
Python 模块和包
Python 模块和包

1. 模块简介
1.1 什么是模块
编写较长程序时,建议用文本编辑器代替解释器,执行文件中的输入内容,这就是编写 脚本 。随着程序越来越长,为了方便维护,最好把脚本拆分成多个文件。编写脚本还一个好处,不同程序调用同一个函数时,不用每次把函数复制到各个程序。为实现这些需求,Python 把各种定义存入一个文件,在脚本或解释器的交互式实例中使用。这个文件就是 模块
模块即是一系列功能的结合体。
1.2 为什么使用模块
提高了代码的可维护性,不用重复造轮子提升开发效率.
1.3 模块的分类
- 内置模块(使用
python解释器直接可以导入) - 第三方模块(使用
pip安装) - 自定义
1.4 模块的表现形式
-
使用python编写的代码(.py文件),就是平时写的一个python文件
-
已被编译为共享库或DLL的C或C++扩展
-
包好一组模块的包(文件夹)
包其实就是多个py文件(模块)的集合
包里面通常会含有一个
__init__.py文件(在python3中这个文件可以没有) -
使用C编写并链接到python解释器的内置模块
2. import句式
导入模块使用关键字import 加py文件名,不要加.py.
示例:
# 导入内置模块
>>> import time
>>> time.time() # 直接使用
1637651203.9467623
#导入自定义
# 代码文件:foo.py
name = 'Hans'
def hello(name):
print("Hello, %s" % name)
# 导入
>>> import foo
>>> foo.
foo.hello( foo.name
>>> foo.name
'Hans'
>>> foo.hello(foo.name)
Hello, Hans
>>> foo.hello("Jack")
Hello, Jack
# 同一个模块多次导入
# 代码文件:boo.py
print("hello")
# 导入
>>> import boo # 第一次导入,会执行里面的代码。
hello
>>> import boo # 第二次导入,不会执行
>>> import boo # 第二次导入,不会执行
>>> import boo # 第二次导入,不会执行
# 多次导入相同模块 只会执行一次
模块首次导入发生了什么?(以导入boo.py中导入foo.py为例)
# foo.py
name = 'Hans'
def hello(name):
print("Hello, %s" % name)
# boo.py
import foo
print("hello world")
foo.name
foo.hello(foo.name)
foo.hello("Jack")
# 执行结果:
hello world
Hello, Hans
Hello, Jack
- 运行导入文件(
boo.py)产生该文件的全局名称空间 - 运行
foo.py - 产生
foo.py全局名称空间 运行foo.py文件内代码 将产生的名字全部存档于foo.py名称空间 - 在导入文件名称空间产生一个
foo的名字指向foo.py全局名称空间
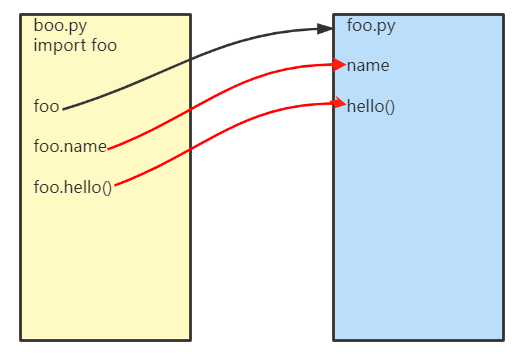
import方法导入模块后就可以使用模块中的所有的变量名或函数名,而且绝对不会冲突,因为调用的时候已经指定了要使用哪个包中的那个变量或函数
3. from...import...句式
from...import...句式为从哪个包或模块中导入哪个模块或功能。
示例:
# foo.py代码:
name = 'Hans'
def hello(name):
print("Hello, %s" % name)
def hi():
print("Hi, world")
# boo.py代码:
from foo import hi #在boo中只使用foo的hi功能
print("hello world")
hi()
# 执行结果:
hello world
Hi, world
# 代码 boo.py
from foo import hi
from foo import hi
from foo import hi
执行结果:
from foo
# from...import...多次导入也只会导入一次
使用from...import...导入:
- 先产生执行文件的全局名称空间
- 执行模块文件 产生模块的全局名称空间
- 将模块中执行之后产生的名字全部存档于模块名称空间中
- 在执行文件中有一个
hi执行模块名称空间中hi指向的值
导入
# foo.py 代码
print("from foo")
name = 'Hans'
def hello(name):
print("Hello, %s" % name)
def hi():
print("Hi, world")
# boo.py 代码
from foo import hi
print("hello world")
def hi():
print("from boo hi")
hi()
# 执行结果:
from foo
hello world
from boo hi # 发现执行hi()的结果为boo.py中的函数不是从foo.py中导入进来的hi
from...import...指定的导入某个名字
在使用的时候直接写名字即可 但是当前名称空间有相同名字的时候,就会产生冲突 使用的就变成了当前名称空间
4. 导入方式的扩展
4.1 使用别名
# import导入
>>> import foo as f # 把foo定义别名为f,这时只能调用f,如果再调用foo就会报错,说foo没有定义
>>> f.name
'Hans'
# from ... import ...导入
>>> from foo import hi as h # 把hi定义为别名为h,调用的时候直接使用h即可,同理hi也不能使用
>>> h()
Hi, world
4.2 连续导入
# import导入
>>> import sys
>>> import os
# 上面的导入方式可以写成下面:
>>> import sys, os # 这种方式和上面的方式功能是一样的
# from ... import ...导入
>>> from foo import hello
>>> from foo import hi
# 上面的导入方式可以写成下面:
>>> from foo import hello, hi # 这种方式和上面的方式功能是一样的
import使用连续导入多个模块时,如果多个模块功能相似或者属于同一个系列时推荐使用。
如果功能不同并且不属于一个系列 那么推荐分行导入
4.3 通用导入
如果使用from ... import ...方式导入一个模块里全部功能时,最基本的方法是依次导入
>>> from foo import hello, hi, name
# 或
>>> from foo import hello
>>> from foo import hi
>>> from foo import name
#可以使用* 号把一个模块里的全部功能都导入
>>> from foo import *
# 如果一个模块里有三个功能,在使用from ... import ... 想让人用其中两个可以使用__all__
# 代码:
print("from foo")
name = 'Hans'
def hello(name):
print("from foo. Hello, %s" % name)
def hi():
print("from foo Hi")
def play():
print("from foo play")
__all__ = ['hi', 'play'] # 在被导入的模块文件中可以使用__all__指定可以被导入使用的名字
# 执行:
>>> from foo import *
from foo
>>> hi()
from foo Hi
>>> play()
from foo play
>>> hello("Hans")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'hello' is not define
4.4 判断py文件是作为模块文件还是执行文件
