5、Docker容器网络
使用Linux进行IP层网络管理的指 http://linux-ip.net/html/
# yum install iproute
http://linux-ip.net/html/tools-ip-route.html
https://segmentfault.com/a/1190000000638244
参考:https://cizixs.com/2017/02/10/network-virtualization-network-namespace/
network namespace 是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自的网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己就在独立的网络中。
介绍 network namespace 的基本概念和用法,network namespace 是 linux 内核提供的功能,借助 ip 命令来完成各种操作。ip 命令来自于 iproute2 安装包,一般系统会默认安装,如果没有的话,请读者自行安装。
NOTE:ip 命令因为需要修改系统的网络配置,默认需要 sudo 权限。这篇文章使用 root 用户执行,请不要在生产环境或者重要的系统中用 root 直接执行,以防产生错误。
ip 命令管理的功能很多,和 network namespace 有关的操作都是在子命令 ip netns 下进行的,可以通过 ip netns help 查看所有操作的帮助信息。
默认情况下,使用 ip netns 是没有网络 namespace 的,所以 ip netns ls 命令看不到任何输出。
# ip
Usage: ip [ OPTIONS ] OBJECT { COMMAND | help }
ip [ -force ] -batch filename
where OBJECT := { link | address | addrlabel | route | rule | neigh | ntable |
tunnel | tuntap | maddress | mroute | mrule | monitor | xfrm |
netns | l2tp | fou | macsec | tcp_metrics | token | netconf | ila |
vrf }
OPTIONS := { -V[ersion] | -s[tatistics] | -d[etails] | -r[esolve] |
-h[uman-readable] | -iec |
-f[amily] { inet | inet6 | ipx | dnet | mpls | bridge | link } |
-4 | -6 | -I | -D | -B | -0 |
-l[oops] { maximum-addr-flush-attempts } | -br[ief] |
-o[neline] | -t[imestamp] | -ts[hort] | -b[atch] [filename] |
-rc[vbuf] [size] | -n[etns] name | -a[ll] |?-c[olor]}
# ip netns help
Usage: ip netns list
ip netns add NAME
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id
创建 network namespace 也非常简单,直接使用 ip netns add 后面跟着要创建的 namespace 名称。
如果相同名字的 namespace 已经存在,命令会报 Cannot create namespace 的错误。
# ip netns add r1
# ip netns list
r1
ip netns 命令创建的 network namespace 会出现在 /var/run/netns/ 目录下,如果需要管理其他不是 ip netns 创建的 network namespace,只要在这个目录下创建一个指向对应 network namespace 文件的链接就行。
有了自己创建的 network namespace,我们还需要看看它里面有哪些东西。对于每个 network namespace 来说,它会有自己独立的网卡、路由表、ARP 表、iptables 等和网络相关的资源。ip命令提供了 ip netns exec 子命令可以在对应的 network namespace 中执行命令,比如我们要看一下这个 network namespace 中有哪些网卡。更棒的是,要执行的可以是任何命令,不只是和网络相关的(当然,和网络无关命令执行的结果和在外部执行没有区别)。比如下面例子中,执行 bash 命令了之后,后面所有的命令都是在这个 network namespace 中执行的,好处是不用每次执行命令都要把 ip netns exec NAME 补全,缺点是你无法清楚知道自己当前所在的 shell,容易混淆。
[@node3 ~]# ip netns exec r1 ifconfig
[@node3 ~]# ip netns exec r1 ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00[@node3 ~]# ip netns exec r1 bash
[@node3 ~]# ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
每个 namespace在创建的时候会自动创建一个 lo 的 interface,它的作用和 linux 系统中默认看到的 lo 一样,都是为了实现 loopback 通信。如果希望 lo 能工作,不要忘记启用它:
[root@node3 ~]# ip netns exec r1 ip link set lo up
默认情况下,network namespace 是不能和主机网络,或者其他 network namespace 通信的。
