相关论文和代码吧。
很有用的参考链接:
https://medium.com/@jonathan_hui/gan-stylegan-stylegan2-479bdf256299https://medium.com/analytics-vidhya/from-gan-basic-to-stylegan2-680add7abe82https://towardsdatascience.com/stylegan-v2-notes-on-training-and-latent-space-exploration-e51cf96584b3
参考文献
- Karras, T., Laine, S., & Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4401-4410).
- Huang, X., & Belongie, S. (2017). Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision (pp. 1501-1510).
- GAN — StyleGAN & StyleGAN2 (Hui, 2020): https://medium.com/@jonathan_hui/gan-stylegan-stylegan2-479bdf256299
posted on 2021-06-04 16:51 Sanny.Liu-CV&&ML 阅读(3413) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号