可以使用函数自带的__name__方法
# foo.py 代码
print("from foo")
name = 'Hans'
def hello(name):
print("from foo. Hello, %s" % name)
def hi():
print("from foo Hi")
def play():
print("from foo play")
print("__name__: %s" % __name__)
# 执行如果:
from foo
__name__: __main__
# 如果foo.py是直接执行时。__name__为 __main__
# 如果foo.py 当成模块在别的文件里导入时:
# importTest.py 代码
import foo
#执行结果:
from foo
__name__: foo
# 如果foo.py文件是被当做模块导入则返回模块名
#
# 一个py文件当成模块被导入时,它会直接执行py文件里的全部代码,可以利用__name__来判断它是否被当成模块导入,如果是则不执行
# 代码 foo.py
def hello(name):
print("from foo. Hello, %s" % name)
def hi():
print("from foo Hi")
def play():
print("from foo play")
if __name__ == '__main__':
print("from foo")
name = 'Hans'
# 代码 importTest.py
import foo
# 执行结果:
#之前导入的时候会直接打印: from foo
5. 模块导入的顺序
模块导入的顺序:
- 先从内存中查找
- 再去内置模块中查找
- 最后去sys.path系统路径查找(自定义模块)
如果都没有查找到则报错
# 1.在内存中查找
# foo.py 代码:
def hello(name):
print("from foo. Hello, %s" % name)
def hi():
print("from foo Hi")
def play():
print("from foo play")
if __name__ == '__main__':
print("from foo")
name = 'Hans'
# importTest.py 代码:
from foo import hello
import time
print("Hello")
time.sleep(10)
hello("time")
# 执行结果:
Hello
#在time.sleep(10)的时候把foo.py删除,这时foo.py已经加载到内存中,所以下面依然执行
from foo. Hello, time
#如果再执行则会报错
# 2.再去内置模块中查找
# 可以自己定义一个和内置模块同名的模块,看看导入的是谁
# 自己编写:time.py 代码:
print("time...")
# boo.py 代码:
import time
print(time)
# 执行结果:
<module 'time' (built-in)>
# 发现time为内置的模块,所以在给py文件命名的时候不要与内置模块名冲突
# sys.path系统路径查找
>>> import sys
>>> sys.path
['', '/usr/lib64/python36.zip', '/usr/lib64/python3.6', '/usr/lib64/python3.6/lib-dynload', '/usr/local/lib64/python3.6/site-packages', '/usr/local/lib/python3.6/site-packages', '/usr/local/lib/python3.6/site-packages/cloud_init-17.1-py3.6.egg', '/usr/lib/python3.6/site-packages', '/usr/lib64/python3.6/site-packages']
# ''为当前目录,然后依次查找
当某个自定义模块查找不到的时候解决方案:
-
自己手动将该模块所在的路径添加到sys.path中
# 查看当前目录 [root@hans_tencent_centos82 tmp]# pwd /tmp [root@hans_tencent_centos82 tmp]# python3 >>> import foo Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'foo' # 提示没有foo模块。 # 查找foo.py模块在哪 [root@hans_tencent_centos82 module]# pwd /tmp/module [root@hans_tencent_centos82 module]# ls -lrt foo.py -rw-r--r-- 1 root root 202 Nov 23 16:54 foo.py # foo.py在/tmp/module目录下。 # /tmp/module加入到sys.path >>> import sys >>> sys.path.append('/tmp/module') >>> import foo >>> sys.path ['', '/usr/lib64/python36.zip', '/usr/lib64/python3.6', '/usr/lib64/python3.6/lib-dynload', '/usr/local/lib64/python3.6/site-packages', '/usr/local/lib/python3.6/site-packages', '/usr/local/lib/python3.6/site-packages/cloud_init-17.1-py3.6.egg', '/usr/lib/python3.6/site-packages', '/usr/lib64/python3.6/site-packages', '/tmp/module'] # 可以看到 '/tmp/module'添加到sys.path -
使用
from...import...句式from文件夹名称.文件夹名称import模块名
from文件夹名称.模块名称import名字# from 文件夹名称.文件夹名称 import 模块名 # foo.py在/tmp/module目录下。 # 当前目录为/tmp # 使用from...import... # 执行结果: >>> from module import foo >>> foo.hi() from foo Hi #当前在/tmp下,而foo.py在/tmp/module/test/下 [root@hans_tencent_centos82 tmp]# ls -lrt /tmp/module/test/foo.py -rw-r--r-- 1 root root 202 Nov 23 16:54 /tmp/module/test/foo.py >>> from module.test import foo >>> foo.play() from foo play # from 文件夹名称.模块名称 import 名字 #只导入foo模块中的一个功能: >>> from module.test.foo import play >>> play() from foo play
6. 绝对导入与相对导入
-
绝对导入
始终按照执行文件所在的
sys.path查找模块,为了防止报错路径加到sys.path路径下。import os import sys sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 使用os.path.dirname取得项目根目录的绝对路径,把项目根目录加入到sys.path,其中os.path.dirname具体嵌套几层要看执行文件的位置。 from src import test1 # os.path.abspath(__file__) 执行文件的绝对路径,如:/tmp/module/test/bin/run.py # os.path.dirname 返回文件路径:/tmp/module/test/bin -
相对导入
句点符(.)