# ip link help Usage: ip link add [link DEV] [ name ] NAME [ txqueuelen PACKETS ] [ address LLADDR ] [ broadcast LLADDR ] [ mtu MTU ] [index IDX ] [ numtxqueues QUEUE_COUNT ] [ numrxqueues QUEUE_COUNT ] type TYPE [ ARGS ] ip link delete { DEVICE | dev DEVICE | group DEVGROUP } type TYPE [ ARGS ] ip link set { DEVICE | dev DEVICE | group DEVGROUP } [ { up | down } ] [ type TYPE ARGS ] [ arp { on | off } ] [ dynamic { on | off } ] [ multicast { on | off } ] [ allmulticast { on | off } ] [ promisc { on | off } ] [ trailers { on | off } ] [ carrier { on | off } ] [ txqueuelen PACKETS ] [ name NEWNAME ] [ address LLADDR ] [ broadcast LLADDR ] [ mtu MTU ] [ netns { PID | NAME } ] [ link-netnsid ID ] [ alias NAME ] [ vf NUM [ mac LLADDR ] [ vlan VLANID [ qos VLAN-QOS ] [ proto VLAN-PROTO ] ] [ rate TXRATE ] [ max_tx_rate TXRATE ] [ min_tx_rate TXRATE ] [ spoofchk { on | off} ] [ query_rss { on | off} ] [ state { auto | enable | disable} ] ] [ trust { on | off} ] ] [ node_guid { eui64 } ] [ port_guid { eui64 } ] [ xdp { off | object FILE [ section NAME ] [ verbose ] | pinned FILE } ] [ master DEVICE ][ vrf NAME ] [ nomaster ] [ addrgenmode { eui64 | none | stable_secret | random } ] [ protodown { on | off } ] ip link show [ DEVICE | group GROUP ] [up] [master DEV] [vrf NAME] [type TYPE] ip link xstats type TYPE [ ARGS ] ip link afstats [ dev DEVICE ] ip link help [ TYPE ] TYPE := { vlan | veth | vcan | dummy | ifb | macvlan | macvtap | bridge | bond | team | ipoib | ip6tnl | ipip | sit | vxlan | gre | gretap | ip6gre | ip6gretap | vti | nlmon | team_slave | bond_slave | ipvlan | geneve | bridge_slave | vrf | macsec }
network namespace 之间通信
有了不同 network namespace 之后,也就有了网络的隔离,但是如果它们之间没有办法通信,也没有实际用处。要把两个网络连接起来,linux 提供了 veth pair 。可以把 veth pair 当做是双向的 pipe(管道),从一个方向发送的网络数据,可以直接被另外一端接收到;或者也可以想象成两个 namespace 直接通过一个特殊的虚拟网卡连接起来,可以直接通信。
使用 ip link add type veth 来创建一对 veth pair 出来,需要记住的是 veth pair 无法单独存在,删除其中一个,另一个也会自动消失。
# ip link add name veth1.1 type veth peer name veth1.2
# ip link sh
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:82:17:a2 brd ff:ff:ff:ff:ff:ff 3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:1a:5e:9d:4e brd ff:ff:ff:ff:ff:ff 4: veth1.2@veth1.1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 //此时veth1.1和veth1.2都是在宿主机上 link/ether 36:59:f5:02:39:1d brd ff:ff:ff:ff:ff:ff 5: veth1.1@veth1.2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 0e:b8:58:dd:5d:5a brd ff:ff:ff:ff:ff:ff
# ip addr list
2: veth1.2@veth1.1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000 //此时都是没有启动的
link/ether d2:e2:d8:fd:50:60 brd ff:ff:ff:ff:ff:ff
3: veth1.1@veth1.2: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 2a:b1:4b:19:fa:b8 brd ff:ff:ff:ff:ff:ff
创建 veth pair 的时候可以自己指定它们的名字,比如 ip link add veth1.1 type veth peer name veth1.2 创建出来的两个名字就是 veth1.1 和 veth1.2 。
如果 pair 的一端接口处于 DOWN 状态,另一端能自动检测到这个信息,并把自己的状态设置为 NO-CARRIER。
创建结束之后,能看到名字为 veth1.1 和 veth1.2 两个网络接口。