.表示当前文件路径
..表示上一层文件路径# 目录结构,bin目录下为执行文件, src为要调用的相关包 [root@hans_tencent_centos82 test]# ls -lrt drwxr-xr-x 2 root root 4096 Nov 24 15:28 bin drwxr-xr-x 3 root root 4096 Nov 24 15:29 src [root@hans_tencent_centos82 test]# ls -lrt bin/ -rw-r--r-- 1 root root 104 Nov 24 15:28 run.py # run.py import os import sys sys.path.append(os.path.dirname(os.getcwd())) from src import test1 test1.foo1() [root@hans_tencent_centos82 test]# ls -lrt src/ -rw-r--r-- 1 root root 42 Nov 24 15:24 test2.py -rw-r--r-- 1 root root 79 Nov 24 15:29 test1.py # test1.py import test2 def foo1(): print("from test1.foo1") test2.foo2() # test2.py def foo2(): print("from test2.foo2") #执行结果 [root@hans_tencent_centos82 bin]# python3 run.py Traceback (most recent call last): File "run.py", line 4, in <module> from src import test1 File "/tmp/module/test/src/test1.py", line 2, in <module> import test2 ModuleNotFoundError: No module named 'test2' # 会报找不到test2 # 可以使用相对导入解决 # 修改test1.py的代码: from . import test2 def foo1(): print("from test1.foo1") test2.foo2() #执行结果 [root@hans_tencent_centos82 bin]# python3 run.py from test1.foo1 from test2.foo2 # 现在又有一个新问题,就是如果直接执行test1.py的时候,它依然会报错: # test1.py 代码: from . import test2 def foo1(): print("from test1.foo1") test2.foo2() foo1() # 执行结果: [root@hans_tencent_centos82 src]# python3 test1.py Traceback (most recent call last): File "test1.py", line 1, in <module> from . import test2 ImportError: cannot import name 'test2' # 相对导入只能用在模块文件中,不能在执行文件中使用注意:相对导入只能用在模块文件中,不能在执行文件中使用
推荐使用绝对导入,这样不管项目在哪里执行都可以执行。
7. 循环导入
不允许出现循环导入
真要出现了,一般解决方法(就是明知道有循环导入了还是让它运行,一错再错方法):
- 调换顺序
将彼此导入的句式放在代码的最后 - 函数形式
将导入的句式放入函数体代码 等待所有的名字加载完毕之后再调用
8.模块导入总结:
在程序中涉及到多个文件之间导入模块的情况,一律按照执行文件所在的路径为准
推荐使用绝对导入,这样不管项目在哪里执行都可以执行。
9. 常用模块
9.1 collections 模块
这个模块实现了特定目标的容器,以提供Python标准内建容器 dict , list , set , 和 tuple 的替代选择
# namedtuple 命名元组(相当于给元组起个名字)
# namedtuple('名称',[名字1,名字2,...])
# namedtuple('名称','名字1 名字2 ...')
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(10, 20)
>>> p
Point(x=10, y=20)
>>> p.x
10
>>> p.y
20
>>> p.x + p.y
30
>>> Point = namedtuple('Point', 'x, y, z')
>>> p = namedtuple('Point', 'x, y, z')
>>> Point = namedtuple('Point', 'x, y, z')
>>> p = Point(1, 2, 3)
>>> p
Point(x=1, y=2, z=3)
9.1.1 OrderedDict
字典是无序的,使用OrderedDict可以保存了他们被添加的顺序
>>> from collections import OrderedDict
>>> dict1 = OrderedDict([("name","Hans"), ("age",18)])
>>> dict1
OrderedDict([('name', 'Hans'), ('age', 18)])
>>> dict1['hobby'] = "read"
>>> dict1
OrderedDict([('name', 'Hans'), ('age', 18), ('hobby', 'read')])
>>>
9.1.2 defaultdict
为字典查询提供一个默认值
>>> from collections import defaultdict
>>> list_num = [1, 2, 3, 4, 5, 6, 7, 8]
>>> myDict = defaultdict(list)
>>> myDict['a']=list_num
>>> myDict
defaultdict(<class 'list'>, {'a': [1, 2, 3, 4, 5, 6, 7, 8]})
>>> for i in list_num:
... if i > 6:
... myDict['a'].append(i)
... else:
... myDict['b'].append(i)
...
>>> myDict
defaultdict(<class 'list'>, {'b': [1, 2, 3, 4, 5, 6], 'a': [7, 8]}
9.1.3 Counter
提供了计数功能
# 统计字符串每个字符出现的次数
>>> from collections import Counter
>>> str1 = 'ABCDDABCEDFHIJMOOP'
>>> res = Counter(str1)
>>> res
Counter({'D': 3, 'A': 2, 'B': 2, 'C': 2, 'O': 2, 'E': 1, 'F': 1, 'H': 1, 'I': 1, 'J': 1, 'M': 1, 'P': 1})
9.1.4 deque
双端队列,两端快速添加(append)和弹出(pop)
# 队列: queue 先进先出:FIFO
>>> import queue
>>> q = queue.Queue() # 初始化队列,Queue()说明没有元素个数限制
>>> q.put(1) # 向队列加入元素
>>> q.put(2)
>>> q.put(3)
>>> q.put(4)
>>> q.put(5)
>>> q.get() # 从队列取元素
1
>>> q.get()
2
>>> q.get()
3
>>> q.get()
4
>>> q.get()
5
>>> q.get() # 从队列取元素如果没有,则会阻塞
# 双端队列 deque
>>> from collections import deque
>>> dq = deque([1, 2, 3, 4, 5]) # 初始化队列
>>> dq
deque([1, 2, 3, 4, 5])
>>> dq.append(6) # 从右边追加元素
>>> dq
deque([1, 2, 3, 4, 5, 6])
>>> dq.appendleft(0) # 从左边追加元素
>>> dq
deque([0, 1, 2, 3, 4, 5, 6])
>>> dq.pop() # 从右边弹出元素
6
>>> dq.popleft() # 从左边弹出元素
0
collections详细说明请看官方文档:
9.2 time模块
时间的访问和转换.
时间三种表现形式
- 时间戳(秒数)
- 结构化时间(一般是给机器看的)
- 格式化时间(一般是给人看的)
三种时间是可以相互转换的
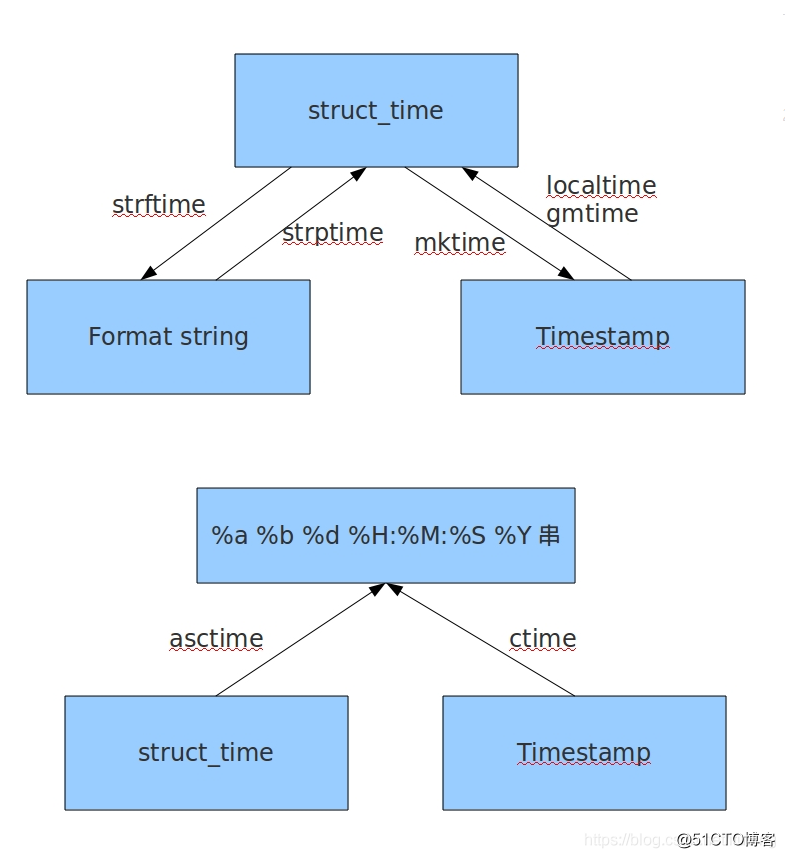
>>> import time
>>> time.time() # 时间戳(自1970年1月1日0时0分0秒到现在的秒数)
1606304157.1071541
# 格式化时间
>>> time.strftime('%Y-%m-%d') # 当前日期
'2020-11-25'
>>> time.strftime('%Y-%m-%d %H:%M:%S') # 当前日期和时间
'2020-11-25 18:57:49'
>>> time.gmtime() # UTC时间
time.struct_time(tm_year=2020, tm_mon=11, tm_mday=25, tm_hour=11, tm_min=0, tm_sec=54, tm_wday=3, tm_yday=329, tm_isdst=0)
>>>
>>> time.strftime('%Y-%m-%d-%H-%M-%S', time.gmtime()) # 格式化时间
'2020-11-25-11-03-20'
>>> time.localtime() # 当地时间
time.struct_time(tm_year=2020, tm_mon=11, tm_mday=25, tm_hour=19, tm_min=1, tm_sec=3, tm_wday=3, tm_yday=329, tm_isdst=0
>>> time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime()) # 格式化时间
'2020-11-25-19-03-55'
# 把时间戳转成可识别时间
# 先转成time.localtime()
# 再使用time.strftime()转成可识别时间
>>> time.strftime('%Y-%m-%d-%H-%M-%S',time.localtime(time.time()))
'2020-11-25-19-07-50'
# 转格式化时间转成赶时间戳
>>> currteTime = time.strftime('%Y%m%d%H%M%S') # 当前时间'20201125193557'
>>> strut_currte = time.strptime(currteTime,'%Y%m%d%H%M%S') # 转成结构化时间 time.struct_time(tm_year=2020, tm_mon=11, tm_mday=25, tm_hour=19, tm_min=35, tm_sec=57, tm_wday=2, tm_yday=330, tm_isdst=-1)
>>> time.mktime(strut_currte) # 转成时间戳
1606304157.0
time详细说明请看官方文档:
9.3 datetime模块
提供用于处理日期和时间
>>> import datetime
>>> datetime.date.today() # 当天日期
datetime.date(2020, 11, 25)
>>> print(datetime.date.today())
2020-11-25
>>> datetime.datetime.today() # 当天日期时间
datetime.datetime(2020, 11, 25, 19, 43, 42, 985477)
>>> print(datetime.datetime.today())
2020-11-25 19:45:04.465346
>>> res = datetime.datetime.today()
>>> res.year # 年
2020
>>> res.month # 月
11
>>> res.day # 日
25
# 时间差timedelta
>>> currTime = datetime.datetime.today()
>>> time_delta = datetime.timedelta(days=2)
>>> currTime
datetime.datetime(2020, 11, 25, 19, 49, 7, 204322)
>>> time_delta
datetime.timedelta(2)
>>> currTime - time_delta
datetime.datetime(2020, 11, 23, 19, 49, 7, 204322)
>>> currTime + time_delta
datetime.datetime(2020, 11, 27, 19, 49, 7, 204322)
datetime详细说明请看官方文档:
9.4 random 模块
该模块实现了各种分布的伪随机数生成器。
>>> import random
>>> random.random() # 它在半开放区间 [0.0,1.0) 内均匀生成随机浮点数
0.251295850082761
>>> random.random()
0.11710038974330583
>>> random.randint(1, 10) # 随机生成1到10之间的整数(包含1和10)
9
>>> random.randint(1, 10)
3
>>> random.uniform(1,5) # 随机生成小数
2.902251945296318
>>> random.choice('abc') # 随机在给的内容内返回一个元素
'b'
>>> random.choice([1, 2, 3])
1
>>> random.sample('abcdef', 3) # 随机返回指定的个数, 并组织成列表形式, 用于无重复的随机抽样
['b', 'e', 'c']
>>> random.sample(['a', 'b', 1, 2,'c'], 4)
['c', 'a', 'b', 2]
>>> list_num =[1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> random.shuffle(list_num) # 打乱容器元素的顺序
>>> list_num
[6, 1, 5, 7, 9, 4, 3, 2, 8]
# 练习随机生成验证码(包含大小写字母和数字)
import random
def random_code(n):
code=''
for i in range(n):
randomInt = str(random.randint(0,9))
randomUpper = chr(random.randint(65,90))
randomLower = chr(random.randint(97,122))
res = random.choice([randomInt,randomUpper,randomLower])
code += res
return code
num = input("想生成几位验证码:").strip()
if num.isdigit:
num = int(num)
res = random_code(num)
print(res)
# 执行结果:
[root@hans_tencent_centos82 tmp]# python3 d.py
想生成几位验证码:3
2xV
[root@hans_tencent_centos82 tmp]# python3 d.py
想生成几位验证码:5
lyF3k
[root@hans_tencent_centos82 tmp]# python3 d.py
想生成几位验证码:8