# ip link help
Usage: ip link add [link DEV] [ name ] NAME ip link set { DEVICE | dev DEVICE | group DEVGROUP } [ { up | down } ] [ type TYPE ARGS ] [ arp { on | off } ] [ dynamic { on | off } ] [ multicast { on | off } ] [ allmulticast { on | off } ] [ promisc { on | off } ] [ trailers { on | off } ] [ carrier { on | off } ] [ txqueuelen PACKETS ] [ name NEWNAME ] [ address LLADDR ] [ broadcast LLADDR ] [ mtu MTU ] [ netns { PID | NAME } ] [ link-netnsid ID ] [ alias NAME ] [ vf NUM [ mac LLADDR ] TYPE := { vlan | veth | vcan | dummy | ifb | macvlan | macvtap | bridge | bond | team | ipoib | ip6tnl | ipip | sit | vxlan | gre | gretap | ip6gre | ip6gretap | vti | nlmon | team_slave | bond_slave | ipvlan | geneve | bridge_slave | vrf | macsec }
接下来,要做的是把veth1.2放到namespace --> r1,把veth1.1留在宿主机上,这个可以使用 ip link set DEV netns NAME 来实现
# ip link set dev veth1.2 netns r1 //利用内核级的系统调用将网卡设备放到名称空间
# ip link sh
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000 link/ether 00:0c:29:82:17:a2 brd ff:ff:ff:ff:ff:ff 3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default link/ether 02:42:1a:5e:9d:4e brd ff:ff:ff:ff:ff:ff 5: veth1.1@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 //此时宿主机空间只有veth1.1了 link/ether 0e:b8:58:dd:5d:5a brd ff:ff:ff:ff:ff:ff link-netnsid 0
# ip netns exec r1 ifconfig -a //一个设备只能属于一个名称空间,查看r1名称空间信息
lo: flags=8<LOOPBACK> mtu 65536 loop txqueuelen 1000 (Local Loopback) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 veth1.2: flags=4098<BROADCAST,MULTICAST> mtu 1500 ether 36:59:f5:02:39:1d txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# ip netns exec r1 ip link set dev veth1.2 name eth0 //更改网卡名称
# ifconfig veth1.1 10.1.0.1/24 up //激活网卡
# ifconfig
veth1.1: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 10.1.0.1 netmask 255.255.255.0 broadcast 10.1.0.255 ether 0e:b8:58:dd:5d:5a txqueuelen 1000 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# ip netns exec r1 ifconfig eth0 10.1.0.2/24 up
# ip netns exec r1 ifconfig -a
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.1.0.2 netmask 255.255.255.0 broadcast 10.1.0.255 inet6 fe80::3459:f5ff:fe02:391d prefixlen 64 scopeid 0x20<link> ether 36:59:f5:02:39:1d txqueuelen 1000 (Ethernet) RX packets 8 bytes 656 (656.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 8 bytes 656 (656.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# ping 10.1.0.2 //此时用宿主机是可以ping通的 PING 10.1.0.2 (10.1.0.2) 56(84) bytes of data. 64 bytes from 10.1.0.2: icmp_seq=1 ttl=64 time=0.153 ms 64 bytes from 10.1.0.2: icmp_seq=2 ttl=64 time=0.041 ms # ping 10.1.0.1 PING 10.1.0.1 (10.1.0.1) 56(84) bytes of data. 64 bytes from 10.1.0.1: icmp_seq=1 ttl=64 time=0.054 ms 64 bytes from 10.1.0.1: icmp_seq=2 ttl=64 time=0.036 ms
# ip netns add r2 //添加名称空间r2
# ip link set dev veth1.1 netns r2 //把veth1.1放到新建的名称空间r2上
# ip netns exec r2 ifconfig -a
# ip netns exec r2 ifconfig veth1.1 10.1.0.3/24 up //配置IP并激活
# ip netns exec r2 ping 10.1.02 //ping r1 的网卡IP是通的
以上的网络拓扑结构
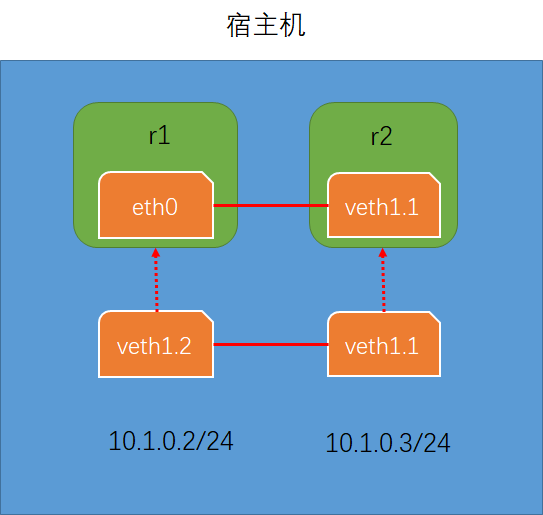
在宿主机中创建两个namespace --> r1和r2,并利用ip netns创建一对虚拟网卡设备veth1.1和veth1.2,在网卡设备没有放进namespace的时候,这对设备是在宿主机上的,但是并没有启动,此时是可以对这对网卡配置IP并启动的。
注意:当veth1.1放进namespace r1,而veth1.2仍然在宿主机上时,如果r1上的veth1.1和veth1.2通信时,相当于r1和宿主机通信。
当把这对网卡设备放进namespace中时,在宿主上是无法查看到的,只能在namespace中可以查看,因为一个设备只支持一个名称空间
四种网络模型
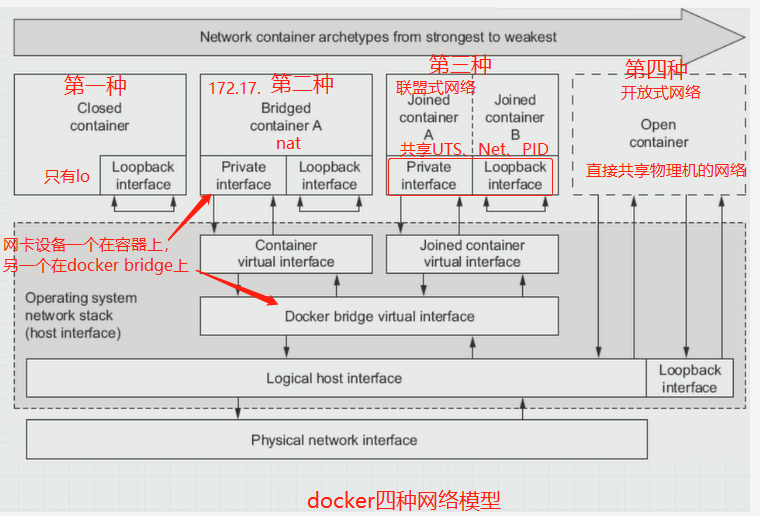
第二种网络模型的配置即bridge网络模型

# docker run --name t1 -ti --rm busybox:latest //第二种网络模型,拥有自己的网络接口
Unable to find image 'busybox:latest' locally
latest: Pulling from library/busybox
697743189b6d: Pull complete
Digest: sha256:061ca9704a714ee3e8b80523ec720c64f6209ad3f97c0ff7cb9ec7d19f15149f
Status: Downloaded newer image for busybox:latest
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
inet addr:172.17.0.2 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:14 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1172 (1.1 KiB) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
--rm Automatically remove the container when it exits
下面对第二种网络模型进行显式配置
# docker run --name t1 -it --network bridge --rm busybox:late //使用network指定bridge网络模式与不指定网络模式是一样的,因为docker的默认网络模式就是bridge
# docker ps -a //查看是否有运行的容器
# docker run --name t1 -it --network none --rm busybox:latest //无网络模式
# docker run --name t1 -it --network bridge --rm busybox:late //bridge模式是用来对外通信的,即使不对宿主机之外的主机进行通信,也可以对统一宿主机内的其他容器进行通信,
主机间通信很多会使用主机名
/ # hostname
d291645c7bac //docker容器的ID号就是docker的主机名,可以使用#docker ps查看,也可以手动指定主机名
# docker run --name t1 -it --network bridge -h t1.beisen --rm busybox:latest //直接指定主机名
/ # hostname //注意:这个容器想要通过主机名的方式访问其他主机/容器,有种方式:一:通过DNS解析主机名,二:通过本地的hosts文件
t1.beisen
/ # cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.17.0.2 t1.beisen t1 //对自己解析没有问题
/ # cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 8.8.8.8 //这里所用的DNS解析服务器是宿主机的DNS服务器,如果能与8.8.8.8通信,那么此处的DNS服务器就可以解析此容器的主机名
/ # nslookup -type=A www.baidu.com Server: 8.8.8.8 Address: 8.8.8.8:53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com Name: www.a.shifen.com Address: 61.135.169.121 Name: www.a.shifen.com Address: 61.135.169.125
想要对某一主机的访问不是通过DNS解析服务器,而是通过/etc/hosts文件来访问
# docker run --help //非常有帮助
Usage: docker run [OPTIONS] IMAGE [COMMAND] [ARG...] Run a command in a new container Options: --add-host list Add a custom host-to-IP mapping (host:ip) -a, --attach list Attach to STDIN, STDOUT or STDERR --blkio-weight uint16 Block IO (relative weight), between 10 and 1000, or 0 to disable (default 0) ......... --dns list Set custom DNS servers --dns-option list Set DNS options --dns-search list Set custom DNS search domains //指明搜索域 --entrypoint string Overwrite the default ENTRYPOINT of the image........ -v, --volume list Bind mount a volume --volume-driver string Optional volume driver for the container --volumes-from list Mount volumes from the specified container(s) -w, --workdir string Working directory inside the container
# docker run --name t1 -it --network bridge -h t1.beisen --dns 114.114.114.114 --rm busybox:latest //指定域名服务器
/ # cat /etc/resolv.conf
nameserver 114.114.114.114
# docker run --name t1 -it --network bridge -h t1.beisen --dns 114.114.114.114 --dns-search ilinux.io --rm busybox:latest //指定搜索域
/ # cat /etc/resolv.conf
search ilinux.io
nameserver 114.114.114.114
如果期望在/etc/hosts文件中自动解析www.baidu.com这样的主机名该如何操作?