6pJ41AA4
random详细说明请看官方文档:
9.5 os 模块
该模块提供了一种使用与操作系统相关的功能的便捷式途径(主要和操作系统 相关)。
>>> os.mkdir('test') # 创建空目录,如果目录存在会报错FileExistsError,而且不能联级创建目录
>>> os.makedirs('test/a') # 联级创建目录空目录,如果目录会报错FileExistsError
>>> os.mkdir('test') # 删除空目录,必须是空目录,里面不能有任何文件
>>> os.removedirs('test/a') # 递归删除目录,必须是空目录
>>> os.getcwd() # 获取当前所在绝对路径,类似pwd
'/tmp'
>>> os.path.join(P, "module") # 路径拼接
'/tmp/module'
>>> os.listdir("/tmp") # 显示指定路径下的文件名称(列表的形式)
['m.py', 'c.py', 'v.py', 'x.py', 'stargate.lock', 'o.py', 'n.py', 'j.py', 'g.py', 'r.py', 's.py', 'systemd-private-483254a5abf24463b5ea620ec843438e-chronyd.service-MQAQof', 'l.py', 'p.py', 'module', 'web.txt', 'k.py', 'b.py', 'z.py', 'q.py', 'y.py', 't.py', 'a.py', 'd.py', 'u.py']
>>> os.remove('web.txt') # 删除一个文件
>>> os.getcwd()
'/tmp'
>>> os.chdir('/etc') # 切换目录,类似cd
>>> os.getcwd()
'/etc'
>>> os.path.exists('/tmp') # 查看路径是否存在,存在返回True,不存在返回False
True
>>> os.path.exists('/tmp/web.txt')
False
>>> os.path.isfile('/tmp/a.py') # 判断是否是个文件,是返回True,不是返回False
True
>>> os.path.isfile('/tmp/module')
False
>>> os.path.isdir('/tmp/module') # 判断是否是个目录,是返回True,不是返回False
True
>>> os.path.isdir('/tmp/a.py')
False
>>> os.path.getsize('t.py') # 查看文件的大小,以字节为单位
813
>>> os.system("ls") # 调用系统命令
os详细说明请看官方文档:
9.6 sys 模块
该模块提供了一些变量和函数。这些变量可能被解释器使用,也可能由解释器提供。这些函数会影响解释器(和python解释器相关)。
>>> import sys
>>> sys.path # 打印python查找路径
>>> sys.version # 打印python解释器版本
'3.6.8 (default, Mar 19 2021, 05:13:41) \n[GCC 8.4.1 20200928 (Red Hat 8.4.1-1)]'
>>> sys.platform # 打印操作系统平台,win为win32,linux为linux,mac为darwin
'linux'
# sys.argv # 传递给 Python 脚本的命令行参数
import sys
print(sys.argv)
[root@hans_tencent_centos82 ~]# python3 /tmp/d.py # 如果不跟任何参数,则返回执行脚本路径,argv[0] 为脚本的名称
['/tmp/d.py']
[root@hans_tencent_centos82 ~]#python3 /tmp/d.py 1 2 3
['/tmp/d.py', '1', '2', '3']
# sys.argv 把传递的参数放到一个列表中,索引值0为脚本名称,1为第一个参数
# 写一个脚本只能接受两个参数:
import sys
num = sys.argv
if len(num)-1 == 2:
print("第一个参数是:%s" % sys.argv[1])
print("第二个参数是:%s" % sys.argv[2])
else:
print("必须传两个值")
# 执行结果:
[root@hans_tencent_centos82 ~]# python3 /tmp/sysargv.py # 不传值
必须传两个值
[root@hans_tencent_centos82 ~]# python3 /tmp/sysargv.py a b # 传两个值
第一个参数是:a
第二个参数是:b
[root@hans_tencent_centos82 ~]# python3 /tmp/sysargv.py a b c # 传三个值
必须传两个值
sys详细说明请看官方文档:
9.7 subprocess模块
子进程管理,该模块允许你生成新的进程,连接它们的输入、输出、错误管道,并且获取它们的返回码。
此模块打算代替一些老旧的模块与功能:
os.system和os.spawn*模块
res = subprocess.Popen('dir',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
print('stdout',res.stdout.read().decode('gbk')) # 获取正确命令执行之后的结果
print('stderr',res.stderr.read().decode('gbk')) # 获取错误命令执行之后的结果
#加decode('gbk')是为了windows解析出中文,否则为unicode编码。
# 可以使用subprocess封成函数,可以执行任何系统命令
def exec_cmd(cmd):
CMD = subprocess.Popen(cmd,
shell=True,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout, stderr = CMD.communicate()
if CMD.returncode != 0:
return CMD.returncode, stderr
return CMD.returncode, stdout
#执行结果
res = exec_cmd("ls")
>>> res
(0, b'a.html\na.py\nboo.py\nhouses.py\nhouses.txt\nhouses_v2.py\nimportTest.py\n__pycache__\ntest\ntime.py\n')
# 0 为命令执行的返回码,为0说明命令执行成功。
>>> res = exec_cmd("ls aaa.py") # 查看一个不存在的文件
>>> res
(2, b"ls: cannot access 'aaa.py': No such file or directory\n")
subprocess详细说明请看官方文档:
9.8 序列化json
json主要用于和别的语言传输数据时编码和解码(前后端分离)。
json两个操作:序列化和反序列化
>>> import json
>>> dict1 = {'name':'Hans', 'age':18, 'gender':'M'} # 定义一个字典
>>> type(dict1)