Usage: docker run [OPTIONS] IMAGE [COMMAND] [ARG...] Run a command in a new container Options: --add-host list Add a custom host-to-IP mapping (host:ip) //生成hosts文件的解析记录
# docker run --name t1 -it --network bridge -h t1.beisen --dns 114.114.114.114 --dns-search ilinux.io --add-host www.baidu.com:1.1.1.1 --rm busybox:latest
//这里直接在容器外通过它的文件系统向内注入信息,而不用启动容器后再进行编辑
/ # cat /etc/hosts 127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback fe00::0 ip6-localnet ff00::0 ip6-mcastprefix ff02::1 ip6-allnodes ff02::2 ip6-allrouters 1.1.1.1 www.baidu.com 172.17.0.2 t1.beisen t1
开放内网通信
假如容器在bridge网络模式下,docker容器提供的nginx服务,那么nginx是向外提供服务的。但是默认情况下这个容器是隐藏在docker bridge之后的,容器的IP地址172.17网络是个私有地址。
比如在node2上启动一个容器,IP为172.17.0.2,在node3上是无法ping通此IP的。因此需要把想运行在容器中的nginx这样的服务暴露到对外通信的网络中去。
暴露的方式有四种:
Opening inbound communication


# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE studycolumn/httpd v0.2 24577eceda35 5 days ago 1.2MB //将此版本启动一个容器,将此容器的80端口映射至宿主机的一个随机端口 beisen/httpd v0.1-1 439595aa4b0f 6 days ago 1.2MB redis 4-alpine 23d561d12e92 2 weeks ago 35.5MB nginx 1.14-alpine 66952fd0a8ef 2 weeks ago 16MB busybox latest 3a093384ac30 7 weeks ago 1.2MB quay.io/coreos/flannel v0.10.0-amd64 f0fad859c909 13 months ago 44.6MB
1、-p <containerPort>
将指定的容器端口映射至主机所有地址的一个动态端口
注意:"主机所有端口"表示一个宿主机上可能会有多个IP,那么 -p 80会把此宿主机的所有IP的 32768 端口都映射为 80 端口。
2、-p <hostPort>::<containerPort>
将容器端口<containerPort>映射至指定的主机端口<hostPort>
3、-p <ip>::<containerPort> //中间两个冒号,两个冒号中间表示宿主机使用什么端口,如果为空就表示随机端口
将指定的容器端口<containerPort>映射至主机指定<ip>的动态端口
4、-p <ip>:<hostPort>:<containerPort>
将指定的容器端口<containerPort>映射至主机指定<ip>的端口<hostPort>
# docker run --name myweb --rm -p 80 studycolumn/httpd:v0.2
# docker inspect myweb
。。。。。。
"Gateway": "172.17.0.1",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "172.17.0.7",。。。。。。
# curl 172.17.0.7
<h1>Busybox server<h1> //在本机内访问容器的nginx服务是可以的,但这只是主机内部的访问,我们想要的效果是外部的物理主机访问此宿主机的IP时,容器内运行的nginx程序提供的web服务器应有相应
但是外部的网络访问容器所在的宿主机IP时,应该访问哪个端口?因为80端口是容器内的程序提供的,而不是宿主机直接提供的。
# iptables -t nat -vnL //可以使用此命令在宿主机上进行查看
Chain PREROUTING (policy ACCEPT 1 packets, 52 bytes) pkts bytes target prot opt in out source destination 11 572 DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL Chain INPUT (policy ACCEPT 1 packets, 52 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 3 packets, 208 bytes) pkts bytes target prot opt in out source destination 0 0 DOCKER all -- * * 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCAL Chain POSTROUTING (policy ACCEPT 3 packets, 208 bytes) pkts bytes target prot opt in out source destination 0 0 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0 0 0 MASQUERADE tcp -- * * 172.17.0.7 172.17.0.7 tcp dpt:80 Chain DOCKER (2 references) pkts bytes target prot opt in out source destination 0 0 RETURN all -- docker0 * 0.0.0.0/0 0.0.0.0/0 0 0 DNAT tcp -- !docker0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:32768 to:172.17.0.7:80 //此规则是在上面创建容器是 -p 80 自动生成的,当容器消失时,这条规则会自动删除
在浏览器中输入宿主机的IP+映射端口:192.168.128.131:32768 即可访问容器中nginx程序提供的web服务
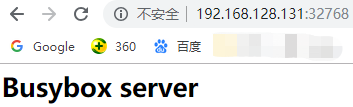
查看映射端口的另一种方法
# docker port myweb //查看映射端口的另一种方法
80/tcp -> 0.0.0.0:32769 //0.0.0.0表示宿主机的所有端口,注意在容器被删除后,再创建同样的容器,映射的随机端口是不断增长的,比如上面映射的端口是32768,推出后再次创建容器映射的随机端口就是32769了。
# docker kill myweb //此时容器myweb被删除,iptables规则就不存在了
如果希望指定映射端口或者IP,而不是自动生成iptables规则,不是映射为一个动态端口,而是映射为固定的地址。
3、-p <ip>::<containerPort> //中间两个冒号,两个冒号中间表示宿主机使用什么端口,如果为空就表示随机端口
将指定的容器端口<containerPort>映射至主机指定<ip>的动态端口
# docker run --name myweb --rm -p 192.168.128.131::80 studycolumn/httpd:v0.2
# docker port myweb
80/tcp -> 192.168.128.131:32768
如果宿主机的80端口没有被使用,也可以指定宿主机的80端口
# docker run --name myweb --rm -p 80:80 studycolumn/httpd:v0.2
# docker port myweb
80/tcp -> 0.0.0.0:80
4、-p <ip>:<hostPort>:<containerPort>
将指定的容器端口<containerPort>映射至主机指定<ip>的端口<hostPort>
# docker run --name myweb --rm -p 192.168.128.131:80:80 studycolumn/httpd:v0.2
# docker port myweb
80/tcp -> 192.168.128.131:80
第三种网络模型:联盟式容器 Joined containers

# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE studycolumn/httpd v0.2 24577eceda35 6 days ago 1.2MB beisen/httpd v0.1-1 439595aa4b0f 6 days ago 1.2MB redis 4-alpine 23d561d12e92 2 weeks ago 35.5MB nginx 1.14-alpine 66952fd0a8ef 2 weeks ago 16MB busybox latest 3a093384ac30 7 weeks ago 1.2MB quay.io/coreos/flannel v0.10.0-amd64 f0fad859c909 13 months ago 44.6MB
# docker run --name b2 -it --rm busybox
/ # ifconfig eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:07 inet addr:172.17.0.7 Bcast:172.17.255.255 Mask:255.255.0.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:6 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:516 (516.0 B) TX bytes:0 (0.0 B)
# docker run --name b2 --network container:b1 -it --rm busybox //上面启动的容器地址与本次启动的容器地址是不同的,因为本次创建的容器是共享了b1的IP,但是b1和b2之间的文件系统等还是隔离的。
/ # ifconfig eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:04 inet addr:172.17.0.4 Bcast:172.17.255.255 Mask:255.255.0.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:18 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1252 (1.2 KiB) TX bytes:0 (0.0 B)
/ # echo "hello world" > /tmp/index.html //注意这里是容器:b2
/ # httpd -h /tmp/ //启动httpd,并把根目录放到/tmp
在b1上访问容器的回环地址lo,可以看到容器b2提供的web服务,所以b1和b2两者是共享网络空间
/ # wget -O - -q 127.0.0.1
hello world
第四种网络模型:开放式网络,直接共享宿主机的网络
下面把两个容器全部退出,然后重新创建容器b2
# docker run --name b2 --network host -it --rm busybox //此次创建的容器b2共享的是宿主机的网络
/ # ifconfig docker0 Link encap:Ethernet HWaddr 02:42:8F:0E:6A:12 inet addr:172.17.0.1 Bcast:172.17.255.255 Mask:255.255.0.0 inet6 addr: fe80::42:8fff:fe0e:6a12/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:111 errors:0 dropped:0 overruns:0 frame:0 TX packets:122 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:9305 (9.0 KiB) TX bytes:12522 (12.2 KiB) ens33 Link encap:Ethernet HWaddr 00:0C:29:EE:53:1E inet addr:192.168.128.131 Bcast:192.168.128.255 Mask:255.255.255.0 inet6 addr: fe80::f528:9792:1744:13a7/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:209474 errors:0 dropped:0 overruns:0 frame:0 TX packets:186992 