<class 'dict'>
>>> res = json.dumps(dict1) # 使用json.dumps方法把这个字典序列化成一个json字符串。
>>> type(res) # 类型变成了字符串
<class 'str'>
>>> res
'{"name": "Hans", "age": 18, "gender": "M"}'
# 这时res变成了一个字符串,所以不能用字典的取值方式, 这个变成json字符串的过程就叫序列化
# 把json字符串格式转换python可以识别的字典
>>> new_dict1 = json.loads(res) # 使用json.loads方法把这个json字符串转成字典。
>>> type(new_dict1)
<class 'dict'>
>>> new_dict1
{'name': 'Hans', 'age': 18, 'gender': 'M'}
>>> new_dict1['name']
'Hans'
# 这时new_dict1为一个字典,这个从json字符串变成python可识别的类型过程叫作反序列
# 通过json序列化到文件
>>> dict1 = {'name': 'Hans', 'age': 18, 'gender': 'M'}
>>> with open('json.txt', 'w', encoding='utf8') as f:
... json.dump(dict1, f) # 把dict1这个字典转成json字符串后写入文件
# 查看结果:
[root@hans_tencent_centos82 module]# cat json.txt
{"name": "Hans", "age": 18, "gender": "M"}
# 从文件反序列化:
>>> with open('json.txt', 'r', encoding='utf8') as f:
... nes_dict1 = json.load(f)
...
>>>
>>>
>>> nes_dict1
{'name': 'Hans', 'age': 18, 'gender': 'M'}
>>> type(nes_dict1)
<class 'dict'>
>>> nes_dict1['age']
18
# 不使用ASCII转换
>>> nDict1 = {'username': '你好', 'age': 123}
>>> json.dumps(nDict1) # 默认ensure_ascii=True,会把nDict1元素都转为ascii码
'{"username": "\\u4f60\\u597d", "age": 123}'
>>>
>>> json.dumps(nDict1,ensure_ascii=False) # 把ensure_ascii=False,则不转换
'{"username": "你好", "age": 123}'
>>>
可转成json 的数据类型:
| Python | JSON |
|---|---|
| dict | object -- 对象 |
| list, tuple | array |
| str | string |
| int, float, int 和 float 派生的枚举 | number |
| True | true |
| False | false |
| None | null |
json详细说明请看官方文档:
9.9 hashlib 模块
这个模块针对许多不同的安全哈希和消息摘要算法实现了一个通用接口,包括 FIPS 安全哈希算法 SHA1, SHA224, SHA256, SHA384 和 SHA512 (定义于 FIPS 180-2) 以及 RSA 的 MD5 算法。
加密:将明文数据通过一系列算法变成密文数据(目的就是为了数据的安全)
# 1. 基础使用
>>> import hashlib
>>> md5 = hashlib.md5() #确定加密算法
>>> md5.update(b'hello') # update只能接受bytes类型数据,否则会报错
>>> md5.update('hello')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Unicode-objects must be encoded before hashing
>>> md5.hexdigest() #获取加密之后的密文数据
'5d41402abc4b2a76b9719d911017c592'
#如果加密内容只有字母或数字,则在前面直接使用b即可。b'123' 或 b'hello'
#如果要对汉字加密,则要编码转成bytes类型
>>> md5.update('你好'.encode("utf8"))
>>> md5.hexdigest()
'2cfe361166078c59730c075c966bfe91'
# 2. 只要明文一样,不管如何传递加密结果肯定是一样的
>>> import hashlib
>>> md5 = hashlib.md5()
>>> md5.update(b'helloworld12345')
>>> md5.hexdigest()
'bc9c17cb5aeecefbaef22b35099369c3'
# 分开加密
>>> import hashlib
>>> md5 = hashlib.md5()
>>> md5.update(b'hello')
>>> md5.update(b'world')
>>> md5.update(b'12345')
>>> md5.hexdigest()
'bc9c17cb5aeecefbaef22b35099369c3'
# 3. 加盐处理(在对明文数据做加密处理过程前添加一些干扰项)
>>> import hashlib
>>> md5 = hashlib.md5()
>>> md5.update("干扰信息".encode('utf8')) # 添加干扰信息(加盐)
>>> md5.update(b'12345')
>>> md5.hexdigest()
'eff055831c7cff056a4c268b047b10b9'
# 直接对'12345'进行md5加密码为:'827ccb0eea8a706c4c34a16891f84e7b'
# 4. 动态加盐
# 当前时间 用户名的部分 uuid(随机字符串(永远不会重复))
>>> import hashlib
>>> import time
>>> md5 = hashlib.md5()
>>> md5.update(str(time.time()).encode('utf8')) # 使用当前时间时间戳做干扰项
>>> md5.update(b'12345')
>>> md5.hexdigest()
'80a3bdbebec15dbbcc6f32a5e5294a2c'
# 5. 校验文件一致性
# md5.txt内容
hello world
>>> import hashlib
>>> md5 = hashlib.md5()
>>> with open(r'md5.txt','rb') as f:
... for i in f:
... md5.update(i)
...
>>> md5.hexdigest()
'6f5902ac237024bdd0c176cb93063dc4'
# 修改内容md5.txt
hello world1
>>> import hashlib
>>> md5 = hashlib.md5()
>>> with open(r'md5.txt','rb') as f:
... for i in f:
... md5.update(i)
...