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:107144705 (102.1 MiB) TX bytes:340231253 (324.4 MiB) lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0 inet6 addr: ::1/128 Scope:Host UP LOOPBACK RUNNING MTU:65536 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # echo "hello world" > /tmp/index.html / # httpd -h /tmp/ / # netstat -tnl Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN tcp 0 0 :::80 :::* LISTEN //可以看出这里监听的是本主机的80端口,所以外网主机可以直接访问容器提供的web服务 tcp 0 0 :::22 :::* LISTEN tcp 0 0 ::1:25 :::* LISTEN
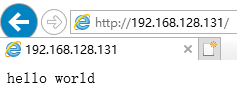
基于 --network host 这种方式的好处在于:不用安装httpd程序,当宿主机出问题的时候,可以直接把容器迁移到其他主机上,直接共享宿主机的网络
自定义docker桥,分别使用不同网段的地址
如何更改默认docker0上的网络地址
自定义docker0桥的网络属性信息:/etc/docker/daemon.json文件 { "bip": "192.168.1.5/24", //只要修改bip,其他选项即可通过计算得知,除了dns "fixed-cidr": "10.20.0.0/16", //注意:只要不是最后一行,行尾一定要有 "," "fixed-cidr-v6": "2001:db8::/64", "mtu": 1500, "default-gateway": "10.20.1.1", "default-gateway-v6": "2001:db8:abcd::89", "dns": ["10.20.1.2","10.20.1.3"] }
核心选项为bip,即bridge ip之意,用于指定docker0桥自身的IP地址,系统会自动推算出这个bridge ip所属网络,
并把这个网络当作随后加入这个bridge的所有容器的默认网络。
演示:修改默认docker0桥的网络IP
# docker kill NAME //杀死所有运行的容器
# systemctl stop docker
# vim /etc/docker/daemon.json
{ "registry-mirrors": ["https://registry.docker-cn.com","https://7g3yx938.mirror.aliyuncs.com"], //注意一定要有逗号 "bip": "10.0.0.1/16" //添加此行 }
# systemctl start docker
# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 10.0.0.1 netmask 255.255.0.0 broadcast 10.0.255.255 //docker0的默认IP地址已经更换,此时docker0的DNS服务器的IP是宿主机的,因为没有指明 inet6 fe80::42:1aff:fe5e:9d4e prefixlen 64 scopeid 0x20<link> ether 02:42:1a:5e:9d:4e txqueuelen 0 (Ethernet) RX packets 10 bytes 535 (535.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 18 bytes 1390 (1.3 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
dockerd守护进程的C/S,其默认仅监听Unix SOcket格式的地址,所以docker仅支持本地通信,路径是:/var/run/docker.sock;
所以不同宿主机上的容器是不能互相管理的
如果想要docker服务器可以被外网访问,需要使用TCP套接字,/etc/docker/daemon.json:
"hosts": ["tcp://0.0.0.0:2375", "unix:///var/run/docker.sock"] //本来只有此路径:unix:///var/run/docker.sock,这里再添加tcp://0.0.0.0:2375表示监听本机tcp协议的所有IP地址的2375端口
也可向docker直接传递"-H|--host"选项;
# systemctl stop docker
# vim /etc/docker/daemon.json
{ "registry-mirrors": ["https://registry.docker-cn.com","https://7g3yx938.mirror.aliyuncs.com"], "bip": "10.0.0.1/16", "host": ["tcp://0.0.0.0:2375","unix:///var/run/docker.sock"] //添加此行 "storage-driver": "devicemapper" //此行可以先不添加,如果有此报错信息:start request repeated too quickly for docker.service 再添加 }
# systemctl start docker
自定义网络类型 --> bridge
# docker info
...
Network: bridge host macvlan null overlay //docker有多种类型(overlay是叠加网络)
...
# docker network --help
Usage: docker network COMMAND Manage networks Commands: connect Connect a container to a network create Create a network disconnect Disconnect a container from a network inspect Display detailed information on one or more networks ls List networks prune Remove all unused networks rm Remove one or more networks Run 'docker network COMMAND --help' for more information on a command.