>>> md5.hexdigest()
'490f5b3ce928fa8dce51d8d93f9e4124'
# 只要内容有任何一点变动,则加密的值就会变。
# 文件不是很大的情况下 可以将所有文件内部全部加密处理,验证一致性
# 但是如果文件特别大 全部加密处理相当消耗资源 如何验证它的一致性?
# 可以使用切片读取的方式
import hashlib
import os
md5 = hashlib.md5()
file_size = os.path.getsize('data')
read_size = [0, file_size//4, file_size//2, file_size-10]
with open(r'data', 'rb') as f:
for i in read_size:
f.seek(i,0)
#res=f.read(10)
md5.update(f.read())
print(md5.hexdigest())
# 执行结果:
6136aa8c5ce7975b784227d82cea8752
# 给文件新增空行
[root@hans_tencent_centos82 module]# echo >>data
# 执行结果:
52035fa8b25a44507b977fe0545948f3
# 密文越长表示算法越复杂 对应的破解算法的难度越高
# 但是越复杂的算法所需要消耗的资源也就越多 密文越长基于网络发送需要占据的数据也就越大
# 涉及到用户密码存储,都要求是密文,只要用户自己知道明文是什么,后台人员看到的都是密文化
hashlib详细说明请看官方文档:
9.10 logging 模块
这个模块为应用与库实现了灵活的事件日志系统的函数与类
日志级别:
| 级别 | 数值 |
|---|---|
CRITICAL |
50 |
ERROR |
40 |
WARNING |
30 |
INFO |
20 |
DEBUG |
10 |
NOTSET |
0 |
logging日志模块四大组件
logger对象:负责产生日志
filter对象:负责过滤日志(可以忽略)
handler对象:负责日志产生的位置
formatter对象:负责日志的格式
logger要绑定在handler上面,handler要绑定到formatter上面
# 基本使用:(输出到屏幕)
>>> import logging
>>>stream_handler = logging.StreamHandler()
>>> logging.basicConfig(
... format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
... datefmt='%Y-%m-%d %H:%M:%S %p',
... handlers=[stream_handler,],
... level=logging.ERROR
... )
>>> logging.error("一条测试信息")
2021-11-29 16:40:54 PM - root - ERROR -<stdin>: 一条测试信息
# 输入出到文件
>>> import logging
>>> logging.FileHandler(filename='log.log', mode='a', encoding='utf-8')
>>> logging.basicConfig(
... format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
... datefmt='%Y-%m-%d %H:%M:%S %p',
... handlers=[file_handler,],
... level=logging.ERROR
... )
>>> logging.error("这是一个调试信息")
# 查看文件log.log
2021-11-29 16:54:18 PM - root - ERROR -<stdin>: 这是一个调试信息
# 格式说明:
"""
%(asctime)s # 创建日志的时间
%(name)s # 日志名, logging.getLogger("测试日志")
%(levelname)s # 文本日志级别
%(levelno)s # 数字日志记录级别
%(pathname)s # 执行文件的绝对路径
%(filename)s # 执行文件名
%(module)s # 模块名
%(funcName)s # 函数名
%(lineno)d # 日志调用出的行号
%(created)f # 创建日志的时间,时间戳
%(msecs)d # 创建时间的毫秒部分
%(relativeCreated)d # 创建日志记录的时间,相对于日志模块加载的时间,通常在应用程序启动时
%(thread)d # 线程号
%(threadName)s # 线程名
%(process)d # 进程号
%(message)s' # 具体信息
"""
日志配置文件:
简单写日志功能
import logging
logging.basicConfig(
# 1、日志输出位置:1、终端 2、文件
# filename='test.log', # 不指定,默认打印到终端
handlers=[logging.FileHandler(filename="test.log",encoding='utf-8')],
# 也可以不写handlers,直接写filename='test.log',但是如果遇到中文有可能乱码
# 2、日志格式
format='%(asctime)s - %(name)s - %(levelname)s - - %(filename)s - %(module)s: %(message)s',
# 3、时间格式
datefmt='%Y-%m-%d %H:%M:%S %p',
# 4、日志级别
# critical => 50
# error => 40
# warning => 30
# info => 20
# debug => 10
level=20,
)
def write_log(info): # 调用write_log即为记录日志
logging.info(info)
write_log("%s" %("hello 你好"))
复杂配置写日志功能:
import logging
import logging.config
# 设置日志输出格式
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
logfile_path = 'a3.log' # 日志存放的具体路径
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': { # 标准输出格式
'format': standard_format
},
'simple': { # 简单输出格式
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG', #日志级别
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple' # 格式名要和上面formatters设置的相同
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard', # 格式名要和上面formatters设置的相同
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5, # 5个文件后日志轮询
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置 空字符串作为键 能够兼容所有的日志
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
# 使用:
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger('xxx') # xxx为自己定义的日志
logger1.debug('要输出的日志信息')
logging详细说明请看官方文档
10. 第三方模块安装(pip)
使用第三方包要先安装,一般使用安装工具为:pip.pip官网
pip要使用先要安装:
pip --version
pip 9.0.3 from /usr/lib/python3.6/site-packages (python 3.6)
# 显示版本号为已经安装。
# 否则没安装,手动安装
pip使用:
pip install 模块名 #安装最新版本
pip install 模块名==版本号 # 指定版本
pip install -U 模块名 # 升级模块版本
pip unstall 模块名 # 卸载模块
pip download 模块名 # 下载模块
pip search 模块名 # 已被禁用
pip show 模块名 # 显示安装模块的信息
pip list # 查看全部安装的模块
pip freeze # 以需求格式输出已安装的软件包(以需求格式即:模块名==版本号)。
[root@hans_tencent_centos82 module]# pip list # 查看全部安装的模块