# docker network create --help
Usage: docker network create [OPTIONS] NETWORK Create a network Options: --attachable Enable manual container attachment --aux-address map Auxiliary IPv4 or IPv6 addresses used by Network driver (default map[]) --config-from string The network from which copying the configuration --config-only Create a configuration only network -d, --driver string Driver to manage the Network (default "bridge") --gateway strings IPv4 or IPv6 Gateway for the master subnet --ingress Create swarm routing-mesh network --internal Restrict external access to the network --ip-range strings Allocate container ip from a sub-range --ipam-driver string IP Address Management Driver (default "default") --ipam-opt map Set IPAM driver specific options (default map[]) --ipv6 Enable IPv6 networking --label list Set metadata on a network -o, --opt map Set driver specific options (default map[]) --scope string Control the network's scope --subnet strings Subnet in CIDR format that represents a network segment
# docker network create -d bridge --subnet "172.26.0.0/16" --gateway "172.26.0.1" mybr0 //注意:mybr0是网络,而不是网络接口
# docker network ls
NETWORK ID NAME DRIVER SCOPE f1f7dae9d2d8 bridge bridge local c7a430036ed4 host host local c1eea5d428d2 mybr0 bridge local e1bfb53c06c1 none null local
# ifconfig //br-c1eea5d428d2是网络接口
br-c1eea5d428d2: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.26.0.1 netmask 255.255.0.0 broadcast 172.26.255.255 ether 02:42:54:30:6a:12 txqueuelen 0 (Ethernet) RX packets 64 bytes 5568 (5.4 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 64 bytes 5568 (5.4 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# ifconfig br-c1eea5d428d2 down //重命名网络接口:br-c1eea5d428d2,修改之前必须使此网络接口下线
# ip link set dev br-c1eea5d428d2 name docker1 //重命名
# ifconfig docker1 up //启动网络接口
docker1: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.26.0.1 netmask 255.255.0.0 broadcast 172.26.255.255 ether 02:42:54:30:6a:12 txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
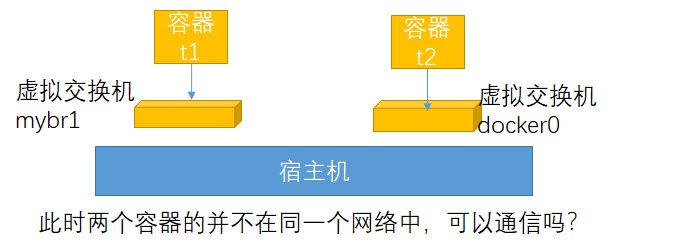
创建容器是直接把这个网络加入就可以了,但是由于更改了网络接口名称,在把网络mybr0加入到容器时出了一些问题,不确定是否是修改网络接口的问题,所以再次创建了网络mybr1
# docker run --name t1 -it --net mybr1 busybox:latest //--net是--network的缩写
/ # ifconfig //此时就有两个桥接时网络 eth0 Link encap:Ethernet HWaddr 02:42:AC:1B:00:02 inet addr:172.27.0.2 Bcast:172.27.255.255 Mask:255.255.0.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:12 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1032 (1.0 KiB) TX bytes:0 (0.0 B)
下面再创建一个容器,使用docker0网络,即原有的bridge网络
# docker run --name t2 -it --net bridge busybox:latest //使用docker默认的桥接网路
/ # ifconfig eth0 Link encap:Ethernet HWaddr 02:42:0A:00:00:02 inet addr:10.0.0.2 Bcast:10.0.255.255 Mask:255.255.0.0 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:16 errors:0 dropped:0 overruns:0 frame:0 TX packets:0 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:0 RX bytes:1312 (1.2 KiB) TX bytes:0 (0.0 B)
此时容器t1和t2是否能通信?是可以通信的,因为网卡1 mybr0和网卡2 docker0同时都有一个接口与宿主机相连接,只需要在宿主机上打开核心转发功能即可
# cat /proc/sys/net/ipv4/ip_forward //核心转发功能已经打开
1
/ # ping 172.27.0.2 //在容器t2上ping容器t1的IP,此时无法ping通,因为宿主机上存在很多iptables规则
# iptables -vnL --line-number //分析iptables规则后发现有一条规则是组织容器间通信
Chain DOCKER-ISOLATION-STAGE-2 (3 references) num pkts bytes target prot opt in out source destination 1 4 336 DROP all -- * br-fa8eef203943 0.0.0.0/0 0.0.0.0/0 //修改此条iptables规则的target为ACCEPT 2 0 0 DROP all -- * docker0 0.0.0.0/0 0.0.0.0/0 3 0 0 DROP all -- * br-c1eea5d428d2 0.0.0.0/0 0.0.0.0/0 4 0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
# iptables -t filter -R DOCKER-ISOLATION-STAGE-2 1 -j ACCEPT //此规则可参考:http://www.zsythink.net/archives/1517
/ # ping 172.27.0.2 //此时在容器t2(10.0.0.2)上即可ping通容器t1
PING 172.27.0.2 (172.27.0.2): 56 data bytes
64 bytes from 172.27.0.2: seq=0 ttl=63 time=1.385 ms
64 bytes from 172.27.0.2: seq=1 ttl=63 time=0.264 ms
可以想象为什么有iptables规则阻止两个容器通信,是因为既然是两个网段就是不让通信的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号