asn1crypto (0.24.0)
attrs (19.3.0)
[root@hans_tencent_centos82 module]# pip freeze # 以需求格式输出已安装的软件包。
asn1crypto==0.24.0
attrs==19.3.0
# 使用 pip freeze 导出安装包到 requirements.txt
# 使用requirements.txt安装包:
[root@hans_module]# pip freeze >requirements.txt # 把安装包导入到requirements.txt
[root@hans_module]# pip install -r requirements.txt # 安装requirements.txt文件里的模块
[root@hans_tencent_centos82 .pip]# pip show zipp
Name: zipp
Version: 0.6.0
Summary: Backport of pathlib-compatible object wrapper for zip files
Home-page: https://github.com/jaraco/zipp
Author: Jason R. Coombs
Author-email: jaraco@jaraco.com
License: UNKNOWN
Location: /usr/local/lib/python3.6/site-packages
Requires: more-itertools
# 修改pip源
# 由于pip源默认为国外的源:
http://mirrors.tencentyun.com/pypi/simple
# 安装模块时会有超时,导致安装失败,可修改为国内的源
# 国内pip源:
pypi 清华大学源:https://pypi.tuna.tsinghua.edu.cn/simple
pypi 豆瓣源 :http://pypi.douban.com/simple/
pypi 腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
pypi 阿里源:https://mirrors.aliyun.com/pypi
# 临时修改:
pip install 模块名 -i https://pypi.tuna.tsinghua.edu.cn/simple
# 永久修改:
# 在登录用户下创建
# mkdir ~/.pip # 创建pip的配置目录
# touch pip.conf # 创建pip的配置文件
# 写入以下内容:
[global]
index-url = http://mirrors.tencentyun.com/pypi/simple
extra-index-url = https://pypi.python.org/simple # extra-index-url可以写多个,即增加多个源
http://pypi.mirrors.ustc.edu.cn/simple/
[install]
trusted-host = mirrors.tencentyun.com
pypi.python.org
pypi.mirrors.ustc.edu.cn
11. 包

一般在一个项目中往往需要使用很多的模块,如果将这些模块都堆放在一起,势必不好管理。而且,使用模块可以有效避免变量名或函数名重名引发的冲突,但是如果模块名重复怎么办呢?因此,Python提出了包(Package)的概念。
包就是文件夹,只不过在该文件夹下必须存在一个名为__init__.py 的文件。
__init__.py这个文件在Python2中是必须的,但在Python3中并不是必须的
每个包的目录下都必须建立一个 __init__.py的模块,可以是一个空模块,可以写一些初始化代码,其作用就是告诉 Python 要将该目录当成包来处理。__init__py不是模块名,在 core包中的 __init__.py 文件,其模块名就是core。
包是一个包含多个模块的文件夹,它的本质依然是模块,因此包中也可以包含包。
11.1 创建包
包其实就是文件夹,更确切的说,是一个包含__init__.py文件的文件夹。如果想手动创建一个包,则需要两步:
- 创建一个文件夹,包名即为文件夹名
- 在文件夹中创建一个
__init__.py文件,在__init__.py中可以不编写任何代码。当然,也可以编写一些初始化代码
导入包的本质就是加载并执行包里的__init__.py 文件,然后将整个文件内容赋值给与包同名的变量,该变量的类型是 module。
包的主要作用是包含多个模块,因此__init__.py文件的主要作用就是导入该包内的其他模块。
[root@hans_package]# tree myPackage
myPackage # 包名
├── first.py # 相当于是模块
├── __init__.py # __init__.py文件
└── second.py # 相当于是模块
11.2 包的导入
# 1. 向 myPackage/__init__.py里写出一些内容,然后再导入这个包
[root@hans_tencent_centos82 package]# cat myPackage/__init__.py
print("This is a package")
# 2. 导入包
[root@hans_tencent_centos82 package]# cat test.py
import myPackage
# 3. 执行:
[root@hans_tencent_centos82 package]# python3 test.py
This is a package
导入包的本质是执行包里的__init__.py 文件,因此我们完全可以在 __init__.py 文件中定义变量、函数、类等程序单元,但是不要这么做。永远记住,__init__.py 文件的作用就是导入该包内的其他模块。
# 1. 要在__init__.py增加包中包含的模块
[root@hans_tencent_centos82 package]# cat myPackage/__init__.py
from myPackage import first, second
# 2. 导入包
[root@hans_tencent_centos82 package]# cat test.py
import myPackage
myPackage.first.foo()
myPackage.second.boo()
# 执行结果:
[root@hans_tencent_centos82 package]# python3 test.py
from foo
from boo
# 如果直接导入包名,在__init__.py中要写入要加载的那些模块,否则会报错。
# 把myPackage/__init__.py 中from myPackage import first, second 这句删除。
# 就会报错: AttributeError: module 'myPackage' has no attribute 'first'
# 如果__init__.py内就是没有内容,则可以使用 from 包名 import 模块名 句式导入
[root@hans_tencent_centos82 package]# cat test.py
from myPackage import first, second
first.foo()
second.boo()
# 执行结果:
[root@hans_tencent_centos82 package]# python3 test.py
from foo
from boo
# 如果想直接执行包内的具体函数 可以使用 from 包名.模块名 import 方法名 句式
[root@hans_tencent_centos82 package]# cat test.py
from myPackage.first import foo
from myPackage.second import boo
foo()
boo()
# 执行结果:
[root@hans_tencent_centos82 package]# python3 test.py
from foo
from boo
11.3 包导入总结
包有三种导入方法:
-
import 包名
直接导入包名,并不会将包中所有模块全部导入到程序中,它的作用仅仅是导入并执行包下的
__init__.py文件,所以要在__init__.py文件写导入的模块,所以使用包名调用的时候会报错,使用方法:包名.模块名.方法名 -
from 包名 import 模块名
使用此语法格式导入包中模块后,在使用其方法时不需要带包名前缀,但需要带模块名前缀,使用方法:
模块名.方法名 -
from 包名.模块名 import 方法名
通过该方式导入的变量(函数、类),在使用时可以直接使用变量名(函数名、类名)调用。 使用方法:
方法名
以上都可以使用as添加别名。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号